
1. 概要
1.1 LightGBMとは
LightGBMとは、2016年にMicrosoft社が開発したGBDT(Greadient Boosting Decision Tree, 勾配ブースティング決定木) のフレームワークまたはアルゴリズムです。 勾配ブースティング決定木(以下、GBDT)は効率性・正確性・解釈性に優れており、広く利用されている機械学習アルゴリズムです。 また、GBDTはマルチクラス分類、クリック予測など多くの機械学習タスクで用いられています。
LightGBMは、他のGBDTに比べ軽い(計算が早い, メモリの消費が少ない)という特徴を持ちます。
1.2 GBDTについて
GBDTとは、 “勾配降下法(Gradient)”、“アンサンブル学習(Boosting)”、“決定木(Decision Tree)”の3つの手法が組み合わされた機械学習の手法のことです。この記事では、勾配降下法、アンサンブル学習、決定木についての説明を省略します。
2. 詳細
2.1 背景
GBDTは優れた機械学習アルゴリズムであったことから、さまざまな機械学習タスクで最先端の性能を達成していました。そして、2017年以前に特徴数やインスタンス数の多いビックデータの出現に伴い、GBDTはそれまで以上に注目集めてきました。しかし、そこで精度と効率のトレードオフという新たな問題に直面しました。
2.2 問題点
GBDTは決定木のアンサンブルモデルで、決定木は順番に学習していきます。
それぞれの決定木は、各反復において負の勾配(残余誤差)をフィッティングすることで学習します。GBDTの主なコストは決定木の学習にあり、最適な分岐点を見つけることに最も時間がかかります。
分岐点を見つける従来の一般的なアルゴリズムは2つあります。
[従来のGBDTアルゴリズム]
・ソート済みアルゴリズム
→ ソート済みの特徴量に基づき、可能な全ての分岐点を列挙し最適な分岐点を見つけるアルゴリズムです。しかし、学習速度とメモリ消費量において非効率的です。
→ 値が0の特徴を無視することで学習コストを削減できます。
・ヒストグラムベースアルゴリズム
→ 連続した特徴量を離散的なビンに分割し、学習時にそのビンを用いて特徴量のヒストグラムを構築し最適な分岐点を見つけるアルゴリズムです。学習速度とメモリの消費の両方において効率的です。
→ ヒストグラムの構築には”data×feature”だけのコストがかかり、分岐点の探索には” bin×feature”だけのコストがかかります。
→ 通常、ビンはデータよりもはるかに小さいため、ヒストグラムの構築が大半の計算量を占めます。そのため、データインスタンスと特徴量を減らすことがGBDTの学習を大幅に高速化することにつながります。
→ しかし、この手法は特徴量の値に関わらず各データインスタンスについて特徴量のビンの値を取得する必要があるため(図4の赤枠の部分を参照)、高速化を実現することができませんでした。

図4: ヒストグラムベースアルゴリズム
(引用先: 参考文献[1])
従来のGBDT(ソート済み、ヒストグラムベース)では、全ての特徴量に対して、全てのデータインスタンスをスキャンし、全ての可能な分岐点の情報利得を推定する必要あります。その際の計算量は特徴量数とデータインスタンス数に比例するため、 実装にかなりの時間がかかるという問題が生じていました。このような従来の手法の限界を解決するために、特徴量数とデータインスタンス数を減らし実装にかかる時間の短縮を実現する新しい手法が提案されました。その手法を以下に示します。
[新しいGBDTアルゴリズム]
・GOSS (Gradient-based One-Side Sampling)
→ データインスタンス数を減らすための手法のことです。
・EFB (Exclusive Feature Bundling)
→ 特徴量数を減らすための手法のことです。
従来のGBDTの問題点に対して、上記の2つの新しい手法を実現したものが “LightGBM”です。
2.3 Gradient-based One-Side Sampling (GOSS)
一般に決定木のアルゴリズムが分岐する点を探索する際には各データインスタンスの勾配が計算されます。また、あるデータインスタンスが小さな勾配であるとき、誤差が少なく十分に学習されているということになります。そのため、小さな勾配であるデータインスタンスを省けばデータインスタンス数を減らすことができ学習を高速化できます。しかし、そうしてしまうとデータの分布が変化し学習したモデルの精度の低下を招いてしまいます。
そこで、GOSSでは以下の方法で学習したモデルの精度を維持するようにデータインスタンス数を減らしています。
その原理を以下で説明します。
[GOSSの原理]
(1) データインスタンスを勾配の絶対値でソートし、上位 $ a*100% $ のデータインスタンスを選択します(勾配の大きいデータインスタンスを残す)。
- 例: $ a=0.8 $ → $ 0.8*100% = 80%$ → 上位 $ 80% $ のデータインスタンスを残します。
(2) 残りのデータインスタンスから $ b*100% $ のデータインスタンスをランダムに選択します(勾配の小さいデータインスタンスをランダムで残す)。
- 例: $ b=0.05 $ → $ 0.05*100% = 5%$ → 全体の $ 5% $ のデータインスタンスを残し, 残りの $ 15% $ は削除します。
(3) その後、選択されたデータインスタンスのうち勾配の小さいものを $ \frac{1-a}{b} $ だけ増幅して情報量を計算することで、データの分布を崩さずデータインスタンス数を減らすことができます。
- 例: $ \frac{1-a}{b}=4 $ → 勾配の小さいもの( (2)で選択した $ 5% $ 分のデータ )を4倍します。
上記の方法のアルゴリズムのコードを以下に示します。

図5: GOSS
(引用先: 参考文献[1])
2.4 Exclusive Feature Bundling (EFB)
特徴量がたくさんある高次元なデータは非常にスパース(データの本質を表すようなデータはデータ中に僅かしか含まれない)です。そのため特徴量を選択し、特徴量数を減らすことができれば、精度をほとんど落とすことなく効率的な学習を行うことができます。スパースな特徴空間では、多くの特徴量は相互に排他的であり、同時に0以外の値を取ることはないため、 このような排他的な特徴量は1つの特徴量としてまとめる(束ねる)ことができます。これを”Exclusive Feature Bundle”といいます。よって、個々の特徴量から得られる同じ特徴のヒストグラムをFeature Bundleから構築することができます。したがって、ヒストグラムベースアルゴリズムでのヒストグラム構築のコストは”data×bundle”となり、GBDTの学習を高速化することが可能になるというわけです。(より詳細なEFBの原理は参考文献[1]をご参照ください。今回は割愛させていただきます。)
3. 実験
3.1 実験環境
以下の表1の実験環境でLightGBMの検証実験が行われました。
表1: 実験環境
| 実験セットアップ項目 | 詳細 |
| データセット | ・Microsoft Learning to Rank (LETOR)
・The Allstate Insurance Claim ・Flight Delay ・KDD CUP 2010 → NTUの優勝ソリューションが使用した特徴量 ・KDD CUP 2012 → NTUの優勝ソリューションが使用した特徴量 |
| マシン | [CPU]
・E5-2670 v3 CPU × 2 (合計24コア) [メモリ] ・256GB [サーバ] ・Linux [スレッド数] ・16 |
| モデル | ・ソート済みアルゴリズムを使用したXGBoost
・ヒストグラムベースアルゴリズムを使用したXGBoost
・GOSSとEFBを使用していないLightGBM
・EFBのみ使用したLightGBM
・GOSSとEFBを使用したLightGBM
|
| パラメータ | [GOSS]
・Allstate, KDD10, KDD12: a=0.05, b=0.05 ・Flight Delay, LETOR : a=0.1, b=0.1 [EFB] ・全てのデータセット : γ=0 |
さらに、以下の図6に検証実験で使用したデータセットの詳細について示します。

図6: 実験で使用したデータセット
(引用先: 参考文献[1])
3.2 実験結果
3.2.1 計算コストの比較
以下の図7は、データセットを用いて1回の反復学習にかかる平均時間コスト[s]をモデル間で比較したものです。
GOSSとEFBを使用したLightGBMが他の4つのモデルと比較して全てのデータセットにおいて平均時間コストが少ないことがわかります。lgb_baselineと比較して、それぞれ約21倍, 6倍, 1.6倍, 14倍, 13倍と高速化できています。
また、lgb_baselineとEFB_onlyを比較すると、EFBが計算の高速化に大幅な貢献をしていることがわかります。 つまり、 EFBは大規模なデータセットに対して、GBDTの学習過程を大幅に高速化できる手法です。
さらに、EFB_onlyとLightGBMを比較すると、GOSSで10-20%([a: 0.05, 0.1], [b: 0.05, 0.1]であることから)のデータを使用すると2倍近い速度を実現することができています。
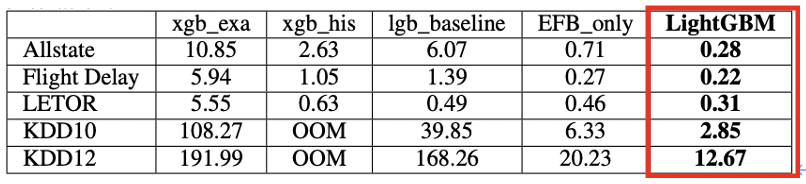
図7: 学習時間コストの比較
(引用先: 参考文献[1])
3.2.2 精度の比較
以下の図8は、各データセットのテスト用データを使用した際の精度をモデル間で比較したものです。
分類タスクにはAUCという評価指標を用いており、ランキングタスクにはNDCG (NDCG@10としている)という評価指標が用いられています。また、SGBとはlgb_baselineにStochastic Gradient Boosting (確率的勾配降下法)を加えたものです。
GOSSとEFBを使用したLightGBMがlgb_baselineと同等の優れた精度であることがわかります。
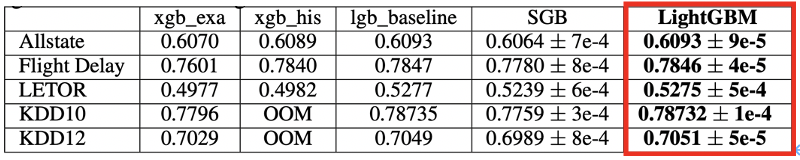
図8: テストデータセットに対する精度の比較
(引用先: 参考文献[1])
また、以下の図9は、データセットFlight Delay、LETORにおいてそれぞれAUC、NDCGの評価指標を用いた場合の全モデルの学習過程をグラフ表示したものです。左図はデータセットFlight Delayを用いた学習過程、右図はデータセットLETORを用いた学習過程を示しています(詳細は図6をご参照ください)。
以下のグラフから、 GOSSとEFBを用いたLightGBMがlgb_baselineの精度を維持しながら計算を高速化できていることがわかります。
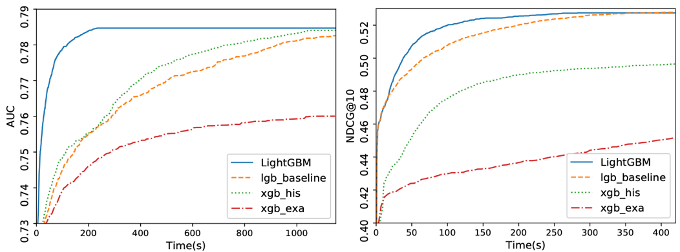
図9: データセットの学習過程
(引用先: 参考文献[1])
4. まとめ
・LightGBMには2つの新しい手法が含んだGBDTアルゴリズムのことです。
- ① Gradient-based One-Side Sampling
- ②Exclusive Feature Bundling
・LightGBMは計算速度とメモリの消費量の点で従来のGBDTアルゴリズムを大幅に凌駕しています。 また、精度も従来のGBDTアルゴリズムと同等のものであることが確認できました。
参考文献
[1] Guolin Ke et al., “LightGBM: A Highly Efficient Gradient Boosting Decision Tree”, 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
[2] shouta, “LightGBMの論文を読んだ記録”,
URL: https://qiita.com/shoutaqiita/items/340dc87f7f244f6c56c5, Qiita, 2020.
[3] kuroitu S, “勾配ブースティング決定木ってなんぞや”,
URL: https://qiita.com/kuroitu/items/57425380546f7b9ed91c, Qiita, 2020.
[4] “勾配降下法とは?わかりやすく図解で解説”,
URL: https://nisshingeppo.com/ai/gradient-descent/, 機械学習ナビ, 2021.
[5] ウマたん, “アンサンブル学習とは?バギングとブースティングとスタッキングの違い”,
URL: https://toukei-lab.com/ensemble, スタビジ, 2021.
[6] LightGBM公式ドキュメント,
URL: https://lightgbm.readthedocs.io/en/latest/index.html