はじめに
豪シドニー大学とファーウェイの研究チームがVisionTransformerとCNNのよい部分を組み合わせて精度と計算効率を向上させたモデル CMT を発表しました。
概要
これまで画像認識分野(Computer Vision: CV)ではCNN、自然言語処理分野(Natural Language Processing : NLP)ではTransformerが大きな成果をあげてきました。NLPでのTransformeの成功に触発される形で、CVでもTransformerが使われるようになり、Transformerだけで画像を処理できるモデル VisionTransformer(ViT)も開発されました。特にモデルのスケーラビリティ capabilities (モデルを大きくすることで性能の向上が見込めること)がTransformerは保証されていることが大きく、その後 Transformer をCVで利用したモデルは多く開発されてきました。しかし、一方で未だに EfficientNets などのCNNベースのモデルに同程度のサイズでは性能や計算効率の面では劣っているという問題も明らかになってきました。
そのため、今回CNNモデルの効率性とローカリティ(少域特徴量をよく捉える)、Transformerのスケーラビリティとグローバリティ(大域特徴量をよく捉える)という良い点を組み合わせた CMT(CNN Meet Transformer) が開発されました。
結果、同程度の精度をだすDeiTよりも1/14倍、EfficientNetよりも1/2倍のモデルサイズで、 CMT は ImageNetで83.5%の精度を4.04B FLOPs で達成することができました。
論文のポイント
・Transformerのスケーラビリティとグローバリティ、CNNの効率性とローカリティをバランスよく組み合わせることで、精度を維持しながらモデルサイズを小さくすることに成功した。
・CNNとTransformerを接合するために、① LPU ②LMHSA ③IRFFN という独自のモジュールを開発して利用している。
詳細
開発背景
ViTなどがCNNベースのモデルに同程度のサイズでは性能や計算効率の面では劣っている原因には、3つの要素があると考えられています。
① 画像をTransformerに入力するためにパッチに分割していること。
⇛シンプルな方法ではあるもののNLPタスクとCVタスクのもつ基礎的な違いを無視することで、性能の低下につながっている。
② 低解像度かつマルチスケールの特徴量マップを抽出することが苦手なこと。
⇛ViTではパッチサイズが固定されているためであり、そのことで物体検出やセグメンテーションなどの密な予測タスクが困難になっている。
③ 計算コストかつメモリコストが入力画像の解像度に二乗すること。
⇛CNNと比べて計算コストが高くなる要因であり、高解像度の画像は近年一般的なものになってきているため、ViT系のモデルではGPUメモリが不足したり、計算効率が低下したりする問題が発生している。
CMT はこれらの問題に対処することで、精度を維持したままより軽量なモデルを作成することができるのではないかという発想からモデルを作成しています。
CMT
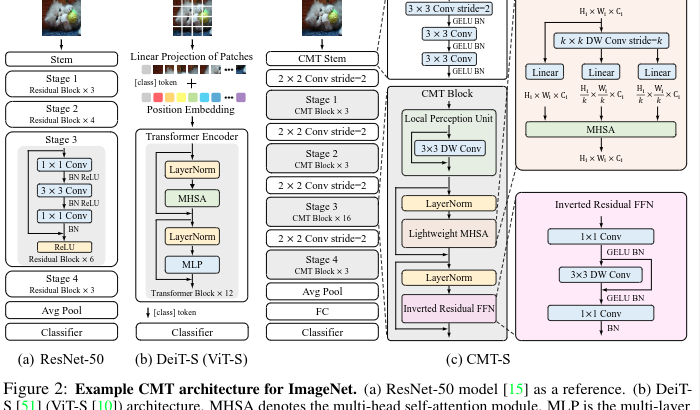
CMTは基本的に以下のような構造になっています。
① CNNをベースにしてきめ細かい特徴量を抽出する。
② CMT block (depth-wise convolution を利用してローカル情報をより獲得しやすくしたTransformerの改良版) に入力して表現を学習する:ViTと比べてより高い解像度(CMT Block : H/4×W/4、 Vit : H/16×W/16)を維持することができるため密なタスクにも対応できる。
③ Stage-wiseなものを利用して特徴量サイズを変化させる
④ average pooling を利用することで変化させたCMTモデルにも適応することができる。
CMT(ResNetとDeiTとの比較)の図(一番右)
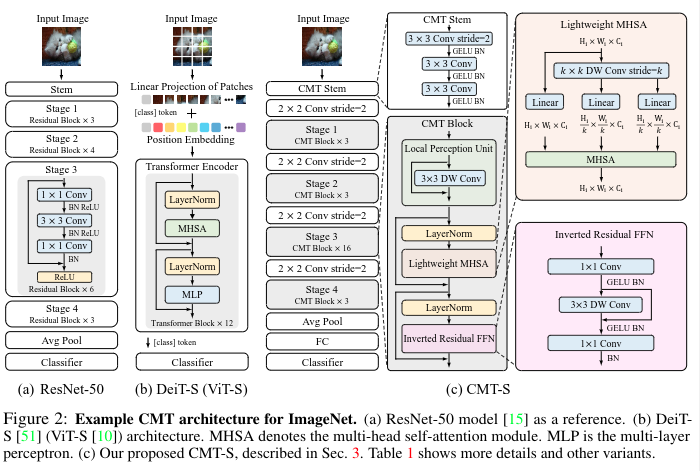
特にポイントとなるのが今回開発されたモジュールなどを組み合わせてつくられた CMT Block となります。
CMT Block
CMT Blockは
① a local perception unit (LPU),
② a lightweight multi-head selfattention (LMHSA) module
③ an inverted residual feed-forward network (IRFFN)
から構成されます。
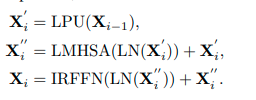
Local Perception Unit
回転や移動といったデータ拡張を行うことで汎化性能をあげることがCNNでは行われていますが、Transformerではパッチ化するせいでローカルな関係性や構造的情報を無視しているため、そうしたことができないという問題点があります。
ローカル情報を抜き出すためのユニットとして、CNNを利用したLPUが作られています。
![]()
X∈R^H×W×d、H×W=画像のステージごとの解像度、d=特徴量マップの次元、DWConv=depth-wise convolution
Lightweight Multi-head Self-attention
self-attentionをそのまま利用すると計算量・メモリが大幅に増加するため、軽量化したSelf-attentionが利用されています。
普通のSelf-attentionは以下のように計算されます。
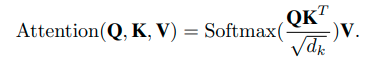
ここからまず計算量のオーバーヘッドをへらすために、K・Vをdepth-wise convolution を利用して小さくします。
![]()
![]()
そこに相対的位置バイアス項 B ランダムに初期化され、学習される)を加えます。これはサイズm1×m2に簡単に変換することができ、このことで他のタスクにファインチューニングするときに簡単にすることができるようになります。
![]()
なお、ヘッドhはn×d/hになるように構築されます。
以上を組み合わせると、Lightweight Multi-head Self-attentionになります。
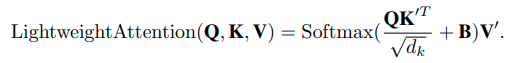
Inverted Residual Feed-forward Network
通常のTransformerのFFNは、活性化関数のGELUを利用したものが使われています。
![]()
CMT Block では MobileNetV2 で使われていた inverted residual block を応用する形で、depth-wise convolution を利用したものをFFNの代わりに利用しています。加えて、ショートカット接続の位置を変えることでよりよいパフォーマンスになっています。
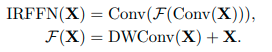
計算コストについて
計算コストが比較されています。
まず、通常のTransformer Blockの計算量は以下になります。
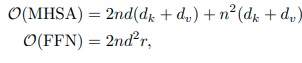
![]()
CMT Blockの計算量になります。k≧1以上であり、大きく計算量が削減されていることがわかります。
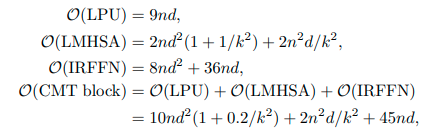
実験
ImageNetによるクラス分類
ImageNetを利用したクラス分類タスクで精度比較が行われています。
●実験時の基礎項目
データセット:ImageNet(学習用1.28M、検証用50K、クラス:1000)
エポック:300
最適化関数: AdamW
GPU:8 NVIDIA Tesla V100 GPUs.
モデルアーキテクチャ図
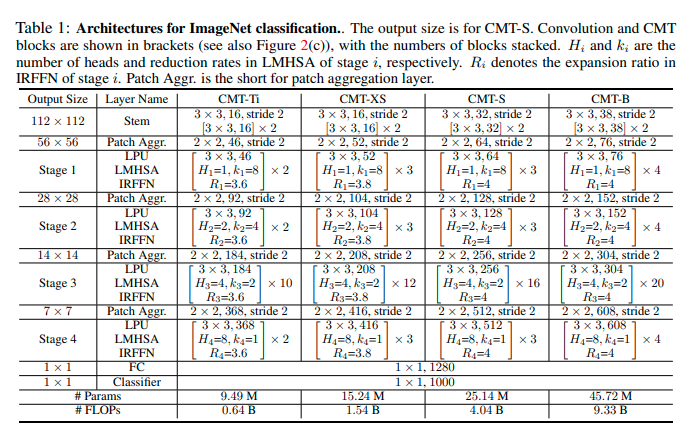
実験結果
同程度のサイズのなかでは一番計算効率及び精度がよいことが示されました。
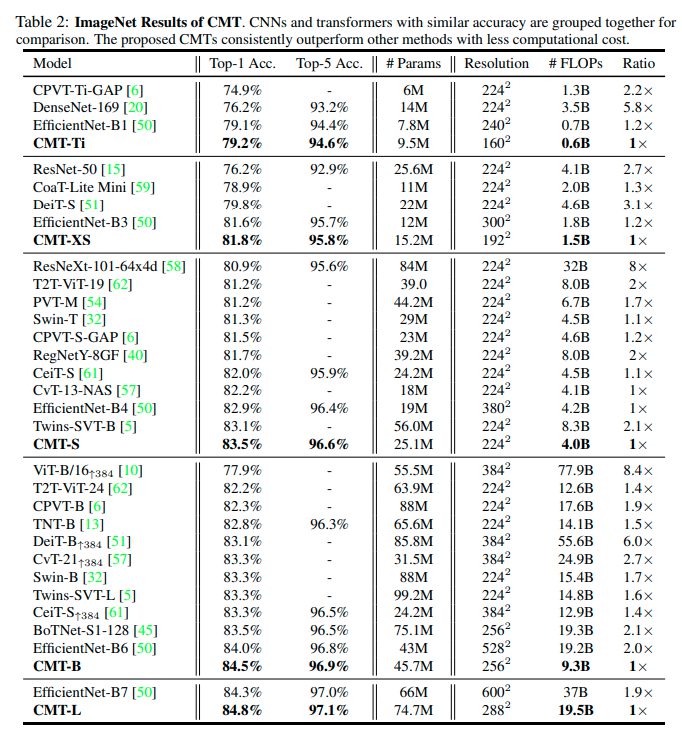
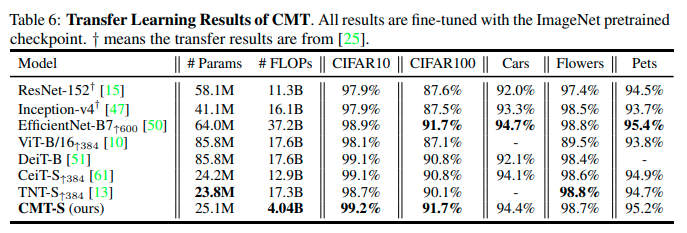
転移学習結果
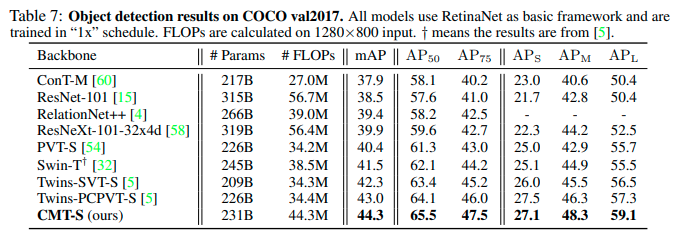
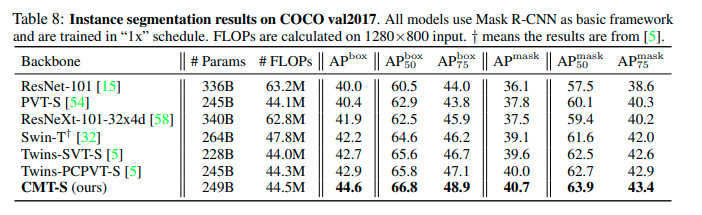
物体検出及びセグメンテーションがCOCOを利用して行われています。どのタスクでも同程度のサイズでは性能が良いことが確認できます。
●実験時の基礎項目
データセット:COCO(学習用118K、検証用5K、クラス:80)
エポック:12
物体検出の結果
セグメンテーションの結果
その他の結果
まとめ
ViT と CNN をバランスよく組み合わせることで、性能と速度の両立を可能にした CMT の詳細解説を行いました。
もともと Transformer は特に画像認識分野ではスケーラビリティの良さのために利用されていましたが、効率の良さは疑問視されていました。そのため gMLP などでは Transformer の限界のひとつにもあげられていました。しかし、一方で gMLP などでは Attention と MLP をうまく組み合わせることが精度上よくなることが明らかになっており、今後 MLP系の CNN や RNN と Transformer をいかに組み合わせるかが重要になると考えられます。