
CNNをベースとした群衆カウントの論文の概要をまとめました。
参照元論文はこちら。(画像についても、こちらの論文より引用しています。)
https://arxiv.org/pdf/2003.12783.pdf
論文概要
論文タイトル
CNN-based Density Estimation and CrowdCounting :A Survey
(https://arxiv.org/abs/2003.12783)
著者
Guangshuai Gao, Junyu Gao, Qingjie Liu, Qi Wang, Yunhong Wang
内容
・群集カウントモデルのサーベイ論文。
・CNNベースの密度推定と群集計数モデルについて、ネットワークアーキテクチャ、学習パラダイムなどの観点から調査を実施。
・性能向上を補助する属性や技術をまとめている。
GitHub
https://github.com/gaoguangshuai/survey-for-crowd-counting
論文構成
1.導入
2.群集カウントの分類
3.データセット
4.評価指標
5.ベンチマークと分析
6.ディスカッション
7.まとめ
Ⅰ.導入
ひとつの画像に含まれる物体の数を正確に推定することは、都市計画や公共安全などあらゆる面で社会的に有用なタスクであるが、同時に非常に困難なタスクでもある。特に群衆カウントの技術開発は社会保障に重要な意味をもち、そのうえ技術転用も可能なため、日々改善のために無数の研究がなされ多くの優れた論文や著作が存在している。本論文は散乱しつつある群衆カウントモデルの研究を概観し今後の研究を効率よくすすめるために、総合的かつ体系的に検討し、分析したものである。220以上の論文を調査し、主にCNNベースの密度マップ推定法を中心にまとめた。


Ⅱ.群衆カウントモデルの分類
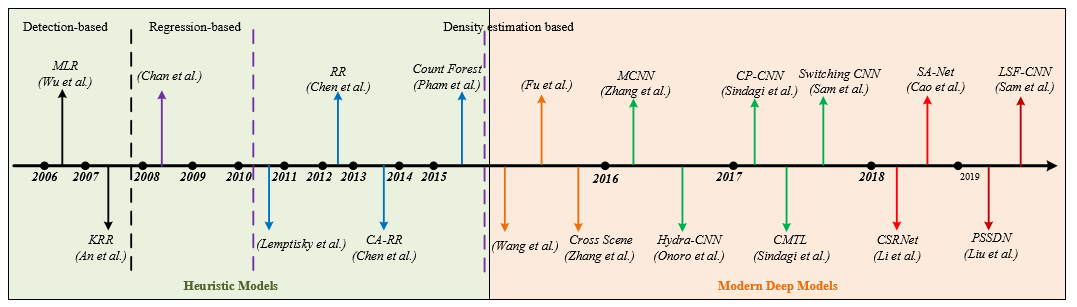
ベースモデルの変遷
初期にはイメージ上の数を直接カウントしようとして検出ベースモデルが作られた。その後、イメージ全体から数を推定するために回帰ベースモデルが提唱され、現在ではイメージ内の密度を推定することでより正確な数の測定を目指している。
(1)検出ベースモデル Detection based
・画像のスライディングウィンドウを介して人もしくは頭部を検出する。
・近年では、R-CNN/YOLO/SSDなどが劇的に精度改善に貢献する可能性はある。
・ただし、非常に密集した群衆に関しては効果が期待できない。
(2)回帰ベースモデル Regression-based
・検出ベースモデルで解決できなかった問題を軽減するために、イメージパッチからカウントへのマッピングを直接学習する回帰を導入。
・全体特徴 global features もしくは部分特徴 local featuresを抽出し、 線形回帰linear regressionとガウス混合回帰Gaussian mixture regressionを用いる。
(3)密度推定モデル Density estimation
・回帰ベースモデルでは空間情報 spatial informationを無視してしまう問題があった。
・そのため、局所特徴と対応する密度マップとの間の線形マッピングを学習する密度推定を採用。
・線形マッピングの難しさを軽減するために、非線形マッピング、ランダムフォレストが推奨される。
⇒CNNベースの密度推定モデル CNN-based density estimation
・初期には基本的なCNNを用いて作成され、近年ではFCNに基づくより効果的で効率的なモデルが作られ、主流となっている。FCNはモデルごとに教師レベルと学習パラダイムが異なる。
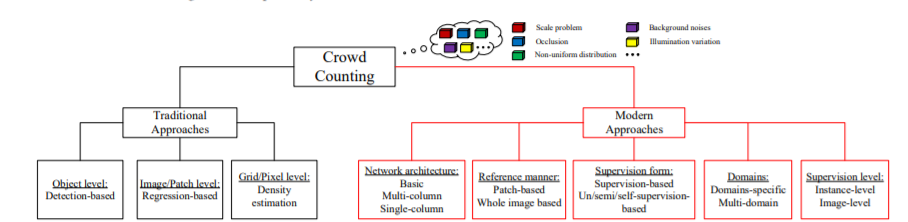
分類項目
モデルは主に以下の6項目を軸として分類される。
A)ネットワークアーキテクチャ
B)学習パラダイム
C)推論方法
D)ネットワークの監視形式
E)ドメイン適応
F)インスタンスレベル/イメージレベル
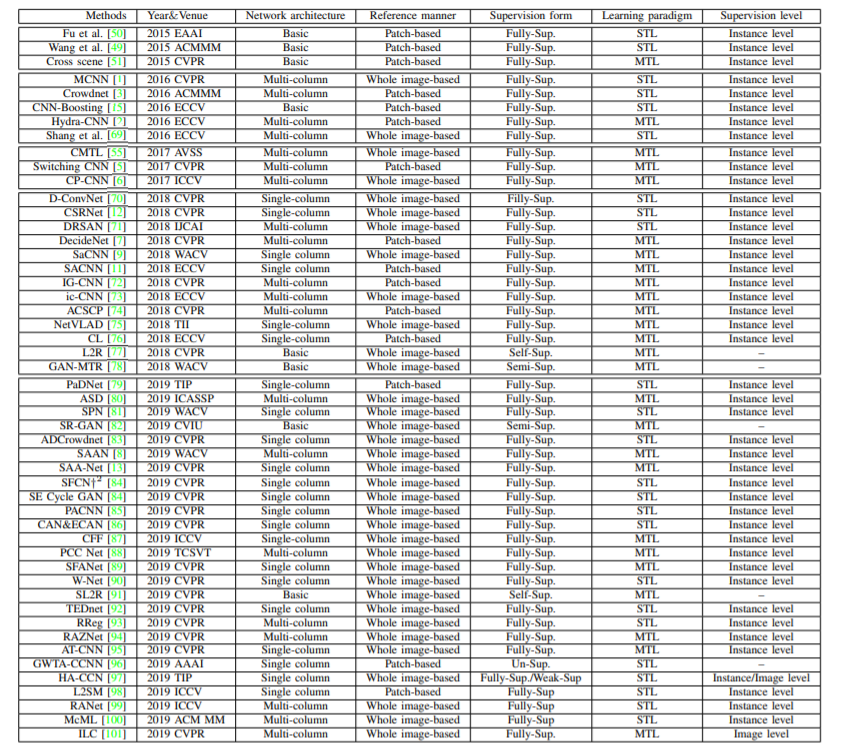
A)ネットワークアーキテクチャ
モデルに採用されているネットワーク構造によって分類する。
(1)ベーシックネットワーク Basic Networks
基本的なCNN構造で、CNNを用いた密度推定や群集測定の初期に使われた。
メリット:シンプルで実装が簡単。
デメリット:通常は精度が低くなる。
(2)マルチカラムネットワーク Multi-Column Networks
異なる受容野に対応するマルチスケール情報を補足するために複数のカラム構造を採用している。
メリット
・群衆カウントのために優れた性能がもたらされる。
デメリット
・学習に時間が必要で、実装が困難。
・異なる分岐を利用しているもののほぼ同じネットワークを利用するため、全体としては冗長になりやすい。
・画像をネットワークに送信する前に密度レベルの分類器が必要だが、実際にカウントする群衆の数は計測の度に大幅に変化するために密度レベルの細かい定義が困難。また、きめの細かい分類はより多くのカラムと構造を必要とするため、より冗長性が高まる。更に、密度レベルの分類器のために大量のパラメータを必要としてしまう。
(3)Single-Column Networks
マルチカラム・ネットワーク・アーキテクチャのような肥大化した構造ではなく、単一で深みのあるCNNを展開しており、ネットワークの複雑さを増やさないことが前提となっている。

B)学習パラダイム
モデルをどのような目的において学習させるかのパラダイムごとに分類する。
(1)シングルタスクベース Single-task based
古典的に用いられる方法で、ほとんどのCNNベースの群集カウント法はこのパラダイムに属する。一般的に密度マップを生成し、すべてのピクセルを合計して総カウント数を得るか、もしくは直接カウント数を得る。
(2)マルチタスクベース Multi-task based
近年では様々なコンピュータビジョンタスクにおけるマルチタスク学習の成功に触発されて、密度推定と分類、検出、セグメンテーションなどの他のタスクを組み合わせて、より良い性能を示している。マルチタスクベースの手法は一般的に複数のサブネットを用いて設計されており、純粋な単一カラムアーキテクチャとは対照的に、異なるタスクに対応する他のブランチが存在する場合もある。
C)推論方法
イメージのどの部分を用いて推論するかで分類する。
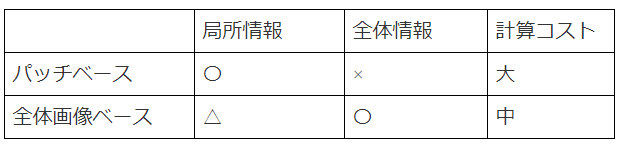
(1)パッチベースメソッド(Patch-based methods)
画像からランダムに切り取られたパッチを用いて学習するために必要とされる。テスト段階では、テスト画像全体に広がるスライディングウィンドウを用い、各ウィンドウの推定値を取得し、それらを組み立てることで画像の最終的な合計カウントを得る。
(2)全体画像ベースメソッド(Whole image-based methods)
パッチベースの手法は常に大域的な情報を無視している。また、スライディングウィンドウ演算のために計算コストの負担が大きい。全体画像ベースの手法では、画像全体を入力とし、それに対応する密度マップや群集の総数を出力するのが一般的である。一方で、ローカル情報を失う場合がある。
D)教師あり学習法
学習方法において教師データの有無によって分類する。
(1)完全教師あり学習(Fully-supervised methods)
大規模かつ手動で正確なアノテーションをつけたデータに依存している。しかし、これらのデータの取得には時間がかかり、通常よりもラベル付けの負担が大きい。また、ラベル付けされたデータが少ないために、オーバーフィットの問題に悩まされることがあり、自然域や他の領域に移植する際に性能が著しく低下する可能性が高い。
(2)非/半/弱/自己教師あり学習(un/semi/weakly/self-supervised methods)
教師あり学習法と比べて同程度のパフォーマンスに到達するためのラベルなしデータを利用する方法が開発されている。
E)ドメイン適応
ドメインの違いによって分類することができる。既存の計数手法は、ほぼすべて特定のドメインに対して設計されている。そのため、どのようなオブジェクトドメインでも測定できるカウントモデルを設計することは、挑戦的でありながらも意味のある作業である。ドメイン適応技術は、この問題に取り組むための強力なツールとなりうる。
F)教師データの性質(インスタンスレベル/イメージレベル)
教師データがどのようにアノテーションされているかで分類する。
(1)インスタンスレベル教師データ(Instance-level supervision)
ほとんどの群集密度推定法は、インスタンスレベル(ポイントレベルまたはバウンディングボックス)の教師データに基づいており、インスタンスの位置ごとに手動でラベルを付けたアノテーションデータが必要となる。
(2)イメージレベル教師データ(Image-level supervision)
イメージレベル教師データに基づく手法では、位置情報を必要としないsubitizing範囲内またはそれを超えたインスタンスの数を瞬時に判断する必要がある。一瞬もしくは一目で数を推定させるようなイメージ。
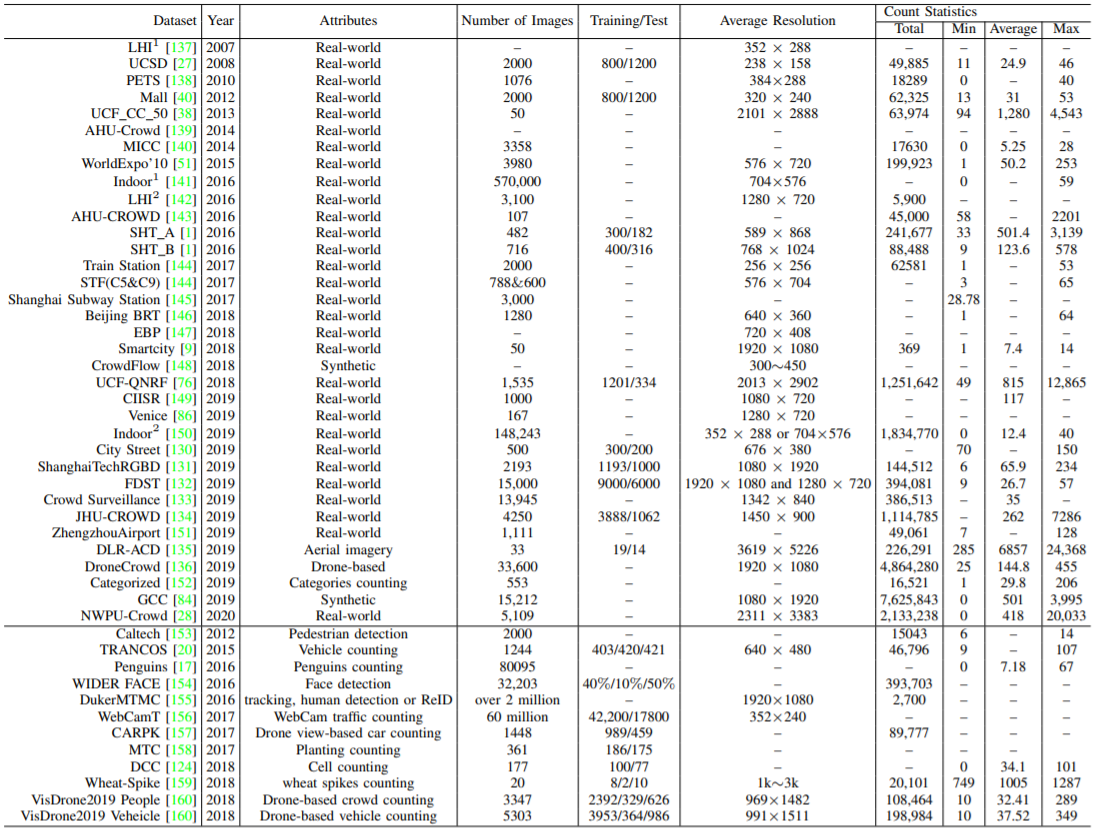
Ⅲ.データセット
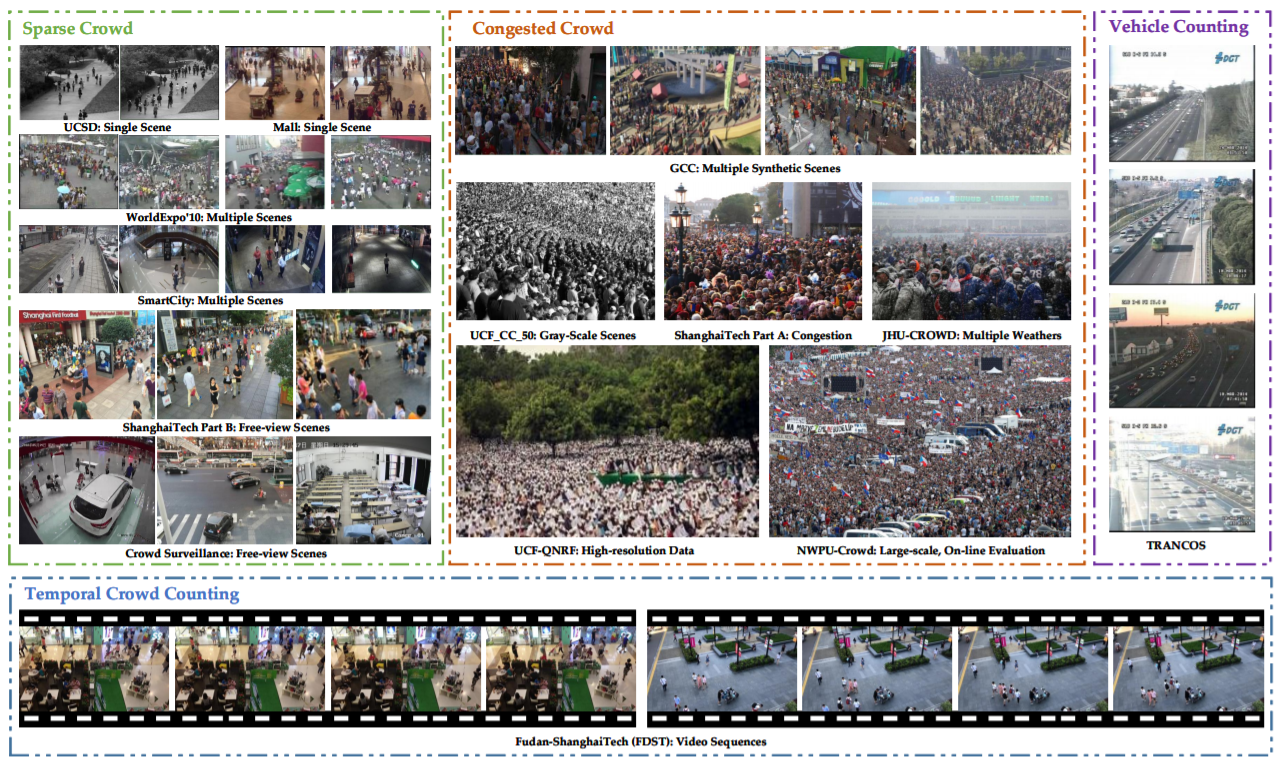
群衆カウント技術の発展に伴い、多数のデータセットが導入されている。規模のばらつき、監視映像中の背景の乱雑さ、変化しやすい環境、自然界での照明のばらつきなど、様々な課題に対応するためにより多くのアルゴリズムが導入されている。
Ⅳ.評価指標
評価指標にはその目的及び利用するレベルに応じて3種類に分類できる。
(1)カウント性能を評価するためのイメージレベル
(2)密度マップクオリティーを測るためのピクセルレベル
(3)局在化の精度を評価するためのポイントレベル
(1)イメージレベル指標
主に使われる指標として、平均絶対誤差(Mean Absolute Error:MAE)と平均二乗誤差(Mean Square Error:RMSE)がある。MAEは推定の精度、RMSEは推定のロバスト性を示す。
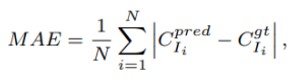
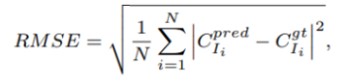
(Nはテスト画像の番号、Cprea/IiとCgt/iはそれぞれ予測結果とグラウンドトゥルースを示している。)
MAEでは正確な評価を提供するために位置情報が失われる可能性がある。そのため、グリッド平均平均絶対誤差(Grid Average Mean Absolute Error:GAME)が提唱されている。
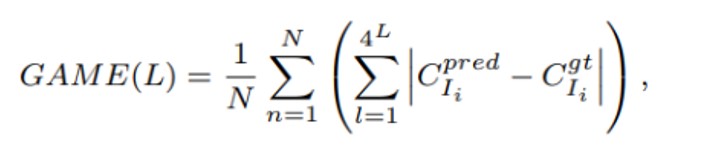
(4Lは画像をいくつかの重複しない領域に分割することを示す。Lが高いほど、GAME指標の制限が厳しくなる。なおL=0の場合は、MAEに退行することに注意する。)
同様にローカライズエラーを考慮して、平均ピクセルレベル絶対誤差(Mean Pixel-level Absolute Error:MPAE)が提唱されている。MPAEは密度が誤って局所化されている度合いを測定する。
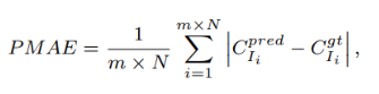
MAEとRMSEの観点では、ローカルの領域を評価できないグローバルな精度とロバスト性の指標になるため、両者を広げるパッチ平均絶対誤差(Patch Mean Absolute Error:PMAE)とパッチ平均二乗誤差(Patch Mean Square Error:PMSE)が提唱されている。

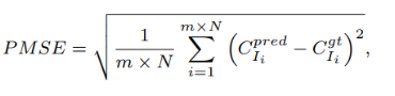
(なお、mは分割された重複しないパッチで、m=1のとき、PMAE⇒MAE、PMSE⇒RMSEになる。)
(2)ピクセルレベル指標
ピーク信号対雑音比(Peak Signal to Noise Ratio: PSNR)及び構造類似性指数(Structual Similarity Index : SSIM)が生成された密度マップのクオリティーを作成するために使われる。
①PSNR
最も一般的かつ広範に使われれる画像評価指数である。基本的には対応するピクセル間のエラー、つまりエラー感度に基づいている。一般的に、高い値は小さなエラーを示すとされる。ただし、人間の視覚特性は考慮されない。(例えば、人間は低空間周波数のコントラストの違いや色相よりも明るさに敏感であること、領域の知覚結果は周囲の隣接する領域の影響をうける等々。)そのため、評価結果は多くの場合、人間の主観的な感覚と一致しない。
②SSIM
明るさ、コントラスト、構造の三要素の掛け合わせから画像類似性を測定する。0:1の範囲を取り、値が大きいほど、画像の歪みは少なくなる。
(3)ポイントレベル指標
モデルのローカリゼーションパフォーマンスを評価するために、平均適合率(Average Precision : AP)と平均再現率(Average Recall : AR)が使われる。一般的にAPの値が増加すると、ARの値が減少する。したがって、トレードオフの関係性にあり、両者をどのような値にすべきかは検討の余地がある問題である。
Ⅴ.ベンチマークと分析
全体的なベンチマーク結果への評価
代表的な群集カウントの性能の比較。(赤、緑、青はそれぞれ第1、第2、第3のパフォーマンスを示す。)
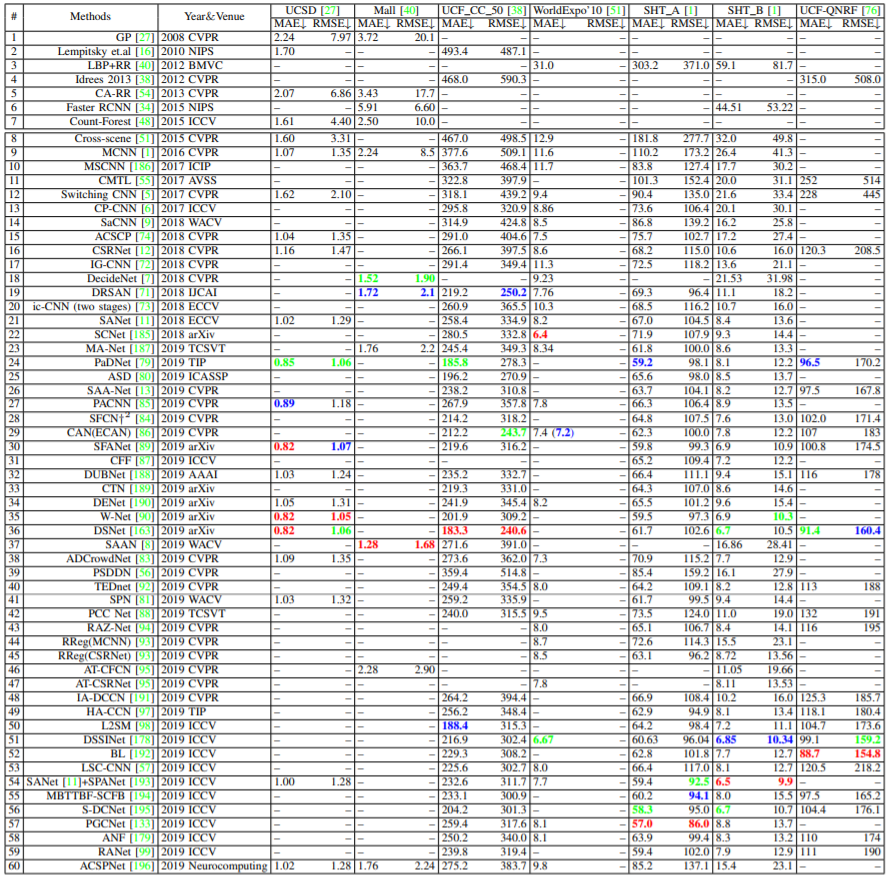
プロパティベースの分析
モデルをプロパティごとに分析する。注目するプロパティは以下の8項目となる。
A) シングルカラムネットワーク Single column network
B) 視覚的注意メカニズム Visual attention mechanism
C) 拡張畳み込み層 Dilated convolution layers
D) 空間転移ネットワーク Spatial Transformer Network(STN)
E) コンディショナルランダムフィールド Conditional Random Fields(CRF)/マルコフランダム Markov Random Fields (MRF))
F) 遠近情報 Perspective information
G) ピラミッドプーリング Pyramid pooling
H) 汎密度 Pan-density/サブリージョン subregion
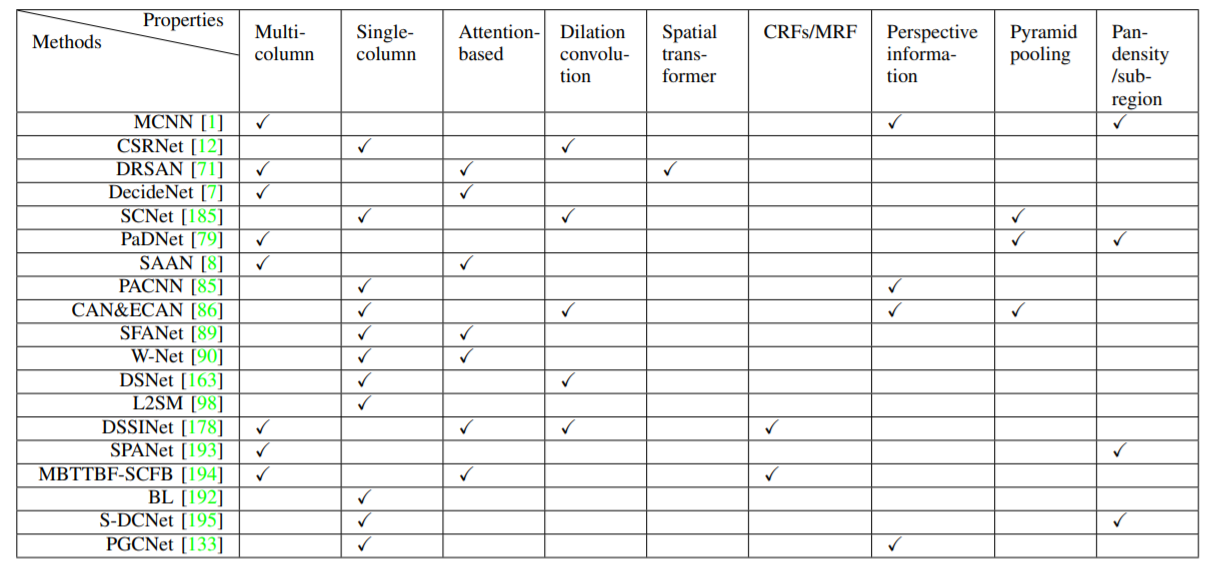
A) シングルカラムネットワーク Single column network
最新手法の2/3がsingle column networkを採用している。そのうち、1/3以上がVisual attention mechanism及び、dilation convolution layer を組み込んでいる。
B) 視覚的注意メカニズム Visual attention mechanism
ニューラル応答を計算するために適切な情報を使用し、特徴マップの各ピクセルの重要度を重み付けするために学習することができる。関心領域を強調表示し、背景クラッタ状況でノイズをフィルタリングする群衆カウントの問題にも適している。
C)拡張畳み込み層 Dilated convolution layers
セグメンテーション作業の精度を大幅に向上させることが実証されている。より多くのマルチスケール特徴を捕捉し、より詳細な情報を維持するために、非圧縮畳み込み層を群集カウントフレームワークに統合することができる。
D) 空間転移ネットワーク Spatial Transformer Network(STN)
回転やスケーリング、反りの問題に対処することができる。余分なアノテーションを必要とせず、異なるデータ間の空間転移を適応的に学習する能力を持っている。
STNは入力画像上で空間変換を行うだけでなく、異なる特徴マップの空間転移を実現するために、畳み込み層のどの層でも空間転移を行うことができる。
E) コンディショナルランダムフィールド Conditional Random Fields(CRF)/マルコフランダム Markov Random Fields (MRF)
群集カウントタスクの異なるスケールの特徴を洗練するためにCRFが利用され、ベンチマークデータセット上でその有効性を実証している。群集カウントのためにCRFと非局所的操作 (self-attentionと同様)を統合したAttentional neural fields(ANF)フレームワークが提案されている。
F) 遠近情報 Perspective information
遠近情報はカメラの6自由度(DOF)に関連するものと、カメラからの距離におけるスケールの変化を識別するもの、の二つの方法から提供される。多くの伝統的な群集カウント法 は、回帰特徴や検出特徴を正規化するためにスケール変化を利用している。最近のCNNベースの手法の中には、遠近情報を利用してGround Truth密度 や身体部位マップ を推定するものもある。
G) ピラミッドプーリング Pyramid pooling
異なるサイズのプーリング層を特徴マップから抽出し、それらを固定長のベクトルに集約することで、ロバスト性と精度を向上させることができ、収束速度を速めることができる。SCNet 、PaDNet 、CANでは、群集計数のためにマルチスケール特徴量の捕捉と融合に用いられている。
H) 汎密度 Pan-density/サブリージョン subregion
異なるシナリオでの密度や分布の変化と、同じシーン内での密度の不一致に対処することが目的。現在の手法の多くは、特定の密度やシナリオに合わせて設計されている。MCNN 、Switch-CNN、CP-CNNなど、多くのマルチカラムアーキテクチャがこの問題に対処するように設計されているが、それらは常に効率が低く、計算が複雑で、局所推定に偏りがあるという問題を抱えている。しかし、PaDNet は、密度汎化ネットワーク Density-Aware Network(DAN)のサブネットワークから特定の群衆を効果的に識別し,特徴強調層 Feature Enhancement Layer( FEL)によって各特徴マップの強調率を学習する合理的な解決策を提供することを提案している。
プロパティベースの評価 まとめ
・ほとんどのネットワークはシングルカラムネットワークアーキテクチャに基づいており、複雑で肥大化した構造を持つマルチカラムアーキテクチャよりも、シンプルでありながら効果的である。
・視覚的注意メカニズム、拡張畳み込み、空間ピラミッドプーリング(SPP)の技術は、最終的な推定の性能と密度マップの品質を大幅に向上させることができる。
・遠近情報を組み込むことで、マルチスケール特徴の抽出のための追加のサポートとガイダンスを提供できる。
・空間変換ネットワーク、変形畳み込みは、密集したノイズの多いシナリオでの群集理解問題により適している群集の回転と均一分布に対処するのに役立つ。
・汎密度学習は大域的な特徴を最大限に活用できるだけでなく、偏った局所的な推定を補うことも可能。
・マルチパスウェイやマルチタスクのフレームワークを用いた場合には、共同損失関数を用いることで推定性能を向上させ、学習を高速化することが可能である。
Ⅵ.ディスカッション
群衆カウントにおいて考慮すべき点
A) オクルージョン
B) 複雑な背景
C) スケール変動
D) 不均等分布
E) 遠近の歪み
F) 回転
G) 照度の変化
H) 天候の変化

A)オクルージョン
群集の密度が高くなると、群集は部分的にお互いを覆い隠しているように見えることがある。密度推定モデルが必要となる。
B) 複雑な背景
背景領域(人物インスタンスを持たない)には、紛らわしいオブジェクトが含まれていたり、前景と類似した外観や色をしていたりする。これはセマンティックセグメンテーションまたは、Visual attention mechanismにより抑制できる。
C) スケール変動
カメラからの距離に応じて物体のスケールが変化するため、密度推定モデルでは最も主要な問題。そのため、ほとんどすべての密度推定モデルは、第一段階でスケール変動問題に対処するように設計される。
D) 不均等分布
同じシーンでも局所領域の分布に一貫性がない状態。マルチレベル特徴によって生成された複数の密度マップを融合するマルチレベル畳み込みニューラルネットワーク(MLCNN)を提案することによって、この問題に取り組んでいる。この問題はPan-density crowd countingと見なすこともできる。
E) 遠近の歪み
遠近法の歪みは、カメラの6自由度(DOF)を推定するためのカメラキャリブレーションに関連しており、群集計数シーンでの人物スケールのばらつきに大きく影響する。
F) 回転
異なる姿勢や撮影角度のようなカメラ視点による回転変動の問題が発生する。LSTMフレームワークへの空間変換ネットワーク(STN)の組込みを介して対処される。
G) 照度の変化
照度は1日の中で太陽の動きに応じて変化する。
H) 天候の変化
晴天、雲、雨、霧、雷、曇りなど、気象条件は日々変化する。
今後の課題
A) モデル設計
B) データセットの構築
C) 密度マップの質
D) ドメイン適応と転移学習
E) 背景に対するロバスト性
F) 不変性、又は一般化
G) 軽量ネットワーク
H) 画像とビデオの組み合わせ
I) ワイドビューにおける群集の数
J) 物体カウントを超えた局所化・分類・追跡
K) 小さな物体のカウント
A) モデル設計
(1)Ground Truth密度マップの作成
高い信頼度のGround Truth 密度マップの生成は、訓練のためのデータ準備に不可欠である。
(2)損失関数
ほとんどが回帰処理であり、通常、推定された密度マップとグランドトゥルースとの差を測定するための損失関数としてユークリッド距離を採用している。しかし、外れ値や画像のぼやけに対する感度、局所的なコヒーレンスを無視した画素独立性の仮定、密度マップの空間的な相関などの欠点がある。それらの欠点に対応するため、SmoothL1損失やTukey損失が利用されている。また、密度マップの品質を向上させるために、敵対的損失が統合される場合もある。
(3)複数の手がかりとなる情報の統合
複数の手掛かりとなる情報を統合して使うことで、アルゴリズムの性能を大幅に向上させることができる。例えばスケールアウェアとコンテキストアウェアの統合や、疎なシナリオと密なシナリオのための異なる経路の組み合わせなどがある。
(4)ネットワークトポロジー
トレーニングの複雑さと必要なパラメータに影響を与える。群集カウントタスクではエンコーダ-デコーダパイプラインが有望な性能を発揮する。
B) データセットの構築
(1)状況の多様性
データセットは現実の多様性に対応して一定程度複雑なものが求められる。初期にはUCSD やMallのように、異なる画像間で遠近感にばらつきのない、同じビデオシーケンスの画像を使用した群集カウントのためのデータセットが作成された。現在はディープラーニングのためのシーン横断的で多様なデータの必要性を満たすために、UCF CC 50 、SHT A 、UCF QNRF、などいくつかのより困難なデータセットが提案されている。ただし、これらのデータセットは問題を抱えており、例えばUCF CC 50は高解像度の群集画像の数が少ないために生成能力が制限されており、SHT Aは不均一な密度レベルと一部のサンプルの不正確なラベルに悩まされている。
(2)マルチビュー
公共の公園や駅での長蛇の列など、単一視点では対応できない状況がある。単一のカメラでは捕捉しきれないほどの広さをもつシーン、カメラからあまりにも遠く離れた場所(解像度が低い)、群衆の大部分が物体に遮られていたりする場合などである。その場合には複数視点(マルチビュー)を含むデータセットを必要する。例えば、市街データセットCity street dataset は、交通量の多い交差点から収集されたもので、より複雑なオクルージョンパターンと大きなスケールの変化を持つ広い範囲の群衆を含んでいる。
(3)アノテーションの精度
既存の密な群集カウントデータセットには欠点があり、UCF CC 50 や上海工大Part A のいくつかのサンプルでは、アノテーションがあまり正確ではない。異なる作業者によってアノテーションされたデータや、異なる基準に従ったデータにおいては避けられない問題であり、改善されたデータセットが求められる。
(4)アノテーションツール
NWPU-Crowdを構築したアノテーションツールを紹介している
https://github.com/gjy3035/ NWPU-Crowd-Sample-Code
C) 密度マップの質
密度マップの品質は性能に影響を与える重要な要素となる。(既存手法はカウント精度に注目。)Sindagi は初めてこの問題に着目しより明確で高品質な密度マップを得るために、ユークリッド損失と敵対的損失(adversarial loss)を併用しながら大域的なコンテキストを18の学習過程に組み込むことを提案した。
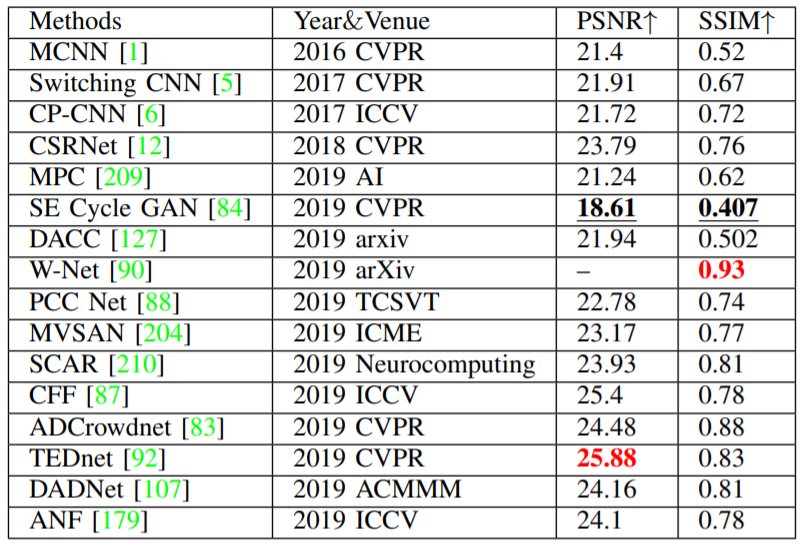
密度マップの品質を、PSNRとSSIMの2軸で比較すると、SSIM Embedding CycleGANが最も悪い性能を示していることがわかる。これは、合成データと実世界のデータとの間の “ドメインギャップ “に起因するものと思われる。
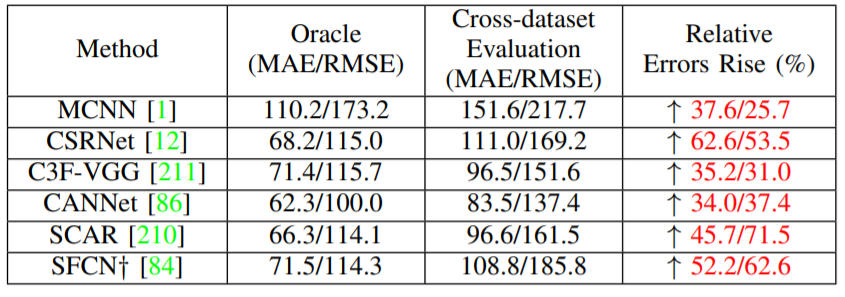
D) ドメイン適応と転移学習
学習モデルを未見のシーン利用すると、予測不可能なドメインギャップのため、最適な結果が得られないことがある。NWPU-Crowdモデルの上海パートA[1]とOracle errorと比較して、平均MAEが44.6%増加し、RMSEが47.0%増加するなど、明らかな性能低下が見られる。 性能低下の主な理由は、密度範囲や画像スタイルなど、多くのドメインギャップ/シフトが存在することにある。ドメインギャップを改善するためには、ドメイン適応の手法が有用。GANベースの手法がこの問題に重要な影響を与えている。例えば、SSIM Embedding CycleGANは、従来のサイクルGANフレームワークに構造的類似度指数(SSIM)を組み込み、合成データと実世界のデータの間のドメインギャップを補うことで、ドメイン適応技術を利用している。
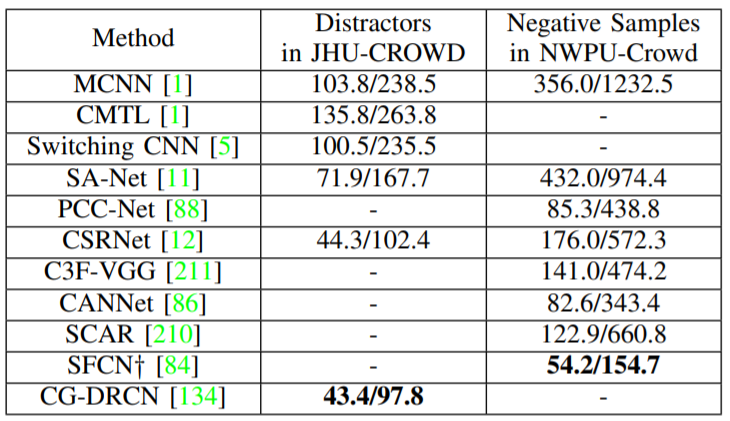
E) 背景に対するロバスト性(頑強性)
ロバストなカウントモデルは、群集密度を正確に推定するだけでなく、バックグラウンド領域のゼロ密度応答を生成する。モデルのロバスト性を評価するために、JHU-CROWD は100個のDistractorを導入し、NWPU-Crowd は351個のネガティブサンプルをそれぞれ独自のデータセットに導入している。NWPU-CROWD では、カウントモデルを混乱させるために、他のオブジェクトが密集しているシーンを意図的に収集している。 表はJHU-CROWDのDistractorとNWPUCrowd のNegative Sampleの推定誤差(MAE/RMSE)をリストアップしたもの。結果から、現在のモデルはこれらのサンプルの密度を誤って推定していることがわかる。

F) 不変性、又は一般化
既存の物体計数モデルのほぼ全ては特定のタスク用に設計されているが、どのようなクラスの物体にも適応できる普遍的なモデルを作成することは有意義な課題であり、アルゴリズムのロバスト性や一般化能力を評価する上で最も効果的な方法でもある。PPPD は、ドメイン固有のスケーリングと正規化レイヤのセットを利用することで、パッチベースのマルチドメインオブジェクト計数ネットワークを提供しており、これは少数のパラメータを使用するだけである。また、目に見えない観察されたドメインでも視覚的なドメイン分類を実行するように拡張することができ、その汎用性とモジュール性が際立っている。この手法は、人間、ペンギン、細胞の計数などへの応用に成功している。
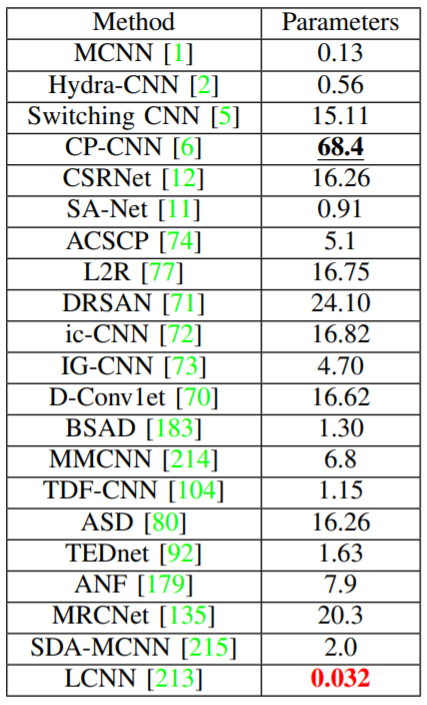
G) 軽量ネットワーク
現在のCNNベースのディープモデルは洗練された構造で設計されているが、それには常に数百万のパラメータが必要であり、計算量(FLOPs)の大幅な増加というコストがかかる。LCNN が最もパラメータ数が少ない。(最もパラメータの多いモデルであるCPCNN よりも 1/2138)軽量化と精度のトレードオフが課題。
H) 画像とビデオの組み合わせ
時間的一貫性を利用して連続密度推定に弱い制約を課すアルゴリズムがいくつか提案されている。あるフレームから次のフレームまでの密度を推定するためにLSTMモデルが利用されている。
I) ワイドビューにおける群集の数
単視点画像での群集カウントは優れた性能が得られているものの、公園や地下鉄のホームなどの大きくて広いシーンには単視点カメラでは十分な詳細情報を捉えることができないため適用できない。そのため、広域カウントの問題に対処するために,複数のカメラビューから情報を取得する試みが行われてきた。カメラが固定されカメラパラメータが既知であることを前提としているが、カメラが移動しておりカメラパラメータが未知である場合の横断シーンや多視点の計数モデルの設計は、今後の課題である。
J) 物体カウントを超えた局所化・分類・追跡
群集カウントのための密度推定CNNベースのモデルは正確なカウントは提供されるが、正確な位置や物体の正確な大きさを示すものではないため、高レベルの理解、定位、分類、追跡などのさらなる研究や応用には、限界がある可能性がある。
K) 小さな物体のカウント
非常に混雑した群衆のシーンでは、人の頭のサイズは非常に小さい。リモートセンシング画像の中の連続した密集した建物、船、小型車両、その他数え切れないほどの物体の数をカウントすることも、他のアプリケーションの可能性として考えられる。リモートセンシングシーンでの物体計数と自然界のシーンでの物体カウント間での明らかな違いは、直立した視点ではなく俯瞰した視点のため、物体の向きが任意であることである。
まとめ
・本論文では、CNNベースの密度推定と群集計数モデルについて、ネットワークアーキテクチャ、学習パラダイムなどの観点から調査を行った。
・群集計数や他分野の代表的なデータを含む一般的なベンチマークデータセットと、様々な手法を評価するための評価基準をまとめた。また、代表的なモデルの性能ベンチマーク評価も行った。
・これらの代表的な手法を包括的かつ徹底的に分析することで、上位3位までの論文を選出し、性能向上のために役立つ属性や技術をまとめた。 また、群集計数の性能に影響を与えるいくつかの要因を調査した。
株式会社Present Square では、
最新のAI手法を取り入れた群集カウントAIの開発を行っております。
興味のある方は、こちらからお問い合わせください。