Google から発表されたFLANについて紹介します。
FLANはFinetunedLAnguage Netの略で、事前トレーニング、微調整、プロンプトを使用して自然言語命令(命令チューニング)を使用することにより、自然言語処理(NLP)モデルのゼロショット学習を改善します。
1.問題・背景
機械学習モデルが意味を持った文章を生成するには、単語に関する大量の知識と文章を抽象化する機能が必要です。意味を持った文章を生成するように訓練された言語モデルは、特徴量をスケーリングするにつれて、単語についての知識を自動的に取得できるようになりますが、その知識を特定のタスクに適用する方法は未だに明確ではありません。
これを行うために確立された手法の1つが、Fine-tuning です。これは、ラベル付きデータセットでBERTやT5などの事前学習済みモデルを再学習して、特定のタスクに適応させる手法です。ただし、Fine-tuningには、特定のタスクごとに保存されたモデルの重みと学習が必要であり、大規模なモデルの場合、実用的とは限りません。
言語モデルを使用してタスクを解決するための最近の一般的な手法の1つは、zero-shotまたはfew-shot prompting です。この手法は、言語モデルが学習中に見たであろうテキストに基づいてタスクを設定し、言語モデルがそのテキストを補完して答えを生成するというものです。たとえば、映画レビューの感情を分類するために、言語モデルに“The movie review ‘best RomCom since Pretty Woman’ is _”という文が与えられ、”positive” または”negative”という単語で文を完成するように求められる場合があります。 この手法は一部のタスクで優れた性能を示しますが、学習中にモデルが学習したデータのように見えるようにタスクを設計するには、高度な技術が必要です。
“Fine-tuned Language Models Are Zero-Shot Learners”では、instruction fine-tuning、または略してinstruction tuningと呼ばれる手法について説明されています。これには、特定のタスクを解決するのではなく、一般的なNLPタスクの解決をより容易にするために、モデルをfine-tuningすることが含まれています。instruction tuningを使用してモデルを学習することをFine-tunedLAnguage Net(FLAN)と呼びます。FLANは、事前トレーニング、Fine-tuning、プロンプトを使用して自然言語命令(命令チューニング)を使用することにより、自然言語処理(NLP)モデルのゼロショット学習を改善する方法です。FLANのinstruction tuningフェーズは、モデルの事前学習に伴う大量の計算と比較して更新数が少ないため、FLANはさまざまなタスクを実行できます。
事前トレーニング
人間と同様に、機械は知識を他の学習領域から別の領域に転送できます(これらの能力が有効になっていると仮定します。ここでは、コンピューターについて言及しているだけではありません)。新しいタスクへの事前トレーニングでは、1つのタスクのモデルが、適用される可能性のある新しいパラメーターを認識するように教えられ、共通のパラメーターの新しい開始重みについてトレーニングされます。結局のところ、感情分析は翻訳とは異なる方法で語順に重みを付けますが、関連するパラメーターのいくつかは両方に共通です。
Instruction Tuning
FLANは、「映画レビューをポジティブまたはネガティブに分類する」や「文章をデンマーク語に翻訳する」など、シンプルで直感的なタスクに適用させるために、様々な指示の大規模なデータセットでモデルをFine-tuningします。モデルをFine-Tuningするために最初から必要なデータセットを作成するには、かなりの量のリソースが必要になります。したがって、代わりにテンプレートを使用して、既存のデータセットを教育形式に変換します。これらの指示でモデルを学習することにより、学習中に見た種類の指示を解決するのが得意になるだけでなく、一般的な指示に従うのも得意になることを示します。
2.モデルの評価
FLANをベンチマークデータセットを使用して、モデルのパフォーマンスを既存のモデルと比較しています。また、学習中にそのデータセットの例を見ることなく、どのように機能するかを評価しています。ただし、評価データセットに類似しすぎているデータセットで学習した場合、性能が歪む可能性があります。例えば、ある質問応答データセットで学習を行うと、モデルが別の質問応答データセットでより適切に機能するようになる場合があります。このため、すべてのデータセットをタスクの種類ごとにクラスターにグループ化し、データセットの学習データだけでなく、データセットが属するタスククラスター全体を保持します。
3.結果
25のタスクでFLANを評価したところ、4つを除くすべてのタスクでzero-shot promptingよりも改善されていることがわかっています。結果は、25のタスクのうち20でzero-shot GPT-3よりも優れており、一部のタスクではfew-shot GPT-3よりも優れていることがわかりました。多くの機械学習モデルは時間がかかる可能性があり、トレーニングに非常に費用がかかります。特に、タスクでトレーニングされた同様のモデルがない場合は費用がかかります。更に、トレーニングデータの開発にも時間と費用がかかる可能性があります。したがって、理想は、他のドメインからトレーニングして迅速に再利用できるモデルを開発することが求められます。上記のように、追加のトレーニングデータ要件がほとんどまたはまったくないことをzero-shotと呼び、それがFLANの設計となっています。
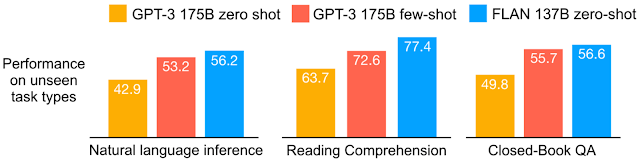
様々なモデルについて、タスククラスタ内の全データセットに対する平均精度を示しています。
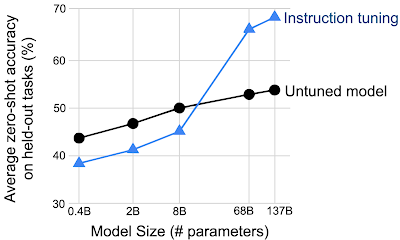
命令のチューニングは、ある程度の大きさのモデルの場合、未経験のタスクでのパフォーマンスを向上させるだけです。
4.まとめ
FLANモデルは、一連の命令を学習する初めてのモデルではありませんが、この手法を大規模に適用した初めてのモデルであり、モデルの一般化能力を向上させることができることを示しています。
参考・出典
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning