
「Decoding speech from non-invasive brain recordings」は2022年8月25日に米国のCornell大学によりarxivに掲載されたものです。非侵襲的脳波計を用いて測定した脳活動から、深層学習モデルを利用することで、自然言語を再現することを目的とした論文です。なお、この記事の画像はすべて下記論文より引用しています。
参照論文:「Decoding speech from non-invasive brain recordings」
参照URL:https://arxiv.org/abs/2208.12266
概要
脳波解析から言語を測定することは様々な分野において長い間の目標とされてきましたが、近年侵襲的な脳波計(頭蓋内に直接電極を埋め込み脳波を測定する)の利用によって文字や単語を測定することが可能になりました。
しかし、依然として日常的に利用される自然言語を測定するという課題は解決されていません。また侵襲的な脳波計は手術などが必要で、身体負荷が大きいという課題も残っていました。
そこで本論文では非侵襲的脳波計(頭に装着し、脳を傷つけることなく脳波を測定する)によって測定される脳波を用いて自然言語の特定を可能とする深層学習モデルの提案が行われています。提案されたモデルを利用した実験では169人の被験者に対して、自然言語を聞いている間の脳波から、44%の精度で音声を再現することができたとのことです。
詳細解説
方法
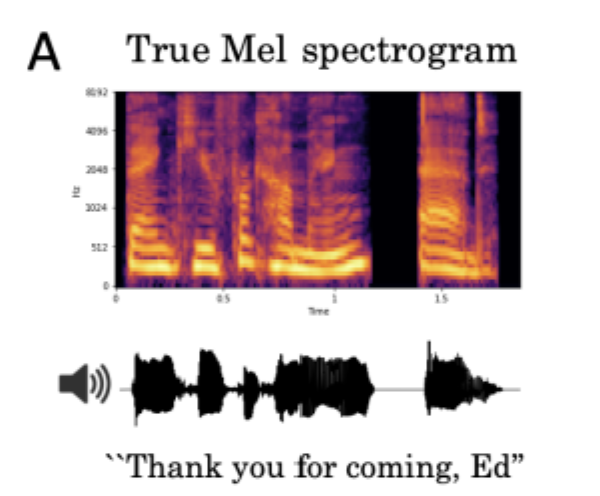
話し言葉が脳内でどのように処理されているかというのは未だ多くのことが知られていません。そのため、脳波解析では一般的に、メルスペクトログラムで脳波データを収集したのち、教師あり学習を利用して音声データと脳波データの特徴の対応付けを行います。しかしながら、この方法を用いた本実験ではいくつかの課題に直面しました。下図のように音声に対して脳波から再現された予測は、区別ができないほど広い範囲に広がっていたのです。この課題に対して、本実験では3つの試みを行いました。
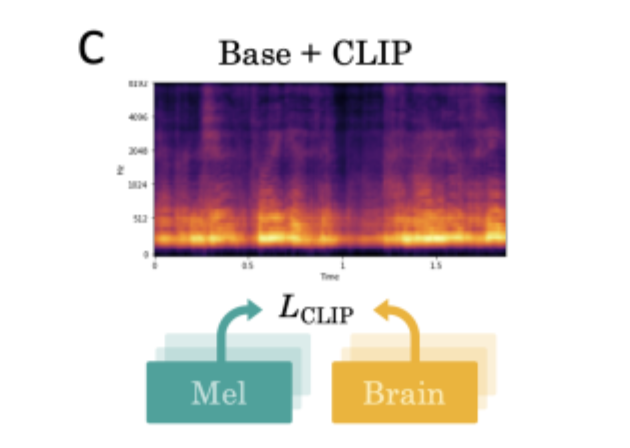
まず、従来の方法は脳内でどのように音声が表現されているかを知るものであり、脳波から音声を再現することを目的とした本実験には効果的でないと考えました。そこで「CLIP損失」と呼ばれる、もともと画像とテキストの関連を表現するために設計された概念を導入したのです。その結果、下図のようにオレンジ部分の反応範囲が狭まり、改善が見られました。
次に、今まで用いられてきたメルスペクトログラムは音声表現のレベルが低いことから、本実験で用いる自然言語の豊富な表現を再現するには適していないと考えました。そこで
「wav2vec 2.0」と呼ばれる独立した自己教師付きの音声モデルを導入しました。
さらに本実験では「fclip」と呼ばれる深層ニューラルネットワークを利用して脳波の分析を行いました。fclipでは従来の回帰損失に代わりCLIP(Contrastive Language-Image Pre-training)損失を用いています。CLIPはもともとテキストと画像の対応づけを予測するために開発されたモデルであり、この手法では、まず測定された脳波データXに対して音声データY(正解データ)を用意します。さらにN-1個の不正解データYjを用意したのちN番目に正解データYを加えたものをデータセットとします。このデータセットにおいて、脳活動Xを潜在表現Zに対応付けするモデルfclip(Z = fclip(X))を訓練します(図3)。この手法により、未学習のデータに対する予測、つまり被験者によって異なる脳波パターンを考慮した分析が可能になりました。このときの推定確率は以下の数式であらわされます。
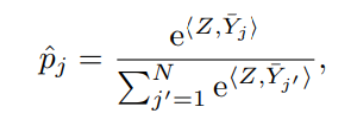
また、本モデルは交差エントロピー誤差を損失関数として訓練されており、十分に大規模なデータセットでは、簡略化された以下の式で算出されます。
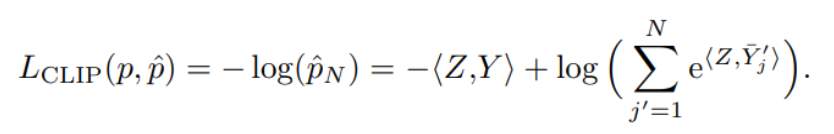
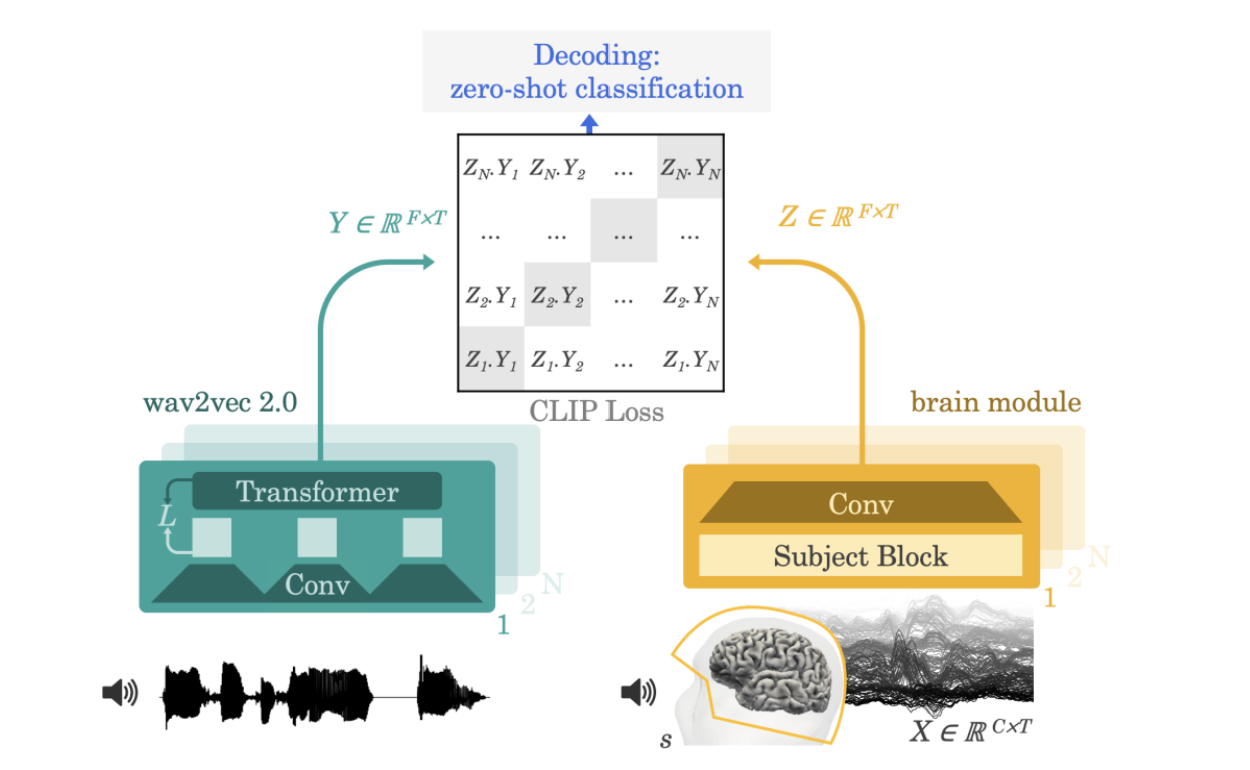
また、上図にある brain module では下図のようなアーキテクチャが用いられています。
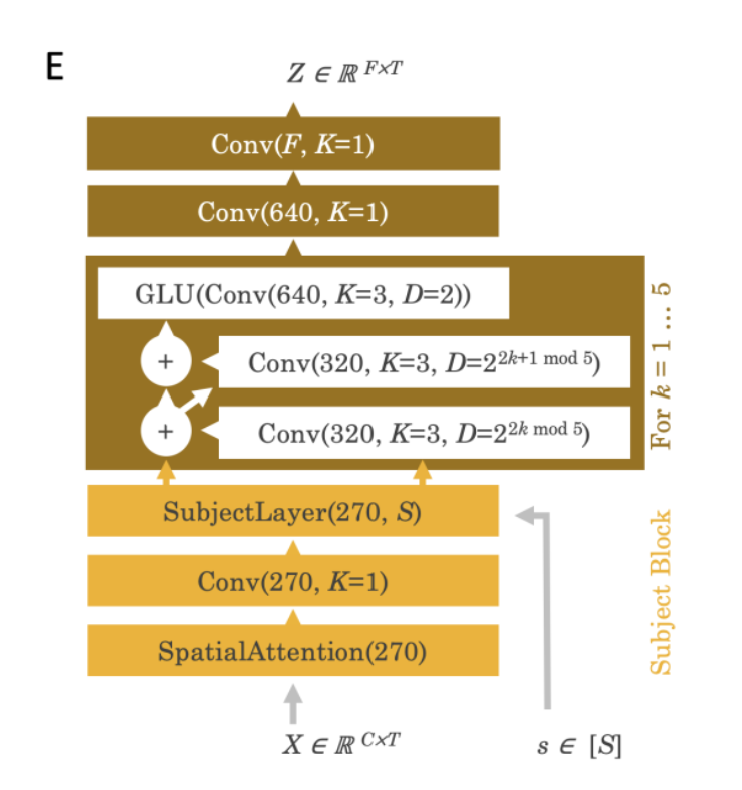
脳波データはまず、センサーの位置に基づいた SpatialAttention 層によって再マッピングされ、二次元平面上に投影、正規化されます。そして入力チャンネルはチャンネルごとにセンサー位置入力(x,y)をもち、出力チャンネルは以下の式であらわされる、フーリエ空間によってパラメータ化された aj に属します。
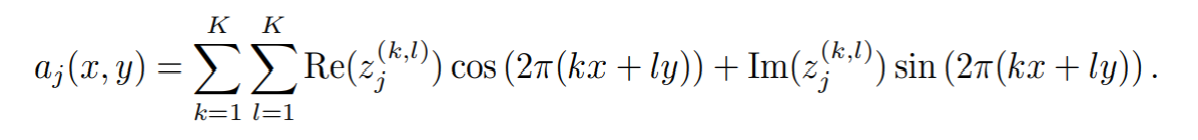
この aj と位置入力(x,y)をもちいて、出力としての空間的注意(SA)は以下の式であらわされます。
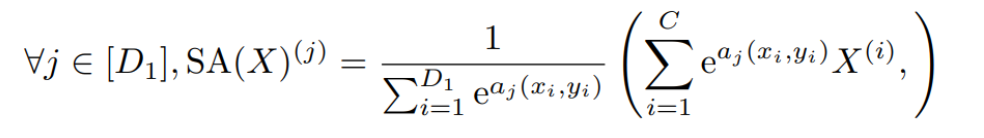
結果
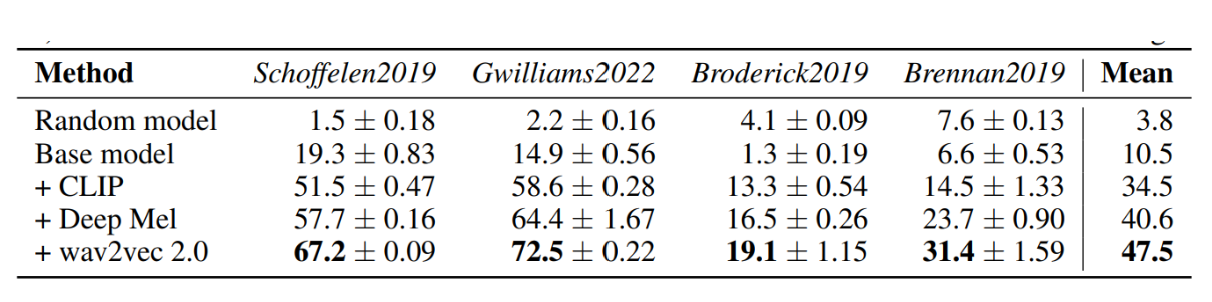
上の表は様々なモデルでデータセットを学習した際の精度をあらわしています。schoffelen2019のデータセットで本実験モデルを用いると、1000単語の選択肢から約67%の精度で正しい単語を予測することができます。一方、ランダムモデルと呼ばれる語彙分布から予測するモデルで同様の実験を行った結果の精度は1.5%程度であり、本モデルの精度をはるかに下回っています。またベースモデルと呼ばれる回帰目的関数を用いた従来のモデルでの精度は19%程度であり、本モデルが他モデルと比べ精度が高くなっていることがわかります。ほかのデータセットについても同様の結果が得られ、すべて平均した精度においても、本実験モデルの精度47.5%が最も高い結果となっています。
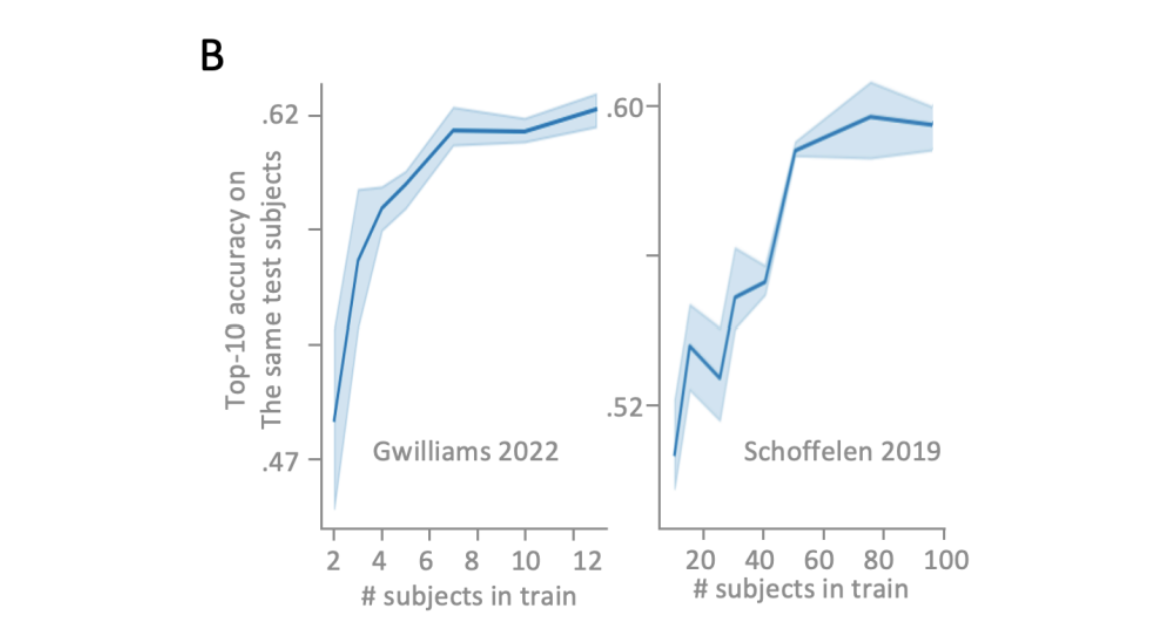
さらに、異なる被験者間におけるモデルの汎用性を調べるため、多数の被験者のデータを用いてモデルを訓練し、上位10%の被験者から得られた精度を計算しました。下図Aは、最初の3名の被験者による実験を通して、予測精度がどれだけ向上したかを示しています。被験者は「Thank you for coming, Ed」という文章を聞き、正しく予測できた単語は青色、間違いの選択肢は黒色で示されています。また、可能性の高い単語はより大きく表示されています。本モデルが訓練するに従い、正解の単語を高い確率で予測できていることがわかります。さらに被験者を増やすと下図Bのように顕著な精度の向上が見られます。

考察
本論文では、最後に提案手法の限界や今後の展望について述べられています。
まず、本実験では短い単語を用いた再現を行っており、複雑な文の解析には不十分であるという課題が挙げられます。しかし、この手法が異なる被験者間で利用可能であることから、異なる言語や文化背景を持つ人々の情報伝達ができる可能性についても論じられています。さらに、今後の課題の解決策として、より多くの被験者や長い単語を含むデータセットの収集が提案されています。
まとめ
本論文によって、今まで不可能だった非侵襲型脳波計を用いた音声再現が可能になりました。まだまだ日常会話をそのまま脳波から翻訳するには課題がありますが、非侵襲型脳波計を用いて気軽にテレパシーのような情報伝達ができる未来も近いのではないのでしょうか。