はじめに
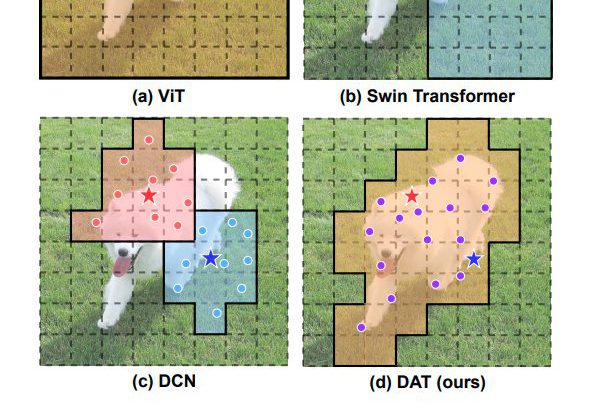
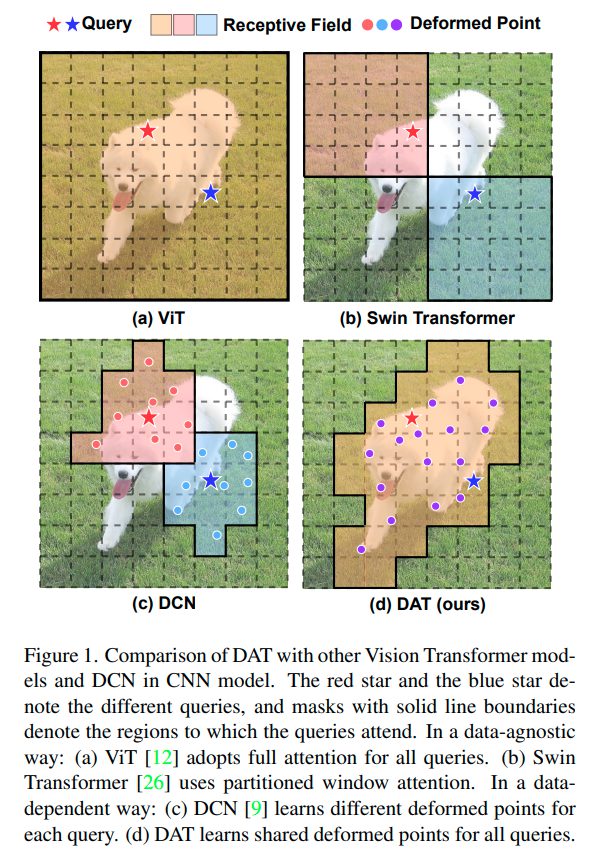
中国の清華大学を中心とした研究チームが、現在多くの画像認識タスクでSOATモデルとされる SwinTransformer を超える Deformable Attention Transformer(DAT)を発表しました。Attention 範囲をより妥当な範囲に絞り込む Deformable Attention を利用することで、性能改善を果たしています。
「Vision Transformer with Deformable Attention」
https://arxiv.org/pdf/2201.00520.pdf
● GitHub
https://github.com/LeapLabTHU/DAT
「画像認識の革新モデル!脱CNNを果たしたVision Transformer(ViT)を徹底解説!」
https://deepsquare.jp/2020/10/vision-transformer/
「自然言語処理の必須知識 Transformer を徹底解説!」
https://deepsquare.jp/2020/07/transformer/
概要
近年 Attention 機構を利用した Transformer は自然言語処理の分野で目覚ましい性能をみせ、自然言語分野ではデファクトスタンダードとなりました。画像処理分野ではConvolution 機構を利用している CNN がデファクトスタンダードでしたが、以降 Transformer を画像処理分野に組み込む試みが行われるようになりました。
当初は、CNNと組み合わせたモデルが考案されていましたが、CNN を排し Transformerのみで構築された Vision Transformer(ViT)が発表されて以降、画像処理分野でも Transformer のみをベースとしたモデルの開発が進んでいます。
ViT のように Transformer を画像処理に利用した際のメリットは、受容野の広さにあります。CNNなどよりも広範の領域を抑えることで、より良い特徴量を取得することが可能となります。
一方で、単純に Transformer を転用しただけの ViT は、Dense Transformer ともよばれ、必要とするメモリや計算コストの上昇という大きなデメリットが存在します。また、無関係な場所が特徴量に影響してしまう可能性があるという問題もあります。
そこで、 ViT を改良する形で作成されたのが、Sparse Transformer ともよばれる Pyramid Vision Transformer(PVT) や SwinTransformer などです。これらは、画像内の領域をある程度絞り込んだ箇所に対して Attention を行うことでメモリ効率や計算効率を向上するモデルです。ViT にくらべ性能や向上しましたが、一方で画像内の領域を絞り込むため、本来の領域から取得できた広範な関係性の情報を失っている可能性があります。
今回提案された Deformable Attention Transformer(DAT)は、PVTやSwinTransformerのように領域を絞り込む際に、より影響関係がある領域を選択できるような Deformable self-attention (変形可能なセルフアテンション)を利用するように改良したモデルです。このことで、従来の画像処理モデルよりも効率や性能を向上させることに成功しました。
・Deformable Attention Transformer は derformable(変形可能) な self-attention を画像認識分野に導入したモデル。
・Deformable self-attention を利用することでより影響関係がある箇所に対して Attention を行うことが可能となり、効率的かつより優位性のある処理が可能となった。
・ImageNetやCOCO、ADE20Kを利用したベンチマークテストでは、既存のPVTやSwinTransformerなどのSOTAとされるモデルよりも高い精度を記録した。
PPT版はこちらをご参考下さい。
詳細解説
開発背景
Vision Transformer の開発により、Transformer の画像処理分野における有用性が認識されるようになりました。
一方で、Vision Transformer のような通常のTransformer のみを利用した場合、以下の様なデメリットがあることが認識されるようになりました。
・必要とするメモリが大きい
・高い計算コスト
・学習の収束の遅延
・過学習の危険性の向上
これらの問題に対応するため、Transofmer に対して様々な工夫が行われてきましたが、そのなかでも有力とされたのが、Pyramid Vision Transformer (PVT)とSwin Transformer です。
Pyramid Vision Transformer (PVT)
計算コストを抑えるためにダウンサンプリングするモデル
Swin Transformer
ローカルウィンドウを利用することで Attention 範囲を制限するモデル
これらのモデルは、それぞれの目的をうまく果たし、ViTから性能を向上させることに成功しました。ただし、Swin Transformer のような人力で構築された Attention 範囲は、効率の面から最適化されていない可能性があります。これは、重要なKey/Value関係を落とした一方で、不要なものを利用している可能性があるためです。
このとき、理想は、各入力画像ごとに Attention 範囲を自由に変形しながら、重要な領域のみを利用できるようになることです。
Deformable Convolution Networks
そうした処理範囲を画像にあわせて柔軟に変形するという理想を体現しているモデルのひとつが、CNNのDeformable Convolution Networks(DCN) です。DCN は実際、CNN のなかでも効率のよいモデルとして知られています。
しかし、このDCNで行われていることを Transformer に単純に応用しようとすると、高いメモリと計算コストが必要となり、実用的ではなくなるという問題がありました。今回、作成された Deformable Attention Transformer は、現実的に利用できるように工夫した Deformable Attention を導入することで実現しました。
Deformable Attention Transformer
Deformable Attention Transformer(DAT) は、画像分類や物体検出、セグメンテーションなどのバックボーンネットワークとして利用できるモデルとなります。画像認識領域に対してはじめて「derformable self-attention backborn」を提案し、高い柔軟性と効率性を可能としました。ImageNetや、ADE20K、COCOなどの有力ベンチマークテストにおいて高いパフォーマンスを出しています。
Deformable Attention
Deformable Attention が、DAT の軸となるモジュールです。特徴量マップ内の重要な領域に対して Attention を行うことで、効率よくトークン間の関係性をモデリングすることが可能となります。オフセットネットワークによるクエリから学習された変形可能なサンプリングポイントを利用することで対象となる Attention 領域を決定します。
DCNとの違い
DCN では、特徴量マップのなかの異なるピクセルに対して、異なる領域を学習するようになっています。
対して DAT では、query-agnosticな領域グループを学習するように作成されています。領域グループで問題ないのは、近年の研究から、グローバルアテンションの結果が、異なるクエリに対してほぼ同じアテンションパターンになるということが知られているためです。このことで、Key/Values を重要な領域に焦点を合わせることが可能となります。各クエリに対して共有されシフトされたキーとバリューから似たような解を得ることで、より効率的なトレードオフが可能となっています。
※DCNと同じように処理しようとしたとき
・3×3のDCで画像がHWCの場合
計算領域:9HWC
・同様にTransformerに適用した場合
計算領域:NqNkC(Nq=Nk=HW)
→計算コストが高すぎ、実用的でないため、工夫が必要。
※Deformable DETR
Transformer とCNN を組み合わせたことで高精度を達成した DETR に Deformable モジュールを組み込んだ Deformable DETR が存在します。Deformable DETR は、Nk=4 とすることで物体検出器としてよく機能していますが、一方で許容できない情報ロスがあるためバックボーンネットワークとしては劣ってしまうという問題があります。
Deformable Attentionの流れ
最終的に、Attention では q(query)、k(key)、v(value) が必要となります。これらを算出する際に利用する Attention ポイントをDeformed (変形)するというのが Deformable Attention の特徴となります。

① 入力として特徴量マップ x ( H×W×C ) を受け取る
② 一様格子のピクセル p ( Hg×Wg×2(Hg = H/r, Wg = W/r でダウンサンプリングする)内の点)が参照点(Reference Points)として生成される。
③ 参照点は二次元座標{(0,0), …., (Hg-1, Wg-1)}上に線形射影され、[-1, +1]の間に正規化される。(Top-left=(-1,-1))
④ 各参照点からオフセットを獲得するために、特徴量マップを線形射影し、クエリトークン q = xWq を取得する。
⑤ クエリトークン q は、サブネットワークθoffsetに投入され、オフセット △p( = θoffset(q))を生成する。
※学習過程を安定させるために、事前定義した値 s を用いて△pが大きすぎるサブセットになるのを制限する。(△p←s tanh(△p))

⑥ 参照点とオフセットの情報を足して、変形した参照点(Deformed Points)を得る。
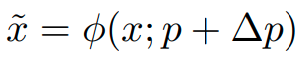
⑦ 変形した参照点に対してバイリニア補完を行い、特徴量 x~ をサンプルする。
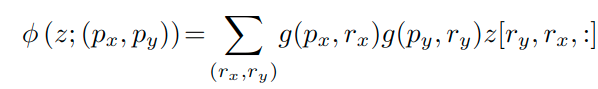
⑧ それらに対して、線形射影を行い、キートークン k~ = x~Wk と バリュートークン v~=x~Wv を得る。
⑨ ポジションエンベディングに相当する情報を組み込んだ形で、Attention が行い最終的な値を出力する。
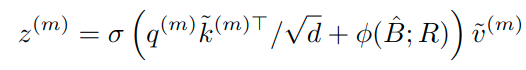
![]()
Deformable Attention の詳細について
オフセット生成
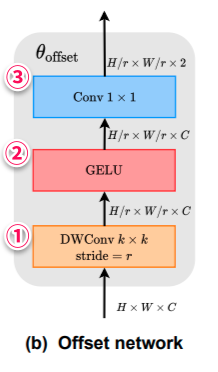
Deformable Attention では、オフセット生成のために、サブネットワークを利用しています。
このサブネットワークでは、さきほどみたようにクエリを利用して参照点ごとにオフセット値を算出します。各参照点が S × S の領域をカバーしていると考えると、サブネットワークは妥当なオフセットを学習するためにローカル特徴量の知覚を必要とすると考えられます。そのため、非線形活性化関数を用いた2つの畳み込みモジュールをもつサブネットワークを実装しています。
サブネットワークの流れ
① k × k (論文では5×5)のデプスワイズ畳み込みによりローカル特徴量を獲得する。
② GELU活性化関数に通す。
③1×1の畳み込みを行い、オフセット値を獲得する。
オフセットグループ
Deformed Points の多様性を促進するために、特徴量チャネルをG個のグループに分割します。(これは、Multi-Head Self-Attention (MHSA)の手法と同様の考え方に基づくものです。)各グループに基づく特徴量は、妥当に対応しているオフセットを生成するために共有されたサブネットワークを利用しています。
実践的には、Multi Head Attention の個数 M は、オフセットグループの数であるG倍であるようにすることで、確実に変形されたキーとバリューのトークンのグループの一つに対して、多重の Attention Head がアサインされるような作りとなっています。
Deformable relative position bias
相対位置バイアスは、クエリとキーのすべてのペア間の相対位置をエンコードします。これにより、空間情報で通常の Attention が強化されることになります。
DATでは、正規化の値、ポジションエンベディングとして、可能なすべてのオフセット値をカバーするための連続的な相対変位が行われています。
計算コストについて
Deformable multi-head atten-tion (DMHA)は、PVT や Swin Transformer など似たような計算コストになります。異なる点は、オフセットネットワークの計算量となります。
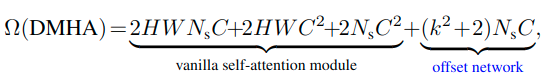
Ns = HGWG = HW=r 2
※Swin-T(H=W = 14, Ns= 49, C= 384)との比較
Swin-T が 79.63M FLOPsのとき、サブネットワークの追加によって生じる計算コストは、およそ 5.08M Flops 程度となる。なお、ダウンサンプリングファクターである r の値を大きくすることで、より計算コストを削減することができる。
モデルアーキテクチャ
DAT では、画像タスクではマルチスケール特徴量マップを必要とするため、これまでの PVT などと同じような階層的特徴量ピラミッドを形成します。
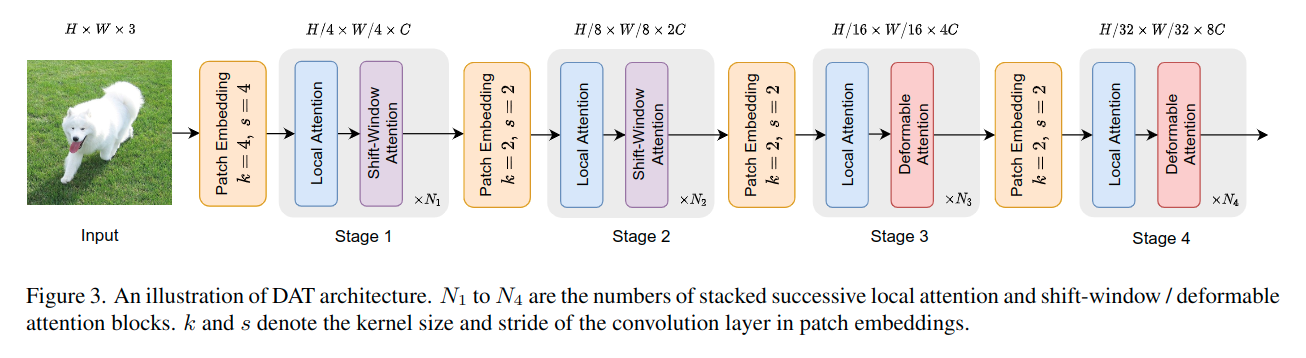

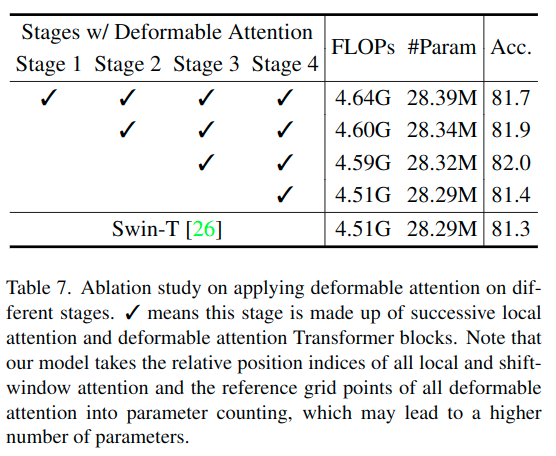
はじめのステージ(Stage1及びStage2)では、よりローカルな特徴を学習することを目的とするため、DAはあまり役にたたず、また空間も広いため、計算コストのオーバーヘッドになるため、採用していません。代わりに、Swin Transformer で利用されるウィンドウベースのローカルアテンション(Shift-Window Attention)でローカル部分の情報を統合しています。
後半のステージ(Stage3及びStage4)で Deformable Attention を利用しています。このことで、ローカルから拡張されたトーク間のより広域の関係性をモデリングすることが可能となります。
なお、分類タスクでは、最初に最終段階から出力された特徴マップを正規化し、次にロジットを予測するためにプールされた特徴を持つ線形分類器を採用しています。
物体検出、インスタンス内セグメンテーション、およびセマンティックセグメンテーションタスクでは、DATはモデルのバックボーンの役割を果たし、マルチスケールの特徴を抽出しています。物体検出、セマンティックセグメンテーションのデコーダーなどでは、FPN のように次のモジュールにフィードする前に、各ステージの機能に正規化レイヤーを追加しています。
実験
以下のベンチマークテストがおこなわれています。
・画像分類: ImageNet-1K
・物体検出: COCO
・セグメンテーション: ADE20K
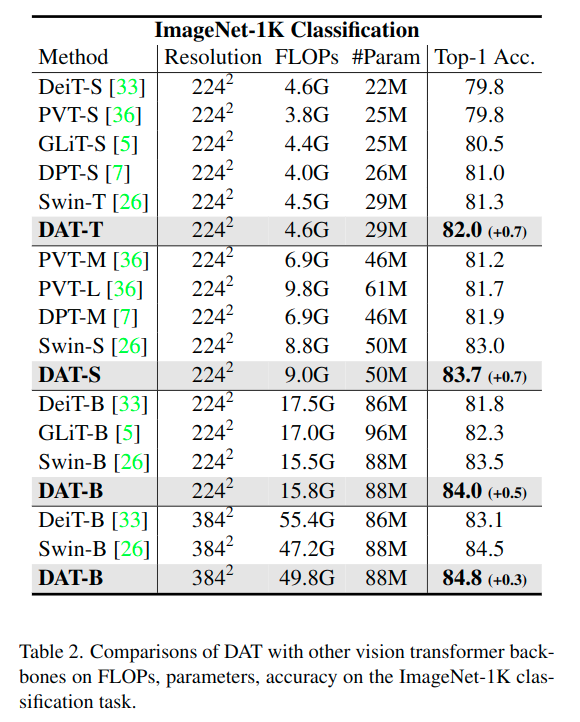
ImageNet-1K(画像枚数:学習用1.28M 検証用50K)
以下の設定で検証が行われました。PVT や Swin Transformer よりも大幅な改善がみられます。
・実験設定
オプティマイザ:AdamW
エポック:300
初期学習率:1 × 10**-3(ウオームアップ 1 × 10**-6→1 × 10**-3)(cosine learning rate decay)
データ拡張:RandAugment 、 Mixup、CutMix
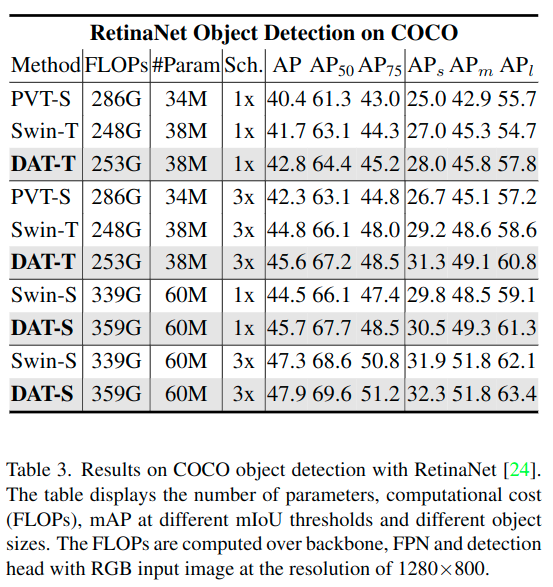
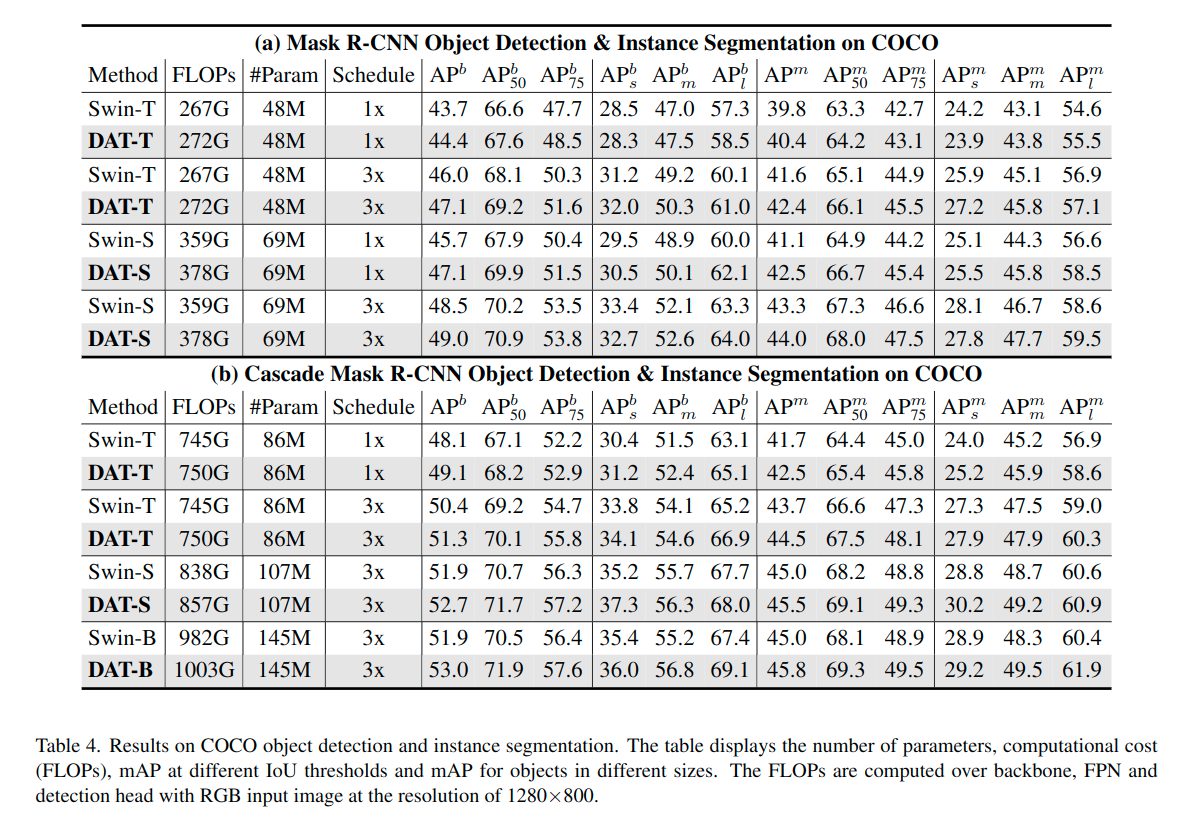
COCO(画像枚数:学習用118K 検証用5K)
RetinaNet、Mask R-CNN、Cascade Mask R-CNNのバックボーンネットワークとして利用し、比較しています。Swin Transformer モデルなどと比べよい成果を出しています。特により大きな物体の検出が得意であることがわかりました。
・実験設定
事前学習:ImageNet-1K(300エポック)
パラメータ:SwinTransformerと同じ
ADE20K(画像枚数:学習用20K 検証用2K)
SemanticFPN と UperNet のバックボーンネットワークとして利用して、比較されました。mIOU スコアで比較され、全体としてよりよい精度を出しました。特にPVT の Tiny モデルと比較すると、大きな改善がみられます。
・実験設定
事前学習:ImageNet-1K
学習:SemanticFPN 40ステップ、UperNet 160K
アブレーションスタディ
現在の組み合わせが有効であることを、ImageNet-1Kの分類によるアブレーションスタディにより確認しています。
・オフセットとポジションエンベディングの必要性の確認
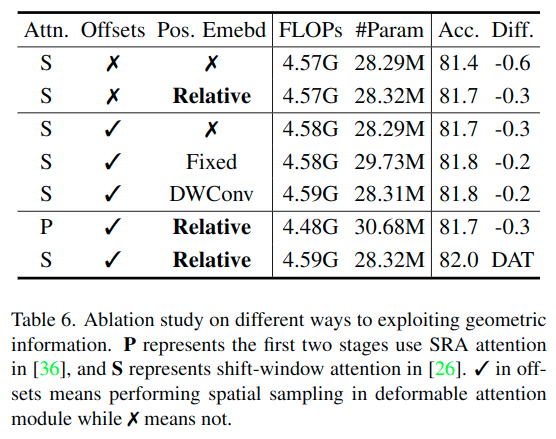
・Deformable Attention の有効なステージの確認
可視化実験
参照点を可視化することで、Swin Transformer よりもより重要な領域に対して参照点が変形されていることを確認します。(各点が格子上の状態をベースとして、対象物体に対して寄っていることが確認できます。)

まとめ
今回は、Deformable Attention Transformer について解説しました。Deformable の考え方及び実装は、CNN を通して培われた技術であり、そうした技術が Transformer にも工夫することで応用できることが明らかになったといえます。
その他にも FPN などの階層的な特徴量の利用などの技術が応用されていることからもわかるように 今後も CNN や Transformer という大きな枠組みはあるものの分野横断的に技術が応用されていくことが想定されます。今後も重要な技術については常に応用可能性を検討していく必要があり、着目していきます。