はじめに
本記事は、物体検出モデルであるRetinaNetを通して「モデルの概念理解」と「コードの理解」ができることを目的としたものです。そのため①モデルの解説、②コードの解説、という二部構成になっています。コードの記述に関しては後日公開予定です。
RetinaNetとは
RetinaNetとは、Facebook AI Research(FAIR)が2017年8月に発表した論文「Focal Loss for Dense Object Detection」で提唱されている物体検出モデルです。
Focal Loss for Dense Object Detection
[Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár @ ICCV 2017]
https://arxiv.org/abs/1708.02002
論文の開発動機で指摘されているように、RetinaNet以前の精度の良い物体検出モデルの多くはR-CNNベースの二段階検出(two-stage object detector)の構成を取っていました。(R-CNNは、まず①物体が存在していると思われるバウンディングボックスの候補集合を提案し、その後②提案された各バウンディングについて分類を行うという2段階になっています。)この二段階検出モデルは高い精度をだすことができますが、一方で推論速度(及びモデルの複雑さ)に問題がありました。
そこで、同時期にYOLO(YOLOについては「物体検出の代表アルゴリズム YOLOシリーズを徹底解説!【AI論文解説】」(https://deepsquare.jp/2020/09/yolo/)をご確認ください)やSSDのような一段階検出(one-stage)で高速に物体検出を行うネットワークが提案されてきました。しかし、これらの一段階検出モデルは高速な一方でやはり精度面に関しては二段階モデルに劣るという課題がありました。RetinaNetの開発者たちは(速度を維持したままで)精度が高い一段階検出モデルができないかと考え、RetinaNetが発表されました。
この論文では一段階検出モデルが二段階検出モデルと並ぶ精度が出せない理由として「クラス間の不均衡(class imbalance)」があると考えられています。そこで、精度向上のために一般的な損失関数であるクロスエントロピー誤差とは異なる損失関数を提案しています。
クラス間の不均衡とは画像のほとんどが背景である(=物体が存在しない)ため、物体がある個所と物体のない箇所の割合を比較すると極度の不均衡状態にあることを指します。なぜこのことが問題かというと、学習のほとんどが簡単な背景判定に割かれてしまい効率的な学習ができていない可能性があるためです。(なお、二段階検出モデルの場合は、最初の段階で背景などを排し注目すべき部分を限定しているため、二段階目の分類の段階で不均衡が解決された状態で学習することができます。また、背景と物体の数の比率を固定したり、OHEMを利用することでバランスを保っています。)
新たな損失関数として提案されたのが、論文のタイトルにもなっている「Focal Loss」です。これは「背景」ではなくより重要である「物体」を検出することにFocus(注視する)して学習できるような損失という意味合いからきています。
Focal Lossとは
Focal Loss(FL) は通常のクロスエントロピー誤差(cross entropy loss :CE) を対象の重要度によって動的に変化させる損失関数です。ここでは、論文に従って通常のクロスエントロピー誤差と何が違うのかを確認します。
通常のクロスエントロピー損失
通常のCEは以下のように表記されます。
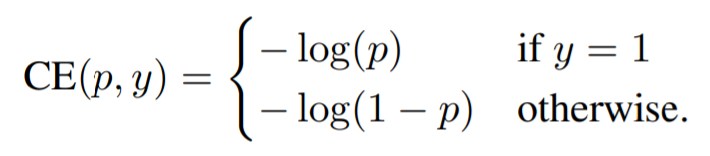
利便性のために、推定確率pを以下のように定義すると、
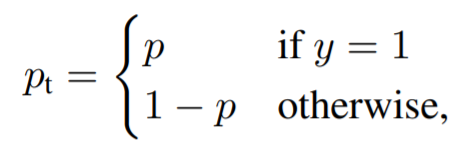
CEは以下のように書き直すことができます。
![]()
この状態の損失関数では、背景などの分類が簡単なものと小さくて検出が難しい物体でも同じような損失をあたえることを意味します。
均衡クロスエントロピー(Balanced Cross Entrophy)
クラス不均衡の問題に対してよく使われるものとして、重みαを導入する方法があります。こちらも上記のptと同じようにαtを定義すると、次のように書くことができます。
![]()
このαは実際にはハイパーパラメータとして扱われるものです。論文では、以上をベースにFocal Lossを提案しています。
Focal Loss
上記で示されたように、現在の損失関数の問題は背景の分類のような簡単で量の多い分類問題によって学習が支配されてしまっている点です。均衡クロスエントロピーで提案されているαは正の例と負の例の重要性のバランスをとってはいますが、易しい例と難しい例の区別をしていない点が問題です。
そのため開発者チームは、以下のように損失関数を再構築して、易しい例の重みを下げることで、難しい例に焦点を当てた学習を行うことができるようにしました。
![]()
提案された(1-pt)**γ項のγは、論文では「Focusing parameter」と呼ばれるハイパーパラメータです。γ≧0の範囲から適切な値を設定します。(なお、γ₌0のときは通常のCEと同じです。)
ここで重要なことは、2点あると論文では示されています。
(1) 例が誤分類されていてptが小さい場合、係数は1に近く、損失は影響を受けません。逆にpt が 1 に近くなると重みが 0に近くなり、うまく分類された例の損失はダウンウェイトされます。
(2) フォーカスパラメータγは、易しい例のダウンウェイト率を滑らかに調整します。γ=0の場合、FLはCEと同等であり、γを増加させるとパラメータの効果も同様に増加します(なお、実験ではγ=2が最も効果的であることがわかったとしています)。
なお、論文の実験ではFocal Lossと均衡クロスエントロピーを組み合わせた下記の関数が用いられています。
![]()
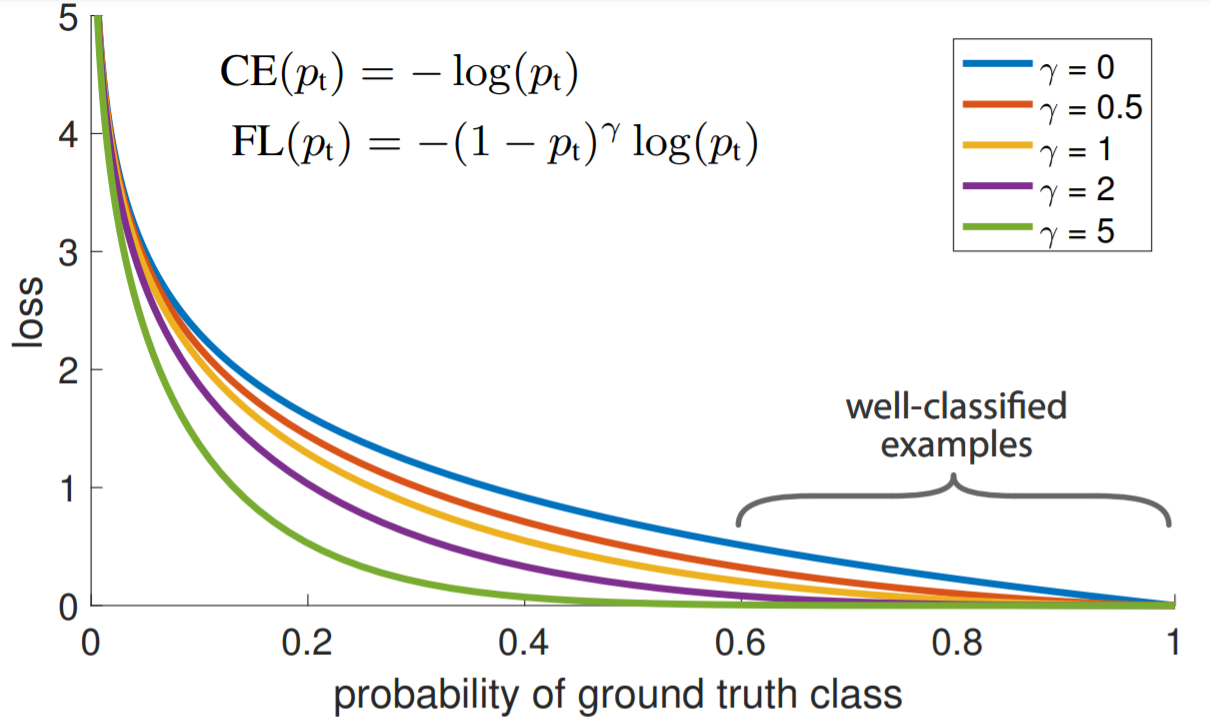
以下がFLと通常のCE(青色)を比較したグラフです。グラフから確認できるように、CEでは簡単に分類されている例(pt≫0.5)で、他よりも大きな損失が発生しています。つまり、CEでは背景などの簡単な分類によって難しい物体を検出できたような特別な損失を見失ってしまう可能性があるということがわかります。またγ₌5など値を大きくしすぎると、学習が困難になっている様子もわかります。
RetinaNetの構造について
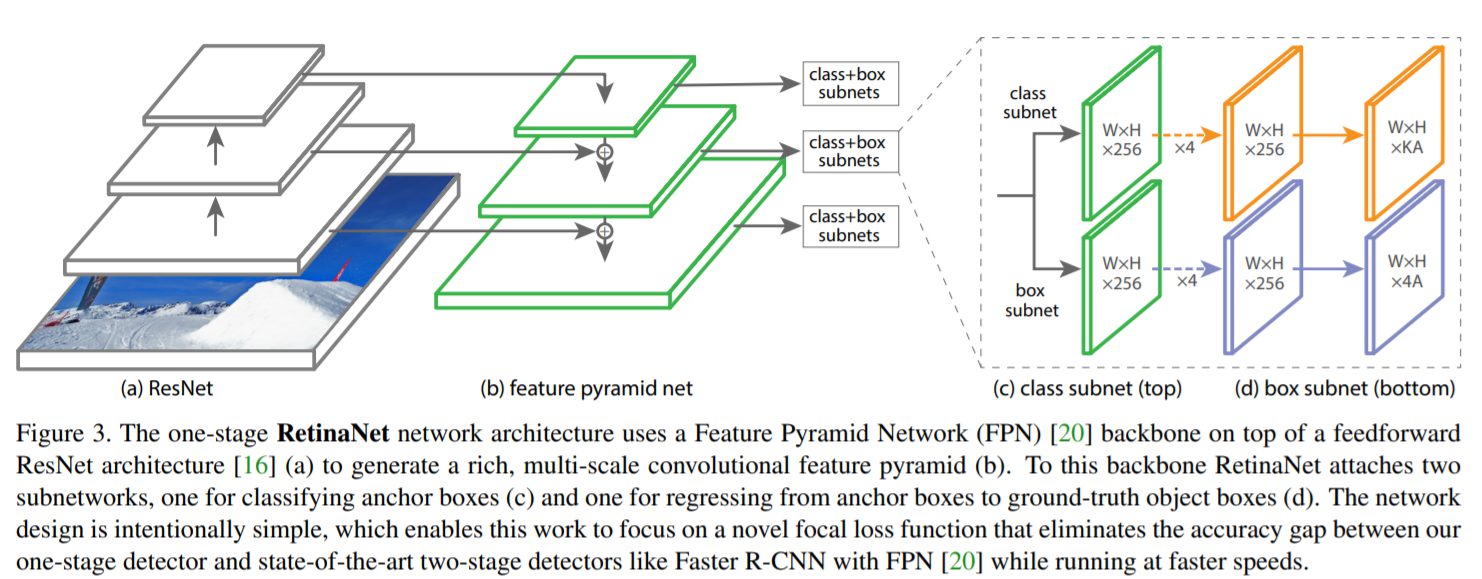
Retinaは畳み込み特徴量マップを計算するbackbone networkと二つのsub networks(クラス分類とバウンディングボックスの推定)で構成されています。backbone networkとしてはFPNが採用されています。(FPNはFeature Pyramid Networkと呼ばれるもので階層構造をとることで精度を向上させるものです。)IoUが0.5以上のアンカーは正解領域として、逆にIoUが0から0.4であった場合は背景とします。各アンカーは一つの物体ボックスに属するのでその対応するクラスを正解クラスとし、anchorとobject boxの相対的位置からbox regressionのターゲットを決めます。
まとめ
RetinaNetの理論的側面についてご紹介しました。損失関数の改良というシンプルな改良ながら、大きな効果をもたらしたモデルであり、現在でも人気があります。次回は、RetinaNetをコードから細かくみていきたいと思います。
参考URL
物体検出モデルの進展 Part3 ~FPNとRetinaNet~
https://qiita.com/TaigaHasegawa/items/653abc81ac4ee1f0d7b8
[論文紹介] Focal Loss for Dense Object Detection
https://qiita.com/agatan/items/53fe8d21f2147b0ac982
概論&全体的な研究トレンドの概観③(FPN、RetinaNet、M2Det)|物体検出(Object Detection)の研究トレンドを俯瞰する #3
https://lib-arts.hatenablog.com/entry/object_detection3