はじめに
近年、画像認識の世界は目覚ましい進歩を遂げています。先日、Transformer(Attentionを利用した構造が特徴)を利用したDETRがFacebookのリサーチチームから発表され、大きな話題となりました。(参考としてこちらを紹介した記事も下記でご紹介しています。)今回、取り上げるのは同じくAttentionを構造に取り入れた「Object-Centric Learning with Slot Attention」という論文です。しかし、このSlot-Attentionを支えている概念はDETRなどとは異なる「物体中心表現(Obejct-Centric representations)」というものです。「物体中心表現」とは、本来三次元である「物体」を二次元情報(画像)から人間が認識する際に活用していると考えられる「構造をもつ潜在表現」をさす言葉です。(なお、人間の認知構造をめぐっては専門家の間でも様々な仮説の妥当を巡って議論が行われているようです。)
「物体中心表現」を利用したモデルとは一般的に——DETRなど多くの画像認識モデルが画像二次元情報だけを参考にして写っているものを認識するのに対して——より柔軟で正確な物体認識を目指し、(人間が二次元画像を認知する際に利用していると考えられる)より高次元で抽象的な潜在表現を利用するモデルのことを意味しています。この分野は人間の認知構造を正確に模すことで、将来的に人間のような(教師なし)画像から新たなものを認知できることを目指しているものが多いという傾向もあります。
以下、論文の概要から詳細なモデルまでみていきます。
発表論文
「Object-Centric Learning with Slot Attention」
https://arxiv.org/abs/2006.15055
※比較のためにこちらの記事もご紹介させていただきます。
「Transformer を物体検出に採用!話題のDETRを詳細解説!」
https://deepsquare.jp/2020/07/detr/
PPT版はこちらをご参考下さい。
論文概要
「Object-Centric Learning with Slot Attention」論文とは
・Google ResearchのBrain Teamが中心となって2020年6月に発表された論文。
・「物体中心表現(Obejct-Centric representations)」という構造情報をもつ潜在表現を獲得し、物体認識のために利用する手法が提案されている。
・中核を占めるアイディアは、低次元の知覚入力から物体中心の抽象表現を学習する多目的アーキテクチャコンポーネント「Slot-Attention」とよばれるもの。
⇒Self-Attentionで取得したAttentionスコア(重み付き平均)をinputとして、GRUを用いてSlot(CNN等から得られた局所特徴=潜在変数の集合)を更新していく。
・教師なしの物体検出と教師ありの物体特性予測の実験では、従来の手法と比べメモリ消費と計算の面でより効率的でありながら、高い精度が確認されている。
論文の主な貢献
論文では以下の貢献があるとされています。
(i)知覚的表現(CNNの出力など)と集合として構造化された表現との間のインターフェイスとして、シンプルなアーキテクチャ・コンポーネントであるSlot-Attentionモジュールを導入したこと。
(ii) 教師なし物体検出にSlot-Attentionベースのアーキテクチャを適用し、よりメモリ効率が高く、訓練時間が大幅に短縮したうえで、関連する最先端のアプローチと一致するか、またはそれを上回る性能を発揮したこと。
(iii) オブジェクトのセグメンテーションを教師なしで学習したうえで、教師付き物体特性予測にSlot-Attentionモジュールが使用できることを実証したこと。
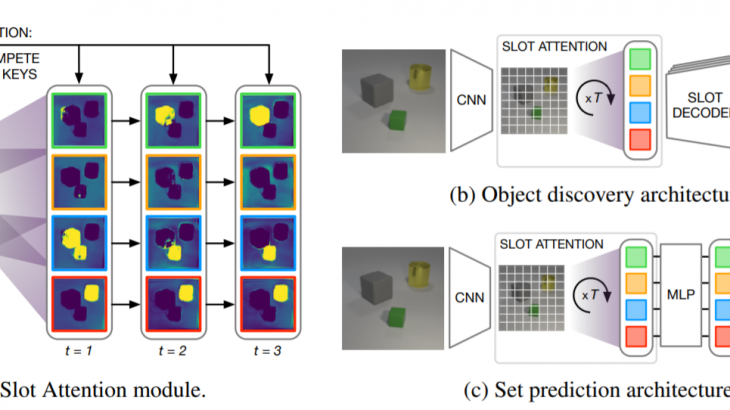
モデル構造
Slot-Attentionのモデル構想を説明します。
①CNNによって画像特徴量を抽出する(ImageFeatures)
②Positional embeddingで位置情報をImageFeaturesに付与する(ImageFeatures₊Position)
③Self-AttentionでImageFeatures+PositionのAttentionスコア(重み付き平均)を取得する(Input)
④Slot-AttentionでInput(k, v)とSlot(q)からAttentionスコアを取得する。
⑤T回反復してSlotを学習させ、Inputのなかの任意のオブジェクトと相同関係を構築する。
※④と⑤がSlot-Attention moduleと呼ばれています。
⇓
得られたSlotを利用して物体検出や分類のタスクに応用させています。ただし、Slotがもつ潜在表現はタスク依存のものとなるため、事前に応用させるタスクは設定しておく必要があります。
論文詳細解説
物体中心表現について
物体中心表現を考える前に、まず物体を認識するとはどういうことでしょうか。 ここでは、ひとまず外界から視覚的に得られた情報を自分の中にある記憶と照らし合わせる処理過程であるとします。そうすると、機械に物体認識を行わせるとは、入力した視覚的な情報から機械内に保持された何かしらの情報を使って何が写っているのかを提示させることを意味します。物体認識という動作を考えると、そこには単純に解決できない問題が存在していることがわかります。
そこでまず問題になるのは、網膜に投影された画像は本来、外界に存在する三次元の拡がりを持った物体を二次元の面上に投影したものであるということです。つまり、これはいわゆる逆問題(出力から入力を推定する問題)に分類されるものですが、根本的に奥行きに関する情報を欠落しているため、数学的には一意の解を求めることが不可能な不良設定問題(問題を解くために必要な情報がそろっていない問題:どこまで計算したとしても確実な解を定めることができないことを意味する)になります。
そして、物体認識が抱えるもう一つの問題は、 同一の物体が様々な条件によってその外観を変化させるということです。 例えば、観察者の立ち位置や日の当たり方などで物体の見え方は大きく異なりますが、通常、人間はそのような変化に対して安定した認識を持っています。それに対して、機械による物体認識はそのような変化に対して一般的に脆弱性があります。
しかし、そもそも人間も機械に与えられている情報と変わらないもので正しい認識ができることを考えると、人間は何かしら別な情報を利用しているのではないかと考えることもできます。このような考え方を支えているのが、人間の物体認知における考え方の一つである「網膜像の変化に関して人間内部の表現が不変なものであれば、安定した物体認知を達成することができると考えることができ、その表現とは物体中心の三次元表現ではないか」という発想です。
このような考え方に基づき、物体中心表現を機械に学習させることで、より正確でかつ汎用性の高い物体認知モデルを構築することができるではないか、というのが物体中心表現という潜在表現を獲得させようというチームのモチベーションになります。
実際、今回の論文では「複雑なシーンの物体中心の表現を学習することは、低次元の知覚特徴から効率的な抽象推論を可能にするための有望なステップである(Learning object-centric representations of complex scenes is a promising step towards enabling efficient abstract reasoning from low-level perceptual features.)」と述べています。つまり、物体中心表現を獲得することで、画像のような低次元情報(二次元)から物体のようなより高次元情報(三次元)推論を可能にすることができると主張しています。
※補足
本論文の本筋からは離れてしまいますが、こちらのサイト(https://www.jcss.gr.jp/journal/vol06/060406/node1.html)で紹介されている理論は今回の「物体中心表現」が実際にどのように使われているのかをイメージする上では参考になるのではないでしょうか。
こちらのサイトでは実験結果から人間の認知能力には①処理速度が速いが視点汎化性能の低いモジュールと、② 処理速度が遅いが視点汎化性能の高いモジュール、の二種類が存在するのではないかという仮説を提案しています。そして、それぞれの特性をいかのような表にまとめています。

引用:https://www.jcss.gr.jp/journal/vol06/060406/node1.html
つまりこれを機械学習モデルに当てはめると、相対的にですが、DETRが二次元的比較処理をすることで処理速度が早い分、汎化能力が低いのにたいして、Slot-Attentionは三次元的比較処理をしているため、処理速度は遅いが、汎化能力が高いといえるのではないでしょうか。
●「物体中心表現」の可能性について
物体中心表現は、「視覚的推論」、「構造化された環境のモデリング」、「マルチエージェントモデリング」、「相互作用する物理システムのシミュレーション」など、さまざまな応用分野で機械学習アルゴリズムのサンプル効率と一般化を向上させる可能性があると論文では指摘しています。
●「物体中心表現」の問題について
画像やビデオなどの「生の知覚入力raw perceptual input」から物体中心表現を得ることは困難であるということが論文では指摘されています。多くの場合、教師またはタスク固有のアーキテクチャを必要としています。その結果、モデルは通常、シミュレーターやゲームエンジンの内部表現などから得られる環境の構造化された表現で動作するように訓練され、物体中心表現を学習するステップは完全にスキップされることが多いと述べています。つまり、ほとんどの深層学習では自然なシーンの構成特性を捉えず(=物体がもつ画像構成特性(物体中心表現)を捉えていない)、画像から取得した分散表現のみを学習していることを意味します。
先行研究について
なお、今回の論文でも名指しされていて、同じように物体中心表現から物体認識を考えている論文を参考としてあげておきます。この二つの論文を理解することで、更にSlot-Attentionの特質が明らかになるかとおもいます。
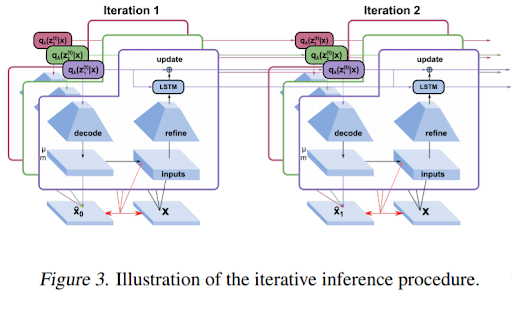
Multi-Object Representation Learning with Iterative Variational Inference
https://arxiv.org/pdf/1903.00450.pdf
・概要
人間の知覚はオブジェクトを中心に構造化されており、それが高次の認知と印象的な体系的な一般化能力の基礎となっているという前提から始まります。そのうえで、表現学習に関するほとんどの研究では、複数の物体を考慮することなく特徴学習に焦点を当てたり、セグメンテーションを(多くの場合、教師付きの)前処理ステップとして扱ったりしているとして問題しています。それらに代わり、この論文ではオブジェクトを分割して表現する学習の重要性を主張しています。
この論文では、シーンが複数の実体で構成されているという単純な仮定から、画像を「分離された表現で解釈可能なオブジェクト」にセグメンテーションする学習が可能であることを示しています。手法としては、空間混合モデルの観点からアプローチし、潜在物体表現を利用することで教師なしで、閉塞した部分を塗り潰すように学習し、より多くのオブジェクトを持つシーンや、新しい特徴の組み合わせを持つみたことがないオブジェクトに外挿していくことで分離していきます。また、反復的変分推論を用いることで、曖昧な入力に対してマルチモーダルな事後処理を学習し、シーケンスにも自然に拡張できることを示しています。
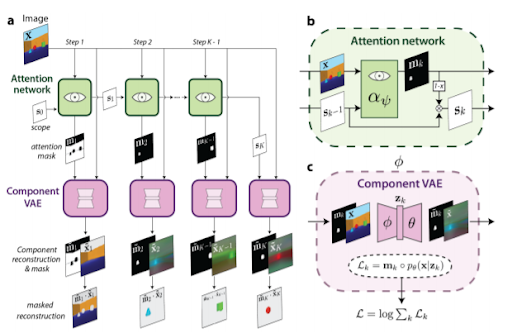
MONet: Unsupervised Scene Decomposition and Representation
https://arxiv.org/pdf/1901.11390.pdf
・概要
リアルな映像シーンには豊かな構造が含まれており、人間はそれを簡単に利用して理性を働かせることができます。効果的かつ知的に 特に、個々の物体を知覚して表現する能力である物体知覚は、我々の感覚を通して知覚された世界を理解すること、そして効率的に相互作用することを可能にする基本的な認知能力であると考えられています。抽象的な構成要素の観点からシーンを分解する能力は、一般的な知性にとって非常に重要であるという前提を持っています。これらの基本的な構成要素がシーン間で意味のある特性、相互作用、その他の規則性を共有している場合、そのような分解は推論を単純化し、新しいシナリオの想像力を促進することができると発想しています。特に、知覚的観測を実体の観点から表現することで、データの効率性と幅広いタスクでの転送性能を向上させることができるというのがこの論文を支えるアイディアです。このような規則性を持つ単位を識別し、共通のフォーマットで表現することで、シーンの有用な分解を発見できるモデルとしてMulti-Object Network (MONet)が提案されています。
このモデルでは、画像の領域の周りの注意マスクと再構成を提供するために、教師なしの方法で、再帰的Attentionネットワークと一緒にVAEをエンド・ツー・エンドで訓練しています。このことでモデルが、困難な3Dシーンを、オブジェクトや背景要素などの意味のある構成要素に分解して表現するために学習できることを示しています。
また同論文は、複数のオブジェクトを持つシーンをうまく表している表現は、以下の条件を満たすべきであることを提案しています。
・シーン内の各オブジェクトに使用される共通の表現空間。
・ オクルージョンを用いて3次元シーン内のオブジェクトを正確に推論する能力。
・可変数のオブジェクトを持つ視覚的なデータセットを表現する柔軟性。
・テスト時に、(i)新しい数のオブジェクトを持つシーン(ii)新しい特徴の組み合わせを持つオブジェクト、および(iii)オブジェクトの新しい共起に一般化することができること。
Slot-Attentionについて
●Slot-Attention概要
Slot-Attentionは前述の「画像やビデオといった生の知覚入力」からは物体中心表現(構成をもつ潜在表現)を得ることが難しいという困難を克服するために考案されました。つまり、CNNなどから得た知覚特徴量と、Slotと呼ぶ物体中心表現変数の集合との間をつなぐことを可能にするものとして、Slot-Attentionモジュールを導入しました。
反復的Attentionメカニズム(an iterative attention mechanism)を用いて、Slot-Attentionは順列対称性を持つ一連の出力ベクトル(=Slot)を生成します。このときのSlotは参考研究にある「カプセルネットワークで使用されているカプセルとは異なり、一般化に悪影響を及ぼす可能性がある特定のタイプやオブジェクトのクラスに特化していない」と論文ではされています。つまり、Slotは汎用性の高い共通の表現形式を獲得しているといえます。(各Slotは、入力内の任意のオブジェクトを格納(およびバインド)できるためです。)これにより、Slot-Attentionは、見たことのない構成、より多くの物体、またより多くのSlotへと体系的な方法で一般化することができるとしています。
●Slot-Attention構造
Slot-Attentionモジュールの具体的な挙動は下記の図に示されています。以下、具体的に何が行われているのかを説明していきます。

attention
Slot-AttentionモジュールはCNNから抽出されたN個の入力特徴ベクトルのセット=Inputを、K個の出力ベクトルのセット=Slotを用いて物体中心(潜在)表現を共通次元Dにマッピングします。そして、このSlot(出力セット)内の各ベクトルは、入力内のオブジェクトまたはエンティティを記述することができるものです。InputをKey、SlotをQueryとしてAttentionスコアをとり、その加重平均をとることでマッピングされています。
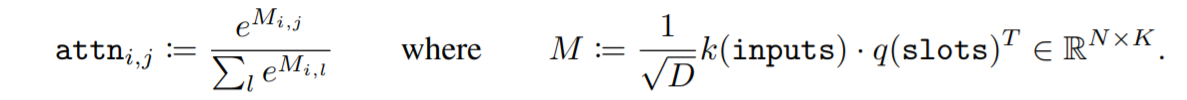
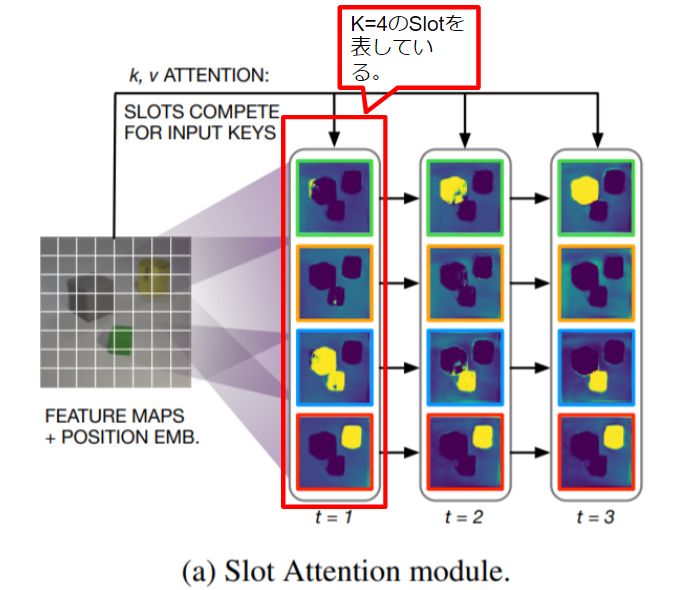
Slotはランダムに初期化され、反復的Slot-Attentionと呼ぶ反復する構造のなかで、Slotの値は入力された特徴の特定の部分に結合するように調整されていきます。初期Slot表現を共有の分布からランダムにサンプリングすることで、テスト時にSlot-Attentionを異なる数のSlotに一般化することができます。
Slot-Attentionでは、内積Attentionが使用されています。これは、Slot全体で正規化されたAttention係数をクエリすることを意味しています。この正規化の選択により、入力の一部を説明するためのSlot間の競合が発生します。またべつの言い方をすればAttention係数の合計が個々の入力特徴ベクトルごとに1になるようにすることで、アテンションメカニズムが入力の一部を無視することを防いでいます。
updates
各反復では、SlotはソフトマックスベースのAttentionメカニズムを介して入力の一部を説明するために競い合い、特徴量を変化させます。具体的にはInputとSlotによって得ることができたAttentionスコアを使って再帰的更新関数によりSlotの表現を更新していきます。なお入力値をそれらの割り当てられたSlotに集約するために、加重平均を使用しています。(Attention係数はSlotにわたって正規化するため、加重和を利用する場合と比較して加重平均を使用することはAttentionメカニズムの安定性を向上させるのに役立つとしています。)
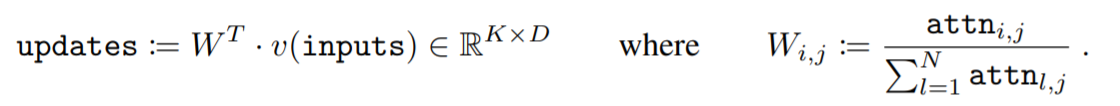
その他
更にGRUの出力をReLU活性化と残差接続を持つ(オプションの)多層パーセプトロン(MLP)で変換することで、性能を向上させることができるとしています。(GRUと残差MLPの両方が、パラメータを共有して各Slotに独立して適用される構造になっています。
モジュールの入力とSlotの特徴の両方にLayerNormを適用しています。これは厳密には必要ではないようですが、学習の収束を早めるのに役立つために利用されているとのことです。
こうして導き出された各Slotの最終的な表現は、教師なし物体検出や教師あり集合予測などの下流のタスクで使用することができます。
●Slot-Attentionの特性
論文では以下の二つを顕著な特性としています。
(1)入力に関するpermutation invariance(つまり、出力は入力に適用される順列とは独立しているため、集合として扱うことに適していることを意味しています)
(2)Slotの順序に関するpermutation equivariance(つまり、初期化後のSlotの順序の入れ替えは、モジュールの出力の入れ替えと同等で集合として扱っても問題ないことを意味しています)。
⇒このpermutation equivarianceが維持されることで、Slotは共通の表現形式を学習し、各Slotが入力内の任意の物体にバインドできることを確実にしています。
DETRやグラフニューラルネットワークなどの近年の研究、特にTransformerモデルのSelf-Attentionメカニズムなどは、一定の濃度(すなわち、集合要素の数)を持つ要素の集合を変換するために頻繁に使用されています。Slot-Attentionは、入力集合と出力集合の両方のpermutation symmetryを尊重することで、ある集合から異なる濃度の別の集合へのマッピングの問題に対処しています。
これに対してDETRなどを含めほとんどの先行研究では、ディープセット予測ネットワーク(DSPN) を除いて、要素ごとに学習した初期化で出力集合の順序表現を学習しているため、これらのアプローチはテスト時に異なる集合の濃度に一般化することができませんでした。(DSPNは、各例に対して内部勾配降下ループを実行することで順列対称性を尊重しますが、これは収束のために多くのステップを必要とし、いくつかの損失ハイパーパラメータを慎重に調整する必要があります。)その代わりに、Slot‐Attentionは、わずか数回のSlot-Attentionの反復と1つのタスク固有の損失関数を使用することで、集合から集合への直接マッピングを行うことを可能にしています。
※permutation invarianceとpermutation equivarianceについて
このpermutation invarianceとpermutation equivarianceの問題に関しては、参考文献にもあげられている「Deep Set Prediction Networks」や「FSPOOL: LEARNING SET REPRESENTATIONS WITH FEATUREWISE SORT POOLING」という論文が深く取り組んでいます。
前者の論文では、「特徴ベクトルから集合を予測する現在のアプローチは、集合の無秩序な性質を無視しており、結果として不連続性の問題に悩まされている」と指摘しています。このことは「集合予測における不連続性による責任問題」という形で提起されています。
どういうことかを後者の論文が取り上げたタスクから説明していきます。
ここで以下のタスクが存在するとします。
タスク
各データポイントが正多角形の頂点を形成する2次元のポイントの集合であるデータセットがあり、データセットのオートエンコーダを学習することを目標とするタスクを設定します。唯一の変数は、(ポイントの数、サイズ、および中心が固定された)この正多角形の原点を中心とした回転角度とします。
このとき、4点の出力の順序には意味がないので、このタスクは集合予想問題ということになります。デコーダーでこの正方形のポイントの1つを生成します。図では、各出力機が出力する点を同じ色にしています。
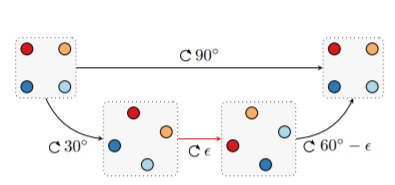
正方形(図の左上)を90度回転させると(図の右上)、集合内の要素を単純に並べ替えたものになります。これらは同じ集合なので、同じ潜在表現にエンコードし、同じリスト表現にデコードする必要があることはわかります。このとき、デコーダーの各出力(機)は回転後も同じ位置のポイントを生成する責任があります。このようにすることで、同じ形でエンコードされた潜在表現を同じ形でデコードすることが可能になります(濃い赤の出力は左上のポイントを担当し、明るい赤の出力は右上のポイントを担当するようにです。)
しかし、部分的にみていくと、この出力には「不連続性」の問題がうまれています。90度回転中のある時点(図の下のパス)で、出力の割り当て方法に不連続なジャンプ(図の赤い矢印)が存在しているのです。つまり、入力の集合を継続的に変更しても、出力のリスト表現(MLPまたはRNN出力)をある部分で不連続に変更する必要があります。これは各出力機はどの値を出力するか(今回でいえば四角形のどの位置の点を出力するか)において「責任」をおっているため、このように連続的に回転させている場合でも出力すべきものを途中で変更する必要があるということです。特に今回のように入力値の変化が小さいのにもかかわらず、出力形式を大きく変化させないといけない場合にモデルは大きな問題を抱える場合が多いとされています。これが「集合予測における不連続性による責任問題」です。
通常、ニューラルネットワークは不連続なジャンプを考慮せず関数のみをモデル化するため、このジャンプはニューラルネットワークの学習にとって課題となります。基本的にニューラルネットワークは入力と出力が対応した形で学習されます。そのため、対応関係を作るのが難しい集合的な入出力データを扱う場合には工夫が必要になっているのです。今回のタスクの場合であれば、多角形の頂点の数(設定された要素の数)を増やすと、すべての出力が一度に不連続に変化しなければならない状況の頻度が増えるため、モデル化が非常に難しくなります。
責任問題において、べつの例をみてみましょう。画像中に存在する2つの同一の物体の色を検出するMLPについてです。
青と赤のオブジェクトを持つ画像が与えられているので、出力1が青を予測し、出力2が赤を予測するとしましょう。おそらく、出力1の重みは青のチャンネルに、出力2の重みは赤のチャンネルに合わせています。青と緑のオブジェクトを持つ別の画像を与えられたとき、出力1が再び青を予測し、出力2が緑を予測すると考えられます。ここでモデルに赤と緑のオブジェクト、または2つの赤いオブジェクトを含む画像を与えた場合、どちらの出力がどちらのオブジェクトを予測すべきかは不明です。出力2は赤と緑の両方を「予測したい」が、どちらか一方を決定しなければならず、出力1は以前は青の検出器であったが、もう一方の物体を担当しなければならないということです。この問題を解決するためには、連続的に出力する形を避けなくてはいけないことは明白です。この場合、主な問題は、そもそも出力1と出力2という概念があり、それによってモデルは集合に順序を与えざるを得ないということにあります。(なお「Deep Set Prediction Networks」論文では、ここに注目しモデルの出力が自由に交換可能であるために、集合の要素が交換可能であるのと同じように出力に順序を課さないモデルをつくったということです。なお同論文で提示されているのは「特徴ベクトルを特徴ベクトルの集合に復号化するモデル」です。)
これらの例は、より一般的な問題が存在していることを論文では指摘しています。スムーズに交換できる2つ以上の集合要素がある場合は常に、これらの不連続が生じます。たとえば、オブジェクト検出の一連のバウンディングボックスは、この正方形のポイント設定とほとんど同じであり不連続性の問題が生じます。なおFaster R-CNNなどの従来の物体検出器は、アンカーベースのアプローチであるため、物体検出を集合予測タスクとして扱っていません。そのため、この責任問題に対応する必要がありません。また集合要素が実数空間ではなく有限領域(多くの場合はラベルの集合)からのものである場合も、集合要素を補間することに意味がないため責任の問題が生じません。これは集合要素が実数空間である場合は入力データに強い連続性がありますが(例えば、座標データなどは強い連続性があることわかります)、そもそもラベルの集合のような有限領域(整数空間)などではもともと入力データ同士の連続性が弱く出力機が責任問題に悩まされることがありません。
「集合予測における不連続性時の責任問題」を対処するために必要なことは、入力の順序と出力の順序を独立な関係なものにするため、①入力をpermutation invarianceなものにできるように設定したうえで、②出力機で出力するものは常に同じであるというpermutation equivarianceなモデルにすることだということです。なお、今回のSlot-Attentionモデルは両方の条件を満たしているため、現実世界のような実数空間にも柔軟に対応できるために、柔軟な対応ができるということになります。
物体検出について
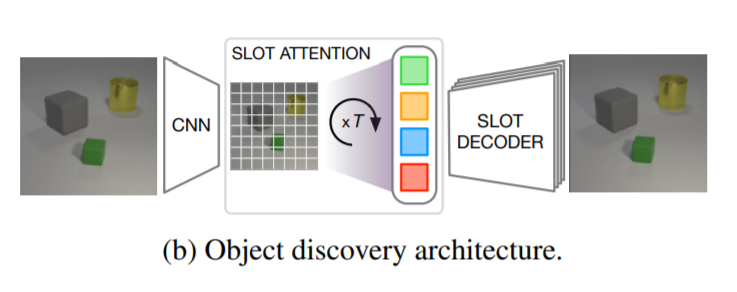
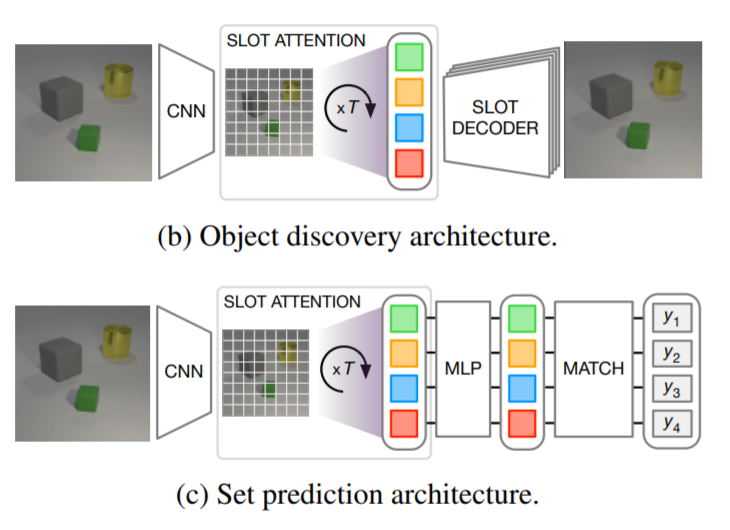
Slot(集合構造化された隠れ表現)は、教師なしの方法で物体を学習するために適した方法です。各Slotは、物体が記述される特定の順序を想定せずに、シーン内の物体のプロパティを補足することができます。Slot-Attentionは入力表現をベクトルの集合(Slot)に変換するため、教師なしオブジェクト発見のためのAuto-Encoderアーキテクチャの一部として使用することができます。Auto-Encoderでは、画像をSlot(一連の隠された表現)にエンコードします。各Slotでは画像の領域または一部のみをエンコードしており、それらをまとめてデコードすることで、元の画像を再構築する形で画像空間に戻すことができます。
Encoder
エンコーダは(i) 位置埋め込みPositional embeddingで補強されたCNNと、(ii)Slot-Attentionモジュールの、2つのコンポーネントで構成されています。Slot-Attentionの出力はSlotの集合であり、シーンのグループ化(オブジェクトなど)を表しています。
Decoder
各Slotは、2Dグリッドにブロードキャストされ、位置の埋め込みが追加される形で個別にデコードされます。このような各グリッドはCNNを用いてデコードされ(Slot間でパラメータが共有されます),W × H × 4のサイズの出力を生成します。出力チャンネルは、RGBカラーチャンネルと(正規化されていない)アルファマスクをエンコードしています。その後、Softmaxを用いてSlot間のアルファマスクを正規化し、それらを混合重みとして使用して、個々の再構成を1つのRGB画像に結合します。
他のモデルとの比較
Slot-Attentionアプローチに最も近いのはMulti-Object Representation Learning with Iterative Variational Inferenceで提唱されているIODINEモデルと紹介されています。このモデルは反復的変分推論を使用して、画像内のオブジェクトを記述する潜在変数の集合を推論しています。各推論の反復では、IODINEはデコードステップに続いて、ピクセル空間での比較とそれに続くエンコーディングステップを実行しています。MONetなどの関連モデルも同様に複数のエンコード・デコードステップを使用しています。
それに対して、Slot-Attentionモデルは、この手順を反復的Slot-Attentionを用いた単一のエンコーディングステップに置き換え、計算効率を向上させています。さらに、これにより、デコーダがなくてもオブジェクト表現とアテンションマスクを推論できるようになり、オブジェクト発見のためのコントラスト表現学習や、制御や計画のような下流タスクの直接最適化など、自動エンコードを超えた拡張が可能になると想定されています。
集合予測について
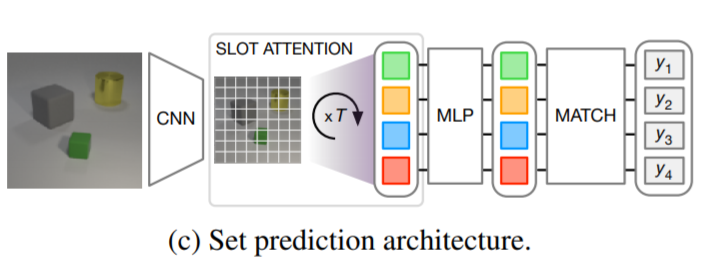
入力画像と予測対象の集合が与えられ、それぞれがシーン内の物体を記述している。集合を予測する際の重要な課題は、ターゲットの順序が任意であるため、K個の要素のセットに対してK!個の等価表現が存在するということです。(これはDETRなどが抱えていた問題と同様です。)そのため意味的に特殊化された2つのSlotがトレーニング中にコンテンツを交換するとき、学習プロセスの不連続性を回避するために、アーキテクチャで明示的にモデル化する必要があります。Slot-Attentionの出力順序はランダムで入力順序とは独立しており、この問題に対応しているといえます。したがって、Slot Attentionは、入力シーンの分散表現を、各オブジェクトを標準分類器で個別に分類できる集合表現に変えるために使用することができます。
Encoder
物体検出と同じアーキテクチャを使用しています。
Classifier
各Slotに対して、Slot間で共有されるパラメーターを使用してMLPを適用します。予測とラベルの順序は任意であるため、DETR同様ハンガリアンアルゴリズムを使用してそれらを照合しています。
実験結果について
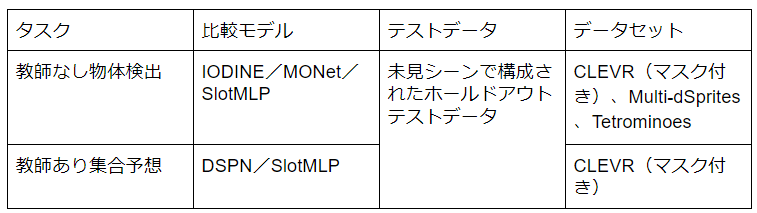
※ディープセット予測ネットワーク(DSPN)は、Slot-Attention以外では順列対称性を尊重する唯一の集合予測モデル
※単純なMLPベースのベースライン(Slot MLP)は、Slot AttentionをMLPに置き換え、CNNの特徴マップ(サイズを変更して平坦化したもの)から(現在では順序付けされた)Slot表現にマップするもののこと。
●物体検出実験の結果

左図から、一般的に、2つの最新のベースラインと比較して良好な結果を示しています。
IODINEと比較して、モデルはメモリ消費量と実行時間の両方の点で非常に効率的です。
右図では、反復回数を増やす実験の結果が示されており、基本的には回数を増やすほうが精度が上がることが示されている。またトレーニング時からKの値を増やしてよりシーン内に多くのオブジェクトがある画像についてテストされているがそれでもセグメンテーション性能は低下しないことが確認されたとしている。
結論として、Slot Attentionは、教師なしシーン分解の先行アプローチと比較して、オブジェクトのセグメンテーションの質、学習速度、メモリ効率の両面で高い競争力を持っているといえます。またテスト時には、Slot Attentionをデコーダなしで使用して、未経験シーンからオブジェクト中心の表現を得ることができます。
※注意
モデルには失敗するケースがあり、まれにTetrominoesデータにおいて、画像を縞模様に分割するという最適解にはまってしまうことがあったことが報告されている。ただし、これは訓練セットの再構成誤差を有意に大きくすることにつながり、このような外れ値は訓練時に容易に識別することができるとはされています。
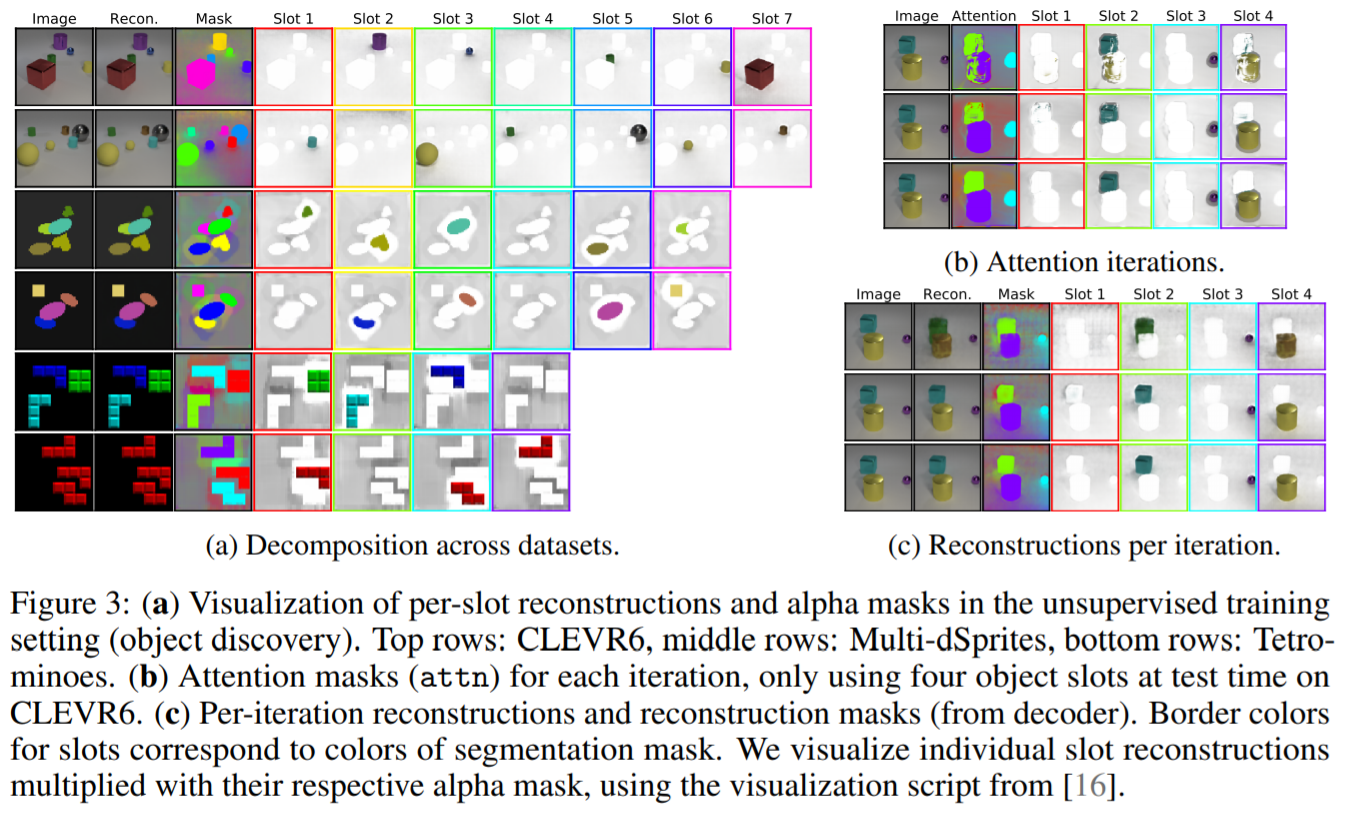
下記図は、セグメンテーションの経過を表したものです。
オブジェクトよりもSlotの数が多い場合、モデルはSlotを空に保つ(背景のみをキャプチャする)ように学習します。Slot-Attentionは通常、単一のSlotだけに背景をキャプチャするのではなく、すべてのSlotに一様な背景を広げていることがわかります。これは、物体の分離や再構成の品質を損なうことのないAttentionメカニズムの成果物である可能性が高いです。またAttentionメカニズムは、2回目の反復ですでに個々のオブジェクトの抽出に特化することを学習していますが、1回目の反復ではまだ複数のオブジェクトの一部を1つのSlotにマッピングしていることがわかります。
●集合予測実験の結果
全体的に、DSPNのベースラインと一致しているか、またはそれ以上の性能を示しています。またテスト時の反復回数を増やすと、一般的に性能が向上することがわかります。Slot-Attentionは、Slot数を変更することで、テスト時に自然とより多くのオブジェクトを扱うことができます。CLEVR6(K=6)でモデルを学習し、より多くのオブジェクトでテストを行うと、APが緩やかに低下することを観察しています。直感的には、この集合予測タスクを解くためには、各Slotが異なるオブジェクトに注目する必要があるという考察がなされています。
またセグメンテーションマスクを使用せずに、対象物の特性を予測するためだけに訓練されているにもかかわらず、自然に対象物をセグメント化していることもわかります。定量的には、注目マスクの調整済みランドインデックス(ARI)スコアを評価することができます。CLEVR10(マスクあり)では、Slot Attentionが生成した注目マスクのARIは78.0%±2.9(ARIを計算するために入力画像を32×32にダウンスケールしています)でした。
結論として、Slot-Attentionは、セット構造化されたプロパティ予測タスクのためにオブジェクトの表現を学習し、実装と調整が非常に容易であると同時に、先行する最先端のアプローチに匹敵する結果を達成したといえます。さらに、Attentionマスクはシーンを自然にセグメント化するため、モデルの予測結果をデバッグや解釈する際に有用とされています。
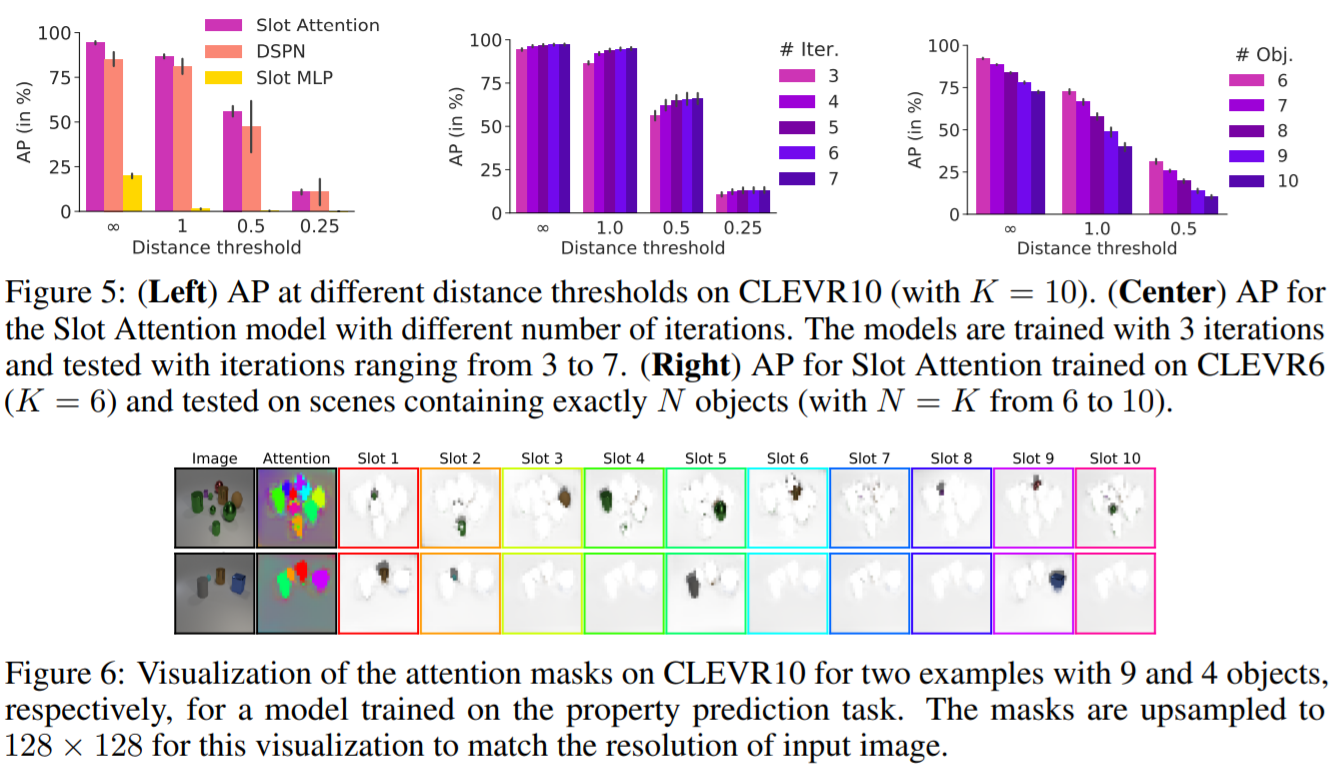
左)CLEVR10(K = 10)の異なる距離しきい値でのAP。
中央)反復回数の異なるSlot-AttentionモデルのAP。
モデルは3回の反復で訓練され、3~7回の反復でテストされています。
右)CLEVR6(K = 6)で訓練されたSlot AttentionのAPと、ちょうどN個の物体を含むシーンでテストされた(N = K = 6~10)。
プロパティ予測タスクで学習されたモデルについて,9 個のオブジェクトと 4 個のオブジェクトを持つ 2 つの例について,CLEVR10 上の注意マスクを可視化したもの.
この可視化では、入力画像の解像度に合わせてマスクを128×128にアップサンプリングしている。
まとめ
低レベルの知覚入力からオブジェクト中心の抽象表現を学習する多目的アーキテクチャコンポーネントとしてSlot-Attentionモジュールは発表されました。Slot-Attentionで使用される反復的Attentionメカニズムにより、入力特徴をSlot表現の集合に分解するためのグループ化戦略を学習することができます。教師なしの視覚シーン分解と教師ありの物体ラベリング予測の実験では、Slot Attentionが先行する関連アプローチと高い競争力を持ち、メモリ消費と計算の面でより効率的であることが示されました。
今回のSlot-Attentionは、DETRなどの実用性が高いモデルと比べると抽象度がたかく将来的に有効利用できることを目指しているモデルといえます。実用的なモデルのほうが注目は浴びやすいですが、このようなモデルは今後出てくるモデルの基礎となる発想を含んでいるため、可能な限りチェックしていくことが必要ではないでしょうか。今後も幅広いモデルを追っていきたいと思っています。