はじめに
2016年に豪クイーンズランド工科大学から発表され、現在のトラッキングアルゴリズムの基礎となっている SORT について解説します。
概要
SORT 以前のトラッキングアルゴリズムは、オクルージョンや物体検出エラーに対応するために、バッチで処理しており、モーションモデリングや、検出した物体の外観情報を利用するために見え方に対して様々な手法を試していました。
SORT の研究チームは「リアルタイムで処理すること」を一番の目的とし、オクルージョンや物体検出エラーに対してあえてトラッキングアルゴリズム側で対応しないことを決めました。(その代わり、物体検出精度を向上させることで、物体検出エラーを低減しています。)
結果として検出物体の外見情報を使用せず、バウンディングボックスの位置や大きさなどに対して、カルマンフィルターやハンガリアンアルゴリズムを組み合わせたアルゴリズム SORT(SIMPLE ONLINE AND REALTIME TRACKING)を開発しました。
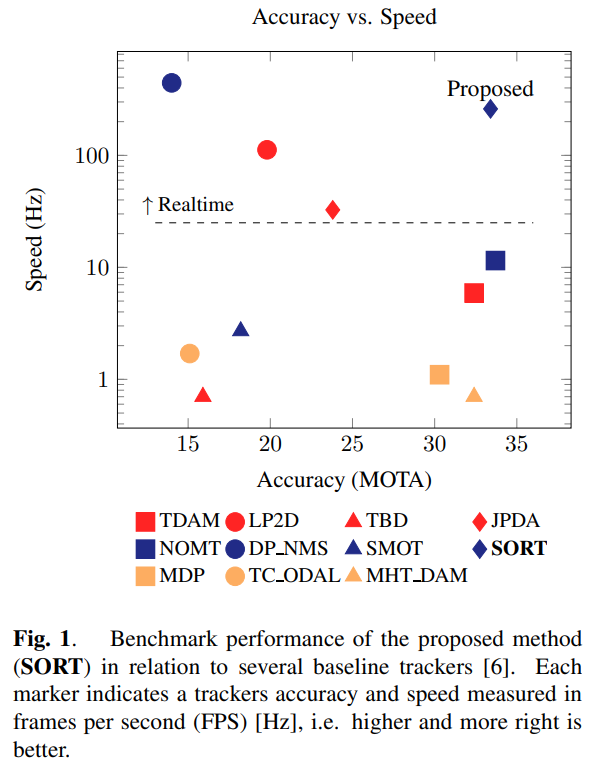
それまで精度と速度がトレードオフの関係性とされていたトラッキングアルゴリズムのなかで、精度と速度の両面をリアルタイムという観点で実用可能なレベルで両立するモデルとして提案されました。
ポイント
・検出精度がトラッキング精度に大きく影響を与えることを示し、MOTの文脈でCNNベースの検出モデルの有用性を明らかにした。
・カルマンフィルターとハンガリアンアルゴリズムに基づく実用的な追跡アプローチ SORT を提案した。
・オープンソースとして公開することで、研究および実用的なアプリケーションへの取り込みのためのベースライン方法を確立するのに貢献した。
詳細
開発背景
SORT 以前のトラッキングアルゴリズム(モデル)は、バッチベースのトラッキングアプローチが主流でした。Multiple Hypothesis Tracking (MHT) や、 Joint Probabilistic Data Association (JPDA) などが、SOATとしてしられており、検出物体同士をむすびつけるために、モーションモデリングや、物体の見え方に対して様々な手法が試されてきました。
一般的に精度と速度の間にはトレードオフの関係性がありますが、論文発表当時、実用的な精度でリアルタイムで利用できる速度に到達していないという問題がありました。SORT の研究チームは、オンライントラッキングのために、バッチ処理ではなく、前のフレームの検出結果と現在のフレームの検出結果のみを利用してより効率的なトラッキングを行うことを目的としています。様々なエッジケースや、検出エラーに対応しない代わりに、効率性とフレーム間のつながりの信頼性を向上し、検出精度そのものを向上させることに注力することで精度と速度の両立を目指しました。
これまでの研究
既存手法の代表例
・Multiple Hypothesis Tracking (MHT)
・ Joint Probabilistic Data Association (JPDA)
具体的な手法イメージ
まず、トラックレット(トラッキングの軌道)は、連続するフレーム間で検出を関連付けることによって生成されます。ここで、「位置情報」と「外観」の両方の情報を組み合わせて、アフィニティマトリックスが形成されます。
次に、トラックレットが相互に関連付けられて、オクルージョンによって引き起こされる「壊れた軌道」同士を結びつけます。(これも「位置情報」と「外観」の両方の情報を使用します。)
この2段階の関連付け方法は、バッチ計算に限定されています。
既存手法の問題点
これらのアプローチでは、追跡されるオブジェクトの数が指数関数的に増加することで計算量が大幅に増加し、非常に動的な環境でのリアルタイムアプリケーションには実用的ではないという問題があります。
提案手法
検出モデルの向上と、カルマンフィルターなどを利用してより効率的に簡素化された推定モデル(トラッキングモデル)が提案されています。
物体の外見情報は使わず、バウンディングボックスの位置と大きさのみの情報を利用しています。オブジェクトの再識別の形でトラッキングアルゴリズムを構築すると、追跡アルゴリズムにかなりのオーバーヘッドが追加され、リアルタイムアプリケーションでの使用が制限される可能性があると指摘しています。
短期および長期のオクルージョンに関する問題を無視しています。これはオクルージョンの問題が非常にまれにしか発生せず、対応するための処理を加えることでかえって複雑さが生じることを避けるためです。
1.検出モデル
それまでより検出精度が向上したCNNベースのモデル、Faster Region CNN(FrRCNN)を利用しています。
FrRCNNは、2つのステージで構成されるエンドツーエンドのモデルです。第1段階では、特徴を抽出し、第2段階の領域を提案します。次に、提案された領域内のオブジェクトを分類します。
このモデルの利点は、パラメーターが2つのステージ間で共有され、検出のための効率的なモデルを作成することができる点です。 さらに、ネットワークアーキテクチャ自体を任意の設計に交換できるため、さまざまなアーキテクチャを迅速に実験して検出パフォーマンスを向上させることができます。
論文では、FrRCNNで提供される2つのネットワークアーキテクチャ、FrRCNN(ZF)とより深いアーキテクチャ(FrRCNN(VGG16))を比較しています。
この論文全体では、PASCALVOCチャレンジ用に学習したデフォルトのパラメーターをFrRCNNに対して適用しています。また歩行者のみに関心があるため、他のすべてのクラスを無視し、出力確率が0.5を超える人物検出結果のみを追跡フレームワークに渡すようにしています。
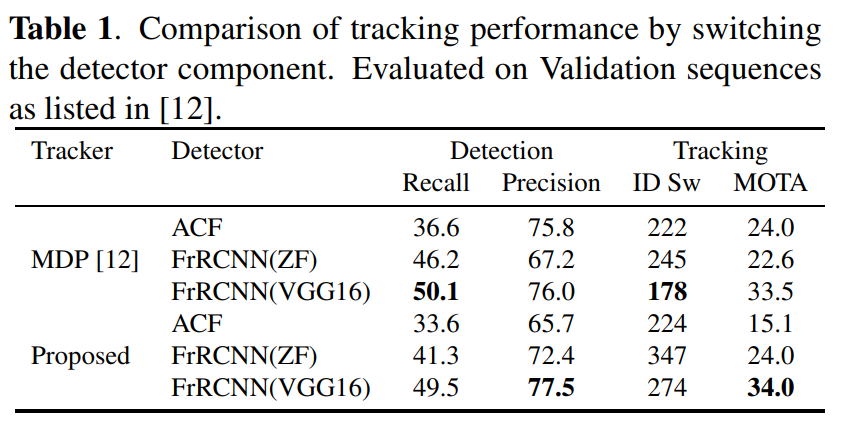
実験では、FrRCNNをACFと比較すると、検出品質が追跡パフォーマンスに大きな影響を与えることがわかりました。 これは、既存のオンライントラッカーMDPとここで提案されているトラッカーの両方に適用される一連の検証シーケンスを使用して示されます。 最良の検出器(FrRCNN(VGG16))が、MDPと提案された方法の両方で最良の追跡精度をもたらすことを示しています。
2.推定モデル
オブジェクト同士を各フレーム間で紐づけるように推定モデルを利用します。
各検出オブジェクトのフレーム間変位を、他のオブジェクトやカメラの動きに依存しない線形定速度モデルで近似します。 各ターゲットの状態は次のようにモデル化されます。
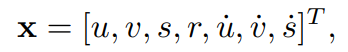
u:ターゲットの中心の水平方向のピクセル位置
v:ターゲットの中心の垂直方向のピクセル位置
s:ターゲットの境界ボックスの面積
r:ターゲットの境界ボックスのアスペクト比
※アスペクト比は一定であると見なされるように設計されています。
検出がターゲットに関連付けられている場合、検出された境界ボックスを使用して、カルマンフィルターを介して速度成分が最適に解決されるターゲット状態を更新します。 ターゲットに検出が関連付けられていない場合、その状態は線形速度モデルを使用して修正せずに単純に予測されます。
3.データ同士の関連付け
既存のターゲットに現在のフレームで検出したオブジェクトを割り当てるために、以下のような手順を踏みます。
1.既存のターゲットが移動先のバウンディングボックスの位置を予測します。
2.「検出されたバウンディングボックス」と、「既存のターゲットの移動先の予測バウンディングボックス」との間のIOU距離をすべて計算し「割り当てコストマトリックス」を作成します。
3. 割り当てを、ハンガリアンアルゴリズムを使用して最適になるように解決します。
4.さらにターゲットのオーバーラップに対する検出がIOUmin未満の割り当てを拒否するために、最小IOUを設定します。
※短期間オクルージョンの解決
バウンディングボックスのIOUは、ターゲットの通過によって引き起こされる短期間のオクルージョンを暗黙的に処理することがわかりました。 具体的には、ターゲットがオクルージョンしてしまった場合、IOUは同様のスケールでの検出を適切に優先するため、オクルーダーのみが検出されます。 これにより、割り当てが行われないため、カバーされたターゲットに影響を与えずに、両方のオクルーダーターゲットを検出で修正できます。
トラッキングIDの割り振り
オブジェクトが画像内を出入りするため、一意のIDを「作成」または「破棄」する必要があります。
・作成
トラッカーは、速度がゼロに設定されたバウンディングボックスの情報を使用して初期化(=作成)されます。この時点では速度が観測されていないため、速度成分の共分散はこの不確実性を反映して大きな値で初期化されます。 さらに、トラッカーは、誤追跡を防ぐために、デモ期間として一定フレーム数の情報を蓄積してから作成するようにされています。
・破棄
トラックが 「TLostフレーム」で検出されない場合、トラッキングを終了するように設計しています。 これにより、検出器からの修正なしで、長期間にわたる予測によって引き起こされるトラッカーの無制限増加が防止されます。 すべての実験で、TLostは「1」に設定されています。これは、①等速モデルは真のダイナミクスの予測には不十分であり、②オブジェクトの再識別が今回のトラッキング手法で扱える範囲を超えている、という理由によります。 また失われたターゲットを早期に削除すると、計算効率が向上するためです。 オブジェクトが再表示された場合、追跡は新しいIDで再開されます。
実験
初期のカルマンフィルター共分散、IOUmin、およびTLostパラメーターを調整するために、同じ設定を利用します。
指標
標準のMOT評価指標を利用しています。
•MOTA(↑):マルチオブジェクト追跡正確度
•MOTP(↑):マルチオブジェクト追跡精度
•FAF(↓):フレームごとの誤警報の数
•MT(↑):主に追跡された軌道の数
•ML(↓):ほとんど失われた軌道の数
•FP(↓):誤検出の数
•FN(↓):検出されなかった検出の数。
•IDsw(↓):IDが別のIDに切り替わる回数
•Frag(↓):トラックがミス検出によって中断された断片化の数
性能評価
トラッキングパフォーマンスは、11の連続した画像に対して正解ラベルが設定されているMOTベンチマークテストを使用して評価されました。以下の表2は、提案された方法SORTを他のいくつかのベースライントラッカーと比較しています。
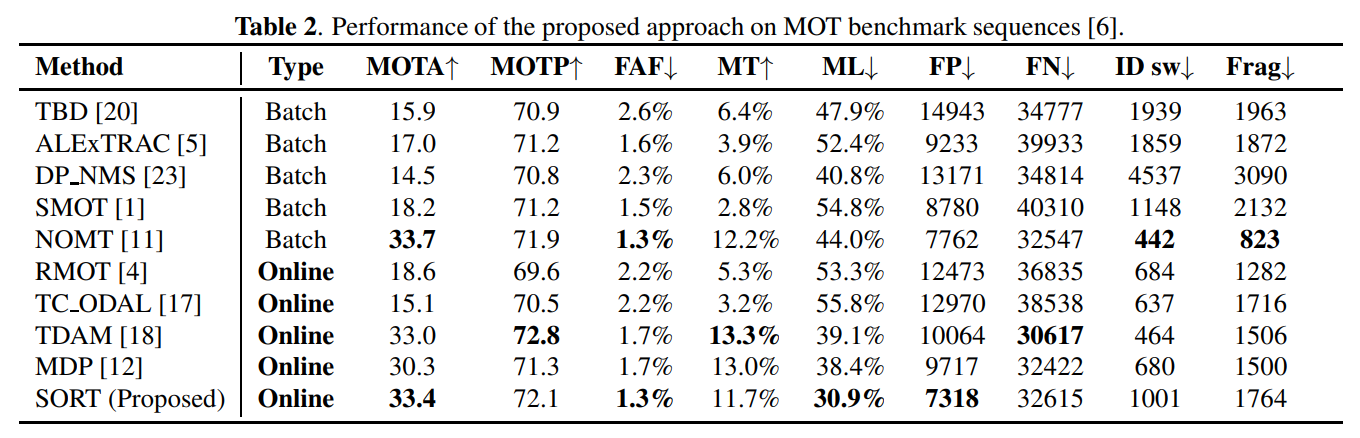
主に処理速度最速のバッチベースのトラッカーや、精度の点でSOATのオンライントラッカーを比較対象としています。SORT はオンライントラッカーで最高のMOTAスコアを達成し、複雑な手法である NOMT の精度に匹敵しています。さらに、SORTはフレーム間の関連付けに焦点を当てることを目的としているため、他のトラッカーと同様の誤検出があるにもかかわらず、失われたターゲット(ML)の数は最小限に抑えられています。
まとめ
それまでのほとんどのMOTソリューションは、多くの場合、実行時のパフォーマンスを犠牲にして、パフォーマンスをより高い精度にすることを目的としていました。オフラインの現場として研究などで実行時間が遅くなることは許容されますが、ロボット工学や自動運転車の場合、リアルタイムのパフォーマンスが不可欠でした。 SORT は速度精度の両方を実現し、これらへの道を大きくかいぜんしました。
SORT は提案されたように速度と精度の両方を利用可能なレベルにしたモデルとしてベースラインとなり、その後のトラッキングモデルで利用されることになります。現在利用されているモデルの基礎となっているので、SORT を理解することでより発展的なモデルへの理解とつながります。