はじめに
現在FacebookAIResearch(FAIR)のチーフサイエンティストで、AIの開発者として著名なヤン・ルカン(Yann LeCun)氏が自己教師あり学習について解説した内容についてご紹介します。
『Self-supervised learning: The dark matter of intelligence』
https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/
概要
教師あり学習はAIの進歩を牽引してきました。ただし、教師あり学習によって作られるモデルはいわばタスクのスペシャリストです。また教師データの作成には莫大なコストがかかり、世界のあらゆる事象に対して教師データを作るのは現実的とはいえません。そのため、教師あり学習の利用は汎用型AIのボトルネックともいえます。
そのため、自己教師あり学習 Self-Supervised Learning: SSLをより発展させることが今後重要になると考えられます。なお、自己教師あり学習は教師なし学習 Unsupervised Learning とも呼ばれることがありますが、実際にはデータに含まれる教師信号 Supervisory signalsを利用しているため、誤解をうむものであり、利用は望ましいとはいえません。
今後、自己教師あり学習では、不確実性の存在下での予測のためのエネルギーベースのモデル、共同埋め込み法、AIシステムにおける自己学習と推論のための潜在変数アーキテクチャなど、最も有望と考えられる新しい方向性に注力していく必要を指摘しています。
詳細
教師あり学習と自己教師あり学習
教師あり学習
近年のAIの進歩を牽引してきたのは、教師あり学習です。教師あり学習によるモデルは特定のタスクのために作られたデータセットを学習することになります。いわば、スペシャリストを育てることになります。教師あり学習の問題点は、限られた分野でしか利用できないことにあります。
教師あり学習は、ラベルデータなしでマルチタスクをこなし新たな技術を吸収していくような汎用性のあるモデルの作成のボトルネックになっています。単純に、世界のすべてにラベルをつけることは不可能である、ということが教師あり学習の限界を明らかにしています。また、ラベル付けが難しいようなものもあることが限界をさらに強調します。そのため、AIにも、人間のように教師データがなくても、柔軟に学習することができることが求められます。
生物の学習能力
赤ちゃんのころから生物は主に観察によって世界がどのように機能するかを学びます。オブジェクトの永続性や重力などの概念を学習することにより、世界のオブジェクトに関する一般化された予測モデルを形成します。世界を観察し、それに基づいて行動し、再び観察し、そして試行錯誤によって行動が環境をどのように変えるかを説明するための仮説を立てます。
作業仮説(a working hypothesis)は、世界に関する一般化された知識、または「常識 common sense」が、人間と動物の両方で生物学的知性の大部分を形成するというものです。この「常識」という能力は、人間や動物では当然のことと考えられていますが、AI研究の開始以来、未解決の課題であり続けています。ある意味で、「常識」は人工知能の暗黒物質(宇宙に存在することはわかっているが、よくわかっていない物質の総称)といえます。
自己教師あり学習
自己教師あり学習は、「常識」を獲得するための重要な手法であるといえます。教師あり学習で利用できるデータ数とは桁違いのデータを使って、世界のより微妙であまり一般的でない表現のパターンを認識して理解することが可能になります。
今回は、自己教師あり学習のうち、不確実性の存在下での予測のためのエネルギーベースのモデル、共同埋め込み法、AIシステムにおける自己学習と推論のための潜在変数アーキテクチャなど、最も有望な新しい方向性と思われるものにもスポットを当てています。
自己教師あり学習とは
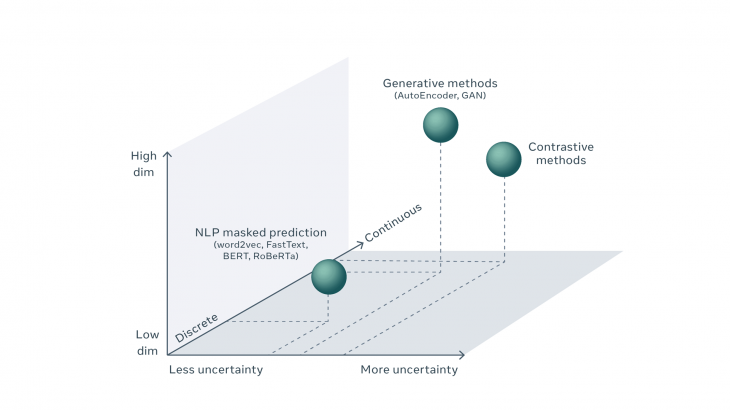
自己教師あり学習とは、『予測学習』であるといえます。データ自身に隠されている構造を読み取り、次にくるものを予測する学習を行います。この学習を通してデータ内部の構造を学習していきます。代表的なものに自然言語処理 : NLP などで行われる次文予測タスクによる自己教師あり学習などがあげられます。NLP分野一般では自己教師あり学習はある程度成功しているといえますが、新たなドメイン(画像認識など)に広げることが難しいという問題があります。実際、NLPで成功しているのにもかかわらず、画像認識 CV ではあまり利用されていません。主な理由は、画像の予測の不確実性を言語よりも表現するのがかなり難しいためです。
自然言語処理の場合
まず予測の不確実性を扱うということについて、NLPについてみてみます。NLPでは、欠落している単語を予測するには、語彙内のすべての可能な単語の予測スコアを計算する必要があります。語彙自体は大きく、欠落している単語を予測するにはある程度の不確実性が伴いますが、その場所での単語の出現の確率推定とともに、語彙内のすべての可能な単語のリストを作成することは可能です。典型的な機械学習システムは、予測問題を分類問題として扱い、巨大ないわゆるソフトマックス層を使用して各結果のスコアを計算することによってこれを行います。この手法では、予測の不確実性は、可能な結果の数が有限であるという条件で、すべての可能な結果にわたる確率分布によって表されます。
画像処理の場合
つまり、同じことが画像でもできれば、画像処理分野でも自己教師あり学習が利用できます。しかし、ビデオのフレームの欠落や画像のパッチの欠落を予測するときに、不確実性を効率的に表す方法は現在のところ、確立されていません。NLPの語彙のように、可能なすべてのビデオフレームをリストし、それらのそれぞれにスコアを関連付けることなどの方法はそれらの数が無限にあるため事実上不可能になっています。無限にあるとは、CVでは、ビデオの「欠落した」フレーム、画像の欠落したパッチ、または音声信号の欠落したセグメントを予測する類似のタスクには、離散的な結果ではなく、高次元の連続オブジェクトの予測が必要になるためです。そのため与えられたビデオクリップをもっともらしく追跡できるビデオフレームは無数にあることになります。この問題により、視覚におけるSSLによるパフォーマンスの向上が制限されています。
例えば、言語の場合、「ライオン」が正解の場合、ライオンが予測できなかったとしても、候補単語として「チーター」などの捕食者のスコアを高くすることで語彙内の単語同士を関連付けることができます。しかし、画像の場合は候補となる画像の選択肢が無数にあり、絞り込むことが事実上できません。
※また、このような語彙のような巨大なものを扱う大規模なモデルをトレーニングするには、精度を犠牲にすることなく、ランタイムとメモリの両方の点で効率的なモデルアーキテクチャも必要となります。これはFAIRで新たに開発されたRegNetsで解決できます。RegNetモデルは、数十億または場合によっては数兆のパラメーターに拡張できるConvNetであり、さまざまなランタイムおよびメモリの制限に合わせて最適化できます。
CV分野でも利用できるような形での自己教師あり学習として、近年研究されているのが、不確実性の存在下での予測のためのエネルギーベースモデル、共同埋め込み法、AIシステムにおける自己学習と推論のための潜在変数アーキテクチャです。
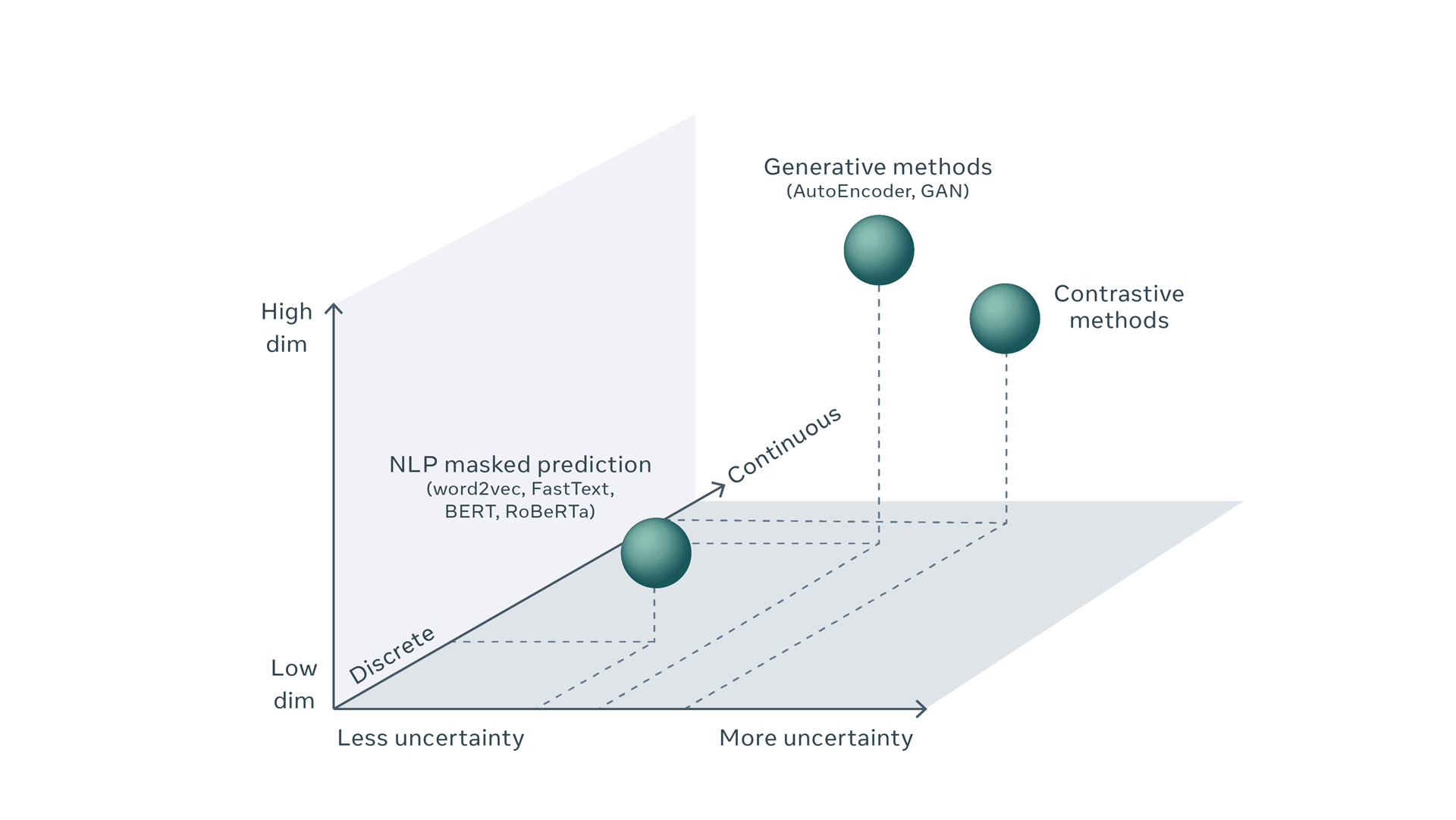
Energy-Based Model(EBM)
EBMはトレーニング可能なシステムであり、xとyの2つの入力が与えられると、それらが互いにどの程度互換性がないかを示します。xとyの間の非互換性を示すために、マシンはエネルギーと呼ばれる単一の数値を生成します。エネルギーが低い場合、xとyは互換性があると見なされます。それが高い場合、それらは互換性がないと見なされます。
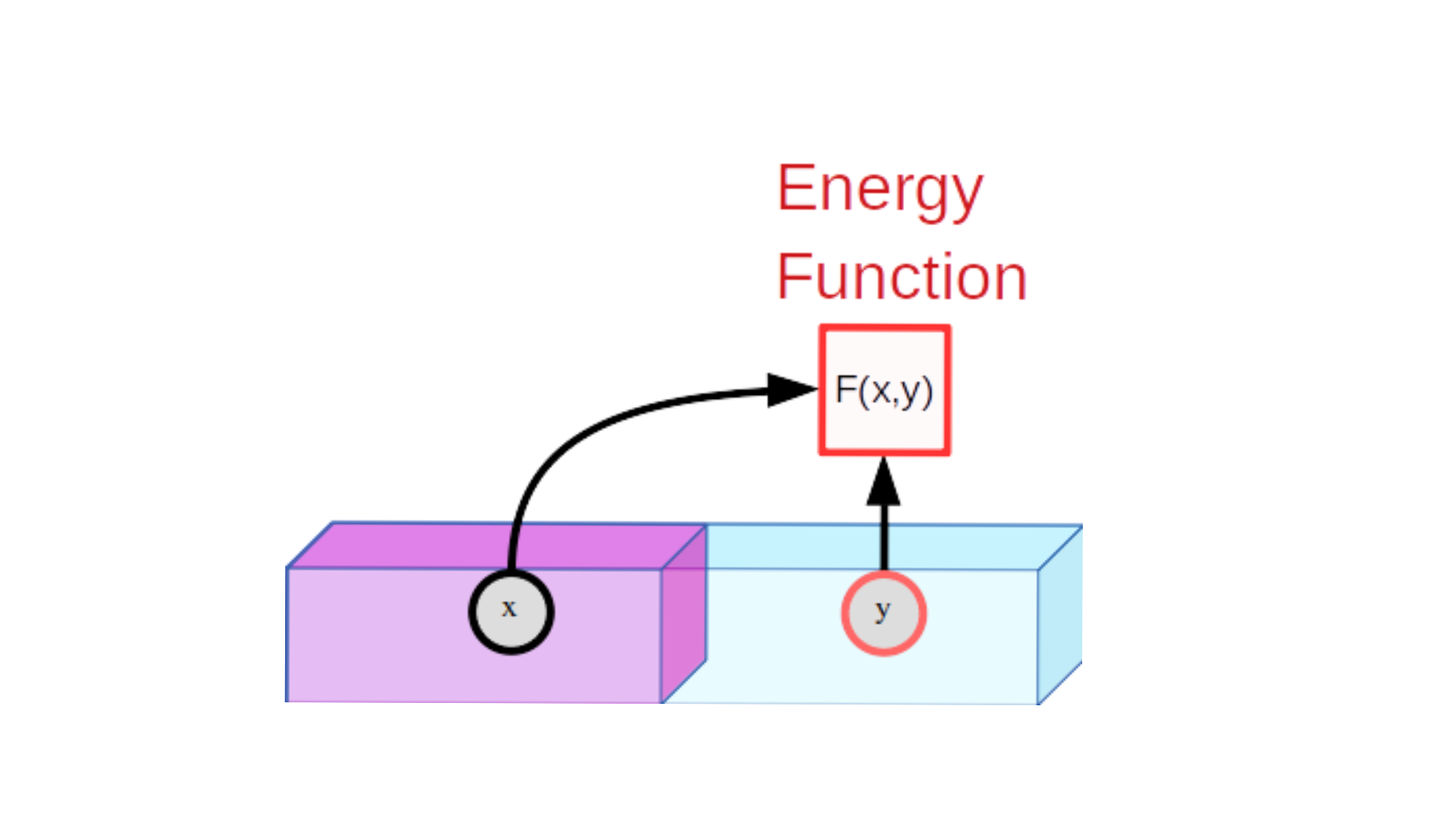
学習過程
(1)互換性のあるxとyの例を示し、低エネルギーを生成するようにトレーニングします。
(2)特定のxについて、xと互換性のないy値がxと互換性のあるy値よりも高いエネルギーを生成することを保証する方法を見つける。
画像認識の場合、モデルは入力としてxとyの2つの画像を取ります。 xとyが同じ画像のわずかに歪んだバージョンである場合、モデルはその出力で低エネルギーを生成するようにトレーニングされます。たとえば、xは車の写真であり、yは同じ車の写真で、わずかに異なる場所から異なる時刻に撮影されたものである可能性があるとします。そのときyの車が移動、回転、拡大、縮小され、xの車とはわずかに異なる色と影が表示されたものであったとき、低エネルギーが出力されることが期待されます。ただし、この学習自体はそこまで難しくありません。EBMの難しさは、学習過程の⑵の部分にあります。
共同埋め込み Joint Embedding, Siamese networks
共同埋め込みアーキテクチャ Joint Embedding は、同じネットワークの2つの同一(またはほぼ同一)のコピーで構成されます。一方のネットワークにはxが供給され、もう一方のネットワークにはyが供給されます。ネットワークは、xとyをベクトル空間に埋め込み embedding、ベクトルを生成します。その後、2つのベクトル間の距離としてエネルギーを計算します。モデルに同じ画像の歪んだバージョンが表示されている場合、ネットワークのパラメーターを簡単に調整して、距離を近づけることができます。これにより、オブジェクトの特定のビューに関係なく、ネットワークがオブジェクトのほぼ同一の表現(またはベクトル)を生成することが保証されます。
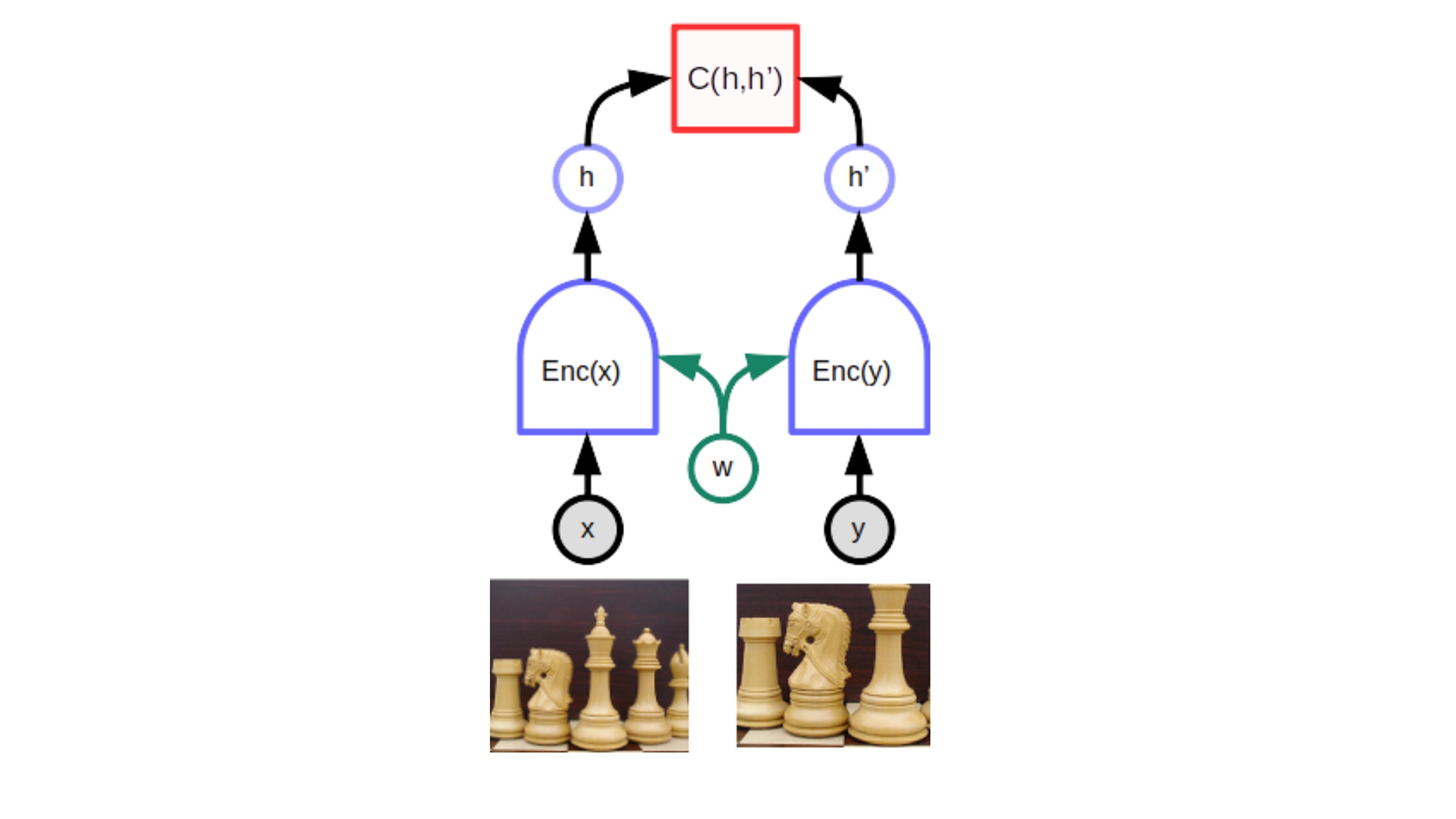
上部の関数Cは、同じパラメータ(w)を共有する2つの同一の双子ネットワークによって生成される表現ベクトル(埋め込み)間の距離を測定するスカラー・エネルギーを生成します。xとyが同じ画像のわずかに異なるバージョンである場合、システムは低いエネルギーを生成するように訓練され、モデルは2つの画像について同様の埋め込みベクトルを生成するように強制されます。
難しいのは、xとyが異なる画像である場合に、ネットワークが高エネルギー、つまり距離が遠くなるような異なるベクトルを生成するようにすることです。そのための特別な方法がなければ、2つのネットワークは入力を無視して、常に同じ出力ベクトルを生成する可能性があります。この現象は「崩壊」と呼ばれます。崩壊が発生した場合、エネルギーは、xとyが一致する場合よりも、xとyが一致しない場合の方が高くなりません。崩壊を回避するための手法には、「対照的手法 contrastive methods」と「正則化手法」の2つがあります。なお、正則化手法に関してはここでは取り上げません。
対照的なエネルギーベースの自己教師あり学習 Contrastive energy-based SSL
対照的な方法は、互換性のないxとyのペアを作成し、対応する出力エネルギーが大きくなるようにモデルのパラメーターを調整するという単純なアイデアに基づいています。
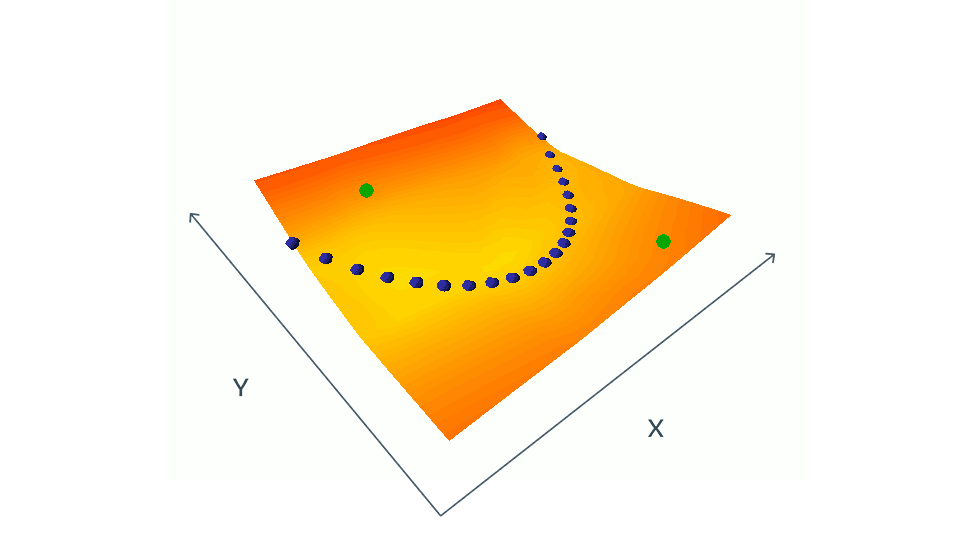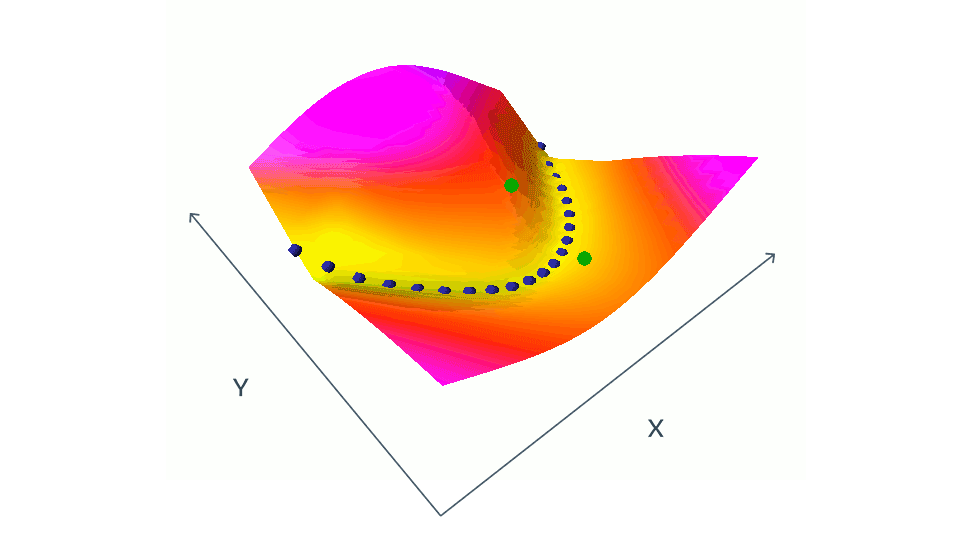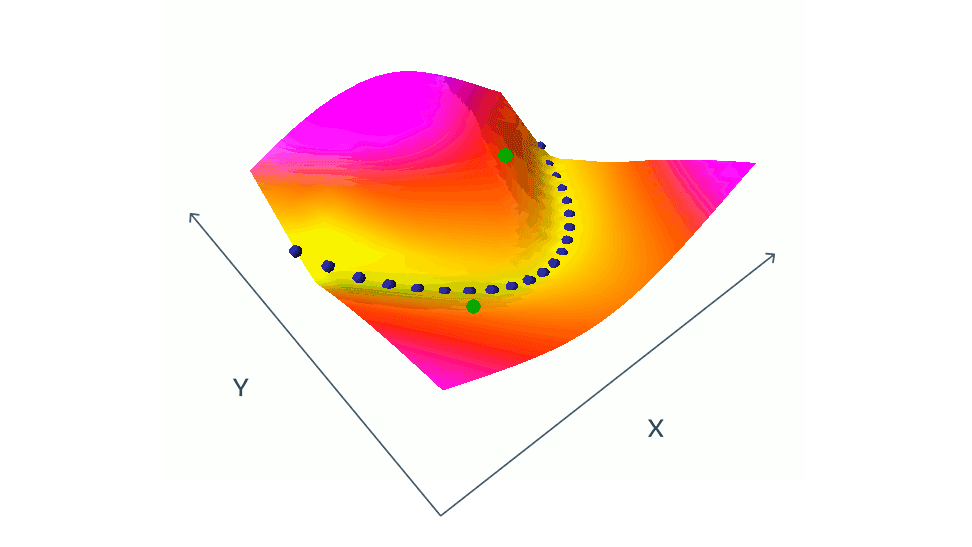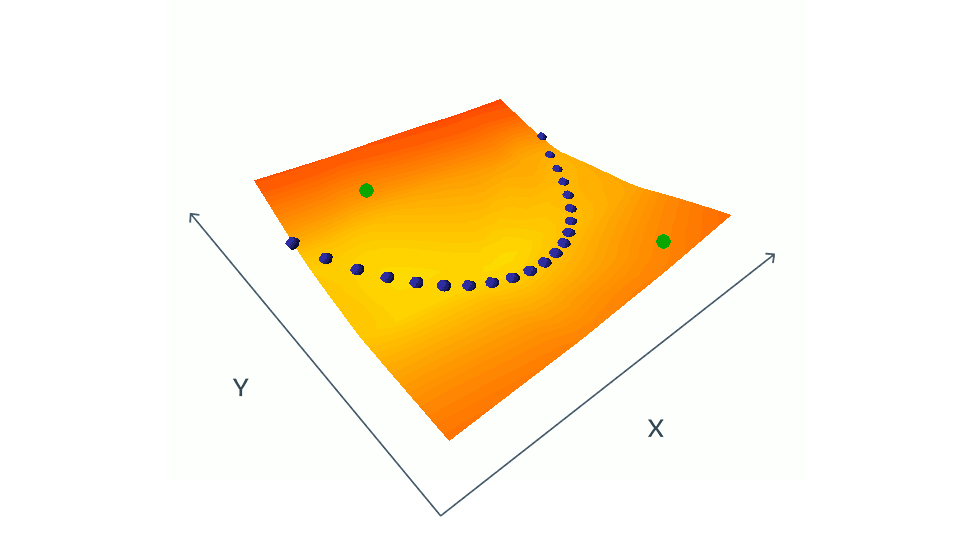
対照法を用いたEBMの学習は、青い点で示された学習セットから互換性のある(x,y)ペアのエネルギーを同時に押し下げ、緑の点で示された互換性のない(x,y)ペアのエネルギーを同時に押し上げることで構成されます。この単純な例では、xとyは両方ともスカラー値ですが、実際の状況では、xとyは何百万もの次元を持つ画像やビデオである可能性があります。エネルギーを適切な方法で形づくることができる相容れないペアを考えることは、困難であり、計算コストがかかります。
一部の入力単語をマスキングまたは置換することによってNLPシステムをトレーニングするために使用される方法は、対照的な方法のカテゴリに属します。ただし、共同埋め込みアーキテクチャは使用していません。代わりに、モデルがyの予測を直接生成する予測アーキテクチャを使用しています。
テキストyの完全なセグメントから開始し、次に、たとえば、いくつかの単語をマスクして観測値xを生成することにより、テキストyを破損します。破損した入力は、元のテキストyを再現するようにトレーニングされた大規模なニューラルネットワークに送られます。破損していないテキストはそれ自体として再構築され(再構築エラーが少ない)、破損したテキストは破損していないバージョンとして再構築されます(再構築エラーが大きい)。再構成エラーをエネルギーとして解釈すると、望ましい特性が得られます。「完全な」テキストの場合は低エネルギー、「破損した」テキストの場合は高エネルギーとして出力されます。
破損したバージョンの入力を復元するようにモデルをトレーニングする一般的な手法は、ノイズ除去オートエンコーダーと呼ばれます。
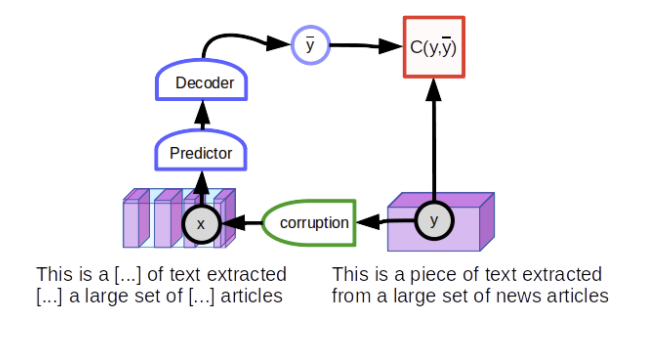
ノイズ除去オートエンコーダのインスタンスであるマスクされた言語モデル、それ自体が対照的な自己教師あり学習のインスタンス。変数yはテキストセグメントです。 xは、一部の単語がマスクされたテキストのバージョンです。ネットワークは、破損していないテキストを再構築するようにトレーニングされています。
このタイプの予測アーキテクチャは、特定の入力に対して単一の予測しか生成できません。しかしモデルは複数の可能な結果を予測できなければならないため、予測は単一の単語セットではなく、語彙内のすべての単語に対して与えられる確率値のスコアセットになります。
ただし、上述した通り、考えられるすべての画像を列挙することはできないため、このトリックを画像に使用することはできません。この方向には興味深いアイデアがありますが、それらはまだ共同埋め込みアーキテクチャほど優れた結果には至っていません。興味深い方法の1つは、潜在変数予測アーキテクチャです。
潜在変数予測モデル
潜在変数モデルは、対照的な方法でトレーニングできます。好例は、生成的敵対的ネットワーク(GAN)です。識別者は、入力yが適切に見えるかどうかを示すエネルギーを計算していると見なすことができます。生成ネットワークは、識別者が高エネルギーを関連付けるように訓練された対照的なサンプルを生成するように訓練されているといえます。
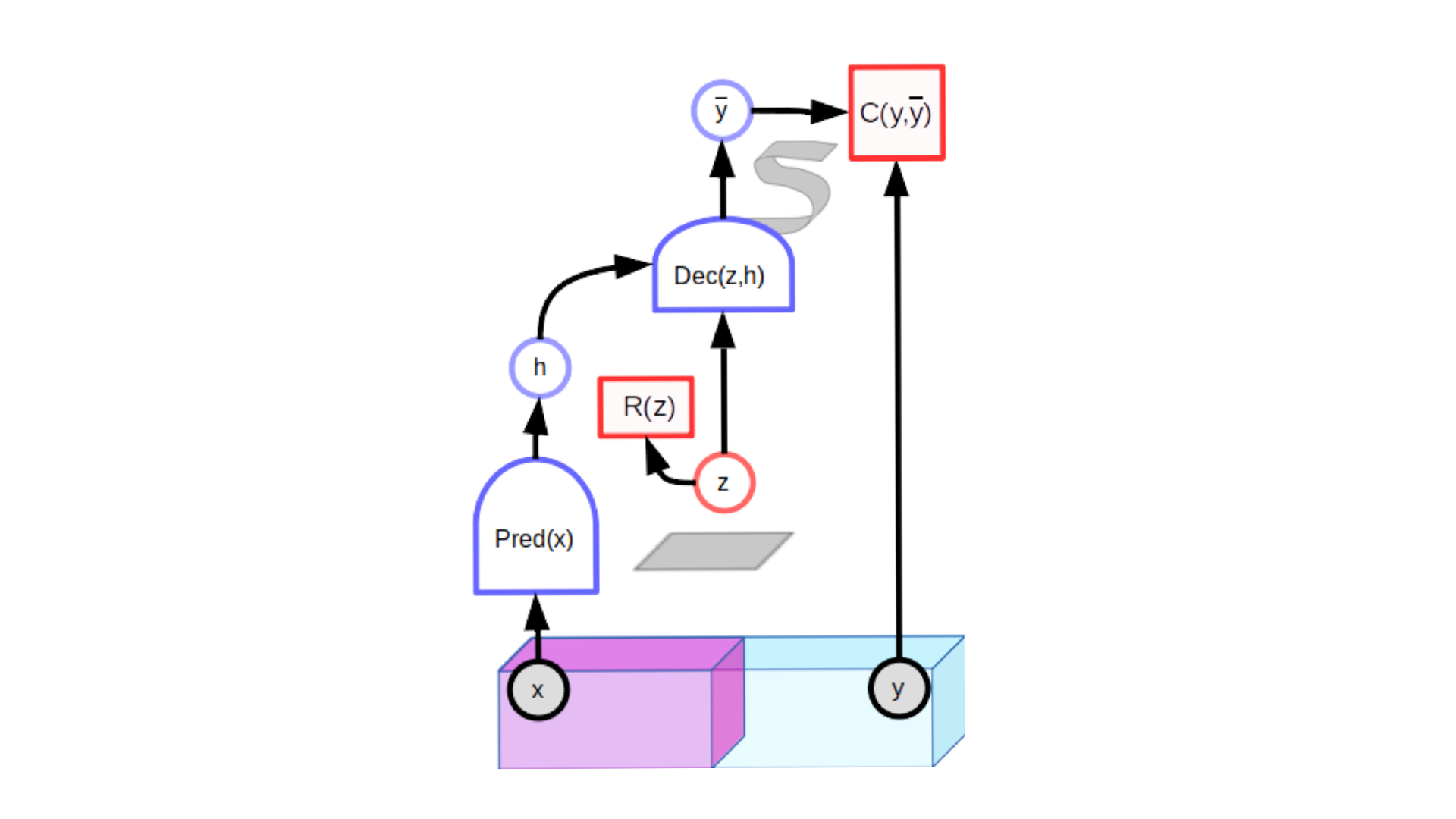
潜在変数予測モデルには、追加の入力変数(z)が含まれています。その値が決して観察されないので、それは潜在的と呼ばれます。適切にトレーニングされたモデルでは、潜在変数が特定のセットで変化するため、出力予測は入力xと互換性のあるもっともらしい予測のセットで変化します。
しかし、対照的な方法には大きな問題があります。それは学習が非常に非効率的であるということです。画像などの高次元空間では、ある画像が別の画像と異なる可能性を示す方法は多々あります。そのため特定の画像とは異なる可能性のあるすべての点をカバーする対照的な画像のセットを見つけることは、ほぼ不可能な作業であるといえます。
多くの互換性のないペアのエネルギーを明示的に押し上げることなく、互換性のないペアのエネルギーが互換性のあるペアのエネルギーよりも高いことを確認するための方法が必要となります。
Non-contrastive energy-based SSL
共同埋め込みアーキテクチャに適用される非対照的な方法は、現時点で画像のためのSSLでおそらく最も重要なトピックといえます。このドメインはまだ大部分が未踏ですが、非常に有望だと考えられます。 DeeperCluster、 ClusterFit、 MoCo-v2、 SwAV、 SimSiam、 Barlow Twins、 BYOLなどのモデルが現在までに提案されています。これらには様々なトリックが利用されています。
・DeeperCluster、 SwAV、 SimSiam
類似した画像のグループに対して仮想的なターゲットエンベッディングを計算します。
・BYOL、MoCo
2つの共同埋め込みアーキテクチャをアーキテクチャやパラメータベクトルを通してわずかに異なるものにします。
・Barlow Twins
埋め込みベクトルの個々のコンポーネント間の冗長性を最小化しようとします。
おそらく、長期的には、潜在変数予測モデルを使用して非対照的な方法を考案することが重要になると考えられます。主な問題は、潜在変数の容量を最小化する方法が必要なことです。潜在変数が変化する可能性のあるセットのボリュームは、低エネルギーを使用する出力のボリュームを制限します。この体積を最小化することにより、エネルギーを正しい方法で自動的に形作ります。
この方法の成功例は 変分オートエンコーダー (VAE)です。潜在変数が「ファジー」になり、その容量が制限されます。しかし、VAEは、下流の視覚的タスクに対して適切な表現を生成することはまだ示されていません。別の成功例は スパースモデリングですが、その使用は単純なアーキテクチャに限定されています。潜在変数の容量を制限する完璧な方法はいまだに存在しないといえます。
まとめ
近年、ハードウェアの進歩やTransformerモデルの発達によりAIは大規模モデル化が進んでいます。その際、問題のひとつがどのように学習データを確保するのかということですが、解決方法としてはおもに教師データを明示的に人間が作らない(=ネット上などから自動的に収集する)か、今回のように教師あり学習ではない方法で行うことがメインとなっています。いまは前者の機械的に収集することで教師データを大規模化することが主流といえますが、解説にあったように汎用化には自己教師あり学習が必ず必要になってきます。今後、注力されていく分野といえると思います。