2018年にGoogleの研究チームから発表されたMobileNetV2の詳細解説を発表論文とGoogleブログを主な参考文献として行う。なお、説明のために引用した図は下記発表論文もしくはGoogleブログから用いた。
元論文:
MobileNetV2: Inverted Residuals and Linear Bottlenecks
(初稿2018年1月13日、最終版2019年3月21日)
https://arxiv.org/abs/1801.04381
Googleブログ:
MobileNetV2: The Next Generation of On-Device Computer Vision Networks
(2018年4月3日)
https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html
サイト内関連記事:
MobileNetV1に関する記事
https://deepsquare.jp/2020/06/mobilenetv1/
ResidualNetworkに関する記事
https://deepsquare.jp/2020/04/resnet-densenet/
(MobileNetV2を理解するうえではResidual Network:ResNetの仕組み、用語を理解していると理解しやすい。)
MobileNetV2大略まとめ
MobilenetV2の大筋を簡単にまとめた。
概要
・2018年にMobileNetV1の後継モデルとして、MobileNetV1の構想、モデルを基礎にしながらモジュールを大幅に改良したもの。
・MobileNetV1同様、分類・物体検出・セマンティックセグメンテーションを含む画像認識をモバイル端末などの限られたリソース下でも高精度で判別するモデルを作成することを目的として作成された。
アーキテクチャモデル
・MobileNetV1で使われたdepthwise separatable convolutionのアイデアを基に構築されている。
・そのうえで、アーキテクチャに新たに2つのモジュールを導入している。
1) レイヤー間の線形ボトルネック(linear bottlenecks)
表現力を維持するためには、活性関数における非線形性を除去することが重要であることがわかった。そのため中間拡張層は、非線形性の原因となる特徴をフィルタリングするために、linear bottlnecksが用いられている。
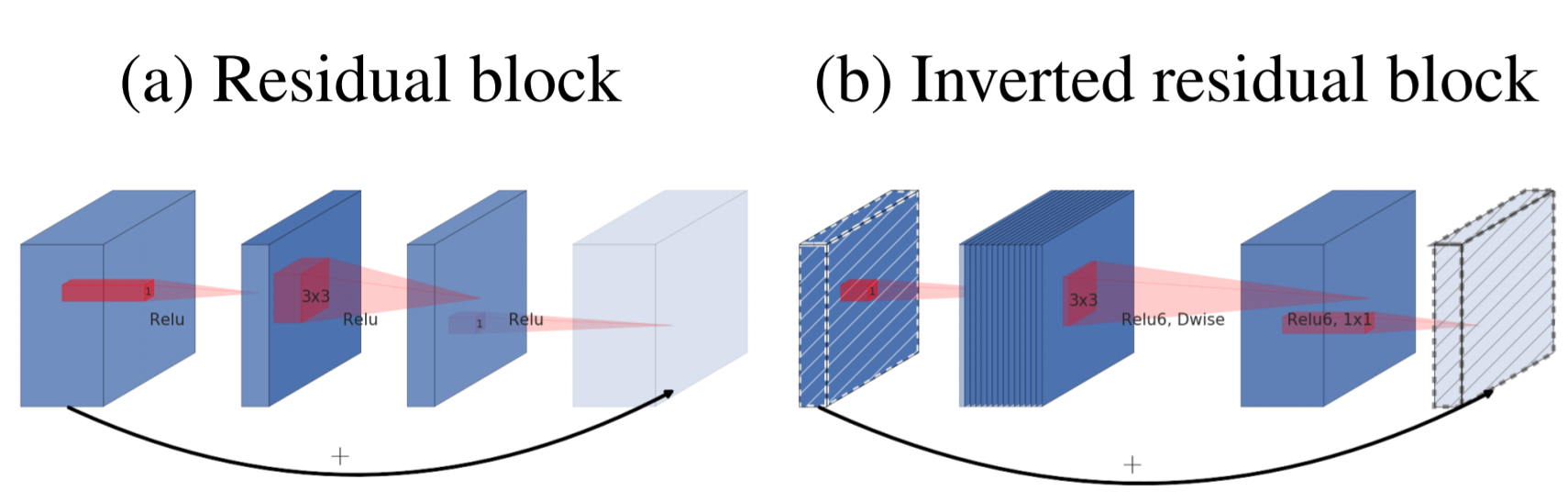
2) ボトルネック間のショートカット接続(inverted residuals(反転残差))
従来の残差ネットワーク(Residual Network:ResNet)と同様に、ショートカットを使用することで、より高速なトレーニングと精度の向上を可能にしている。なお、inverted反転とついているのは、利用している活性関数ReLUが情報量を維持できる線形性を保つ必要からチャネル数の増減の流れが通常のresidualとは逆になっているため。
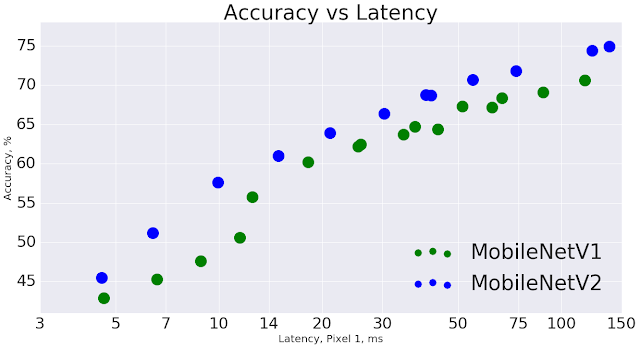
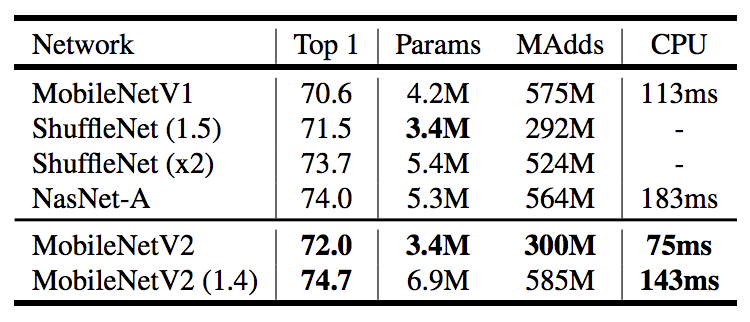
MobileNetV1との性能比較
・全体として、同一精度であればより高速になっている。
・使用する演算子が1/2倍となり、必要なパラメータ数が30%少なくなっている。
・Google Pixel携帯電話では約30~40%高速でありながら、より高い精度を実現している。
他モデルとの比較
・ShuffleNetやNesNetなどとパラメータ数を同程度にした場合、わずかに精度が上回り、処理速度が高速になっていることが確認されている。
利用方法
・TensorFlow-Slim画像分類ライブラリの一部としてリリースされている。
・Colabですぐ利用を開始することもできる。もしくはノートブックをダウンロードして、Jupyterを使ってローカルに利用することもできる。
・MobileNetV2 は TF-Hub のモジュールとしても利用可能で、事前に学習したチェックポイントは github で見つけることができる。
MobileNetV2詳細まとめ
MobileNetV2の詳細解説を行う。
MobileNetの特徴
〇前提
作業 精度と性能の最適なバランスをとるためにディープニューラルアーキテクチャをチューニングすることは、発表当時(2018年)までの数年間において活発な研究分野であった。そのため、ハイパーパラメータ最適化やネットワーク剪定、接続性学習などの様々な手法を含むアルゴリズムアーキテクチャの探索に多くの進展があった。また、ShuffleNetのように内部の畳み込みブロックの接続構造を変更したり、スパーシティを導入するなどの取り組みもあった。直近(2018年)では、遺伝的アルゴリズムや強化学習を含む最適化手法をアーキテクチャ探索に持ち込むという新たな方向性が切り開かれた。しかし、結果として得られるネットワークが非常に複雑になるという欠点が生じていた。
〇特徴
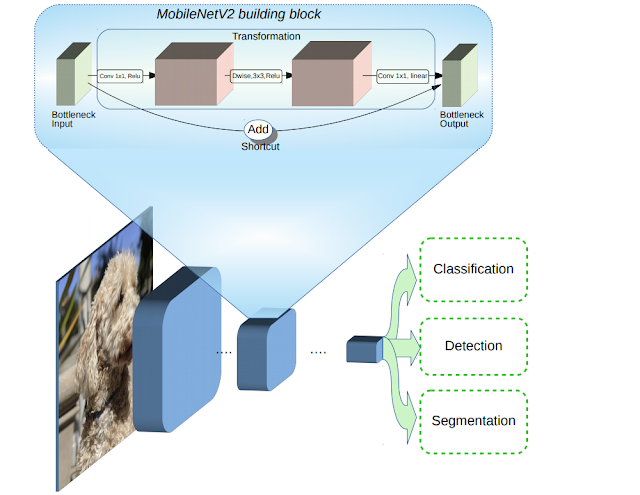
MobileNetシリーズでは、ニューラルネットワークがどのように動作するかについてのより良い直感を磨き、可能な限り単純なネットワーク設計を導くためにそれを使用するという目標を追求している。そのために今回MobileNetV2で導入されたのが、新しいレイヤーモジュールであるthe inverted residuals with linear bottlenecks(線形ボトルネック付き反転残差)である。※より正確にいえば、MobileNetV1で利用されたdepth-separable convolution も組み込まれているため、 a bottleneck depth-separable convolution with residuals(残差を伴うボトルネック深さ方向分離可能畳み込み)といえる。
このレイヤーモジュールでは、①低次元の圧縮表現を入力とし、②高次元に展開された上で軽量なdepthwise convolutionでフィルタリングされ、その後③線形畳み込みを用いて低次元表現に投影される。
このモジュールは、任意の最新のフレームワークで標準的な操作を使用して効率的に実装することができる。さらに、大きな中間テンソルを完全に具現化しないことで、推論中に必要なメモリフットプリントを大幅に削減できるため、モバイル設計に特に適しているといえる。(少量の非常に高速なソフトウェア制御キャッシュメモリを提供する多くの組み込みハードウェア設計におけるメインメモリアクセスの必要性を低減することができる。)
モジュール説明
MobileNetV2で利用されているモジュールは以下の3つになる。
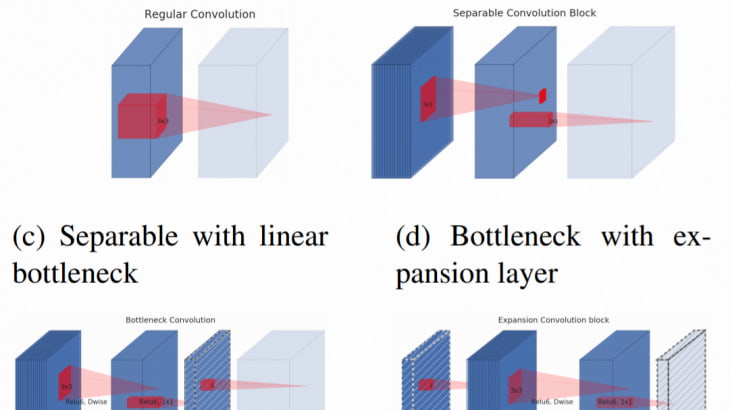
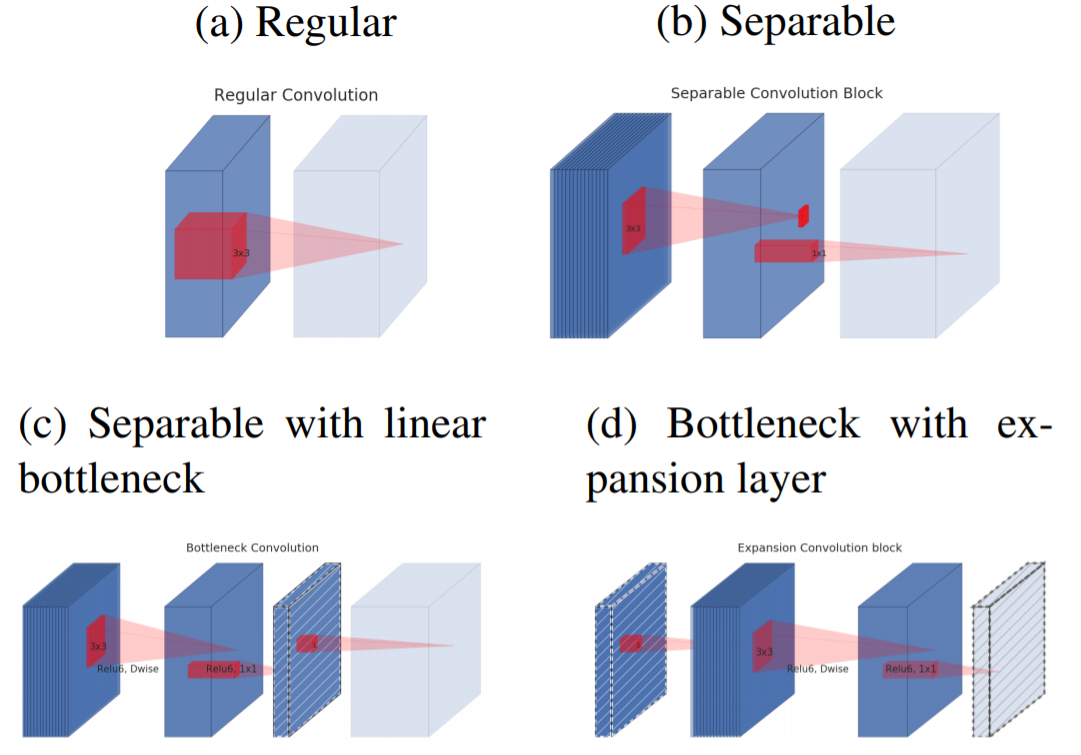
・Depthwise Separable Convolutions(深さ方向分離可能畳み込み)
・ Linear Bottlenecks (線形ボトルネック)
・Inverted residuals(反転残差)
①Depthwise Separable Convolutions(深さ方向分離可能畳み込み)
MobileNetV2でも Depthwise Separable Convolutionsを利用することで、計算量を減らしている。 (Depthwise Separable Convolutionsの詳細については、MobileNetV1の記事を参照のこと。)
②Linear Bottlenecks (線形ボトルネック)
活性関数に非線形性をもつ層(ReLU層やSoftmax層、tanh層など)を利用すると、非常に多くの情報が失われることがあきらかになった。そのため、MobileNetV2では活性関数のReLUの特性を利用して線形性をもつ形にすることで情報が失われることを防いでいる。
詳細説明(参考)
一般に、実画像の入力セットに対して、活性化層を通すことで出力されたたデータは「manifold of interest(関心事の多様体)」を形成していると言う。ニューラルネットワークにおいて「関心事の多様体」とは、高次元空間に存在するはずの情報群がより低次元の部分空間に埋め込まれてできたもの(射影できるもの)と想定されてきた。※「多様体仮説」に基づいている。「多様体仮説」については下記注釈を確認のこと。
言い換えれば、深い畳み込み層においてみられる個々のすべての値に関して、それらの値にエンコードされた情報は、実際には何らかの多様体に存在しており、その多様体は低次元部分空間に埋め込むことができるということが想定されてきたことを意味する。このような想定は、層の次元を単純に減らすことで低次元多様体を捕捉および活用でき、それにより演算空間の次元を減らすことができるという直接的な認識を生み出すことになる。実際、MobileNetV1ではこの認識のもと a width multiplier parameterなどが実装されていた。
しかし、深層畳み込みニューラルネットワークでは、実際には点座標ごとにReLU のような非線形な座標変換があることで、この想定が正しくないことが明らかになる。ReLUは入力値がゼロ以下の場合全て値0として出力し、ゼロ以上の値のみを線形変換する非線形関数である。そのため、ディープネットワークは、出力領域が非ゼロ量になる部分の線形分類器の力しか持たなことを意味する。(さらなる詳細をもとめる場合は、論文の付属解説を参照のこと。) つまりReLU関数を利用した非線形変換だと、必要な情報を持っている領域を誤ってつぶしてしまっているといえる。
とはいえ、ReLUのような活性化層空間において関心の多様体が構造を持っている場合、失われるチャネル以外の他のチャンネルに必要十分な情報が保存されている可能性が存在する。つまり、ReLU変換後も必要な情報を保持している場合があることを示しているといえる。ただし、あまりにも低次元に落とし込むとReLUのmanifoldに埋め込まれる情報量が、実像を反映しない情報量しか保有していない可能性が高くなり高い精度をだすことが困難になる。
そのことを示すのが、下記図である。ReLUに入力されるデータのn次元ごとにどのように情報が失われているかを模したものになる。n=2やn=3などでは著しく失われている一方で、n=15やn=30ではある程度維持されていることがわかる。

そのためReLUにつながる中間部分のチャンネルを拡大する(=次元を増やす)ことによって、本来つぶれてしまう情報を他のチャンネルに持たせることができ、情報の喪失を防げるのではないかと仮説を立てることでMobileNetV2ではBottolneck Convolutionが実装されている。入力ボトルネックの大きさとinner layerの大きさの比をthe expansion ratio拡大率と論文では呼称している。なお、次元をおおきくしすぎてもうまく機能しないことが知られており、論文では拡大率を6に設定している。このチャネルを増やすことでReLUによる情報消失を解消しようとすることが、通常のresidual(残差)のチャネル数変化とは逆になるため、MobileNetV2ではinverted residual(反転残差)が実装されることとなる。
以上より、適切な情報を引き出すためには「関心のある多様体」が高次元活性化空間の低次元部分空間に存在しなければならないという要件を示す2つの特性を理解することが重要になる。
1. ReLU変換後「関心の多様体」が非ゼロ量に存在して入れば、ReLUによる変換は線形変換に相当する。(₌Linear)
2. 「関心の多様体」が入力空間の低次元部分空間にある場合に限り、ReLUによる線形変換をしたあとのデータも「関心の多様体」に関する完全な情報を保持することができる。
線形変換を使用することが、非線形性が非常に多くの情報を破壊するのを防ぐために重要であることを意味している。(ボトルネックに非線形層を使用すると、実際に性能が数パーセント低下することが示されている。)
※多様体仮説について
各点の周りがn次元的に拡がっているような空間を多様体と呼ぶ。別の言い方をすれば、局所的にはn次元の座標系を使って表すことができ、それがn次元ユークリッド空間と同相(滑らかに変形させていって同じ形にできる)であるような空間である。
例えば、球面というのは3次元空間中の2次元的な広がりを持つ多様体であるといえる。各点の周りだけをみれば2次元とみなすことができる(局所的に世界地図は地球という球面を正しく表現できているといえる)が、球面全体は2次元と同相ではない(しかし、世界地図では北極、南極で非連続になっており全てが正しいとはいえないことは明らかである)。
現実世界で観測される多くのデータの分布が実際の高次元多様体よりも低次元多様体として捉えられるという仮説を多様体仮説と呼ぶ。この多様体仮説が重要となるのは、現実の物事を想定する際に、現実に計算可能な範囲で計算量を抑える必要があるためである。たとえば、画像一枚を考えたとしても、そのピクセル配置に関しては非常に多次元でほぼ無限にある。しかし、そのほとんどが砂嵐のようなもので、少なくとも人間に意味ある配置はかなり限られた範囲内におさまっていることが現実世界の観察から理解される。この人間に意味ある配置は実際の可能配置空間よりもかなり低次元空間上に存在していると考えられるが、このことを理論的に構築しているのが多様体仮説となる。
機械学習では、データ中に埋め込まれている多様体をどのように推定するか、そして、多様体中の座標と元の世界の座標をどのように対応づけるかについては様々な手法が検討されている。この対応付けを実現する手法として線形であれば主成分分析(PCA)が、非線形であればIsomap、LLE(locally linear embedding)、Laplacian Eigenmaps、SDE(semidefinite embedding)などが知られている。
参考記事:
多様体仮説:現実世界のデータをどうモデル化するか
https://xtech.nikkei.com/dm/atcl/mag/15/00144/00031/
(日本経済新聞 2017/05/10)
③Inverted residuals(反転残差)
ReLUの表現力の問題に関連してInverted residulals blockを考案している。このblockを基本的にMobileNetV1の単純なDepthwise Separable Convolutionと置き換えることになる。 inverted residuals blockは3つのconvolutionから構成されており、最初のconvolutionは1×1Convである。 そしてこのConvはt倍(tはthe expantion ratio展開率)に出力チャンネルを写像する役割を持っている。 (このハイパーパラメータであるthe expantion ratio 展開率tが本論文では6にされているため、ReLU6と表現されているなおReLU6を使用しているのは、低精度計算で使用した場合のロバスト性が高いため。) 3つ目のConvolutionも同様に1×1convであるが、こちらは出力チャンネルを入力時のチャンネル次元数に戻すようなConvolutionになっている。

なお、ボトルネックには実際に必要な情報がすべて含まれているのに対し、expantion layer展開層はテンソルの非線形変換に付随する実装の詳細にすぎないという直感のもと、ボトルネック間を直接つなぐショートカットを使用することにしている。
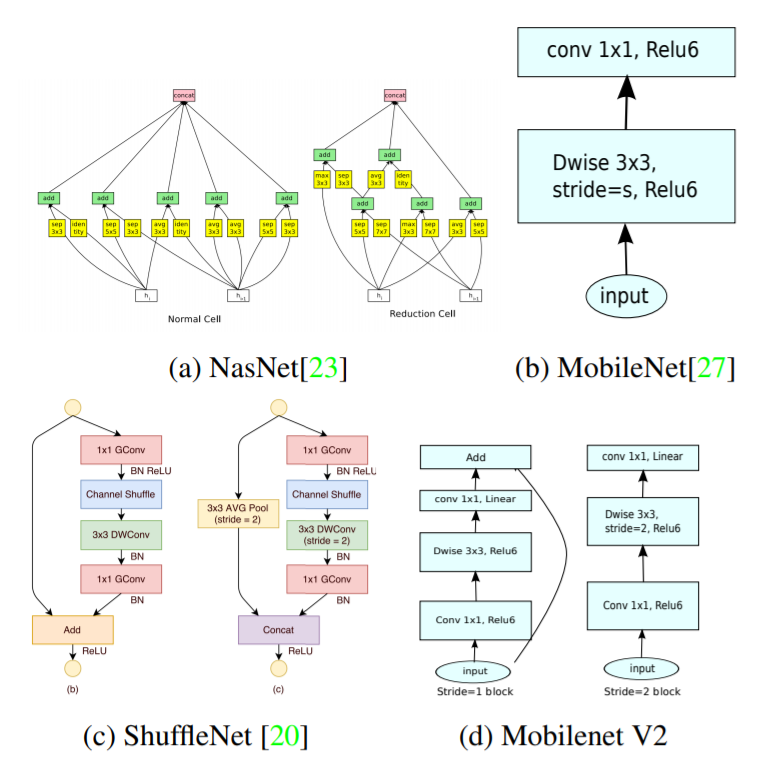
アーキテクチャ構造

〇構成ブロック
基本的な構成ブロックは a bottleneck depth-separable convolution with residuals(残差を含むボトルネック深さ分離可能な畳み込み)である。論文のMobileNetV2のアーキテクチャは、32個のフィルタを有する初期の完全畳み込み層と、19個のボトルネック層で構成されている。(なお現在最も一般的なカーネルサイズ3×3を使用し、訓練中にドロップアウトとバッチ正規化を利用している。)
第1層を除いて、ネットワーク全体で一定(t=6)のthe expantion ratio展開率(t)を使用している。実験では5と10の間の拡張率では、ほぼ同じ性能曲線が得られることがわかっている。なお小さいネットワークではわずかに小さい展開率の方が良く、大きいネットワークは大きい展開率の方がわずかに良いことがわかっている。
MobileNetV2のアーキテクチャ特性の一つは、ビルディング・ブロック(ボトルネック層)の入力/出力領域と、入力を出力に変換する非線形関数である変換層との間に自然な分離を提供していることにある。前者は各層でのネットワークのキャパシティとして見ることができ、後者は表現力として見ることができる。これは、従来の畳み込みブロックでは、表現力とキャパシティの両方が絡み合い、出力層の深さの関数となっていたのとは対照的なことがわかる。(特に、inner layerの深さが 0 の場合、ショートカット接続のおかげで、基礎となる畳み込みが恒等関数となる。the expantion ratio展開率が1よりも小さい場合、これは古典的な残差畳み込みブロックとなるが、1よりも大きい展開率が有用であることが今回の論文では明らかにされている。)
なお、この解釈から、ネットワークの表現力とキャパシティを分離して研究することができ、ネットワークの特性をよりよく理解するためには、この分離のさらなる探求が必要であるとMobileNetの作者たちは考えている。
〇トレードオフハイパーパラメータ
MobileNetV1と同様に、入力画像の解像度とthe width multiplier幅乗算器を調整可能なハイパーパラメータとして使用している。そのことで、異なる性能ポイントに合わせてアーキテクチャを調整することが可能となっている。(これらのハイパーパラメータの意味や、性能についてはMobileNetV1の記事を参照のこと。)
検証(他モデルとの比較)
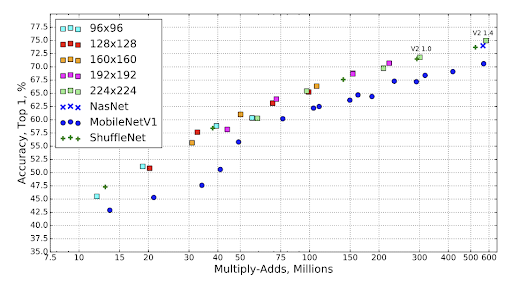
①イメージ分類
下図はImagenet classificationにおけるtop-1 accuracyと積和演算のトレードオフのグラフである。 MobileNetV1より全体的に効率がよくNaSNetや ShuffleNetなどと同等の精度があることがわかる。
下図は計算速度を表しており、MobileNetV2がはやいことがわかる。
②物体検出
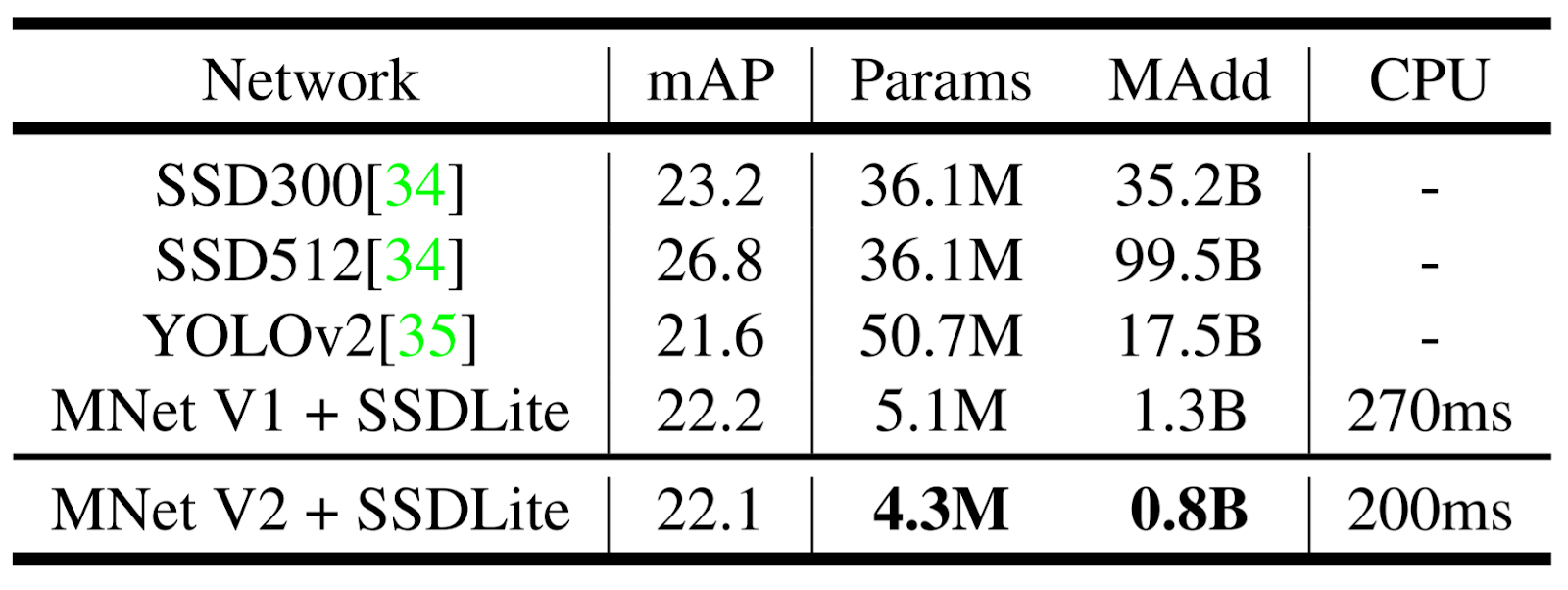
エンコーダとしてのMobileNetV2とMobileNetV1の物体検出性能を、シングルショット検出器(SSD)の改良版、ベースラインとしてYOLOv2 とオリジナル SSD (VGG-16 をベースネットワークとする) を用いてCOCOデータセット上で評価・比較している。なお、SSDLiteを実験では用いている。(論文ではその使用も勧めている。)SSDLiteはSSD 予測層において、すべての通常の畳み込みを分離可能な畳み込み(深さ方向に続く 1×1 射影)に置き換えたモデル。通常の SSD と比較して、SSDLite はパラメータ数と計算コストの両方を劇的に削減することができる。
結果は下記図に表されている。MobileNetV2 SSDLiteは、最も効率的なモデルであるだけでなく、3つのモデルの中で最も精度が高いことがわかる。MobileNetV2 SSDLiteは、COCOデータセット上でYOLOv2を上回る20倍の効率性と10倍の小型化を実現している。
③セマンティックセグメンテーション
エンコーダとして使用されるMobileNetV1およびMobileNetV2をDeepLabv3と比較している。モバイルモデルを構築するために、以下の3つのデザインバリエーションを用いて実験を行ったとしている。
(1)異なるエンコーダ
(2)計算を高速化するためのDeepLabv3ヘッドの単純化
(3)性能を向上させるための異なる推論戦略
結果は下記図のようになった。
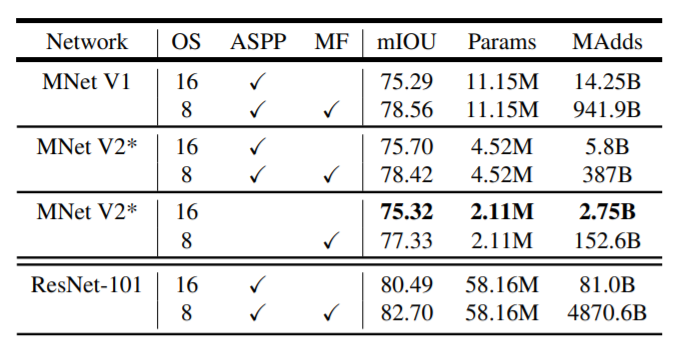
また以下の知見を得ることができたと公表している。
(a) マルチスケール入力やレフトライト反転画像の追加などの推論戦略は MAdds が大幅に増加するため、オンデバイスアプリケーションには適していないこと
(b) 出力ストライド = 16 を使用することは出力ストライド = 8 よりも効率的であること
(c) MobileNetV1 は既に強力なエンコーダであり、必要とする MAdds は ResNet-101の約1/5倍しかないこと。
(d) MobileNetV2 の最後の 2 番目の特徴マップの上に DeepLabv3 ヘッドを構築するのは、元の最後の層の特徴マップに構築するよりも効率的であること
(e)DeepLabv3 ヘッドは計算量が多く、ASPP モジュールを削除することで、わずかな性能低下で MAdds を大幅に削減することができること
まとめ
MobileNetV2はMobileNetV1につづき非常にシンプルなネットワークアーキテクチャでありながら、高効率なモバイルモデルを構築することを可能にした。モバイルデバイスに適した非常にメモリ効率の高い推論を可能にし、すべてのニューラルフレームワークに存在する標準的な操作を利用することを可能にしている。
性能実証面では、画像分類、物体検出、セグメンテーションなどで効率的ながら同一モデルと同等の精度もしくはより高い精度で、高速に出力することがあきらかになった。
理論面では、MobileNetV2で新たに提案された畳み込みブロックは、(展開層によってコード化された)ネットワークの表現力と(ボトルネック入力によってコード化された)ボリュームを分離できる特性がある。