はじめに
2022年に Meta AI の研究チームから、新たな動画生成モデル「 Make-A-Video 」が発表されました。このモデルは、 Text-Video の データ無しで Text から高品質な Video を生成することを可能にしました。
※記事内の図等は特に断りがない限り、当該論文から引用しております。
『Make-A-Video: Text-to-Video Generation without Text-Video Data』
https://arxiv.org/pdf/2206.14651v1.pdf
概要
今回発表された「 Make-A-Video 」は「 Text-to-Image(T2I) 」生成モデルを「 Text-to-Video(T2V) 」生成モデルに発展させたものです。テキスト-ビデオのペアデータを必要とせずテキストから直接ビデオを生成できることが大きな特徴です。加えて幻想的な表現を含む多様なビデオの生成を行えることも特徴としています。
「 Make-A-Video 」は T2I モデルにシンプルで効果的な設計を追加することで実現しました。はじめに U-Net とアテンション・テンソルを分解し、時間軸および空間軸で近似し、次に高解像度、高フレームレートの時間軸と空間軸双方のパイプラインを組み合わせる設計を行っています。
Make-A-Video は時間軸および空間軸における「解像度」等の品質はもちろん、元のテキストを表現する「忠実度」も優れたビデオを生成することを可能にしました。
詳細
1. 紹介
Text-to-Image(T2I) は、インターネット上にある何十億ものテキストと画像のペアを収集することによってブレークスルーを可能にしました。しかしながら Text-to-Video(T2V) の場合は、「同じ規模のテキストとビデオのペアデータセットを収集することが非常に困難である」という問題点がありました。
そこで Make-A-Video では教師なし学習を採用しました。教師なし学習は、自然言語処理 (NLP) の分野で成功しており、ラベル付されていないネットワーク上のデータから学習を可能とします。今回は、もともとはペアでは無いテキストとビデオデータを教師無し学習させ、テキストとビデオの関係性を学習させました。その結果、対のテキスト、ビデオのデータセットを使わずにテキストから動画を生成することが可能となりました。また、教師無しビデオはテキスト無しの静止画だけでも動きの違いを確認できます。
【参考】 T2V の出力サンプル

(a) 赤いマント付きのスーパーヒーローの衣装を着た空飛ぶ犬

(b) 本の山を照らす日光が差し込んでいる窓のそばのテーブル

(c) タイムズスクエアで踊るロボット

(d) ビーチに沿って走るユニコーン
(a) では、リアルに空を飛ぶ犬です。 (b) では、本はほとんど静止していますが、カメラの動きによってシーンが変化します。
※ビデオ サンプルは、make-a-video.github.io で入手可能です。
時間軸上・空間軸上にモデルを拡張することで、ビデオから時間的なダイナミズムを学習することを可能にしました。このことで、以前の T2I モデルで得られた情報を瞬時に現在の T2V モデルに移行することができ、 T2V モデルの学習を加速させることが可能となります。また、映像品質を向上させるために空間的超解像度モデルやフレーム補間モデルを学習させて高解像度、高フレームレートの映像作成を可能にしています。その結果、 Make-A-Video は以下のこと実現しています。
・ T2I モデルを、時間軸、空間軸上で効果的に拡張しています。
・テキストとビデオのペアデータが不要なので、より大量のビデオデータに拡張できます。
・ユーザーが入力したテキストから高精細・高フレームレートの動画を生成します。
2. 事前準備
2-1. Text-to-Image 生成
T2I はラベル無し GAN をT2I生成に拡張した最初の手法の1つです。その後、進化を遂げ DALLE 、 Make-A-Scene 、 Denoising Diffusion Probabilistic Models ( DDPMs ) 、 GLIDE 、 DALLE-2 等を生み出しています。
2-2. Text-to-Video 生成
T2I 生成の進歩は目覚ましく、それに比べて T2V 生成の進歩は大きく遅れています。これは高品質のテキストとビデオのペアを持つ大規模データセットがないことと、高次元のビデオデータのモデリングの複雑さの2つが主な理由です。そこで研究チームではオープンソースのデータセットを使用しています。
2-3. ビデオ生成のための優先画像の活用
動画をモデル化する複雑さと、高品質の動画データ収集する困難のため学習プロセスを単純化するために動画の優先画像を活用するようになりました。(画像=ビデオ1フレームに相当するため)ラベル無し学習の MoCoGAN-HD は事前学習し固定された画像から潜在空間中の軌跡を見つける方法を定式化しています。 T2V 生成の NUWA は、マルチタスク事前学習段階で画像とビデオのデータセットを組み合わせ、微調整のためのモデル汎用化を向上させています。 CogVideo は、学習時のメモリ使用量を減らすために少数の学習可能なパラメータのみで事前学習された固定 T2I モデルを使用します。しかし、固定のオートエンコーダーと T2I モデルは、 T2V の生成に制約を与えます。 VDM のアーキテクチャは、画像とビデオの結合を可能にしますが、ランダムな動画からランダムな独立した画像を画像の源としてサンプリングしており、膨大なテキスト-画像データセットを活用できていません。
Make-A-Video はいくつかの点で従来のモデルとは異なります。
(1)テキストービデオペアへの依存を解消します。
(2)モデルの重みを効果的に適応させて T2I モデルを微調整します。( CogVideo は重みを凍結しています。)
(3)擬似 3D 畳み込みと時間軸アテンション層の使用によって、 T2I アーキテクチャの活用だけでなく VDM と比較してもより良い時間軸情報の融合を可能にします。
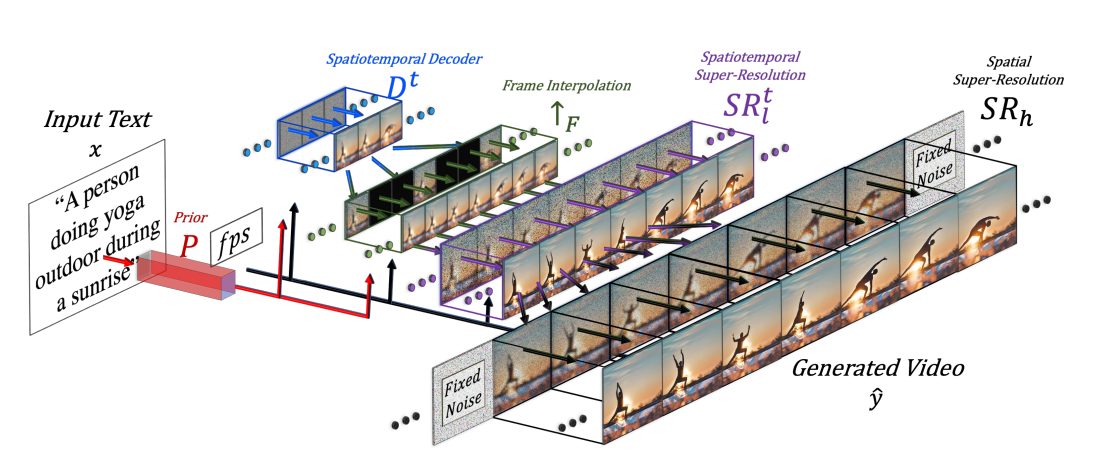
図2: Make-A-Video のハイレベル・アーキテクチャ。
デコーダ Dt は、入力テキストxが事前 P で画像埋め込みに変換されたものを、任意のフレームレート fps で 64×64 の 16 枚のフレームを生成します。↑F によって高いフレームレートに補間され、 SRtl によって 256×256 に変換されます。さらに SR h によって 768×768 に解像度アップされて高時空間、高解像度の生成ビデオ yˆ が出力されます。
3. 方法
Make-A-Video は以下の3つの主要なコンポーネントから構成されています。
(1) テキストと画像のペアで学習した基本的な T2I モデル
(2) ネットワークの構成要素を時間軸に拡張する時間軸と空間軸双方の畳み込み層とアテンション層
(3) 時空間層と、T2V生成に必要なもう一つの重要な要素である高フレームレート生成のためのフレーム補間ネットワークから構成される時空間ネットワーク
Make-A-Video は以下の式で表されます。
![]()
ここで ![]() は生成されるビデオ、
は生成されるビデオ、![]() は空間的および時間空間的な超解像度ネットワーク、
は空間的および時間空間的な超解像度ネットワーク、![]() はフレーム補間ネットワーク、
はフレーム補間ネットワーク、![]() は時空間デコーダ、
は時空間デコーダ、![]() は先行、
は先行、![]() は BPE エンコードされたテキスト、
は BPE エンコードされたテキスト、![]() は CLIP テキストエンコーダー、
は CLIP テキストエンコーダー、![]() は入力テキストを表しています。
は入力テキストを表しています。
3-1. TEXT-TO-IMAGE モデル
時間軸成分を追加する前に、基幹となる T2I モデルを訓練します。以下の3つのネットワークを使います。
(1)先行ネットワーク P :推論中に与えられた埋込テキスト xeとBPE 符号化されたテキストトークン xˆ から埋込画像 ye を生成するネットワーク
(2)デコーダネットワーク D :画像埋め込み情報 ye を条件として、64×64 RGB の低解像度画像 yˆ を生成するネットワーク
(3)2つの超解像度ネットワーク SRl,SRh :生成された画像 yˆ の解像度をそれぞれ256×256と768×768ピクセルに上げる2つのネットワーク
これらにより最終的に生成画像 yˆ が得られます。
3-2. 時空間層
2次元( 2D )条件ネットワークを時間軸に拡張するために、空間次元だけでなく時間次元も必要とする2つのキービルディングブロックとして、畳み込み層とアテンション層を修正しています。時間軸の修正は U-Net ベースで行われます。すなわち時空間デコーダ Dt は64×64の RGB 16フレームを生成します。また、新たに追加されたフレーム補間ネットワーク ↑F は、生成された16 フレームと、超解像ネットワーク SRt 間を補間することで実効フレームレートを向上させます。ちらつきが発生しないようにするには「幻覚(超高解像度化のために生成された画像情報)」がフレーム間で一貫している必要があります。そのため、 SRtl モジュールを空間軸、時間軸で動作させます。定性的な調査では、フレーム単位の超解像度化よりも優れていることがわかりました。SRhを時間軸に拡張することは、メモリやコンピューターの制約から困難なので空間軸にのみ作用します。しかし、フレーム間で一貫した「幻覚」を促すために、各フレームで同じノイズの初期化を行います。
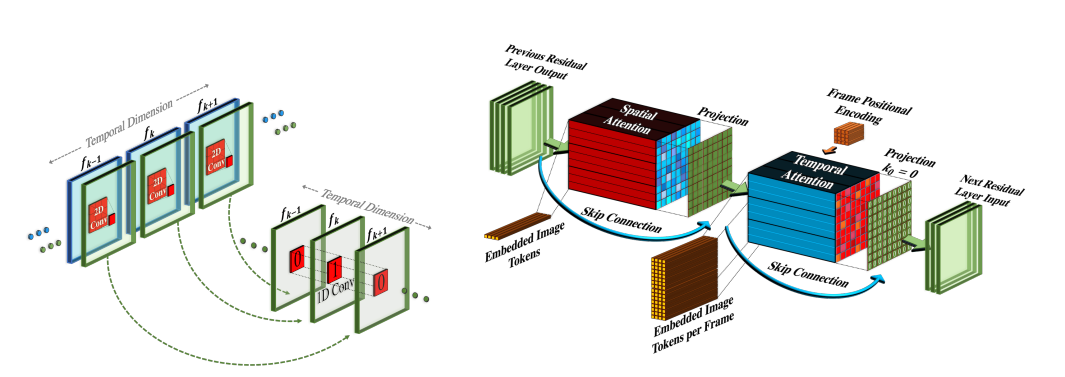
図3:擬似3次元畳み込み層とアテンション層のアーキテクチャー
初期化スキームにより、事前に学習した Text-to-Image モデルから時間軸へのシームレスな移行が可能となっている。
(左) 各空間軸 2D 畳み込み層は、時間軸 1D 畳み込み層に続きます。時間軸畳み込み層は恒等関数で初期化されます。
(右) 時間軸アテンション層は 空間軸アテンション層に続きます。
時間軸投影をゼロに初期化することにより、時間軸アテンション層が適用され、その結果、時間軸アテンション・ブロックの恒等関数が得られます。
3-2-1. 擬似 3D 畳み込み層
図3に示すように、各 2D 畳み込み層の後に 1D 畳み込みを積み重ねます。これは、 3D 畳み込みに計算負荷をかけることなく、空間軸と時間軸の間の情報共有を容易にします。学習済みの2次元畳み込み層と新たに初期化した1次元畳み込み層の間に具体的な仕切りを設けることによって、空間畳み込み層の重みに学習済みの空間知識を保持したまま、時間畳み込みをゼロから学習することが可能になります。入力されたテンソルhを
![]()
と記すと( B, C, F, H, W はそれぞれバッチ、チャンネル、フレーム、高さ、幅の次元)擬似3次元畳み込み層は以下のように定義されます。
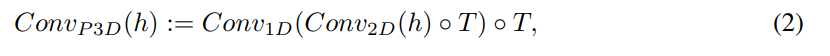
ここで、転置演算子 ◦T は空間軸と時間軸を入れ替えます。 初期化をスムーズに行うため、畳み込み 2D 層は事前に学習した T2I モデルから初期化されますが、畳み込み 1D 層は恒等関数として初期化され空間層だけの学習から時間軸と空間軸双方の層へのシームレスな移行を可能にします。なお初期化時に、ネットワークは K個の異なる画像をランダムノイズにより生成することにご注意下さい。
3-2-2. 擬似3次元アテンション層
T2I ネットワークの重要な構成要素はアテンション層です。3次元畳み込み層の使用は計算量が多く、アテンション層に時間軸を追加することは、メモリが足らないため基本的には実行不可能です。そこで次元分解戦略をアテンション層にも拡張しました。事前訓練された各空間的アテンション層に続き、畳み込み層と同様にして、時間軸アテンション層を積み重ね完全な時空間的アテンション層を近似しています。具体的には、入力テンソル h が与えられたとき、空間軸を
![]()
に平坦化する行列演算子として flatten を定義します。 unflatten は逆行列演算子として定義されます。つまり擬似3次元アテンション層は次のように定義されます。
![]()
ConvP3D と同様に、時空間的な初期化をスムーズに行うため、ATTN2D 層は事前に学習した T2I モデルから初期化し、ATTN1D 層は恒等関数として初期化します。因数分解された時空間アテンション層は、 VDM や CogVideo でも使用されています。CogVideoはそれぞれの(凍結された)空間層に時間層を追加していますが、ここでは一緒に学習しています。VDM は、画像と動画に対応した学習をさせるために、2次元の U-Net を1x3x3の畳み込みフィルタにより3次元に拡張し、空間的アテンションは2次元のままとし、相対位置埋め込みにより1次元の時間的アテンションを追加しています。これに対し、ここでは、各1x3x3の後に、さらに3x1x1の畳み込み射影を適用し、時間情報も各畳み込み層に通過させます。
3-2-3. フレームレート調整
CogVideo と同様に、T2I 条件付けに加えて、生成されたビデオの1秒あたりのフレーム数を表す条件付きパラメータ fps を追加しています。秒間フレーム数を変化させながら条件付けすることで、学習時に利用可能な映像の量が限られている場合に、追加的な補強方法を可能にします。
3-3. フレーム内挿ネットワーク
前節で述べた時空間的な修正に加えて、マスクされたフレーム補間・外挿ネットワーク ↑F を新たに学習させ、より滑らかな映像生成のためのフレーム補間、あるいは映像の長さを伸ばすための前後フレーム外挿のいずれかによって、生成映像のフレーム数を増やすことができます。メモリ等の制約の中でフレームレートを向上させるため 時空間的デコーダ Dt をマスク付きフレーム補間のタスクに微調整し、マスクされた入力フレームをゼロ・パディングすることで映像のアップサンプリングを可能にします。微調整を行う場合、 U-Net の入力に4チャンネルを追加します。つまり RGB マスクビデオ入力の3チャンネルとどのフレームがマスクされたかを示すバイナリチャンネルを追加します。推論時に複数の時間軸アップサンプリングレートを可能にするため、可変フレームスキップや fps コンディショニングで微調整します。ここで、与えられたビデオテンソルをマスクフレーム補間によって拡張したものを ↑F とします。すべての実験において、5フレームスキップで ↑F を適用し、16フレーム映像を76フレーム((16-1)×5+1)にアップサンプリングしました。同じアーキテクチャを、動画の最初や最後のフレームをマスクすることで、動画の外挿や画像アニメーションにも利用できます。
3-4. トレーニング
上記の Make-A-Video の異なるコンポーネントは独立して学習されます。テキスト入力を受け取る唯一の要素が先行処理の P であり、テキストと画像のペアデータで訓練しますが、動画では微調整を行いません。デコーダ、先行処理、2つの超解像度コンポーネントは、まず画像の上で独立して学習されます。デコーダは CLIP 埋込画像を入力として受け取り、超解像度コンポーネントはダウンサンプリングされた画像を入力として受け取ります。画像で学習した後、新しい時間軸を追加して初期化し、ラベル無しビデオデータで微調整を行います。オリジナルビデオから16フレームを1〜30のランダムな fps でサンプリングします。サンプリングにはベータ関数を用い、デコーダのトレーニングでは、高い FPS レンジ(動きが少ない)から始め、次に低い FPS レンジ(動きが多い)へと移行します。マスクされたフレーム補間コンポーネントは、時間軸デコーダから微調整されます
4. 実験
4-1. データセットと設定
データセット: 画像モデルをトレーニングするために、英語テキストのデータセットの2.3B サブセットを使用します。なお不適切な画像や文章、または電子透かしの確率が 0.5 より大きい画像を含むサンプルペアは除外します。
表1: MSR-VTT での T2V 生成評価。 ゼロショットとは、MSR-VTT でトレーニングが行われないことを意味します。 Samples/Inputs は、各入力に対して生成された (そしてランク付けされた) サンプルの数を意味します。

WebVid-10M と HD-VILA-100M からの 10M サブセットを使用して、ビデオ生成モデルをトレーニングします。デコーダー Dt と補間モデルは、 WebVid-10M でトレーニングされています。 SRtl は、WebVid-10M と HD-VILA-10M の両方でトレーニングされています。 以前の研究では、T2V 生成のためにプライベートなテキストとビデオのペアを収集しましたが、今回は公開データセットのみを使用します (ビデオにはペアのテキストは使用しません)。 UCF-101 と MSR-VTT上で自動評価をゼロショット設定で実施します。
4-1-1. 自動評価指標
UCF-101 については、各クラスごとにテンプレート文を一つ書き(動画は生成せず)、それを評価用に固定します。10Kサンプルについてフレシェビデオ距離( FVD )と Inception Score ( IS ) を報告します。トレーニングセットと同じクラス分布に従うサンプルを生成します。MSR-VTT については、テストセットの全59, 794個のキャプションを用いてフレシェ開始距離 ( FID ) と CLIPSIM (ビデオフレームとテキスト間の平均 CLIP 類似度) を報告します。
4-1-2. 人間用の評価セットと指標
Amazon Mechanical Turk ( AMT ) から 300 のプロンプトからなる評価セットを収集します。なお” Jump into water “などの不完全なもの、 ” climate change ” などの抽象的なもの、あるいは不快なものを除外しています。そして、5つのカテゴリー(動物、ファンタジー、人物、自然、風景)に絞り込み、人間による評価には、Imagen の DrawBench を使用しています。そして映像品質とテキスト-映像の忠実度を評価します。映像の品質については、2つの映像をランダムな順番で見せ、どちらが高品質かを見比べてもらいます。忠実度については、さらにテキストを表示し 、どちらの動画がテキストとよりよく対応しているかを確認します(品質の問題は無視します)。また、人間による評価によって動画像の動きのリアルさを比較しました。各比較において、5人の異なる人たちによる多数決を最終結果としました。
4-2. 定量的な結果
4-2-1.MSR-VTT での自動評価
MSR-VTT 上で報告する GODIVA と NUWA に加え、比較のために公式にリリースされた CogVideo モデルでも中国語と英語の入力で推論を行いました。 CogVideo と Make-A-Video では、ゼロショット設定で各プロンプトに対して1サンプルずつしか生成していません。また、評価モデルではそれ以上の解像度やフレームレートを想定していないため、16×256×256の動画のみを生成しています。その結果を表1に示しています。Make-A-Video のゼロショット性能は、MSR-VTT で学習させた GODIVA や NUWA よりはるかに優れています。また、CogVideo に対しても、中国語、英語の両設定で優れています。このように、Make-AVideo は先行研究よりも大幅に優れた汎用化能力を持っています。
4-2-2. UCF-101 での自動評価
ビデオ生成の評価ベンチマークとして有名な UCF-101 を使います。これは最近では T2V モデルでも利用されています。 CogVideo はクラス条件付きビデオ生成のために事前学習したモデルの微調整を行いました。 VDM は無条件で映像生成を行い、 UCF-101 で1から学習を行いました。いずれの設定も理想的なものではなく、 T2V の生成能力の直接的な評価にはならないかも知れません。さらに、 FVD の評価モデルでは、動画は0.5秒(16フレーム)を想定しており、実用のビデオ生成に用いるには短すぎます。
しかし、先行研究との比較のために、 UCF-101 を用いたゼロショットと微調整の両方で評価を行いました。表2に示すように、 Make-A-Video のゼロショット性能は、 UCF-101 で学習した他のアプローチと比較しても競争力があり、 CogVideo よりもはるかに優れていることから、このような特定のドメインにおいても Make-A-Video がよりよく汎用化できることがわかります。このことは、 Make-A-Video がこのような特殊な領域においても、より優れた汎用性を持つことを示しています。
表2: UCF-101 での動画生成評価(ゼロショット、微調整の両設定)
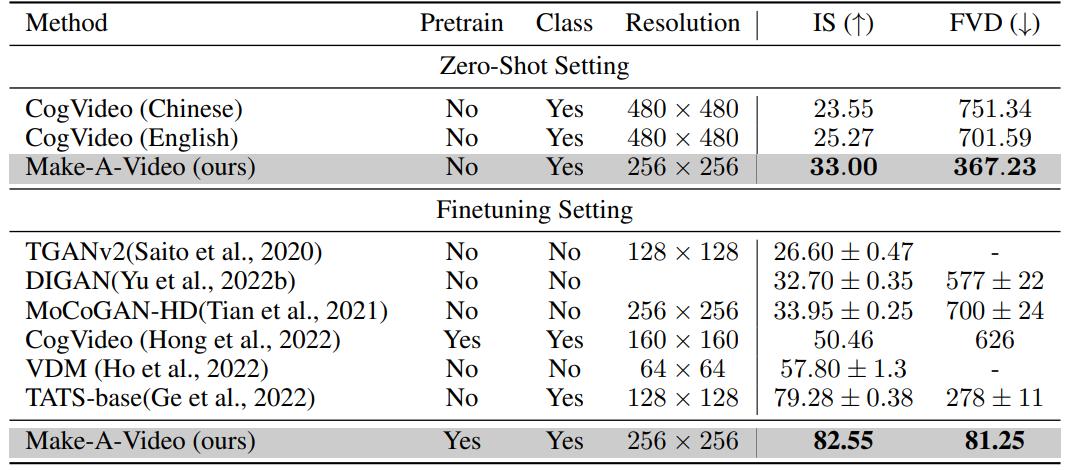
表3:CogVideo の DrawBench とテストセット、および VDM の Web サイトにある 28 の例で比較した人間による評価結果。数値は、評価者のうち、研究チームの Make-A-Video モデルの結果を好む人の割合を示しています。
4-2-3. 人による評価
CogVideo (唯一の公開ゼロショットT2V生成モデル)と DrawBench と研究チームのテストセットで比較します。また、 VDM の Web ページで公開されている 28 の動画でも評価しました。これは非常に小さなテストセットなので、各入力に対してランダムに 8 つの動画を生成し,8回評価を行い,その平均値を報告しています。また人間による評価のため、76×256×256 の解像度で動画を生成しています.その結果を表3に示します。
Make-A-Video は、すべてのベンチマークと比較して、ビデオの品質とテキストとビデオの忠実度の両方ではるかに優れた性能を達成しています。 CogVideo に対して、 DrawBench と研究チームの評価セットで同様の結果が得られています。 VDM に対して、手抜きなしで大いに改善したことは特筆すべきことです。また FILM と比較して、研究チームのフレーム補間ネットワークの評価も行いました。まず DrawBench と評価セットのテキストプロンプトから低フレームレートのビデオ( 1FPS )を生成し、次に各手法を用いて 4FPS にアップサンプリングしました。評価者は、評価セットの 62% 、 DrawBench の 54% の確率で、よりリアルな動きをする研究チームの方法を選択しました。このようにフレーム間の差が大きい場合、対象の動きに関する実際の世界の知識を持つことが重要であることを確認しました。
4-3. 定性的な結果
Make-A-Video 生成例を図4に示しています。ここでは、 CogVideo や VDM との T2V 生成比較、 FILM との映像補間比較について示します。また本モデルは画像アニメーション、映像バリエーションなど、様々なタスクに利用することが可能です。
図4:様々な比較・応用における定性的な結果。

(a)T2V生成:「夜の高速道路が混んでいる」という入力に対する、VDM(上)、CogVideo(中)、Nake-A-Video(下)の比較。

(b) 画像アニメーション:左端が入力画像で、それを動画にするためにアニメーションさせたもの。

(c)画像補間:2つの画像(左端と右端)が与えられると、フレームを補間する。 FILM (左)と Make-A-Video の(右)の比較。

(d) 映像のバリエーション:元の映像(上)に対するバリエーションとして、新しい映像(下)を生成することができます。
図4(a)は,Make-A-Video と CogVideo 、 VDM との比較です。Make-A-Video は、動きの整合やテキストの対応性など、よりリッチなコンテンツを生成することができます。
図4(b)は、マスクフレーム補間・外挿ネットワーク ↑F を画像に条件付けし、 CLIP 画像埋め込みで残りの動画を外挿した画像アニメーションの例です。これにより、ユーザーは自分の画像を使って動画を生成することができます。つまりユーザは生成された動画をパーソナライズし、直接コントロールすることが可能です。
図4(c)は、2つの画像間の補間のタスクについて、 FILM と研究チームのアプローチを比較したものです。研究チームは、2つの画像を開始フレームと終了フレームとし、その間の14フレームをマスクして生成する補間モデルを用いることでこれを実現します。 FILM は何が動いているかという意味的な実世界の理解なしに、主にフレーム間を滑らかに遷移するようにしているのに対し、研究チームのモデルはより意味のある補間を生成します。
図4(d)は映像の変化に関する例です。研究チームは、ビデオの全フレームの平均 CLIP 埋込に、意味的に類似したビデオを生成する条件としています。
その他の動画像生成例とアプリケーションはこちらでご覧いただけます:
make-a-video.github.io.
以下にその一部を参考として紹介します。
Text/Image →Video
1.A dog wearing a Superhero outfit →
2.A teddy bear painting a portrait →
3.Swimming Turtle
 →
→
5. 最後に
今回の研究は、ラベル付けされた画像とラベルのないビデオ映像を効果的に組み合わせ、教師なし学習を用いて、桁違いに多くの動画から世界のダイナミクスを学習させて実現しています。次のステップとして、動画でのみ推測可能なテキストと現象の間の関連付けを学習することはできないので、これらをどのように組み込むか(例えば、人が手を左から右、あるいは右から左に振る動画を生成する等)また、より長い動画を生成したり、より詳細なストーリーを表現するために、複数のシーンやイベントを含むより長い動画を生成する必要がありますがこれらが、今後の課題となります。