
今回取り上げる論文はこちらです。
LayoutGAN : Generating Graphic Layouts with Wireframe Discriminator
0.選定理由
この記事を読んで頂いている方は、ポスターや広告、Web画面、アプリの画面などを作成する際に、デザインやレイアウトで困ったりすることはありませんか? 私はよくよく困ってます(笑)
なので、私はデザインとかレイアウトとかもっと手軽に出来たら嬉しいなと思っているわけです。
これまでも、GANで生成してくれないかなと見てきたのですが、あまり良いモデルがありませんでした。
例えば、位置の指定や物体同士の関係性が表現できるものとしては、「Image Generation from Scene Graphs」があり、こちらで遊んでみたことはありますが、実用には遠い生成物が出来上がりました(笑)
そのため、もっと良い手法がないかなと思っていた所、今回、レイアウトを生成するというアプローチで論文が出ていたので、こちらを纏めさせて頂きます。(なお、本手法はレイアウト生成であってコンテンツ表現までを含むものではないので、ポスターや広告、Web画面、アプリの画面などを作成するには、更なる手法が必要です。)
それでは、以下に論文の内容を紹介していきます。
※文中のGはGenerator、DはDiscriminatorを表しています。
1.概要
従来のGANは、ピクセルレベルでレイアウトを合成するため、異なる要素間の依存性を正確に特定できず、配置やレイアウトスタイルをうまくとらえることができません。そこでLayoutGANは、意味論的・幾何学的関係をモデル化することによってこの問題を解決しようとします。
LayoutGANは、GANの一種なので、GeneratorとDiscriminatorによって学習を行います。Generatorは、関係をモデル化することによってグラフィックレイアウトを生成します。DiscriminatorはGeneratorの生成物と実データの真偽を識別しますが、本論文ではDiscriminatorとして、2つのモデルが提案されています。それが、「関係ベース識別器」と、「ワイヤフレームレンダリング識別器」です。関係ベース識別器は、グラフィック要素間の関係性を直接抽出して識別を行います。ワイヤーフレームレンダリング識別器は、グラフィック要素をラスタライズして画像をワイヤフレーム化し、要素配置から位置合わせをできるようにしています。
これらのモデルを、MNISTの生成やドキュメントレイアウトの生成、抽象的なシーン生成などの実験を通じて、有効性を示しています。
2.提案手法
これが、LayoutGANのアーキテクチャです。
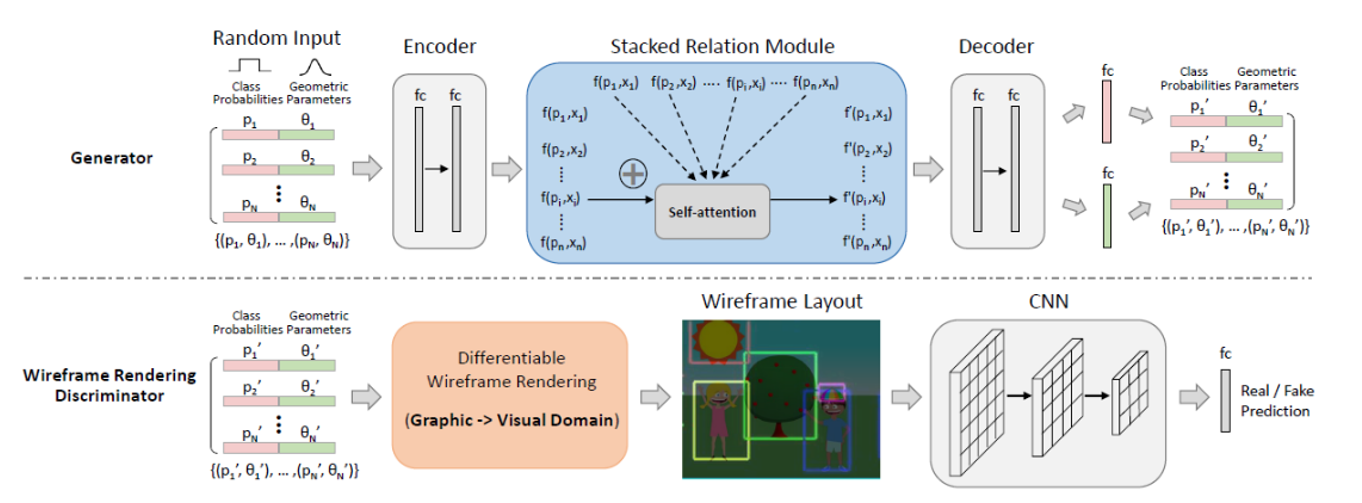
LayoutGANは、画素レベルの画像を生成する代わりに、{(p1, θ1), …, (pN, θN)}で表される要素の集合を合成します。ここで、pはクラス確率であり、θ=θ1、…、θmは、様々な図形レイアウトに対して様々な形態をとることができる幾何学的パラメータです。例えば、2点集合の生成についてはθ= [X、Y]であり、バウンディングボックス生成(文書レイアウト)についてはθ= [X1, Y1, X2, Y2]、ポジション、スケール、フリップを同時に考慮したグラフィックレイアウトでは、θ= [X、Y、S、F]で定義することができます。
Generatorは、関数Gを学習することが目的です。関数Gは、無作為にサンプリングされたクラスラベルと幾何学的パラメータ(pi, θi),(i = 1, …, N)を有するz={(p1, θ1), ···,(pN, θN)}を入力として、本物のグラフィックレイアウトに似せたレイアウトG(z)=(p’1, θ’1),…, (p’N, θ’N)を生成する関数です。
Discriminatorは、関係ベース識別器と、ワイヤフレームレンダリング識別器の2つを提案していますが、こちらの図は、ワイヤフレームレンダリング識別器の図です。ワイヤフレームレンダリング識別器は、グラフィックドメインとビジュアルドメインの両方からレイアウト最適化のための異なる要素間の意味論的関係と幾何学的関係を捕らえることを学びます。グラフィック要素の合成データと実構造データの両方をワイヤフレーム画像にラベリングし、CNNを使用してビジュアル領域とグラフィック領域のレイアウトを最適化することができる新しいワイヤフレーム描画レイヤーを提案しています。
続いて、GとDの設計の詳細について説明します。
2.1 Generatorアーキテクチャ
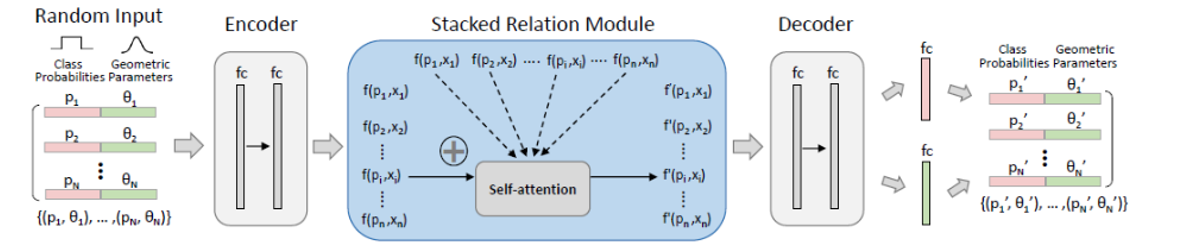
Generatorは、ランダムなクラスラベルと幾何学的パラメータを持つグラフィック要素のセットを入力として受け取ります。FC層からなるエンコーダは、最初に、各グラフィック要素のクラスラベルおよび幾何学的パラメータを埋め込み、Stacked Relation Moduleに渡します。Stacked Relation Moduleは、Self Attentionの構造を持ったモジュールで、各要素間の関係性を計算します。(詳細は[1]をご参考ください。)そして、セット内の他のすべての要素との意味論的関係および空間的関係をモデリングすることによって、各グラフィック要素の埋め込み特徴量を精緻化します。
図形要素iの埋め込み特徴としてf(pi, θi)を表す場合、精緻化した特徴表現f'(pi, θi)は、次の式によって得ることができます。
https://deepsquare.jp/wp-content/uploads/2019/12/layoutgan-shiki1.png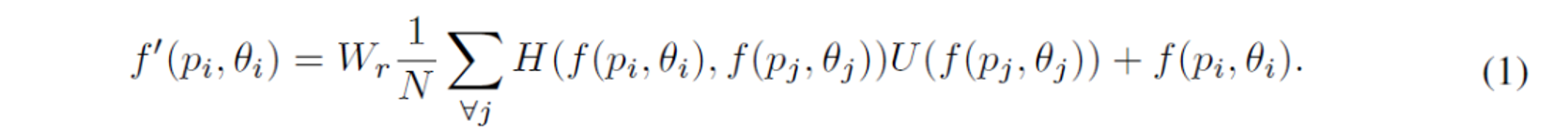
ここで、jは要素インデックスであり、単項関数Uは、要素jの埋め込み特徴f(pj, θj)の表現を計算します。ペアワイズ関数Hは、要素iと要素jとの間の関係を表すスカラー値を計算します。したがって、他のすべての要素 j≠iにおいて、それらの関係を合計することによって要素iの特徴を細分化することができます。また、集合内の要素の総数Nで割ることによって正規化しています。重み行列Wrは線形埋め込みを計算し、特徴の細分化のためにf(pi, θi)上に付加される残差を生成します。Hをドット積として定義すると、次の式で表現できます。
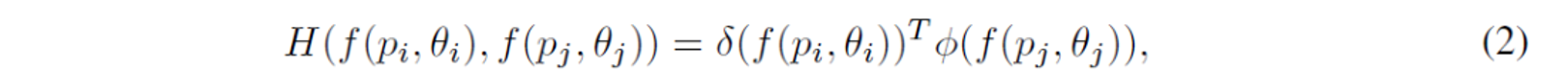
ここで、δ(f(pi, θi))=Wδf(pi, θi)およびφ(f(pj, θj))=Wφf(pj, θj)は2つの線形埋め込みです。特徴の細分化のためにT=4の関係モジュールを積み重ねています。最後に、別の多層NNとシグモイド活性化を伴うFC層の2つのブランチからなるデコーダを使用して、各要素の洗練された特徴をそれぞれクラス確率および幾何学的パラメータに戻します。必要に応じて、重複しない要素を削除するためにNon-Maximum Suppression(NMS)を適用することができます。
2.2 Discriminatorアーキテクチャ
Discriminatorは、2つのモデルが提案されています。「関係ベース識別器」と、「ワイヤフレームレンダリング識別器」です。関係ベース識別器は、グラフィック要素間の関係性を直接抽出して識別を行います。ワイヤーフレームレンダリング識別器は、グラフィック要素をラスタライズして画像をワイヤフレーム化し、要素配置からの位置合わせを識別できるようにしています。
2つのモデルについて、違いを詳しく見ていきます。
2.2.1 関係ベース識別器
関係ベース識別器は、Generatorと構造が似ています。入力グラフィック要素を埋め込み、グラフィック領域からレイアウト最適化のためのグラフィック関係を抽出します。g(r(p1, θ1)···r(pN, θN))の間のグローバルな図形関係を抽出するために、それらを多層NNからなるエンコーダに供給します。r(pi, θi)は、ジェネレータと同様のrelation moduleから得られます。gはmax-pooling関数です。したがって、すべてのグラフィック要素間のグローバルな関係をモデル化することができ、その上でシグモイド活性化を伴う多層NNによって構成された分類器を使って真/偽の予測を行います。
2.2.2 ワイヤフレームレンダリング識別器

ワイヤフレームレンダリング識別器は、グラフィックドメインとビジュアルドメインの両方から、異なる要素間の意味論的関係と幾何学的関係を学習します。グラフィック要素の合成データと実構造データの両方をワイヤフレーム画像にラベリングし、CNNを使用してビジュアル領域とグラフィック領域のレイアウトを最適化します。CNNを利用するには、グラフィック要素を2D画像に微分可能にマッピングする必要があります。すなわち、ラスタライズ(ビットマップ化)を行います。
下の3つの図は、異なる形状(点、長方形、三角形)のワイヤフレームレンダリングを表しています。黒いグリッドはターゲット画像のグリッドを表し、オレンジ色の点/点線は、画像グリッド上にマッピングされたグラフィック要素を表し、青い実線は、クラス要素と幾何学的パラメータの両方の観点からグラフィック要素の微分可能な関数として表現されたラスタライズされたワイヤフレームを表しています。
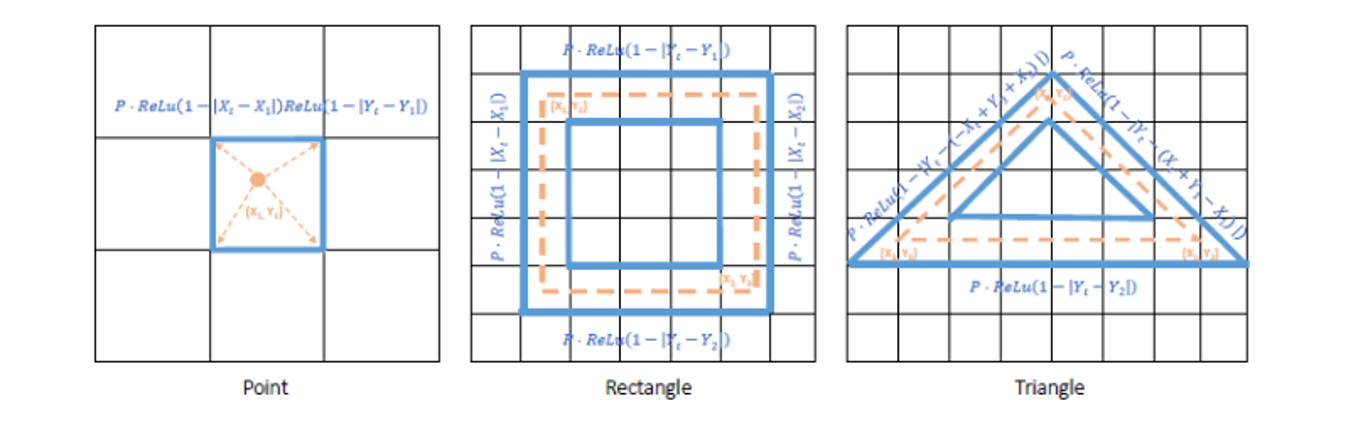
これらの異なる形状をそれぞれ数式で表現することを試みます。すなわち、オレンジ色の線/点線の情報から、青い線を表現します。
ターゲット画像I(Xt, Yt)上に{(p1, θ1), …, (pN, θN)}として表されるN個の要素を有するグラフィックレイアウトをラスタライズすることを考えます。(Xt, Yt)は、あらかじめ定義された規則的なグリッド内に存在します。レンダリングされた画像内の位置(Xt, Yt)上のピクセルI(Xt, Yt)、R((pi, θi),(Xt, Yt))は、次の式で表すことができます。
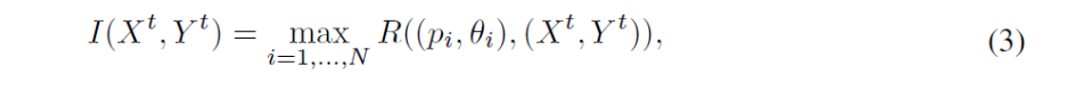
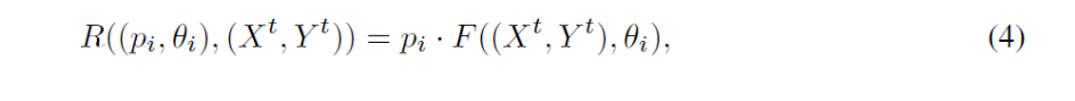
ここで関数Fはグラフィック要素の異なる幾何学的形態に応じて変化するラスタライズを計算します。
まず、最も簡単な要素iの単一キーポイントθi=(X1i, Y1i)についてです。ラスタライズのために補間カーネルkを実装します。レンダリングされた画像における(Xt, Yt)上のその空間レンダリング応答は、以下のように書くことができます。
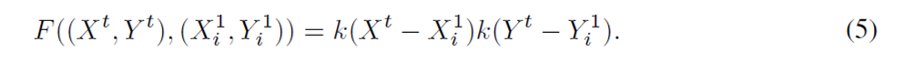
カーネルkは、K(d)= max(0, 1 – | d |)(活性化関数はReLU)を採用しています。R((pi、θi),(Xt, Yt))はクラス確率と座標の一次関数であるので、勾配はそれらの両方に逆方向に伝搬することができます。
次に、長方形の場合です。要素が、左上および右下の座標θ = (X1, Y1, X2, Y2)によって表される矩形または境界ボックスであると仮定すると、これは様々なデザインで利用することができます。具体的には、図2に示すように、座標(X1i, Y1i, X2i, Y2i)を有する矩形iを考えると、黒色グリッドはレンダリングされた画像内の位置を表し、オレンジ色の点線のボックスはラスタライズされる矩形レンダリングされたイメージに表示します。ワイヤフレーム表示の場合、点線枠の境界付近の点(青の実線)は矩形に関連しているため、(Xt, Yt)上の空間レンダリング応答は次のように定式化できます。ここで、b(d)= min(max(0,d), 1)は、ピクセルの近くにレンダリングすることを制約しています。
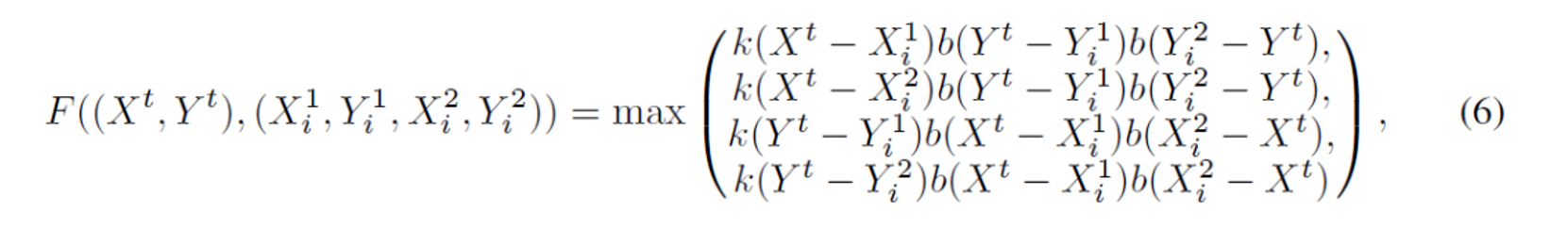
最後に、三角形のワイヤフレームレンダリングプロセスです。3つの頂点の座標θi=(X1i, Y1i, X2i, Y2i, X3i, Y3i)によって表される三角形iに対して、レンダリングされた画像における(Xt, Yt)は、次のように計算できます。
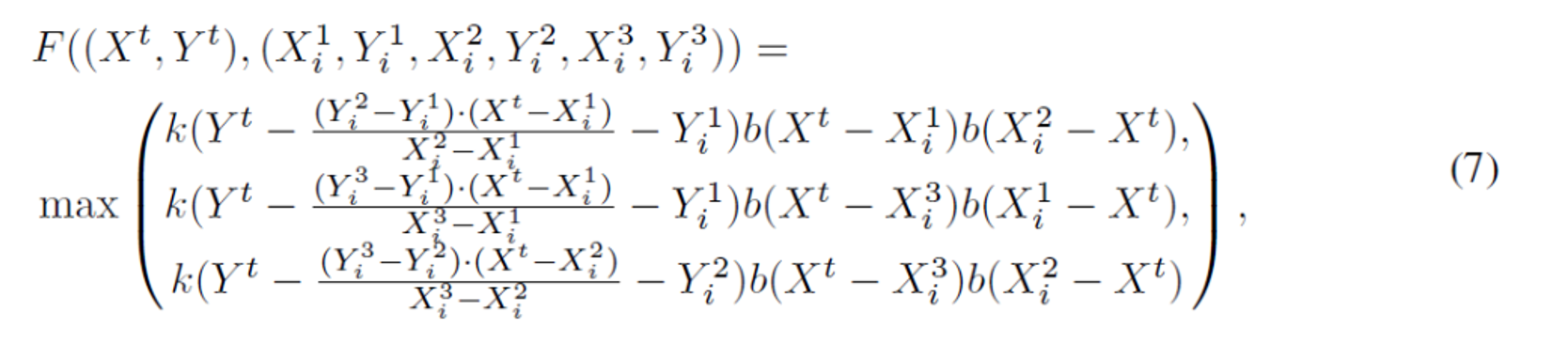
このワイヤフレームレンダリングプロセスを介して、勾配は、最適化のためにグラフィック要素のクラス確率と幾何学的パラメータの両方に逆方向に伝播することができます。3つの畳み込み層+シグモイド活性化を伴うFC層からなるCNNは、グラフィックレイアウトの真/偽を予測するために使用されます。
3.実験結果
3.1 MNIST DIGITS GENERATION
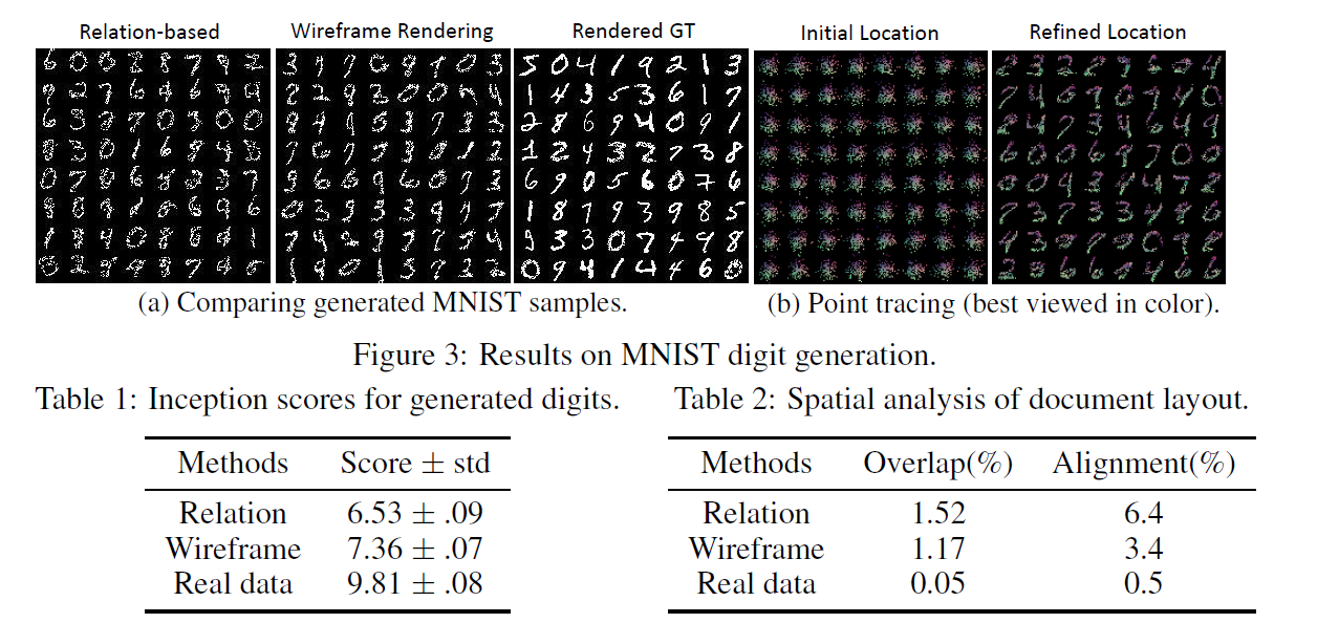
LayoutGANを使ってMNISTを生成しています。各画像について、128個のランダムに選択された前景ピクセルの位置をグラフィック表現として抽出し、生成しています。図3aが左から関係ベース識別器、ワイヤフレームレンダリング識別器、実データを表しています。ワイヤフレームレンダリング識別器は、よりコンパクトで、より良い位置合わせされた点のレイアウトになっているのがわかります。(表1に示す通り、ワイヤーフレームレンダリング識別器の方がスコアも高いです。)
3.2 DOCUMENT SEMANTIC LAYOUT GENERATION

LayoutGANでドキュメントのレイアウトを生成したのが図4です。1つのドキュメントページは、見出し、段落、表、図、キャプション、リストなど、意味の異なる役割を持つ多数の領域で構成されています。各領域はバウンディングボックスで表されます。実際の文書データでは、これらの意味的にラベル付けされたバウンディングボックスは、しばしばいくつかの軸に従って良好に整列され、見出しが段落または表の上に常に現れるなどの特定のパターンに従って配置されます。
この実験では、上記のように6つの意味クラスに属する可能性のあるバウンディングボックスが9個以下で1列のレイアウトを生成しています。上から、DCGAN、関係ベース識別器、ワイヤフレームレンダリング識別器、実データの順です。DCGANは、生成された結果は領域間の位置ずれが発生しています。また、異なるセマンティックブロックが、空間的意味パターンを十分に捕捉できていないことがわかります。また、2行目の関係ベースの識別器と3行目のワイヤフレームレンダリング識別器とを比べると、関係ベースの識別器は重なり合いや位置ずれの問題が生じています。実際のドキュメントレイアウトのバウンディングボックスは左または中央に配置されているため、重複することはありません(図表付きのキャプションを除く)。
本論文では、生成されたレイアウトの品質を定量的に測定するための2つのメトリックを提案しています。1つ目は重複インデックスです。これはページ全体の2つの境界ボックスの中の重複領域の合計の割合を計算しています。2つ目は整列インデックスです。これはすべての境界ボックスの左または中心の座標の最小標準偏差を見つけることによって計算しています。表2に示す通り、ワイヤフレームレンダリング識別器を備えたLayoutGANは、リレーションベース識別器のものより重複インデックスおよび整列インデックスの両方でより低い値を達成することが分かります。
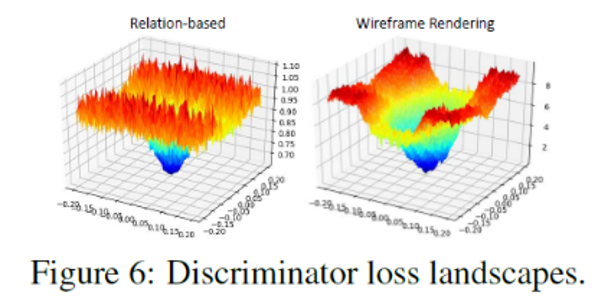
また、損失関数を分析した結果もワイヤフレームレンダリング識別器の方が望ましい結果となっています。具体的には、実際のレイアウトのバウンディングボックスにシフト摂動を加え、それらを両方の識別器に試し、損失挙動を調べています。その結果を図6に示しており、異なる摂動の程度に対応する両方の識別器の損失状況を視覚化しています。ワイヤフレームレンダリング識別器の損失面は、関係ベースの識別器のシフト摂動よりも滑らかであることが分かります。
3.3 CLIPART ABSTRACT SCENE GENERATION
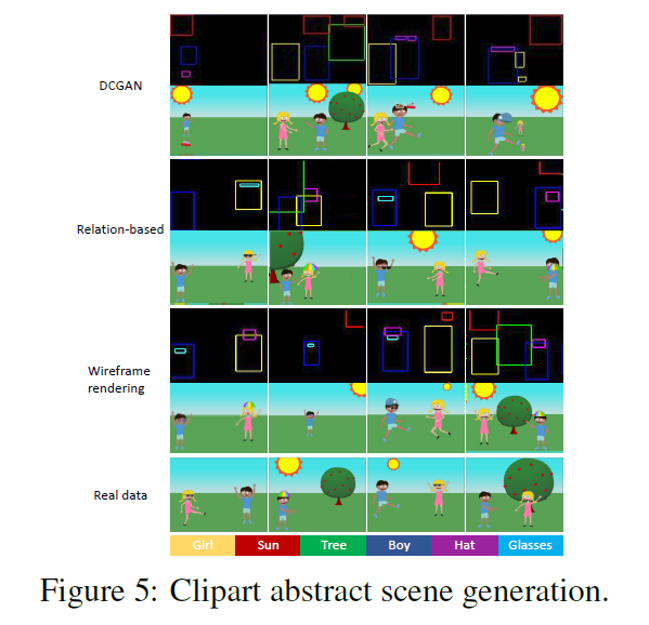
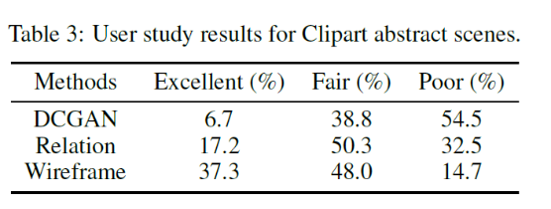
LayoutGANによって特定のクリップアートシーン要素(少年、少女、眼鏡、帽子、太陽、および木)のセットを配置することによって抽象的なシーンを合成する抽象的なシーン生成をしたのが図5です。上から、DCGAN、関係ベース識別器を使用したLayoutGAN、ワイヤフレームレンダリング識別器を使用したLayoutGANによって生成されたシーンを示しています。最後の行は、実データのいくつかのサンプルです。特に、帽子や眼鏡などのオブジェクトに注目すると、DCGANや関係ベースの識別器を使用したLayoutGANよりも、ワイヤフレームレンダリング識別器を使用したLayoutGANの方が、オブジェクト同士の関係性をより正確に捕捉し、正確なシーンレイアウトを形成することがわかります。論文では、さらに結果を主観的に評価するために、20人の回答者を対象としたユーザー調査を実施しており、こちらの結果も表3が示す通り、ワイヤフレームレンダリング識別器を使用したLayoutGANの評価が高い結果となっています。
4.まとめ
リレーショナルグラフィック要素のレイアウトを生成するための新しいLayoutGANを紹介しました。
LayoutGANは、ピクセルレベルでイメージを生成する従来のGANとは異なり、一連のリレーショナルグラフィック要素を直接出力できる点が面白いなと思いました。今後は、レイアウトだけでなく、各グラフィック要素にテキスト、アイコン、画像などのコンテンツ表現を追加することができたらもっと面白いものが生成できそうで楽しみです。
※本記事はQiitaにも同様の内容を投稿しております。
参考文献
[1]XiaolongWang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. arXiv preprint arXiv:1711.07971, 2017.
[2]Mart´ın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016.
[3]Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. Learning representations and generative models for 3d point clouds. arXiv preprint arXiv:1707.02392, 2017.
[4]Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
[5]Zoya Bylinskii, Nam Wook Kim, Peter O’Donovan, Sami Alsheikh, Spandan Madan, Hanspeter Pfister, Fredo Durand, Bryan Russell, and Aaron Hertzmann. Learning visual importance for graphic designs and data visualizations. In Proceedings of the 30th Annual ACM Symposium on User Interface Software & Technology, 2017.
[6]Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hibschman, Daniel Afergan, Yang Li, Jeffrey
Nichols, and Ranjitha Kumar. Rico: A mobile app dataset for building data-driven design applications.