はじめに
自然言語処理(Natural Language Processing: NLP)の文脈から誕生したTransformerはそのモデルのシンプルさにもかかわらず、大きな成果をあげることに成功しました。そのため、その後NLPにブレイクスルーをもたらしたBERTやGPT-2などのモデルはTransformerをもとにつくられています。現在(2020年)では、DETRなど最新の物体検出モデルにも使われるようになり、Transformerは機械学習を学ぶ上では避けて通ることができないモデル・アイディアであるといえるでしょう。
今回は、近年の最重要モデルといえるTransformerについて発表論文「All you need is attention」を中心に、その誕生背景からモデル概念まで一から解説したいと思います。
なお、今回の内容は以下の二つに大別されます。
.Transformerが誕生した背景
.Transformerの詳細
前提知識を理解されている方や、Transformerのモデルについてのみ知りたい方は目次から詳細以下をご参照ください。
・論文
Attention Is All You Need
https://arxiv.org/abs/1706.03762
・GoogleBlog
Transformer: A Novel Neural Network Architecture for Language Understanding
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
・自然言語処理の必須知識 BERT を徹底解説!
(https://deepsquare.jp//2020/09/bert/)
・話題沸騰のGPT-3 OpenAI発の革新的なAIを紹介!
(https://deepsquare.jp/2020/08/gpt-3/)
・Transformer を物体検出に採用!話題の DETR を詳細解説!
(https://deepsquare.jp//2020/07/detr/)
・画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!(https://deepsquare.jp/2020/10/vision-transformer/)
モデル開発の歴史
Transformerが開発されるに至った歴史を簡単に説明します。
RNN(LSTMやGRU含む)時代
初期の言語モデル(1-gram言語モデルなど)では、限られた単語同士の結びつきを情報として保持するのみでした。しかし、より精度の高い言語モデルを目指すうえでは、文章全体の結びつき(いわゆる文脈)をふまえた処理が必要であることが明らかになります。
例)Tom gets an apple. He eats it.
「He」が誰なのか、「it」が何なのかは前の文章とのつながり(文脈)を理解していないとわからない。
⇒そのために、RNN(LSTM)などに代表される文章全体の依存関係情報を保持できる再帰モデルがつくられることになります。発想としては入力データを固定長ベクトルに変形する(分散表現化する)際に、それ以前の単語の情報も加味したうえで固定長ベクトルに変形すればよいのではないかというものです。
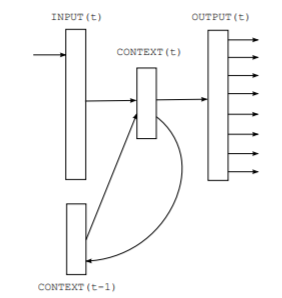
RNN(LSTM)などは、「閉じたモデル」、「ループするモデル」ともいわれますが、それは①同じ関数を再帰的に(何度も)利用して逐次的に出力し、②次の入力に用いられるデータの一部に前の出力が含まれるためです。こうして得られた固定長ベクトルに、文脈を加味した形で文章全体の情報が圧縮されていると考えることができます。
このことで、RNN(LSTM)は、文脈(単語の依存関係)を反映することが可能になりました。このことで、より表現力が高い言語モデルを構築することができるようになったといえます。しかし、再帰的に計算するとは逐次計算することを意味し、計算の並列化することができず(GPUなどの特性を生かせない)計算の高速化が難しいという問題を残すことになりました。
Recurrent neural network based language model
https://arxiv.org/pdf/1508.04025.pdf
Seq2seq時代
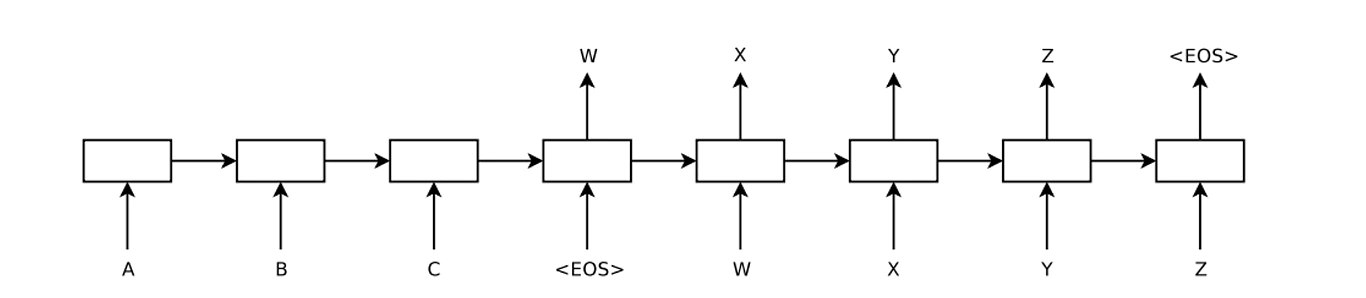
機械翻訳など異なる時系列データを利用するために、RNN(LSTM)をEncoder/Decoderとして二つ利用するSeq2seqモデル(Encoder‐Decoder型RNN(LSTM))が考案されます。
Seq2seqではEncoder/Decoderにおいて入力データはひとつの固定長ベクトルに変換され、RNNなどと同様の形で利用されています。このSeq2seqは異なる時系列データの変換という点では、大きな成果をあげましたが、その一方で問題点も明らかになります。それは①入力する文章の長さにかかわらず、固定長ベクトルに圧縮していることで必要な情報までが捨象されてしまうこと、そして②単語や文章同士の照応関係(アライメント)を利用することができないということ、です。
この何に注目すべきなのかを示す照応関係が利用できるようになることは、翻訳などで異なる時系列データを扱う場合では特に重要になります。(例えば漠然と「dog」が何を意味するかを探すより、「dog」と「犬」の照応関係をふまえた方がより正確な翻訳が可能になることを意味しています。)
Sequence to Sequence Learning with Neural Networks
[Submitted on 10 Sep 2014 (v1), last revised 14 Dec 2014 (this version, v3)]
Attention付きseq2seq時代
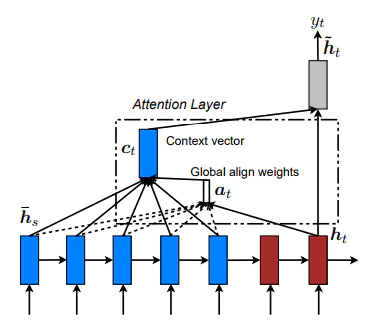
それらSeq2seqの問題を解決したのが、Attention付きSeq2seqになります。AttentionはそれまでEncoder部分から作られる固定長ベクトルが最後の部分しか利用されていなかった点に着目し、各単語が入力される際に出力される固定長ベクトルをすべて利用することで①単語の数と同じ数だけの固定長ベクトルを獲得することができ(文章の長さに応じた情報量を獲得することができる)、②そのことで各単語間の照応関係(アライメント)を獲得することを可能にしました。(これは、各単語を入力したときに出力される固定長ベクトルには、最後に入力された単語の情報が強く反映される傾向があることを利用したものです。)
また、Attentionは単語間の照応関係を一対一対応で考えるのではなくSoftmax関数などを用いてこれらを確率的なものであると考えています。(dogは「犬:0.6」「動物:0.2」「人:0000.1」という形で照応しているとしています。この数値をAttentionスコアと一般的にいいます。)これらの数値は単語間の関係性を示しているため、ディープラーニングの問題とされていたブラックボックス化をさけ、どのような単語と紐づいているかを可視化することができるという利点もあります。もちろん、この利点はTransformerにも引き継がれています。
Effective Approaches to Attention-based Neural Machine Translation
https://arxiv.org/abs/1508.04025
Transformer時代(RNN系不使用)
Attentionを利用することでより精度が高まった一方で、以前としてRNNなどを併用することで生じている問題は解決されないままでした。それは時系列データ(シーケンシャルなデータ)を逐次的に処理するため、データを並列処理できず、計算の高速化が困難であるというものです。高速化を目指した過程でAttention付きCNNも考案されましたが、長文の依存関係モデルを構築することが難しいという別の問題が生じ、結局抜本的な解決には至りませんでした。
それらの問題を乗り越えたのがTransformerです。RNNやCNNなどを利用することを一切やめ、完全にAttention層だけを用いて構築することで、TransformerはRNNやAttention付きSeq2seqなどが抱えていた「高速化できない」という問題や「精度の高い依存関係モデルを構築できない」という問題を解決することに成功しました。
Transformer概要
Transformerとは
・2017年中旬、Googleが発表した論文「Attention is all you need」で提出され、正確な翻訳を目指したモデル。
・それまでNLPの世界で主流であったRNN(及びCNN)を利用するモデル構造をやめ、AttentionのみをもちいてEncoder-Decoder型のモデルを設計しました。
・当時のSoTAを超えるBLEUスコア(28.4)を叩き出しました。(なお、BLEUスコア(0~100)とは「プロの翻訳者の訳と近ければ近いほどその機械翻訳の精度は高い」という発想のもと、正解となる翻訳とどれだけ一致できたかによって算出されるもの。)
・現在の最新NLPモデルに使われている重要基礎モデルであるだけでなく、最近ではDETRなど画像認識にも使われ優れた結果を残している汎用性の高いモデル。
Transformerの特徴
①RNNやCNNを使わずAttention層のみで構築(Self-Attention層とTarget-Source‐Attention層のみで構築)
⇒ RNNを併用する場合と比べて、並列計算が可能になり計算が高速化しました。
CNNを併用する場合と比べて、長文の為の深いモデル構築が不要となりました。
②PositionalEncoding層の採用
⇒RNNなどを利用しないことで失われてしまうはずの文脈情報を、入力する単語データに「文全体における単語の位置情報」を埋め込むことで保持することに成功しました。
③Attention層におけるQuery-Key-Valueモデルの採用
⇒初期のAttentionにおける単純なSource-Target型から改良され、より単語同士の照応関係(アライメント)を正確に反映することができるようになったことで精度が改善されました。
以上がTransformerの重要な特徴となります。Transformerにはほかにも細かい工夫がなされていますが、この三つの仕組みを理解することが出来ればTransformerの核となる部分は理解できたといえるかとおもいます。三つの仕組み、なぜ上記のような効果を得ることができるのかについては、これから詳しく説明します。
なお、これらの工夫によって、Transformerは従来モデルよりも、
①計算を高速化した上で、②文脈情報を保持することに成功し、③より正確な変換(翻訳)
を可能にすることができたといえます。
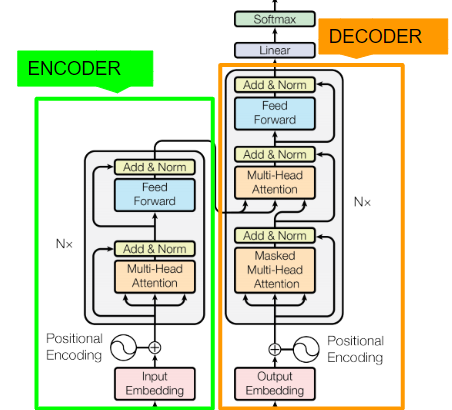
Transformerの構造
TransformerはSeq2seqと同じでEncoder‐Decoderモデルです。Encoder/Decoderで異なる時系列データが入力されています。
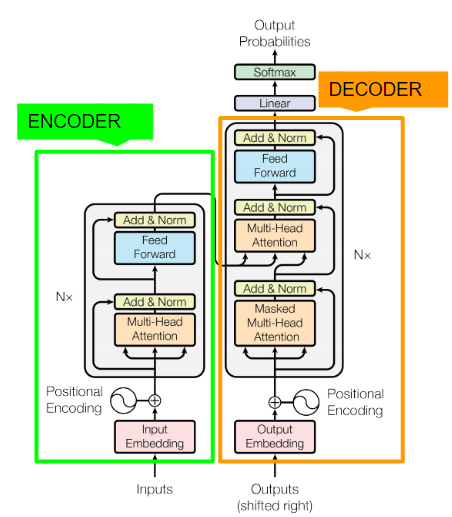
Encoderの構造
1.Embedding層によって入力文章を512次元のベクトルに圧縮
2.Positional Encoder層によって位置情報を付加
3.Multi-Head Attention層でSelf Attentionを計算し、データ内照応関係を付加
4.各種Normalizationを行う
5.Point-wise順伝播ネットワーク(PFFN)で活性化関数を適用
6.各種Normalizationを行う
3〜6を6層繰り返します
Decoderの構造
1.Embeddingレイヤによって入力文章を512次元のベクトルに圧縮
2.Positional Encoder層によって位置情報を付加
3.Masked Multi-Head AttentionでSelf Attentionを計算し、データ内照応関係を付加
4.各種Normalizationを行う
5.ここまでの出力をQueryに、Encoderの出力をKeyとValueにしてMulti-Head AttentionでAttentionを計算し、異なる時系列データの照応関係情報を獲得
6.各種Normalizationを行う
7.PFFNで変換
8.各種Normalizationを行う
3〜8を6層繰り返します
予測のための構造
最後に、線形変換+softmaxで各ラベルの予測確率を計算して、予想される翻訳を出力します。
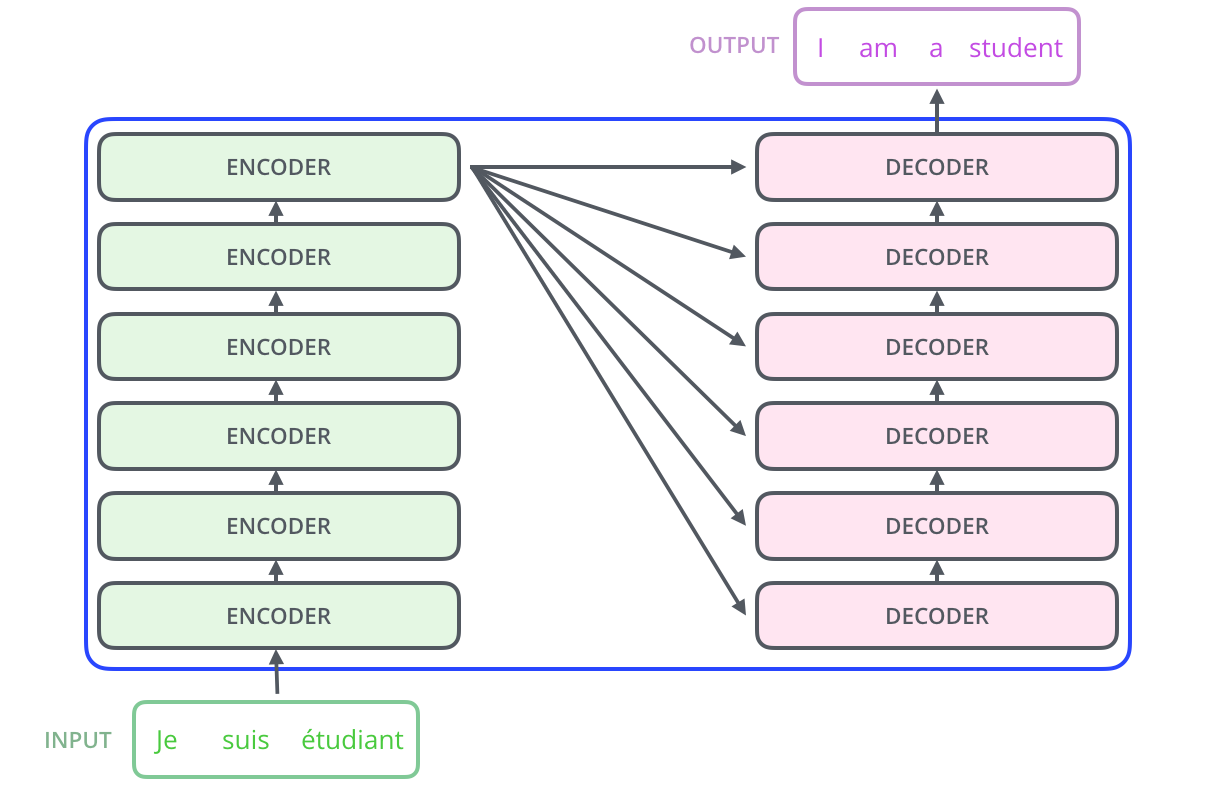

Transformer: A Novel Neural Network Architecture for Language Understanding
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Transformerのポイントとなる層
①PositionalEncoding層(単語の位置情報を埋め込む層)
②Attention層
・Self-Attention層(入力文章内の照応関係(類似度や重要度)を獲得する層)
・MultiHead-Attention層(アンサンブル学習の様にすることでSingle-Self-Attention層だけのときよりも取りこぼしを少なくします)
・Masked Multi-Head Attention層(PositionalEncoding層によって受け取ってしまう情報を隠す=カンニングの様な状態になることを避けるため)
・Source‐Target‐Attention層(異なる文章同士の照応関係(類似度や重要度)を獲得する層)
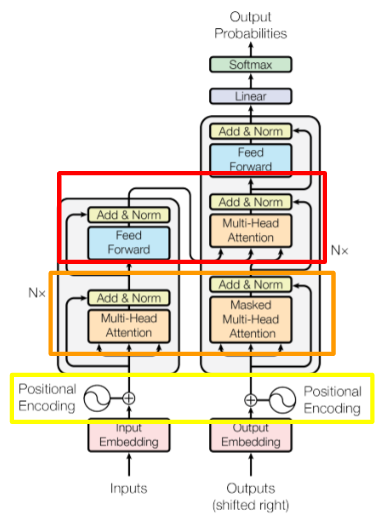
Transformer各種仕組み詳細
Transformerを特徴づける各種の工夫について層ごとに説明します。
PositionalEncoding層
Transformerは計算の高速化を妨げていたRNNを利用しない選択をしました。しかし、そのことはそれまでRNNが担っていた文脈(データ同士の長期依存関係)を取得できなくなることを意味します。
PositionalEncoding層はそうした問題を解決するために導入された仕組みで、各要素に「n番目」というような文中の位置が一意に定まる情報を付与します。そのことで、各要素データを並列処理したとしても、もともと入力データが持っていた文章上の前後要素との関係情報を維持できるようにしました。つまり、Attentionによって意味的つながりが付与され、PositonalEncodingによって文章上の位置的つながりが付与されることになります。
実際には、周波数が異なるsin関数・cos関数をの値をベクトルに埋め込むことで、位置情報を与えています。
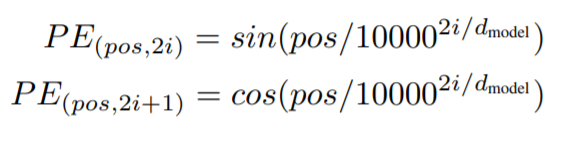
なお、学習・推論を並列処理することで大幅に高速化できる利点はありますが、一方で大量のメモリを消費することにもなります。
Attention層
Self-Attention
Self-Attentionはそれまで異なる時系列データ間で行われていたことを、同じ入力データ内でも行うことでより適切な単語照応関係を把握することを可能にしました。RNNのように逐次的に照応関係を把握せず、個々のデータがデータ全体の照応関係を並列的に参照するため、より広範囲の照応関係も把握することができるようになりました。
Self-Attentionを使うメリットは具体的には以下の4つにあるといえます。
①RNNを使わないことで並列計算が可能になります。
②計算量も小さくなります。
③広範囲の照応関係を学習可能とします。
④高い解釈可能性を有します。
Self-Attention層はSeq2Seqなどで付随される形で利用されていたAttention層(異なるデータ間の照応関係を獲得する)とは異なり、入力データ内の単語同士の照応関係情報(類似度や重要度)を獲得します。
例)
従来のAttention I have a dog. ⇔ 私は犬を飼っています
⇒このとき、例えば「I」は、特に「私」や「飼っています」との照応関係を獲得する
Self-Attention I have a dog. ⇔ I have a dog.
⇒このとき、例えば「I」は、特に「I」、「have」との照応関係を獲得する
Self-Attentionを行うことで同一文章内の類似度が獲得され、特に多義語や代名詞などが実際はなにを指しているのかを正しく理解することができるようになりました。
具体的には、以下のように照応関係が獲得されています。(類似している文章でも、正しく代名詞のもととなる単語が照応されていることがわかります。)
例)The animal didn’t cross the street because it was too tired.
⇒このときの「it」は「animal」
The animal didn’t cross the street because it was too tired.
⇒このときの「it」は「street」
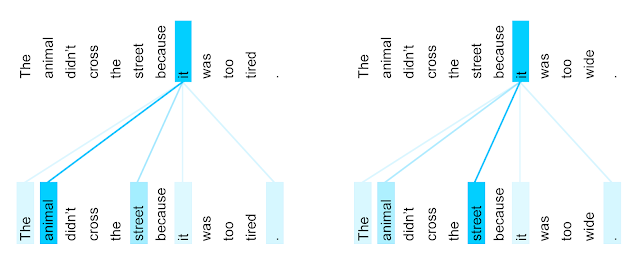
Transformer: A Novel Neural Network Architecture for Language Understanding
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
実際には以下のような動作を経て、照応関係情報を獲得しています。
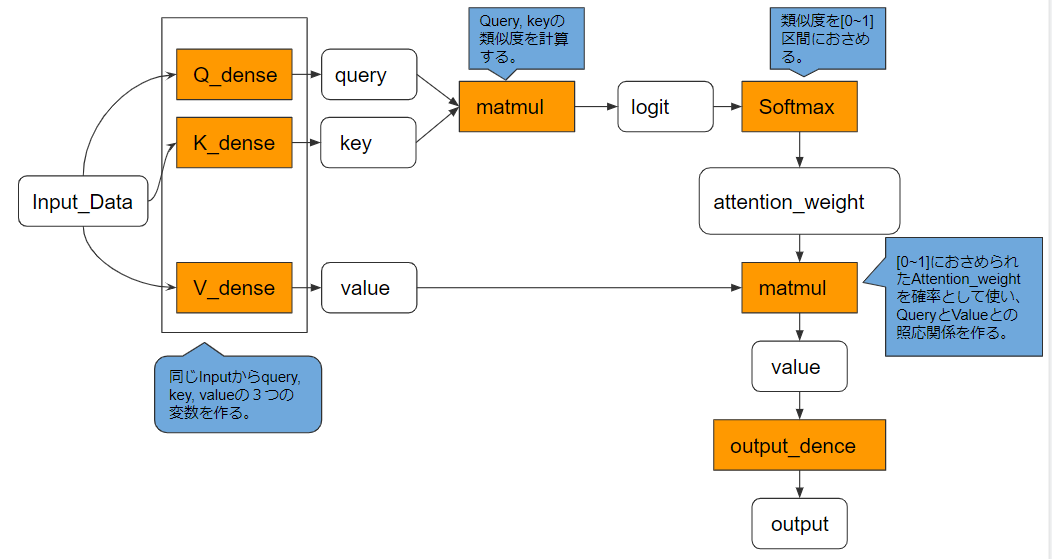
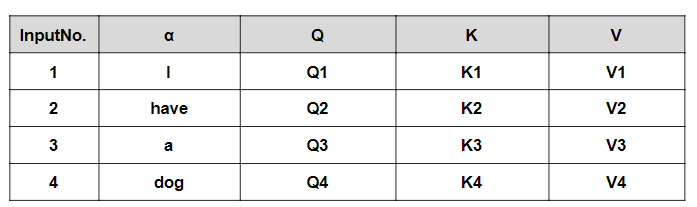
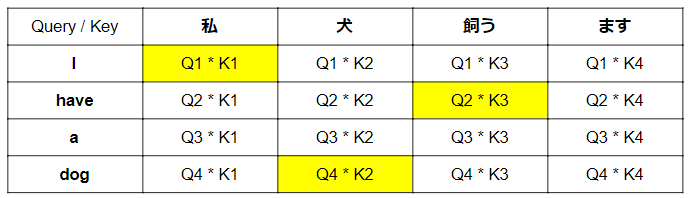
Self-Attention層では、一つの入力からQuery、Key、Valueの三つの変数を形成することになります。実際には、入力データをα、それぞれの重みをとして、Query=Q、Key=K、Value=Vとすると、
Qn = Wq * αn
Kn = Wk * αn
Vn = Wv * αn
のように計算されています。
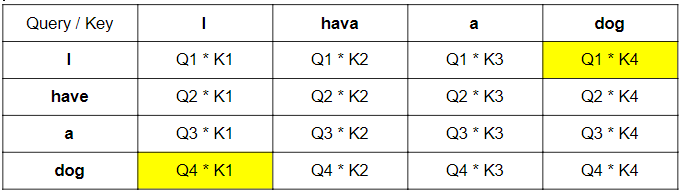
上記のように取得されていきます。
厳密には異なりますがイメージとして以下のような計算がなされ、Valueが照応されることになります。検索もと(Query)と検索先(Key)が同じ単語の場合一見すると同じ値になるような気がしますが、下記図でわかるように計算に使っている変数が異なるため、異なる値が算出されます。
例)「I」と「dog」の照応関係は、「I」を検索もとにすると、Q1 * K4のように獲得されますが、「dog」を検索もとにすると、Q4 * K1と獲得されていることがわかります。
Attentionスコアを支える類似度
それぞれの単語の類似度(照応関係に反映される)を判定する方法はいくつかありますが、論文中でも紹介されている方法としてはAdditive AttentionとDot-Product Attention(Multiplicative Attention)があります。(イメージとしては、ベクトルがどれくらい同じ方向を向いているかで判定しているようなものですが、厳密には異なります)
①Additive Attention
重みをかけたQueryとKeyを加算したものを活性関数で出力することで求めます。メリットとしてはQueryとKeyの次元が同じ数になっていなくても問題が生じません。
②Dot-Product Attention(Multiplicative Attention)
QueryとKeyの内積で求める方法です。一般にこちらの方がパラメータが必要なく (故にメモリ効率も良く) 高速です。ただし、深さの次元数が大きくなりすぎると、内積が大きくなりすぎて、逆伝播することがうまくできなくなります。(そうなると、Additive Attentionの方が性能がよくなります。)そのため、Transformerで実際に使用されているものは、深さの次元数の平方根でスケーリングするScaled Dot-Product Attentionです。こうすることで、内積が大きくなりすぎずうまく逆伝播することができるようになります。
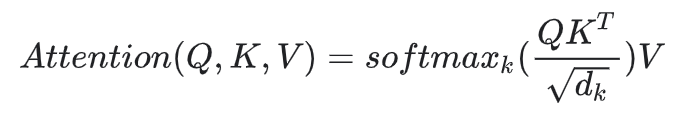
Key-Valueモデル
それまでのAttentionでは、Target、Sourceという二つの変数から照応関係をみていました。Transformerでは、Target=Query、Source=Key、Valueという三つの変数から照応関係を更に適切に反映させています。これは照応関係をただ持たせるのではなく、辞書表現のように探索用(Key)と内実用(Value)に分離して格納することで、より適切な表現力が得られるという考えに基づいています。(なお、このKey-ValueモデルはTransformerではじめて提唱された技術ではありませんが、理解しておくことでTransformerがなぜ高い精度、早い処理を可能にしているのかのイメージをつかむことができます。)
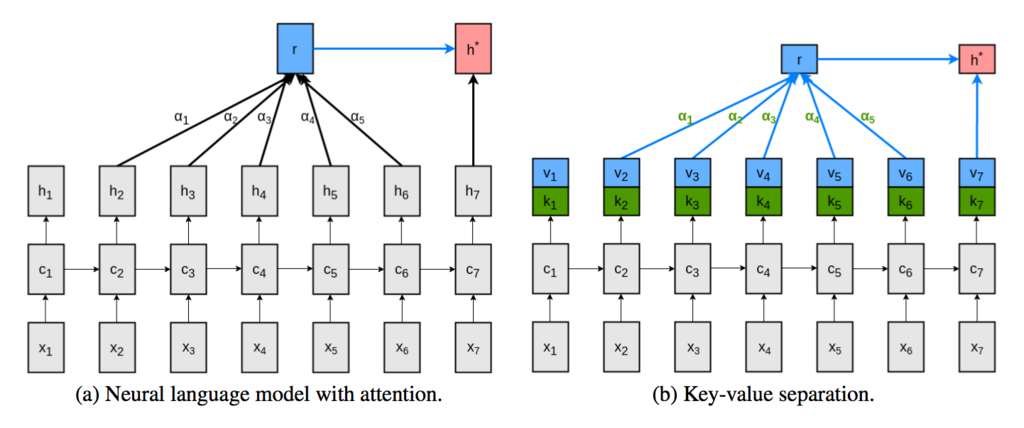
Frustratingly Short Attention Spans in Neural Language Modeling [Michał Daniluk, arXiv, ICLR, 2017/02]
それまでのAttentionで行われていた照応関係の探索の仕方は①EncoderとDecoderで獲得された各々の固定長ベクトル同士の類似度を算出し、②類似度が高いものをより強い照応関係であると判定するものです。このとき、「固定長ベクトルとは各単語の特徴を表すものである」ことが成立していることで可能となっています。これは厳密に単語同士を分離することは言語学的にも不可能であるというのが理由です。例えば、「Tom」とは何か、という説明をするためにはほかの単語(「human」など)の助けが必要なことからわかるかとおもいます。つまり、各単語そのものがほかの単語と共有している何かがあるために成り立っているのです。(そして、そもそもこのような発想のもと分散表現などは考案されています。)
しかし、それでもある単語はほかの単語とは異なるものとして存在している以上、それらを分離することのできる単語の核ともいうべき特徴があるはずでもあります。この微妙な関係性を表現したのが「Key」と「Value」という辞書オブジェクトの組み合わせであり、このことがより正確に単語同士の照応関係を参照することを可能にしたといえます。以下では各単語の類似度から照応関係を判定することの問題点、Key-Valueに分離することの利点を説明します。
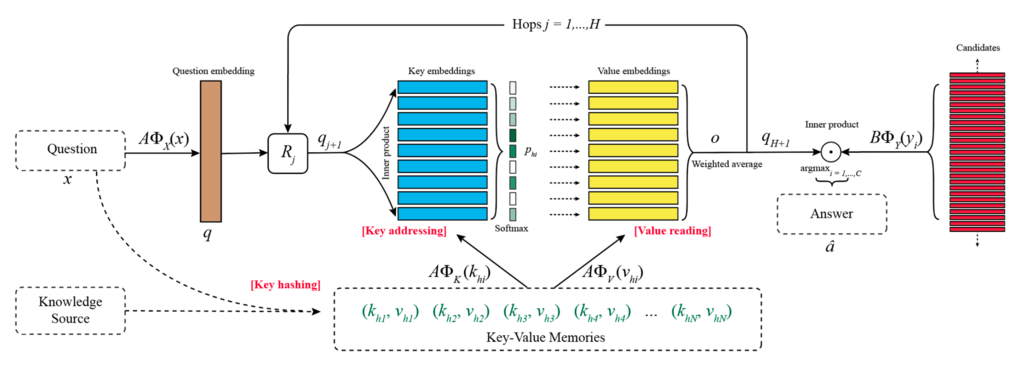
Key-Value Memory Networks for Directly Reading Documents [Alexander Miller, last: Jason Weston, arXiv, 2016/06]
「直接単語の特徴を参照する」ことで生じている問題をイメージするために、例えば、質疑応答に関する学習について考えてみるとわかりやすいです。
情報:Tom is 17years-old.
質問:Who is 17years-old?
答え:Tom.
このとき、正しい答えを導くために2つの動作が行われていると考えることができます。
①質問に対する探索
②(質問に正しく応答している)答えに対する探索
重要なことは質問に答えは含まれないということです。このとき、従来のKeyとValueが一致している場合、質問に含まれる単語(17years-oldなど)の特徴に類似しているものを探索して答えを見つけ出していました。もちろん、Tomと17years-oldの間には強い照応関係があるため、17years-oldだけの特徴を用いて質問を探し答えたとしても多くの場合正解することができます。
しかし、本来17years-oldとTomは別の概念であり、単語同士の類似性のみを根拠にして答えとすることは全体データが大きくなればなるほど不安定になっていきます。(たとえば、類似性だけであれば、18years-oldの様な表現のほうが近いかもしれません。)このときTomの側に内実の特徴(Tom自身を示す特徴)だけでなく、17yearsとのつながりを示す特徴があれば、それを参照することでより正確にTomにたどり着くことができるといえます。加えて、whoなどとのつながりを示す特徴をもつことでより正解に近づいていくことができます。
つまり、Keyとは他の単語との関係性を示すもの、Valueはその単語そのものを示すものであるといえます。無鉄砲に荒野から自分と似ているというValueを探すよりも、Keyという目印に従ってValueという答えを得る方が、より早くより適切な答えを見つけることができるようなイメージです。それゆえに、KeyとValueを設定することでより正確な検索と応答を可能にすることができる(高い表現力を獲得する)と考えられたのです。Key-Valueモデルを提唱した研究チームは「Keyは質問に一致させるのを助ける特徴をもつべきであり、Valueは応答に一致させるのを助ける特徴を持つべきである」と述べています。「(i) 自分のタスクに関する事前知識を符号化するためのより大きな柔軟性を、(ii) KeyとValueの間の非自明な変換を介したモデルのより効果的なパワーの両方を得る」ことができるとしています。
このように二つを明確に分離することでより高い表現力を獲得することが可能となったのです。
Source-Target-Attention
Source-Target-Attentionは、Self-Attentionと同様にQuery-Key-Value構造をもっています。両者の違いは、Self-Attentionが同一データ内の照応関係を獲得しているのに対し、Source-Target-Attentionは異なるデータ間の照応関係を獲得しているという点です。下図はSource-Target-Attentionのイメージ図になります。
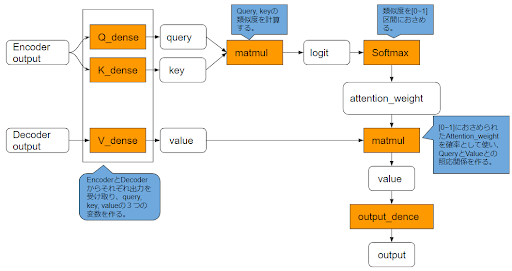
Source-Target-attentionで、異なる時系列データの照応関係をとることになります。
黄色部分のAttentionスコアが高くなれば成功といえます。
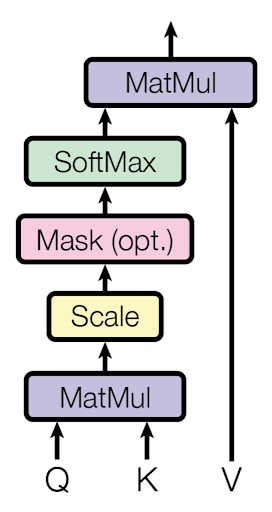
Mask 目隠し (オプション)
訓練時のデコーダでは、全ターゲット単語を同時に入力,全ターゲット単語を同時に予測することになります。そのため、入力した単語が先読みを防ぐために情報を遮断するマスクをするオプションがあります。(ただし、評価/推論時は逐次的に単語列を生成するので必要ありません。)つまり、実際にはすべての単語を利用することが可能ですが、3番目の単語を予測する際には、最初と2番目の単語のみを使用できるようにしています。(同様に、4番目の単語を予測するために、1番目、2番目、3番目の単語のみが使用されるようにします。)3番目の単語を予測するために、3番目の単語の情報を使ってしまうと、カンニングしている状態になり、柔軟性が低くなってしまいます。(そのかわり、学習が収束しやすくなります。)
実際にはSoftmax への入力のうち予測すべき単語より後にある単語に対応する部分を −∞ で埋めることで行われています。
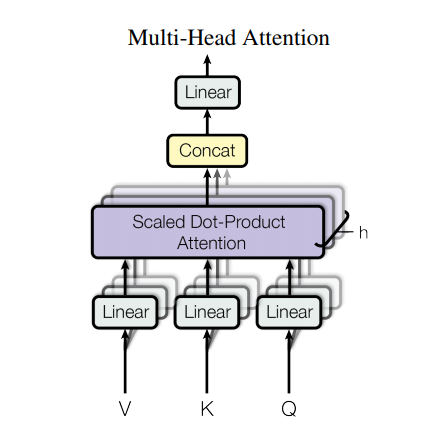
MultiHead 多種ヘッド
各単語に対してヘッド数分だけのQuery,Key,Valueの組をつくり、それぞれのヘッドで異なる組をもちいて潜在表現を計算する方法です。 最終的にそれらを1つのベクトルに落とすことで、ある単語のもつ潜在表現とします。(アンサンブル学習のようなものです。)
より具体的には、それぞれのheadの潜在表現たちをConcatし、それを重みで掛け算することで元の次元に戻してその層のOutputとしています。MultiHeadの方が単一のものより性能が高いことが知られています。これは単一ヘッドで深く潜在表現を処理するよりも、ヘッドが異なれば処理している潜在表現空間も異なるという事実からMultiHeadで複数の潜在表現空間を処理してまとめる方がより広範に豊かな情報を取ってきてくれるといえるためです。
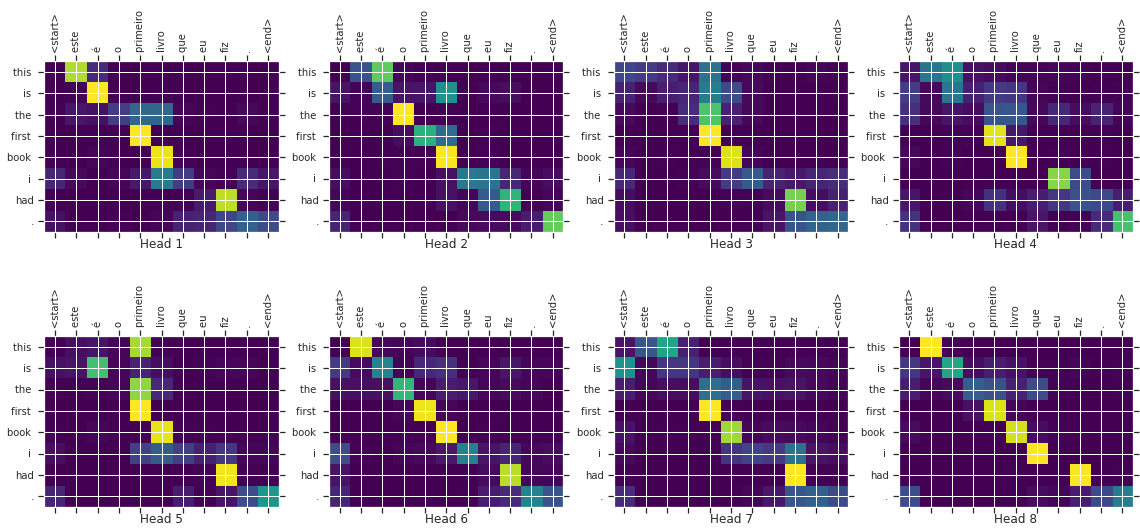
以下の図は、英語とフランス語で訓練していくなかで、得たHeadごとの照応関係を図示したものになります。各ヘッドで異なるAttentionスコアを獲得していることがわかります。最終的にこれらをまとめれば、より精度の高いAttentionスコアが得られるということです。
その他構造
Position-wise Feed-Forward Networks 位置単位順伝播ネットワーク
ReLU で活性化する dff=2048 次元の中間層と dmodel=512 次元の出力層から成る 2 層の全結合ニューラルネットワークです。位置単位で個別に順伝播ネットワークを形成することで、他単語との影響関係を排して位置情報毎に並列に処理することを可能としています。ただし、重みは共有されm全時刻で同じ変換が行われています。
この層はなくても機能すると考えられます。しかし、Self-Attention層を通過して形成された位置情報には潜在的にほかの位置情報を含んだものとなっている(ほかの位置情報と依存関係にある)ため、一度ユニークなもの(一意なもの)として整えなおす必要もあります。そのために、依存関係を考慮せずに位置単位で個別に順伝播ネットワークを作り、位置情報があらわす単語情報をユニークなもの(一意なもの)としてとらえることで表現力が増すということから追加されていると考えることができます。
。
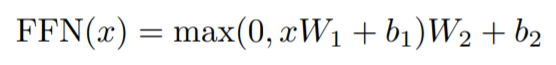
Embedding層とSoftmax層
EncoderとDecoderに用いる単語は次元dmodelのベクトルに変換するために、すでに学習されたEmbedding層を使用しています。また、通常の学習線形変換とSoftmaxを用いています。2つのEmbedding層とpre-softmax線形変換の間では同じ重み行列が共有されています。なお、Embedding層では、それらの重みを√dmodelで乗算しています。
Transformerの性能実験について
性能実験の設定
最適化関数
Adamを用いて、トレーニングの過程で学習率を変化させています。
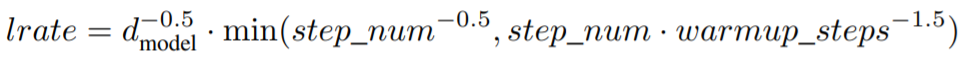
最初のwarmup_stepsで学習率を線形に増加させ、その後はステップ数の逆平方根に比例して学習率を減少させています。(実験では warmup_steps = 4000 としています。)
各種Normalization
トレーニング時には 3 種類のNormalizationを使用しています。
①Label Smoothing
Label Smoothingとは正解ラベルは一意に定まっているため、0(不正解)と1(正解)でのみ判断されますが、それだといわゆる「おしい」不正解と「的外れな」不正解も同じように処理されてしまうため、それを防ぐために行われる処理です。正解ラベルに緩さをもたせ、一意に定めないようにします。モデルは不確かなラベルを学習することになるため、パープレキシティは悪化しますが、精度と BLEU スコアは向上することが知られています。
②Residual Dropout(実験では、ドロップアウト率は Pdrop=0.1 を使用しています)
入力の加算と層正規化 (Add & Norm) 前の各層の出力にドロップアウトを適応しています。EncoderとDecoderのEmbedding層とPositionalEncodingの和にもドロップアウトを適応しています。
③Attention Dropout
Scaled Dot-Product Attention 後のsoftmaxによる活性化は、順伝播ネットワークの隠れ層の活性化と同様のものと見做すことができます。そのため、softmax の出力に対してドロップアウトを適用しています。
ハードウェアと学習時間
使用ハードウェア:NVIDIA P100 GPU × 8

結果
機械翻訳タスク
トレーニングデータ
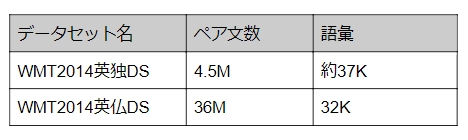
①WMT 2014年の英語からドイツ語への翻訳タスクについて
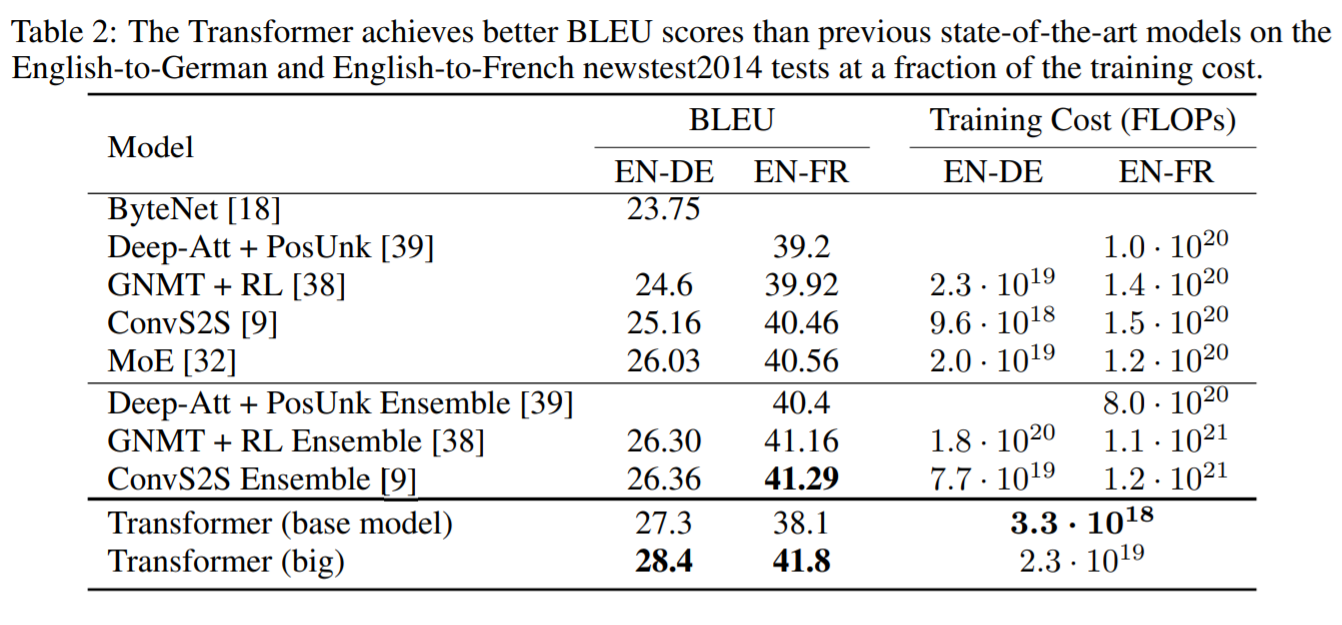
大規模モデルは、BLEUスコアでこれまでに報告された最良のモデル(アンサンブルを含む)を2.0以上上回り、28.4という当時の最高BLEUスコアを確立しました。また重要なのは競合モデルのトレーニングコストの何分の一かでこれらの結果をのこしたという点にあります。
②WMT 2014の英語からフランス語への翻訳タスク
大規模モデルでもすべてのスコアを上回るとともに、トレーニングコストは以前の最先端モデルの1/4以下に抑えることに成功したとしています。
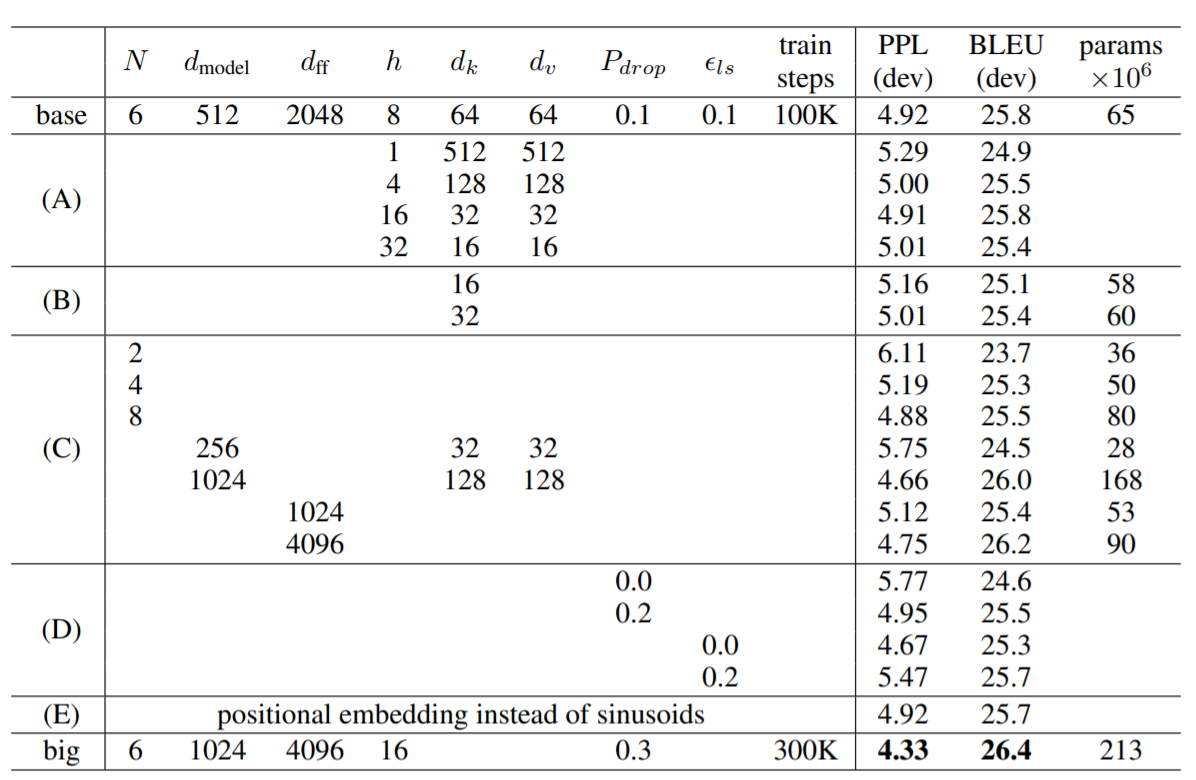
またパラメータを変更して様々なヴァリエーションを試したことで、以下の5つがわかったと報告しています。
((A)から(E)の符号は下記表と対応)
(A)ヘッドが1つの時より複数ヘッドの方が良い(ただし、ヘッド数が多すぎても逆に性能劣化します。)
(B)Key(Valueも同じ)の次元を下げると性能劣化が劣化する
⇒なお、これは類似度の判定が容易ではなく、内積をとるよりも洗練された類似度関数が有益である可能性を示唆しています。
(C)モデルサイズが大きいと性能は向上する
(D)Label SmoothingやResidual Dropoutは有効である
(E)PositionalEncoding層の代わりに位置を考慮したEmbedding層を使っても性能は変わらなかった
各種パラメータを変更したときの表
一般化対応タスク(英語の選挙区に対する構文解析実験)
Transformerが他のタスクに一般化できるかどうかを評価するために、英語の選挙区の構文解析の実験を行ったとしています。
このタスクには
①出力は強い構造的制約を受け、入力よりもかなり長くなる。
②RNNのようなシーケンスモデルは、小さなデータ領域では最先端の結果を得ることができなかった。
という課題があります。

かなりよい結果は得られたと報告しています。この実験で重要なのはWSJのトレーニングデータのみで訓練した場合でも、BerkeleyParserのようなより精度のたかい教師データをもちいて学習したモデルよりも性能が良い場合があったこととしています。このことは、基本的に学習を効率化できていることを意味しています。

まとめと所感
TransformerはAttentionのみをもちいることでモデルをシンプル化したうえで、精度と計算コストを減らすことに成功しました。
多くのモデルが精度、モデルのシンプルさ、計算コストをトレードオフのような関係性としているなかでは驚異的なことだったとおもいます。
Attentionだけでうまくいくように細かく工夫がされていることが今回、まとめていくなかでよくわかりました。
またこの論文が参考にしている多くのアイディアはべつな研究からうまれたものでもあり、改めてTransformerというものが流れのなかから生まれたことであることも実感することになりました。
今回書いた内容には誤り等が含まれている可能性もありますので、お気づきの点がありましたらお手数ですがご連絡お願い致します。
また多くの論文、個人の方が書かれたブログなどを参考にさせていただきましたので以下に記載させていただきます。
今後は、Transformerを用いた画像認識であるDETRについても紹介したいと思います。
参考
参考論文
Recurrent neural network based language model
https://arxiv.org/pdf/1508.04025.pdf
Sequence to Sequence Learning with Neural Networks
https://arxiv.org/abs/1409.3215Effective Approaches to Attention-based Neural Machine Translation
https://arxiv.org/abs/1508.04025
Frustratingly Short Attention Spans in Neural Language Modeling
https://arxiv.org/pdf/1702.04521.pdf
Key-Value Memory Networks for Directly Reading Documents
https://arxiv.org/abs/1606.03126
参考ブログ
・自然言語処理の巨獣「Transformer」のSelf-Attention Layer紹介
https://medium.com/lsc-psd/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86%E3%81%AE%E5%B7%A8%E7%8D%A3-transformer-%E3%81%AEself-attention-layer%E7%B4%B9%E4%BB%8B-a04dc999efc5
・深層学習界の大前提Transformerの論文解説!
https://qiita.com/omiita/items/07e69aef6c156d23c538
・作って理解する Transformer / Attention
https://qiita.com/halhorn/items/c91497522be27bde17ce
・論文解説 Attention Is All You Need (Transformer)
http://deeplearning.hatenablog.com/entry/transformer