勾配消失問題を解消し、層を深くするために開発されたResNet及びDenseNetについて解説します。
ResNet元論文「Deep Residual Learning for Image Recognition」(2015/12/10)
https://arxiv.org/abs/1512.03385
DenseNet元論文「Densely Connected Convolutional Networks」(2016/08/25)
https://arxiv.org/abs/1608.06993
ResNet、DenseNetが誕生した背景
近年のコンピュータの計算力の向上など、インフラ面の発展により、更に深いネットワークを訓練することが可能となり、CNNによる画像認識が進歩した。しかし、ネットワークが深くなると勾配消失の問題が発生し、学習がうまくいかないため、更に層数を増やすのが困難という課題にぶつかった。そのため数十、あるいは数百の深さのレイヤーになりうるネットワークであっても、全レイヤーにシグナルがより簡単に届くようにデザインすることが求められるようになった。2015年のResNetなどの登場により100層以上のネットワークが構成できるようになり、更に精度が向上することになった。DenseNetはResNetを更に改良したモデルとなる。
ResNetとDenseNetの比較
同じ点:
①DenseNetsはResNetをふまえて開発されたもので、ともにより深い層の実現を目指したものである。
②DenseNetsでもResNetと同様、畳み込み層が用いられている。
③DenseNets及びResNetはともにBottleNeckとよばれる1×1の畳み込み変換が使われている。
異なる点:
ResNetはある層に与えられた信号をそれよりも少し上位の層の出力に追加するスキップ接続(ショートカット接続)により深いネットワークを訓練できるようにした。それに対してDenseNetは前方の各層からの出力すべてが後方の層への入力として用いられる。
Kerasが提供する訓練済みモデルの比較表
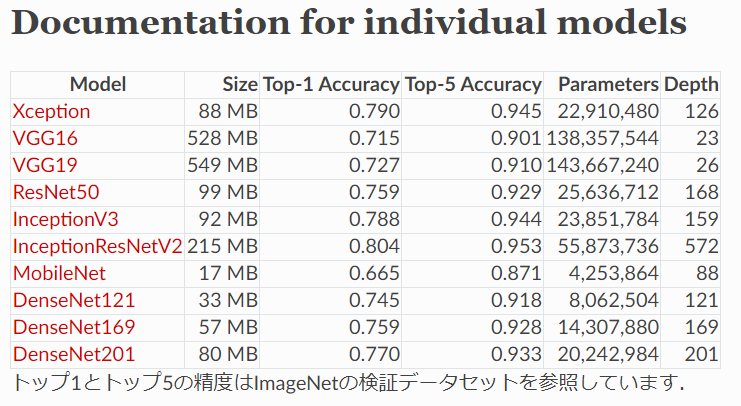
引用 https://keras.io/ja/applications/
Residual Network詳細
Residual Network (ResNet)はshortcut connectionという機構を導入し、手前の層の入力を後ろの層に直接足し合わせることで、勾配消失問題を解決した。Microsoft Research(現Facebook AI Research)のKaiming He氏が2015年に考案したニューラルネットワークのモデルがResNetで、2015年に開催されたILSVRCのImageNetにおいて152もの層(なお、2014年の優勝モデルは22層)を重ねることに成功し、優勝モデルとなった。
ResNetのアイデアはシンプルで、「ある層で求める最適な出力を学習するのではなく、層の入力を参照した残差関数を学習する」 ことで最適化しやすくしている。
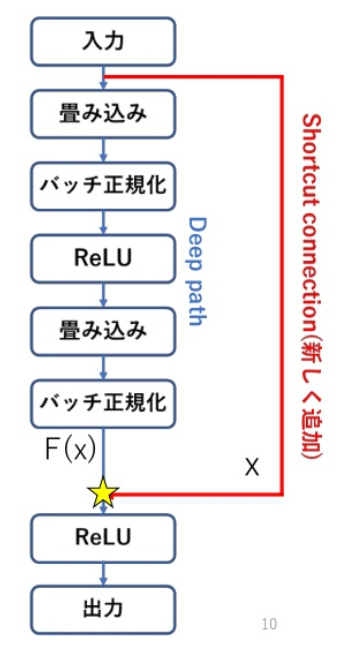
引用:https://www.slideshare.net/KotaNagasato/resnet-82940994
deep pathが従来のルートで、ResNetにおいて追加されたのが、shortcut connectionとなる。入力値をx、従来のCNNにおける★部分での値をH(x)とすると、ResNetではshortcut connectionでx、deep pathでF(x)=H(x)‐xを出力し、★で加算する。重みの更新もdeep pathでF(x)を出力するように学習される。残差(residue)を出力するため、ResNetと呼ばれる。
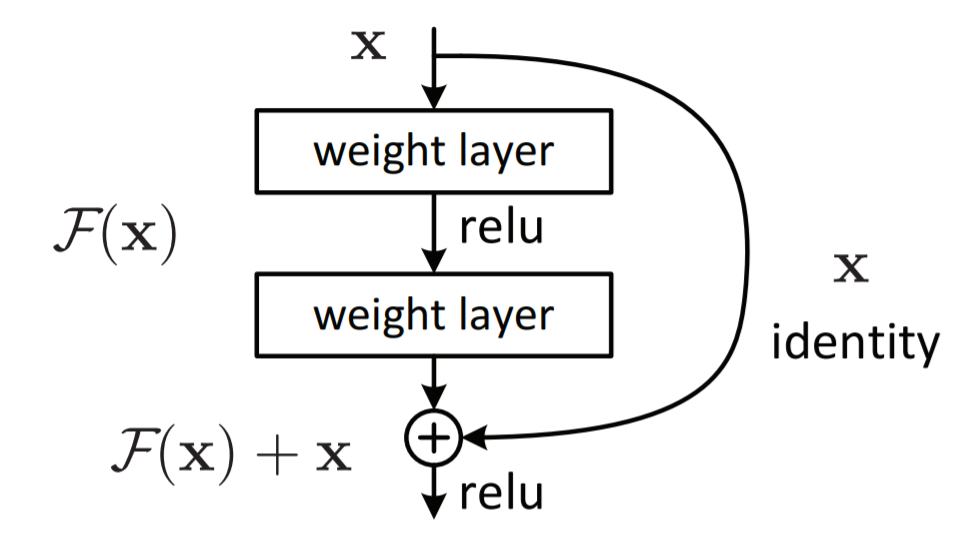
残差ブロック(Residual Block)
ResNetは下図のような残差ブロックを繰り返して構成される。残差ブロックは、畳込み層とSkip Connectionの組み合わせになっている。2つの枝から構成されていて、それぞれの要素を足し合わせる。残差ブロックの一つはConvolution層の組み合わせで、もう一つはIdentity関数となる。こうすれば、仮に追加の層で変換が不要でもweightを0にすれば良い。残差ブロックを導入することで、結果的に層の深度の限界を押し上げることができ、精度向上を果たすことが出来た。
引用:https://arxiv.org/pdf/1512.03385.pdf
下図は左図がbuilding blockで右図がbottleneck building blockと呼ばれる。同等の計算コストとなるが、Bottleneckアーキテクチャの方はPlainよりも1層多くなる。1×1と3×3のConvolution層で出力のDepthの次元を小さくしてから最後の1×1のConvolution層でDepthの次元を復元することからBottleneckという名前がついている。
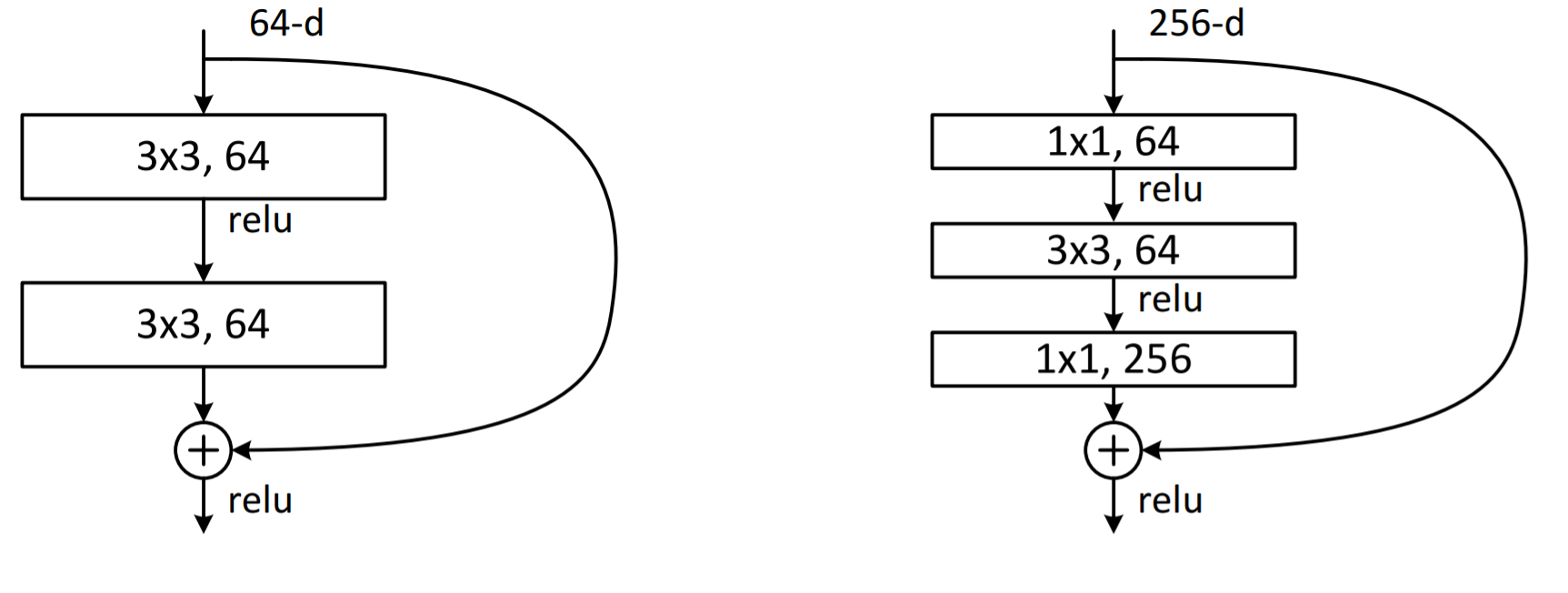
shortcut connectionの数式的理解
従来のネットワークにおいて、レイヤーのアクティベーションは以下のように定義されていた。
y = f(x)
※x は入力、f() は出力(畳み込み、行列乗算、バッチ正規化など)を表現。
信号が逆方向に送られた時、勾配は常にf(x)を通過することとなる。代わりにResNetは以下を実装している。
H(x) = F(x) + x
※building blockへの入力を x 、building block内の層の出力を F(x) 、最終的なbuilding blockの出力を H(x) で表現。
最後の“+ x”がショートカットを意味する。これは手前の層で学習しきれなかった誤差の部分を次の層で学習することを表すので、機械学習のアンサンブル学習で用いられるstackingという手法と同じであると見なせ、精度の向上にも寄与する。
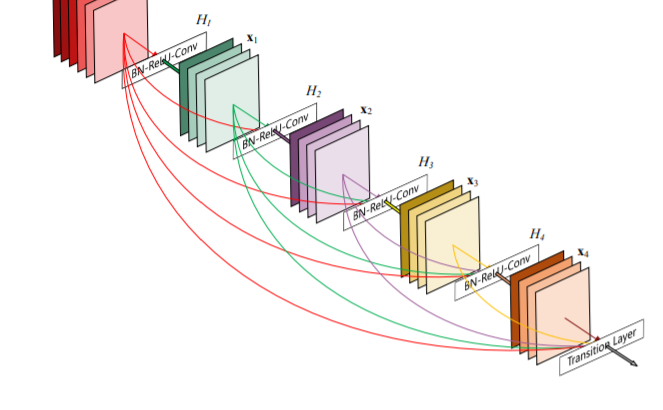
DenseNet詳細
DenseNetのアイディアは、もし前のレイヤーとスキップ接続で接続することによってパフォーマンスが向上するならば、どうしてレイヤーをその他のレイヤーに直接接続しないのか、というもの。この発想を実現するということは、常にネットワークを介した情報を送る直接的なルートを存在させることを意味する。レイヤー間の情報の伝達を最大化するためにすべての特徴量サイズが同じレイヤーを結合させている。逆伝播を保つため、ある層より前の層の出力を入力とする。レイヤー間が密に結合していることから、DenseNetとよぶ。
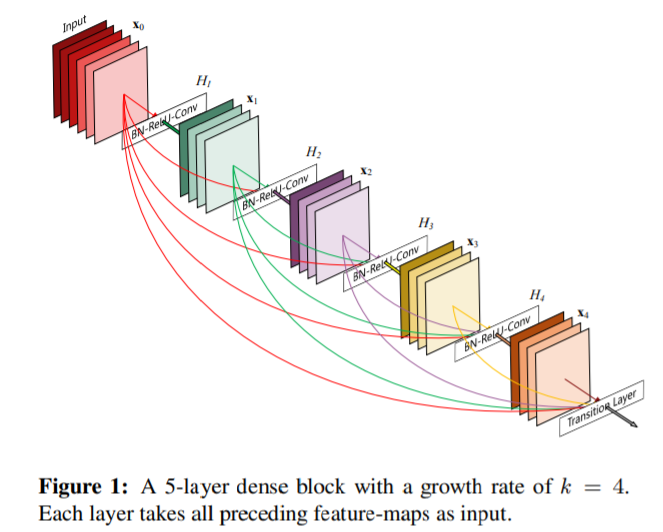
引用 https://arxiv.org/pdf/1608.06993.pdf
DenseNetのメリット
すべてのレイヤーを直接接続することによって、
①勾配消失の削減
②特徴伝達の強化
③特徴の効率的な利用
④パラメータ数の削減
⑤正則化効果の期待
を実現している。
DenseNetの構造
①Initial Convolution
②Dense Block
③Transition layer
④Classification layer

引用 https://arxiv.org/pdf/1608.06993.pdf
Dense Block
第i層の出力をxiとすると、Dense Blockの第i層の出力は以下の式で表される。
xi = Hi([x0, x1, …, xi-1])
・ここでHiは
・Bacth normalization
・ReLU
・3×3 Convolution
の合成関数を表す。
・上記式は入力のテンソルx0, x1, …, xl-1を結合して入力することを表す。
例)xiが16×32×32のとき、入力は
(入力のチャネル数)+((lー1)×16)×32×32)
Transition layer
Pooling層をどうするのか、という問題がある。
・Dense Blockは特徴量マップのサイズが変わってしまうと使えない。
・しかし、マップサイズを変えるダウンサンプリングを行う層はCNNの重要な要素であり、いれないわけにはいかない。
⇓
ネットワークをDense Blockが複数結合した構造にし、間にPooling層を入れる形で解決した。この層を、transiton layerとよぶ。
![]()
引用 https://arxiv.org/pdf/1608.06993.pdf
DenseNetはDenseBlockとTransitionLayerを交互に重ねていくことになる。TransitionLayerは1×1畳み込みと2×2のAveragePoolingをするだけの簡単な存在となる。1×1畳み込みではチャンネル数の圧縮を行う。この圧縮のパラメーター(Compression factor)はθで0<θ≤1となる。
例えば、直前までのチャンネル数が256だった場合、この圧縮によりチャンネル数は128となる。また続くAveragePoolingにより解像度は半分にダウンサンプリングされる。
成長率(Growth rate)
Dense Blockの式で確認したように、Hlがチャネル数kの特徴量マップを出力する場合、l番目のレイヤへの入力は k × ( l – 1 ) + k0 となる。(k0はBlockへ入力される画像のチャネル数)ネットワークが大きくなりすぎるのを防ぐために、kは小さい整数に設定する。
このkの値を成長率(Growth rate)と呼ぶ。簡単にいえば、ネットワーク上でDenseBlock1つあたり、どの程度フィルター数を増やすかというものになる。発表論文ではより直感的な表現として、「知識の収集」と表現している。DenseBlockによりk個の特徴量のマッピングが追加されることになる。成長率はどの程度新しい情報をグローバルな状態(メイン側)に追加するのかをコントロールすることにもなる。ハイパーパラメータであり、いろいろな値を設定することができる。
ボトルネック層による計算効率の上昇
発表論文では、1×1畳み込みをボトルネック層(Bottleneck layer)と呼んでいる。分岐前のチャンネル数n次第では、n→128としたときにチャンネル数が増える場合減る場合の両方が考えられる。これは少なくとも「1×1→3×3畳み込みをする際のパラメーター数や計算量を頭打ちにする」、というメリットがあると言える。いきなり3×3畳み込みをしてしまうと、nの値が大きくなるとパラメーター数がとても大きくなってしまう。
参考URL
ResNet元論文「Deep Residual Learning for Image Recognition」(2015/12/10)
https://arxiv.org/abs/1512.03385
DenseNet元論文「Densely Connected Convolutional Networks」(2016/08/25)
https://arxiv.org/abs/1608.06993
「DenseNetの論文を読んで自分で実装してみる」(2018/08/06)
https://qiita.com/koshian2/items/01bd9f08444799625607「ResNet、HighwayNet、DenseNetのロジック解説」(2020/01/6)
https://spjai.com/resnet-highwaynet-densenet/#i-2
「Residual Network(ResNet)の理解とチューニングのベストプラクティス」(2016/11/300)https://deepage.net/deep_learning/2016/11/30/resnet.html
「Keras Documention」
https://keras.io/ja/applications/
<所感>
代表的なモデルである「ResNet」、「DenseNet」の解説を行った。
次は、「EfficientNet」の理解を深めたい。