はじめに
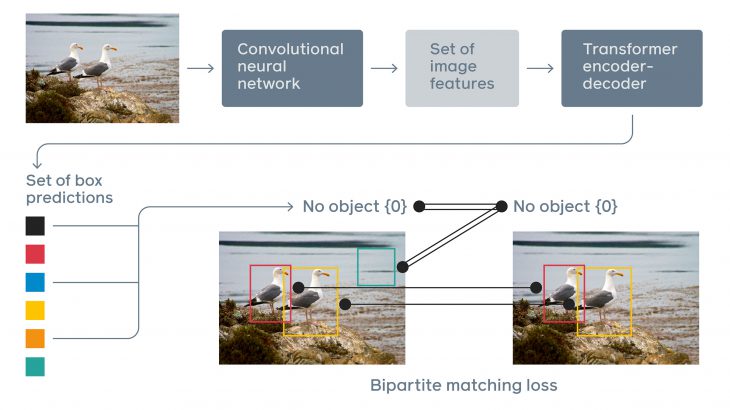
Transformerを物体検出にはじめて取り入れた「DETR(DEtection Transformer)」が2020年5月にFacebookから発表されました。DETRは人間による手作業を大幅に減らすことに成功し、End-to-Endモデルに近く誰でも利用しやすいモデルになっています。また、「水着があるなら、一緒に写っている板のようなものはサーフボードである確率が高い」など、一枚の画像内にあるオブジェクト間の関係性を利用する形で物体検出が可能になりました。こうしたことがどうして可能になったのかを以下で見ていきたいと思います。
なお、Transformerに関しては一定程度の理解がある前提で説明しております。Transformerに関しても記事を作成しておりますので、下記をご参照ください。
公式論文
「End-to-End Object Detection with Transformers」
https://arxiv.org/abs/2005.12872
Facebookブログ
「End-to-end object detection with Transformers」
https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers/
Githubに公開されているコード
https://github.com/facebookresearch/detr
Transformerに関する記事
https://deepsquare.jp/2020/07/transformer/
DETR概要
お忙しい方、概要だけつかみたい方はこちらをご参照ください。
DETRとは…
・Facebook AI Research(FAIR) が2020年5月に公開したモデル。
・Encoder-Decoder型Transformerを使った初めての物体検出モデルとなる。
⇒物体検出を「直接的な集合予測問題」として再定義することで可能となりました。
・End-to-endなモデルを実現し、人手によるハイパーパラメータの設計を大幅に削減することに成功。
⇒これまで必要だったAnchor boxの数、アスペクト比、Bounding boxのデフォルト座標、NMSの閾値等の事前設定が不要になりました。
DETRモデル概要
① backbone
1⃣ CNNによる画像特徴量の抽出:画像 (3, H0, W0) → 特徴量マップ (C, H, W)
※なお、論文ではC=2048、H₌H0/32、W=W0/32に設定している。
2⃣ 1×1Convで特徴量の次元を削減:特徴量マップ (C, H, W) →削減後特徴量 (d, H, W)
3⃣ 縦横をまとめて一次元(1dimension)に変形:削減後特徴量(d, H, W) →1D特徴量 (d, HW)
② PositionalEncoding
・固定の位置情報(Position)を1D特徴量に足す:1D特徴量→1DP特徴量
③ Encoder(詳細は後述)
・Self-Transformerで「1DP特徴量」のQuery, Key, Valueの値を得る
③ Decoder(詳細は後述)
1⃣ Self-Transformerで「Object queries」(N個)のQuery, Key, Valueを得る
2⃣ Transformerで「1DP特徴量」のKey, Valueと「Object queries」のQueryを突き合わせて、次元dでN個のOutputを並列的に出力する(d, N)
④Prediction heads
・Feed Forfard Networkで予測値に変換:(d, N) →(クラス数+1, N)and 座標(4, N)
注意
※ d ₌ hidden_dim (中間特徴マップ数):論文ではd=256で設定されており、性能に影響を与える。
※ N ₌ Number of Object queries (物体クエリ数):論文ではN=100で設定されている。Nは1画像に含まれるオブジェクト数より十分に多い値を選ぶ必要がある。(なお、クラス分類の大半は「分類すべき対象が存在しない(=物体ではない)」を意味するno object(=φ)になる。)
※Object queries(物体クエリ)とは、画像内から物体検出と分類をするために学習される値。(詳しくは後述)
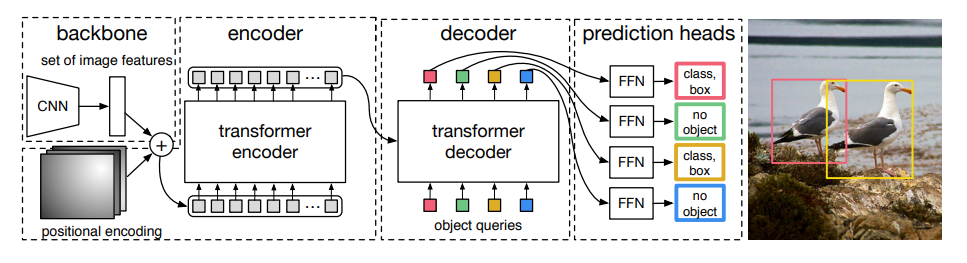
(なお、各特徴量の呼び方は区別しやすくするためにこちらが勝手に呼称しているだけです。公式論文で用いられているものではないのでご注意ください。)
DETR詳細解説
発表論文を参考に、DETRについて詳しく解説します。
DETRはなにがすごいのか?
Transformerは、それまでシークエンスデータ(連続したデータ)を扱う際に主流であったRNNなどが抱えていた「逐次計算による処理速度の高速化が困難という問題」を克服し、① 精度を維持しながら② 並列計算することで高速処理な処理を可能にしました。そのため、自然言語処理(Natural Language Processing:NLP)の世界では、BERTをはじめとして現在の主流モデルのほとんどで利用されています。NLPと画像認識は、CNN・RNNを始めとして片方の世界で革新的な結果を残したモデルがもう片方の世界にも応用されることが頻繁にあります。しかし一方で、NLPの世界と画像認識の世界は前提や必要とされる処理などが異なるため、優れたモデルであっても応用が難しい場合があります。
DETRで使われるまで、Transformerは物体検出の世界では使われてきませんでした。それは物体検出の世界ではTransformerの利点(シークエンスデータを並列的に処理することができる点)を活かした設計をすることが、困難であったためです。
これまでの物体検出では、シークエンスデータを利用することがほとんどありませんでした。現在主流である物体検出では、①画像内の物体を検出する(バウンディングボックスを配置する)、②検出された物体を分類する、という作業が行われています。このときに入力として与えられる画像データはシークエンスデータとして扱う必要がないため、Transformerの利点を活かすような設計をする必要はうまれませんでした。
DETR論文の革新性は、物体検出問題を直接集合予測問題(a direct set prediction problem)として捉えた上で、それをTransformerを利用してシンプルなモデルながら実用可能レベルで実現した点です。直接集合予測問題として捉えるとは、従来の方法である検出したうえで分類を予測するという二段階アプローチ(間接単体予測問題とでもいえるのでしょうか)とは異なり、一度の処理(直接)で画像内のすべての物体の検出と分類(集合)を予測するというアプローチを目指すことを意味しています。つまり、画像内の物体の配置(場所と大きさ)と分類(人間、犬など)の関係性を捉えることが求められているということです。(例えば犬が写っている写真があった場合、そこには(チンパンジーではなく)飼い主の人間がうつっている可能性が高いという推測が可能になります。また、画像内に犬がある大きさである場所に写っていれば、人間はこうした場所にこのくらいの大きさでいる可能性が高いと当たりをつけられます。なお、あくまでこれらの表現は人間が理解するためのものであり、厳密なものではありません。)この「画像内の関係性」を利用するために、画像データをつながりのあるデータ(シークエンスデータ)としてとらえる意味が見出され、Transformerを利用する意義が生じました。
そして、直接集合予測問題として再定義することでこれまで必要だったAnchor boxの数、アスペクト比、Bounding boxのデフォルト座標、Non-maximum surpression(NMS)の閾値等の事前設定を不要とする作りにすることができました。このことは多くの人々に手軽に精度の高いモデルを利用することを可能にしています。
DETRはこれまでの物体検出及び画像分類問題を異なる角度から見直し、Transformerを画像認識、物体検出の世界に持ち込んだということ、そして人手の作業がいらないEnd-to-endに近いモデルになったことが評価されるべきことといえるでしょう。
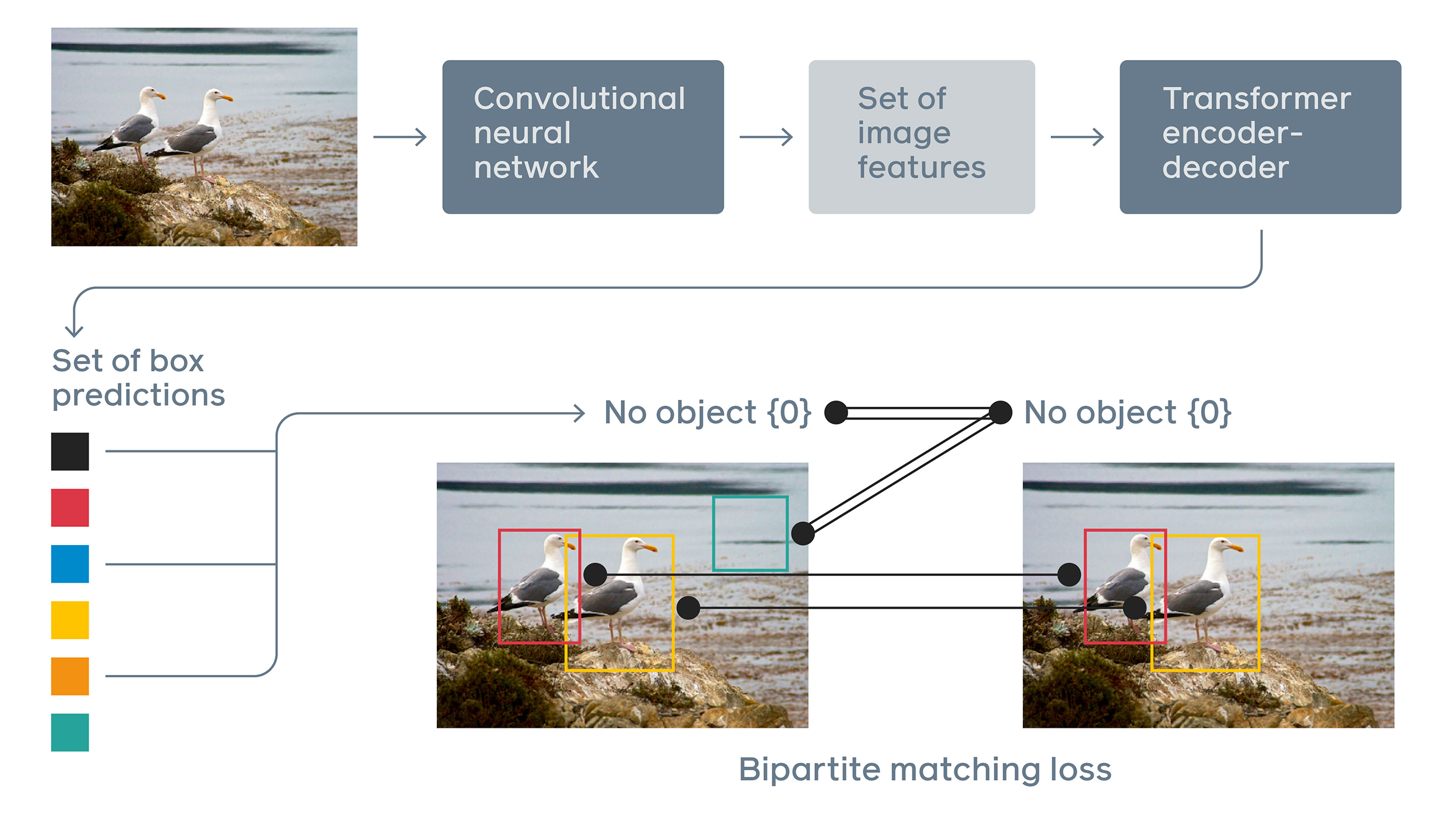
「直接集合予測」するとはどういうことか
直接集合予測するとは、バウンディングボックスとそれに対応する分類を同時に結果として算出することを意味します。直接集合予測という考え方自体は前からありましたが、直接集合予測問題を解くことを困難していた課題があり、DETRではそれらの課題に対応する仕組みがあります。
課題 ①:
学習時に、画像内の全推論結果と全正解ラベルをどう対応付けた上で Loss を算出すれば良いのかわからない。
(正解ラベルに対応した推論結果がどれなのか機械にはわからないという問題)
➡ 二部マッチング問題として考え、ハンガリアン法で適切な対応付けを求めます。
二部マッチング問題:異なる二つの集合の要素をどのように組み合わせると目的を最大値で達成することができるのか。(得手不得手に差がある従業員と仕事の割りふりなど)
ハンガリアン法:二部マッチング問題を効率的に解くための解法。二つの集合における要素同士を組み合わせたときの出力値(要素同士の対応関係)が全てわかれば利用できます。(N人*N仕事分の各出力値)
(詳しい二部マッチング問題、ハンガリアン法に関しては下記URLが参考になるかと思います。)
●二部マッチング
「実世界で超頻出!二部マッチング (輸送問題、ネットワークフロー問題)の解法を総整理!」
https://qiita.com/drken/items/e805e3f514acceb87602
●ハンガリアン法
「割当問題のハンガリアン法をpythonで実装してみた」
https://qiita.com/m__k/items/8e2cb9067ec5d720c30d
課題 ②:
画像をシークエンスデータとして処理する必要があるが、RNNでは期待される性能に達しない。
➡ Transformerを利用することで期待される性能を実現しています。
DETRで新たに用いられた技術
DETRはTransformerを物体検出に持ち込んだという点がすでに革新的ですが、ほかに二つの新しい技術が導入されています。(なお、(教師データの範疇においては)画像内の物体数を十分に超えるだけのNが設定されています。実際に画像内に存在する物体の数を大きくこえるN個分だけ物体が検出・分類されるため、多くのバウンディングボックスはNo objectというカテゴリーに分類されることになります。)
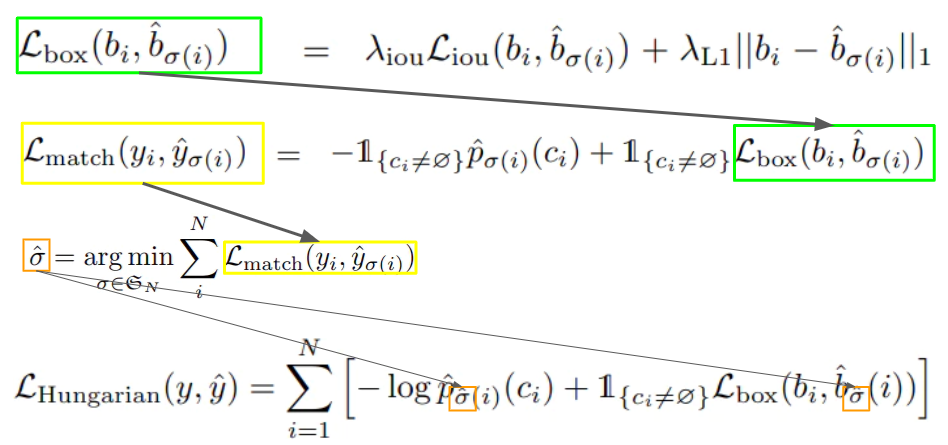
二部マッチングロス
直接集合予測問題を解く上で、上述する予測とラベルのマッチングが正しく行われているのかを判断する必要があります。そのために、DETRでは二部マッチングのために様々なロス計算が行われています。
Lbox:Generalized IoUロス(IoUに距離の概念を追加したもの)と回帰ロス(位置・サイズ)を足したもの。回帰ロス(位置・サイズ)はスケール変化に弱いため、IoUロスを追加している。
Lmatch:予測と正解ラベルをマッチングしたときに生じるロス。
σ^:Lmatchをすべて計算し、その結果から物体の対応関係一覧を得る。
LHungarian:σ^によって得た物体の対応関係一覧から最適な予測と正解ラベルのマッチングを算出する。
Parallel Decoder(並列デコーダー)
デコーダーを並列的に出力する試みは近年では機械翻訳、音声認識、単語認識などさまざまな場面で取り入れられています。(例として、論文ではBERTなどがあげられています。)Transformerの仕組み上、予測を並列に出力することは技術的に困難なわけではないですが、一般的にNLPの世界で利用することが多いため、予測時には回帰構造で逐次的に出力されることがほとんどです。今回、Transformerを取り入れることで、並列的に予測することが可能になったため、DETRではParallel Decoderを取り入れています。
DETRモデル構造詳細
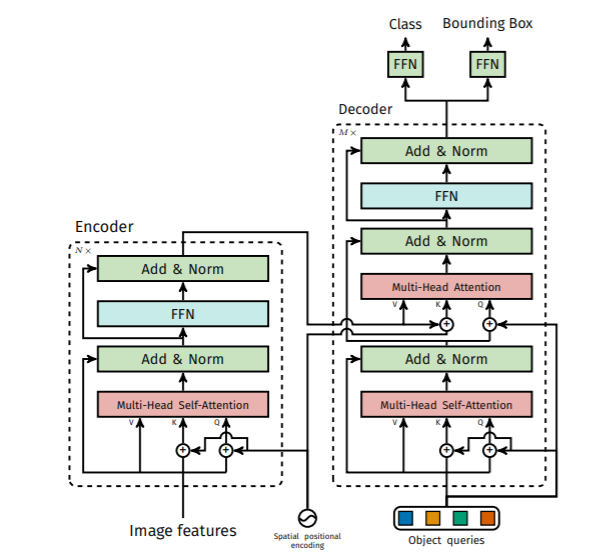
ここでは、詳しくEncoderとDecoderの仕組み、及び「Object queries」をみてみたいと思います。
Encoder
① 画像特徴量をもとにPositionalEncoding(位置情報を付与)したQuery, Key, Valueを作成する。
② Self-Attention層でQuery, Key, Valueの対応関係を学習させる。
*Multi-Headで複数の情報空間からそれぞれの対応関係を学習させる。
③ 活性関数、正規化を行う。
④ Feed Forfard Networkを通す。
⑤ 再び活性関数、正規化を行う。
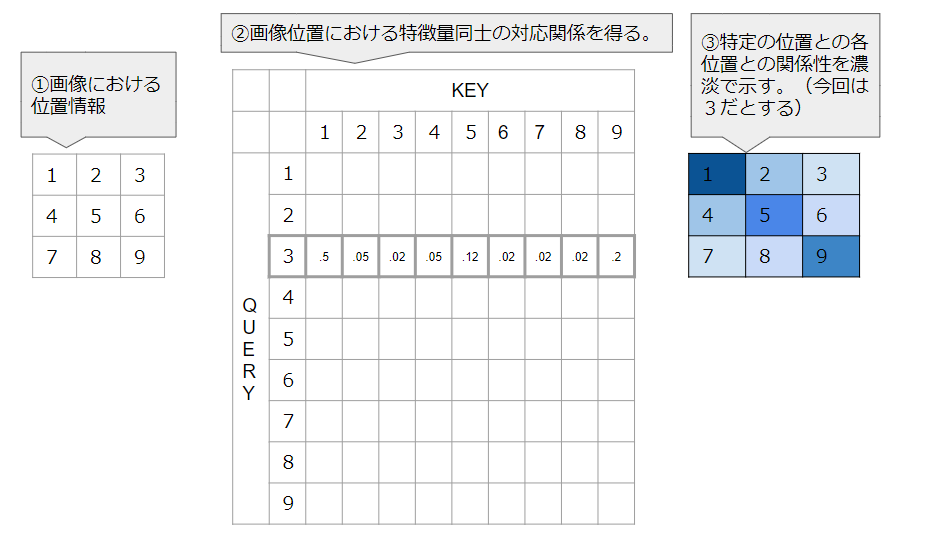
下の写真はEncoder時に得られた画像特徴量同士の関係性マップから、イメージしやすいものを論文執筆者が部分的にとってきたとするものです。誤解を招きやすいですが、これはある地点の画像特徴量が各地点の画像特徴量に対して関係性をどのように持っているかを図示しているものになります。(下の説明図のようなことをすると得られるもの)ある点に着目するとがうえの写真のようなものにみえるときがあるということをいっています。

Decoder
① 「Object queries」(初期値はランダムなベクトル量)をもとにPositionalEncoding(位置情報を付与)したQuery, Key, Valueを作成する。
② Self-Attention層でQuery, Key, Valueの対応関係を学習させる。
*Multi-Headとして複数の情報空間からそれぞれの対応関係を学習させる。
③ 活性関数、正規化を行う。
④ Attention層で「画像特徴量」のKey, Valueと「Object queries」のQueryの対応関係を学習させる。
*Multi-Headとして複数の情報空間からそれぞれの対応関係を学習させる。
⑤ Feed Forfard Networkを通す。
⑥ 再び活性関数、正規化を行う。
Object queries(物体クエリ)とは…
画像内から物体検出と分類をするために学習される値です。学習の際に設定される初期値は完全にランダムなベクトル数値です。任意のN個が設定されることになります。
イメージの話として、N人の人間がいると仮定します。画面のどこの部分をどのサイズ間で注目し(物体検出)、何だと思うか(分類)は人それぞれで異なるとします。彼らは与えられた時間内で正確に物体を検出し分類することを求められています。その場合、必要となるのは適切な分担と情報の共有をすることです。つまり、一枚の画像のうち、誰がどこを重点的に見るかきちんと分担したうえで、見た情報から推測した結果をみんなで共有すると正しい結果が得られるのではないか、ということです。例えば、N=4人の場合を考えると、各人がそれぞれ四隅を重点的にみると分担したうえで、見たものが海に関係するものか、草原に関係するものかなどの情報を共有していくということです。特に後者の情報の共有に関しては、誰かが自信をもって「この写真には水着が写っている」と主張した場合、ほかの人で板か、サーフボードかを迷っている人がサーフボードを選ぶための有力な情報になります。これが最初に説明した画像内の関係性をとってくるということを可能にしているイメージとなります。
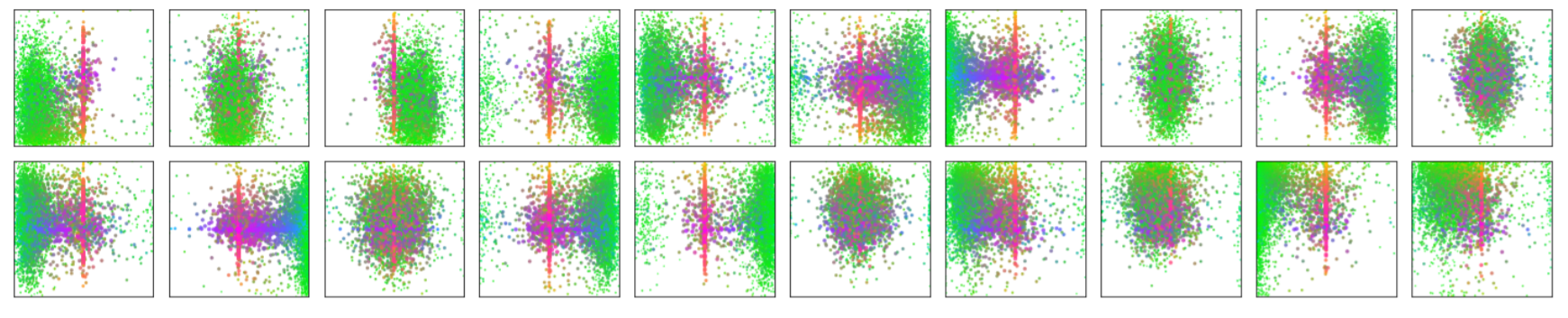
下記の図は画像データセットを与えたときに、各Nが算出したバウンディングボックスの大きさ(赤が水平方向におおきいボックス、青が垂直方向に大きいボックス、緑が小さいボックス)とその中心位置を重ねて図示したものになります。各Nのバウンディングボックスの出し方の傾向(見方)がわかります。Nそれぞれで見方の傾向に違いがあることがよくわかります。この違いが適切に物体検出と分類を行うことを可能にしているのです。
DETR実験結果
DETRの実験では、ハイパーパラメータが以下のように設定されています。
N=100
d=256
Encoder層数=6層
Decoder層数=6層
Multi-head数=8
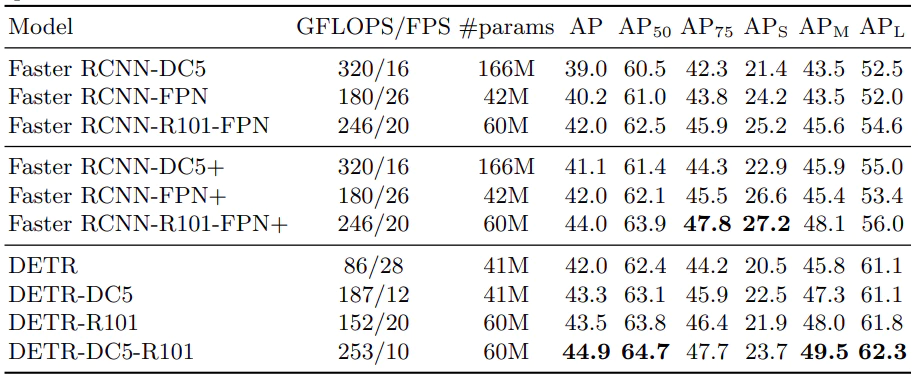
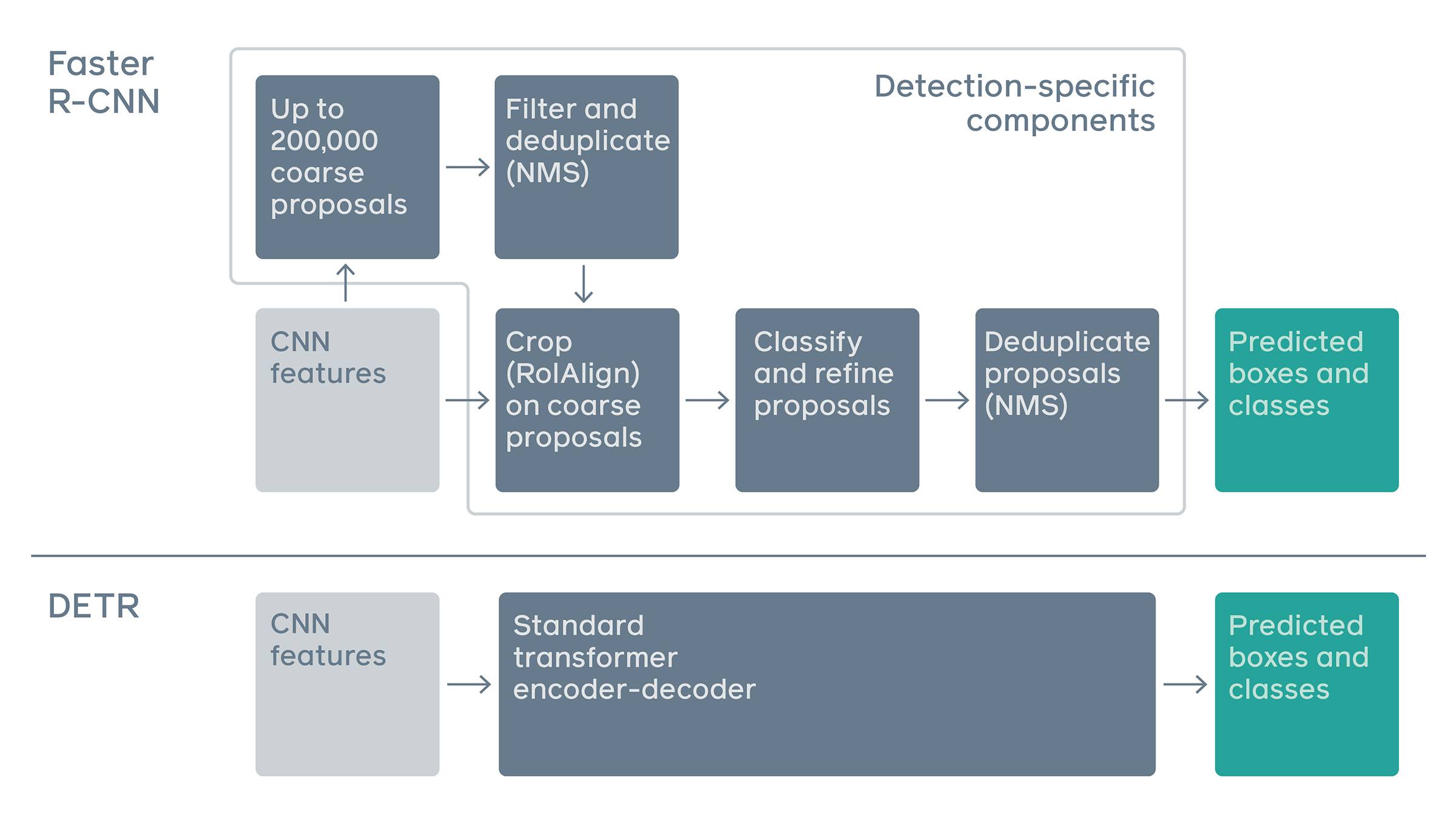
Faster RCNNよりも高い精度を残しています。これはある程度の性能を残しているといえますが、対抗にすべきモデルとしてはほかにも性能のよいモデルがあるのでこの比較が正しいものであるかといえば微妙なところです。ただし、DETRは精度の良さが売りというよりは、Transformerを導入しモデルをシンプルにしたこと(下図でシンプルさがわかるかとおもいます)、拡張性が高いという点に評価ポイントがあるとおもいます。これからもさらなる改良、拡張の余地がまだまだ残されており、今後DETRをベースとしたモデルが多く作られていくかのではないかとおもいます。
まとめ
NLPの世界では主流となっていたTransformerがついに画像認識の世界でも応用されることになりました。NLPと画像認識の世界の技術が交流していくことで、これからもさらなる飛躍をうむようなモデルがうまれていくことを期待したいところです。今後も応用モデルなどに注目していきたいとおもいます。
参考
●DETRについて
「「DETR」Transformerの物体検出デビュー」
https://medium.com/lsc-psd/detr-transformer%E3%81%AE%E7%89%A9%E4%BD%93%E6%A4%9C%E5%87%BA%E3%83%87%E3%83%93%E3%83%A5%E3%83%BC-dc18e582dec1
「ついに出た!本当にDETR! 物体検出の革新的なパラダイム」
https://ai-scholar.tech/articles/object-detection/detr-object-detection-transformers-paradigm
「End-to-End Object Detection with Transformers (DETR) の解説」
https://qiita.com/sasgawy/items/61fb64d848df9f6b53d1
「DETR: End-to-End Object Detection with Transformers (Paper Explained)」
https://www.youtube.com/watch?v=T35ba_VXkMY
●二部マッチング
「実世界で超頻出!二部マッチング (輸送問題、ネットワークフロー問題)の解法を総整理!」
https://qiita.com/drken/items/e805e3f514acceb87602
●ハンガリアン法
「割当問題のハンガリアン法をpythonで実装してみた」
https://qiita.com/m__k/items/8e2cb9067ec5d720c30d
●並列デコーダについて
「Non-Autoregressive Neural Machine Translation」
https://arxiv.org/abs/1711.02281