
はじめに
SORT (2016) を開発した独コブレンツランダウ大学、豪クイーンズランド工科大学の研究チームが、2017年に発表した論文『SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC(DeepSort)』 を解説します。
※特に断りがない限り、図等は論文より引用しています。
『SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC』
https://arxiv.org/abs/1703.07402
SORT への理解
https://deepsquare.jp/2022/06/sort/
概要
SORT (2016) を開発した独コブレンツランダウ大学、豪クイーンズランド工科大学の研究チームは、SORT の開発により計算量をおさえることでリアルタイムでの利用を可能としました。一方で、問題点として、長期間のオクルージョンなどがあったときにIDのスイッチングがよく起きてしまい、精度が悪化してしまうことが問題視されていました。
それらの問題点を改善したモデルとして、2017年に『SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC(DeepSort)』 を発表しました。
これは文字通り、ディープラーニングを用いて外見情報をRe-IDように利用したマッチングをSORTに組み込んだモデルで、大幅にIDのスイッチを減らすことに成功しました。
ポイント
・SORT をベースとして、Re-IDのデータセットで事前学習させたDeepモデルを利用して、外見の一致度もマッチングに組み込んだモデルDeepSORT を開発した。
・長期間のオクルージョンなどでも追跡を可能とした。
・IDのスイッチをおさえることができた。
詳細
開発背景
これまでのアルゴリズム
これまでのトラッキングアルゴリズム(「flow network formulations」「probabilistic graphical models」など)は、トラッキングをグローバル最適化問題として、ビデオ全体でバッチ処理するように行っていました。これらのモデルの問題点は、オンラインでのリアルタイム処理できないという点にあります。
その後、JPDAFやMHTなどのオンラインで処理するモデルが開発されました。JPDAFは、1個の状態仮説のみが、外見の類似度によって重みづけされた個々の計測によって生成されるモデルです。MHTは、すべての可能仮説がトラッキングされるが、計算負荷の関係から削減される必要があるという問題点があります。両者は検出精度などの向上もあり、トラッキング精度としては実用に耐えうる程度には向上していますが、依然として実装時の複雑性と計算量の増加という問題を抱えていました。
SORT の開発
SORT の開発でオンライントラッキングや高いフレームレイトのときに良い精度が出せるようになりました。SORは、カルマンフィルターで物体の動きを予測し、ハンガリアンアルゴリズムで、予測した物体と検出した物体のIoUを計算し、突合することで、トラッキングを行います。
SORT の問題点
SORT の問題点は、オクルージョンなどがあると、簡単に ID のスイッチが起きてしまう点にありました。これは、状態推定の精度に不安がないことを前提としているためです。
SORTの改良目標とDeepSORT
SORT のマッチングがあくまでカルマンフィルターの予測位置との近さにあったことを反省し、動きと外見情報を利用したものに変えることを目指しました。Re-ID データセット学習された CNN を利用することで、簡単に実装でき、オンライン利用できる処理速度を維持しながら、ミスやオクルージョンに対してロバストにすることが可能となりました。
DeepSORT
トラッキングと状態推定
DeepSORT では、以下の情報を保持して、トラッキングと状態推定を行います。
●保持情報: (u, v, γ, h, x,˙ y,˙ γ, ˙ h˙)
(u, v):中央座標
γ :アスペクト比
h :高さ
+相対速度
●設定値
ak :最後に突合が成功した計測からのフレーム数、次の突合まで加算され、加算された0に戻す。
Amax:事前設定する値で、トラック候補を維持し続ける最大値
定速の動きを前提とするカルマンフィルターと線形観察モデルを利用して、次の位置を予測します。新しいトラッキング候補は、既存のトラッキング候補のなかで突合できるものがいないとき、生成されます。新しい候補は、最初の3フレームは暫定的なものとして扱われ、3フレーム後に決定されます(3フレーム内に継続して突合されないものは、トラック対象としては削除されます)
アサインメント
次に既存のトラッキング物体と検出された物体同士をどのように結びつけるかを説明します。
●マハラノビス距離
カルマンフィルターで予測した状態と新しい計測値の間のマハラノビス距離を計測し、モーション情報を組み込みます。
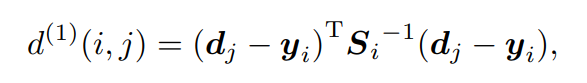
i :トラッキング
j :バウンディングボックス検出
(yi ,Si) :計測値
マハラノビス距離は、検出が平均トラック位置からどれだけ離れているかを測定することにより、状態推定の不確実性を考慮に入れます。さらに、このメトリックを使用すると、逆χ2分布から計算された95%の信頼区間でマハラノビス距離をしきい値処理することにより、ありそうもない関連を除外することができます。
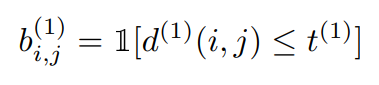
トラックキングしたものと、検出したものが突合してよいとなれば、1となります。
マハラノビス距離の閾値 t(1) は、実験で 9.4877 がよいとされています。
マハラノビス距離は、モーションの不確実性が低い場合には、安定したアサインメント指標となります。しかし、観察に問題がある場合、カルマンフィルターによる予測値がおおよその値しか示せないため、不安定になっていきます。
●コサイン距離:コサイン類似度(外見情報を利用する)
バウンディングボックスの検出 dj ごとに、|| rj || = 1の外観記述子 rj を計算します。さらに、各トラック k に関連付けられた最後のLk=100の外観記述子のギャラリーを保持します。
外観空間でのi番目のトラックとj番目の検出の間の最小コサイン距離を測定することで、外見の類似度を計算します。
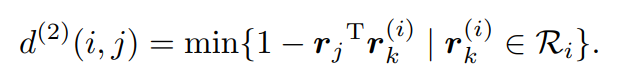
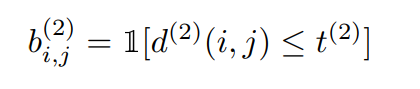
●両者の組み合わせ
両方のメトリックを組み合わせて利用することで、互いに補完し合います。 マハラノビス距離は、短期間の予測に特に役立つ、動きに基づいて可能なオブジェクトの位置に関する情報を提供します。 一方、コサイン距離は、動きの識別性が低い場合に、長期間のオクルージョン後にIDを回復するのに特に役立つ外観情報を提供します。
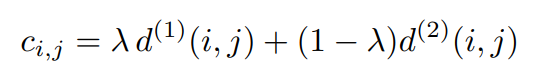
λで考慮する情報のバランスを制御します。
※ただし、実験では、λ=0:カメラ情報が安定している場合は、よい選択となることがしめされています。これはマハラノビス距離を利用していないことを意味しますが、カルマンフィルターによって推測された可能性のあるオブジェクトの場所などが実行不可能な割り当てであり、無視する必要がある場合などは有効となると研究チームは指摘しています。
マッチングカスケード
グローバル割り当て問題で測定とトラックの関連付けを解決する代わりに、一連のサブ問題を解決するカスケードを導入します。
・現状の問題点と導入理由
オブジェクトが長期間オクルージョンされている場合、カルマンフィルターの予測したオブジェクトの位置の不確実性が高まります。その結果、確率質量が状態空間に広がり、観測尤度のピークが少なくなります。(つまり、確実性が下がっていることを意味します。)
直感的には、この確率質量の広がりにあわせて、マハラノビス距離ものびることが期待されます。しかし、直感に反して、2つのトラックが同じ検出をめぐって競合する場合、マハラノビス距離は、予測されたトラック平均に対する検出の標準偏差の距離を効果的に短縮するため、より大きな不確実性を優先してしまいます。
これは、トラックの断片化が進み、トラックが不安定になる可能性があるため、望ましくない動作であると言えます。そのため、より頻繁に見られるオブジェクトを優先するマッチングカスケードを導入します。
マッチングアルゴリズムの概要

入力として、トラックTと検出Dのインデックスのセット、および Amax (候補を継続させる期間)を渡します。
1行目と2行目:関連付けコストマトリックスと許容可能な関連付けのマトリックスを計算します。
3行目と4行目:初期化します。
以下、トラックの計測フレーム数 n を繰り返し処理して、計測数が増加するトラックの線形割り当ての問題を解決します。
6行目:最後のnフレームの検出に関連付けられていないトラックTnのサブセットを選択します。
7行目:Tnのトラックと一致しない検出Uの間の線形割り当てを解決します。
8行目と9行目では、一致と不一致の検出のセットを更新します。
※この一致カスケードは、計測数の少ないトラック、つまり最近見られたトラックを優先することに注意が必要と指摘しています。
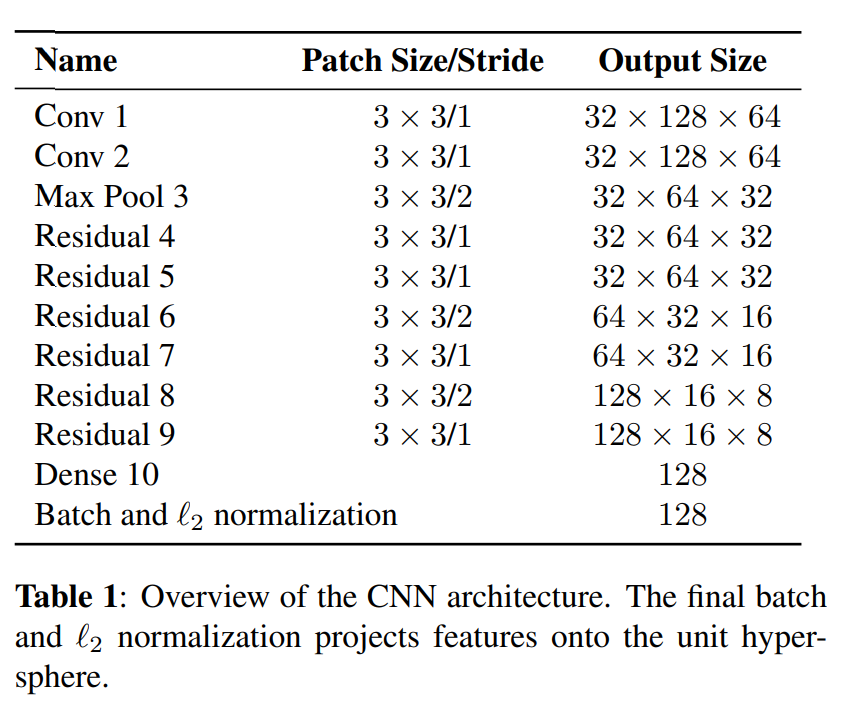
Deep を利用した外見情報を利用するモデルの詳細
追加のメトリック指標を利用する際に、計算量を抑えるために事前学習させたモデルを利用する必要があります。そのために、1,261人の歩行者の1,100,000を超える画像を含む大規模な個人再識別(Re-ID)データセッでトレーニングされたCNNを採用し
ています。
実験
MOT16ベンチマークデータセットで DeepSORT のパフォーマンスを評価しています。検出モデルはすべてのトラッカーで同様のものを利用しています。
テストでは、λ=0およびAmax=30フレームを使用して実行されました。検出は0.3の信頼スコアでしきい値処理されています。
評価指標
•マルチオブジェクト追跡精度(MOTA):誤検知、誤検知、およびIDスイッチに関する全体的な追跡精度の要約。
•マルチオブジェクト追跡精度(MOTP):グラウンドトゥルースと報告された場所の間のバウンディングボックスのオーバーラップに関する全体的な追跡精度の要約。
•ほとんど追跡(MT):トラッキング期間の80%以上にわたって同じラベルを持つグラウンドトゥルーストラックの割合。
•ほとんど失われた(ML):トラッキング期間の最大20%で追跡されたグラウンドトゥルーストラックの割合。
•IDスイッチ(ID):グラウンドトゥルーストラックの報告されたIDが変更された回数。
•フラグメンテーション(FM):検出の欠落によってトラックが中断された回数。
結果
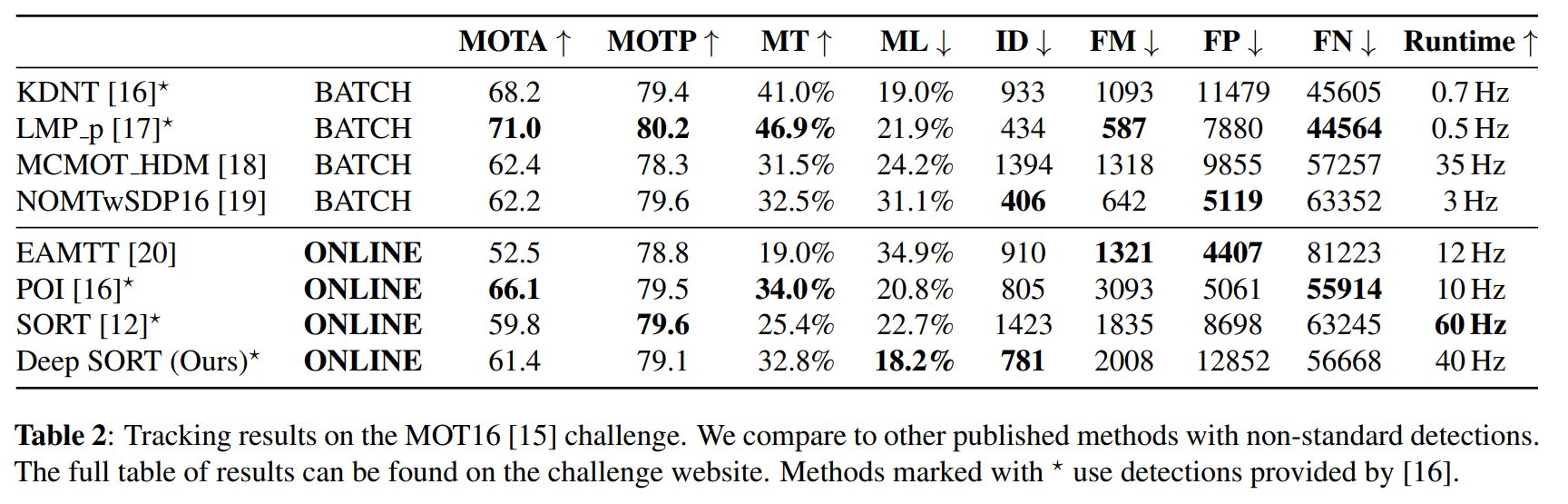
IDスイッチの数を減らすことに成功しました。(SORTと比較して、IDスイッチは1423から781に減少します。)同時に、オクルージョンやミスによってオブジェクトのアイデンティティを維持するため、トラックの断片化がわずかに増加します。また、ほとんど追跡されているオブジェクトの数が大幅に増加し、ほとんど失われているオブジェクトが減少しています。全体として、外観情報の統合により、より長いオクルージョンを通じてIDを維持することに成功しました。
DeepSORT の実装は約20Hzで実行され、機能の生成に費やされる時間の約半分が含まれます。したがって、最新のGPUを考えると、システムは計算効率を維持し、リアルタイムで動作します。(現在のGPUの精度から考えると十分にリアルタイムで処理することが可能です。)
まとめ
DeepSORT の発表により、よりオクルージョンに強くなり、現実でも利用可能となりました。その後、