はじめに
Microsoft Researchから画像タスク用の事前学習モデルBEiTが発表されました。自然言語処理の世界で革新的な事前学習モデルになったBERTの構想を画像に対しても適用したものです。BERTのような自己教師あり学習であることがポイントで、より効率的かつ性能のよい事前学習が可能になるとしています。
・自然言語処理の必須知識 BERT を徹底解説!
https://deepsquare.jp/2020/09/bert/
・AIの第一人者であるYann LuCan氏による最新の自己教師あり学習に対する解説を紹介!
https://deepsquare.jp/2021/03/yann-lucan-self-supervised-learning/
・FAIRから発表された画像処理分野用の自己教師あり学習モデルSEERを紹介!
https://deepsquare.jp/2021/03/fair-seer/
・画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!
https://deepsquare.jp/2020/10/vision-transformer/
概要
Microsoft ResearchがBERTの画像処理版となるBEiT(Bidirectional Encoder representation from Image Transformers)を発表しました。BEiTはBERTのようにもとのデータの一部をマスクして、復元することで学習する自己教師あり学習モデルです。
画像は自然言語と異なり、ボキャブラリーというものが存在しないため、予測候補が存在しない(ある意味で際限なく存在するともいえます)ということがこれまでBERTを画像処理の世界で応用することが難しかった理由です。今回、BEiTはもとの画像から画像パッチ(16×16など)と画像トークンという二つの形を生成するという工夫を行うことでうまくBERTの形を画像処理に持ち込むことに成功しました。
画像分類やセマンティックセグメンテーションの事前学習モデルとしてBEiTはDeiTなどの自己教師あり型事前学習モデルよりもよい精度をだすことができたとしています。
BEiTのポイント
・自己教師あり事前学習モデルである。
・独自の工夫を加えることで、BERTと同じ作りを画像処理分野に対して導入することに成功した。
詳細
背景
現在、モデルの大規模化やアノテーションコストの高さの問題から、画像から直接学習できる自己教師あり学習の研究が進められています。また画像処理にTransformerを応用したVision Transformer(ViT)はCNNモデルよりもより多くの訓練データを必要とすることが明らかになっており、ViT系モデルが普及していくなかでより有効な自己教師あり学習手法が求められています。
自然言語の世界では革新的な自己教師あり事前学習モデルBERTが発表されて以降、効率的な自己教師あり学習手法が確立されているといえます。しかし、画像処理分野ではいまだに確立されているとは言い難い状況にありました。
今回研究チームは自然言語処理分野で成功したBERTを画像処理の世界でも再現することを目指しました。
問題点
BERTの成功とViTの発表以来、画像処理分野でもBERTのような自己教師あり学習モデルの開発が進められなかったわけではありません。しかし、単純に単語の代わりに画像データを入力として与える形でBERT型の事前学習を行うことはできないということがありました。
BERTは、おおまかにいえば入力データの一部をマスクして、そのマスク部分を再現できるように学習することで有用な特徴量を取得できるというモデルです。これと同じことを画像データに対して行おうとすると、一番の問題となるのは画像データには自然言語のボキャブラリー(語彙)に相当する予測候補になるようなものが存在しない(ある意味で無数に存在する)ことです。入力データに対して事前に存在するボキャブラリーのような画像パッチが存在しないため、単純にソフトマックス関数を実装して候補の該当確率を予測するということができなくなります。
単純な解決方法は分類問題ではなくピクセル単位の画像パッチを推定する回帰問題として扱うことになります。しかし、この手法は既に試されており、狭い範囲の依存関係と高密度の(不要な)詳細情報に集中してしまうため、モデルの容量などを大きく損なうことが知られています。そのため、分類問題として扱えるような工夫を今回のモデルでは行うことで、よい精度をだすことに成功しました。
BEiT
今回、研究チームはMIM(masked image modeling)とよぶ事前学習タスクを行うBEiTというモデルを提案しました。
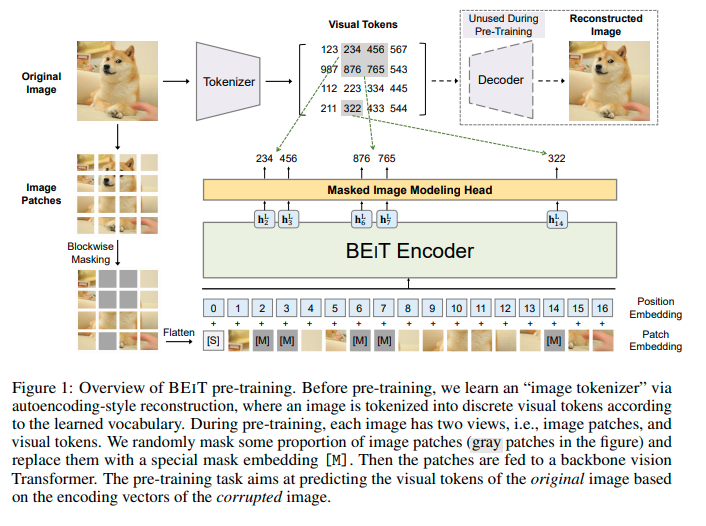
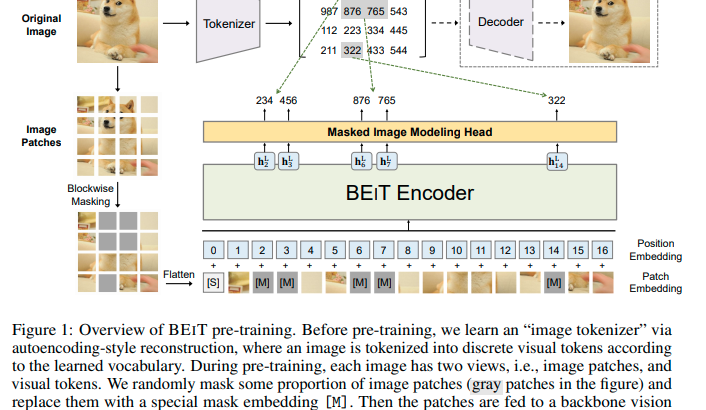
Masked Image Modeling(MIM)
MIMは、オリジナル画像を①グリッドで分割したパッチをTransformerで特徴表現に変換したもの(=Image Patch)と、②画像トークンに変換したもの(=Visual Token)、の2つを利用して行います。画像パッチの40%程度をマスクして、正しい画像トークンの確率を最大化するように学習します。
MIMの手順
①BERTと同じように画像パッチのいくつかの部分をランダムにマスクし、崩れた画像をTransformer(BEiT Encoder)に与える。
②モデルは、もともとのマスクされたパッチ部分のピクセルの代わりに、オリジナル画像から得られたはずの画像トークンに戻すことを学習していく。
最大化目標
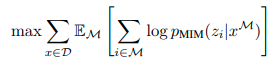
D:学習コーパスの数
M:ランダムにマスクされた位置
x^M:マスクされた画像
Blockwise Masking(マスク箇所を決めるためのアルゴリズム)

VAEの観点
この学習がよく機能する理由はVAEの理論から説明することができます。VAEの観点から考えると、BEiTは以下の式を計算していることになります。
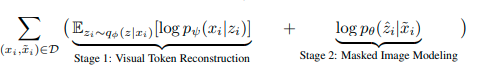
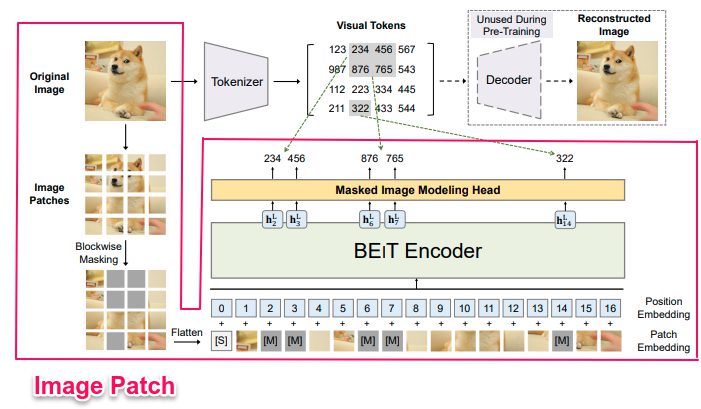
Image Patch
画像パッチに分割した後に、それらをベクトル化し、線形射影を行います。(基本的にはBERTで行われている単語埋め込みと同じです。)BEiT内で画像パッチはピクセル情報で受け取られるものの、基本的には入力特徴としてベクトル化されたものが使われることになります。
論文では、224×224の画像を14ずつのグリッドで分割しています。(つまり、パッチひとつのサイズは16×16になります。)Backbone Networkとして、ViTなどと同じように普通のTransformerを利用しています。
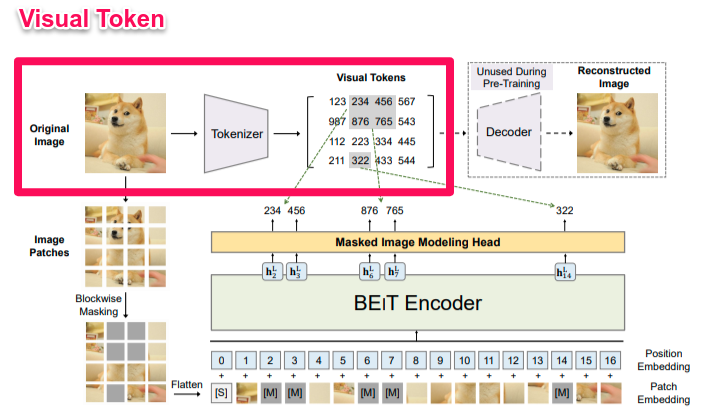
Visual Token
自然言語処理で単語に行われていることと同じように、画像を一連の離散トークンにトークナイズします(=トークンにすること)。離散トークンを学習させるために、生成モデルでは一般的なGumbel-Softmax(離散データをサンプリングするための微分可能な近似ソフトマックス)が利用されています。画像トークンのボキャブラリーサイズは8192に設定されています。(なお、この画像トークンの生成はDALL-Eで利用されているものを参考にしているとのことです。)
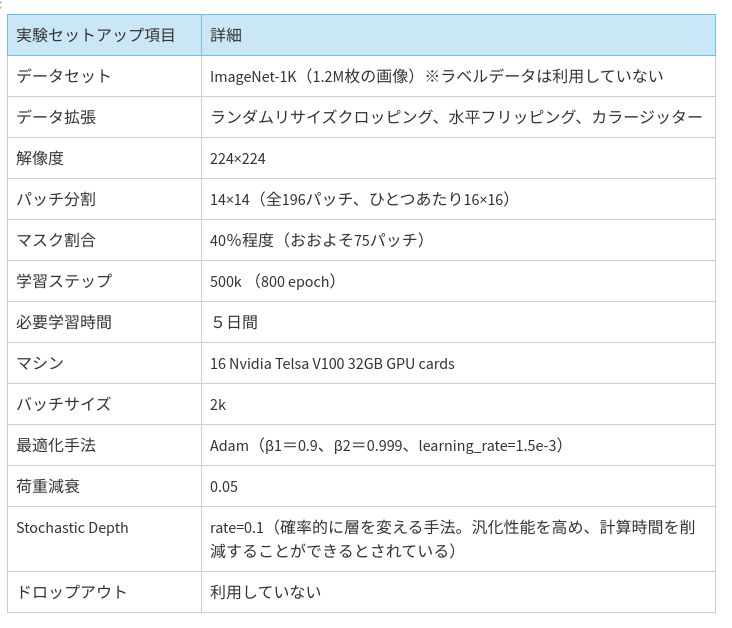
実験
以下のセットアップで画像分類とセグメンテーションで精度実験が行われました。
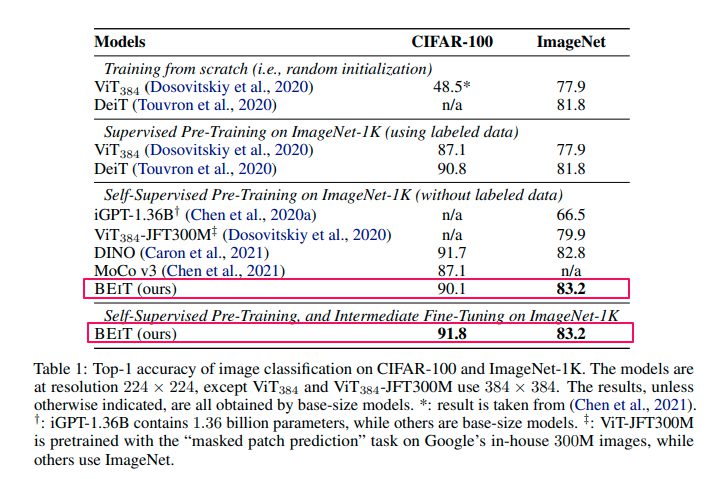
実験結果(画像分類)
CIFAR-100(100クラス、60k枚)とImageNet(1kクラス、1.3M枚)を用いて画像分類の性能を測定しました。基本的なハイパーパラメータの設定はDeiTを踏襲しています。
どちらも最高精度をだすことができました。特にCIFAR-100などのデータ数が少ないものに対して自己教師あり学習で精度を向上することができることが確認できた点にポイントを置いています。このことで、アノテーション作業が減らせると考えられます。
ImageNetの詳細の結果
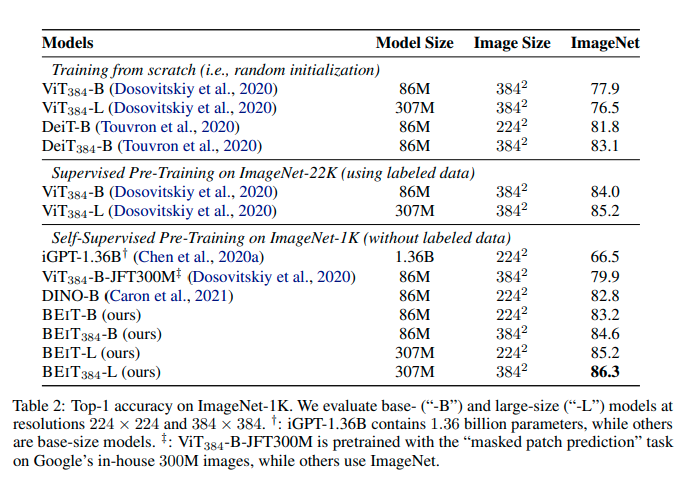
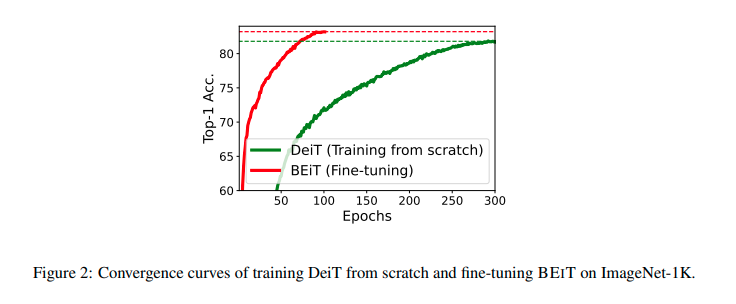
この結果から、BEiTを使うことで巨大なモデルに対して必要とされる巨大なデータセットの量を削減することができると考えられる。また、以下の結果が示すように、少ないエポック数で高い精度に到達することができます。
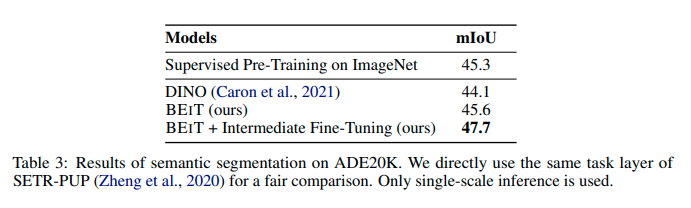
実験結果(セマンティックセグメンテーション)
ADE20K(150クラス、25k枚)を用いて行われました。高い精度をだすことができることが確認されました。
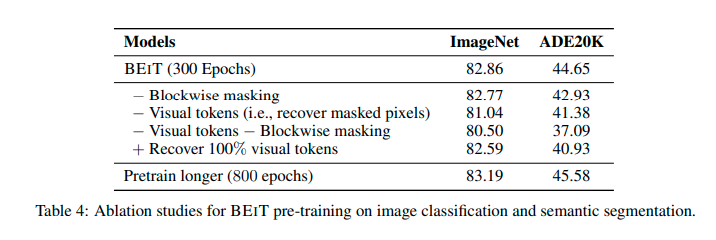
その他
BEiTに組み込ま割れいてる要素が必要であることが確認されています。
BEiTのAttentionMap
BEiTのAttentionMapを可視化したものです。きちんと対象物に対してAttentionが働いていることが確認できます。

まとめ
BEiTはBERTを画像処理に持ち込むことに成功しました。基本的なモデル構造がシンプルかつ自己教師あり学習のため、現在利用しているモデルに対しても底上げが可能であると考えられます。また自己教師あり学習の必要性は強く認識されており、BEiTの成功がさらなる革新的なモデルを生み出すことが期待されます。