
はじめに
Google リサーチとミシガン大学の研究チームは、ICCV2021に向けて、なじみのない建物内でどこに何があるか予測しナビゲーションする世界モデル Pathdreamer を発表しました。
Pathdreamer: A World Model for Indoor Navigation
https://arxiv.org/abs/2105.08756
●GitHub
https://github.com/google-research/pathdreamer
問題・背景
人間はなじみのない建物であっても、目的地に向かって移動するとき、多くの視覚的、空間的、意味論的な手がかりを利用して、効率的に目的地に到達します。一方で現在のロボットエージェントにとっては、人間のように意味的な手がかりと統計的な規則性を利用して未知の建物を効率的に移動することは困難なタスクとなります。
現在、タスクを解決するために一般的にロボットエージェントに対して用いられるアプローチは、モデルフリーの強化学習です。この手法は、「手がかりが何であるか」および「ナビゲーションタスクにそれらを使用する方法」を経験から暗黙的に学習させます。
しかし、この方法でナビゲーションを学習するのは、計算コストが高く、またテストが難しく、最初から学習しなおさずに別のエージェントで再利用するのが困難です。

図1 人間は多くの手がかりを利用して、角を曲がったところを予測することができます。この機能を備えた計算モデルが、視覚的な世界モデルです。
今回、研究チームは、代替手段として、世界モデルを使用した、周囲に関する「豊富」で「意味のある」情報をカプセル化する方法に着目しています。これにより、エージェントは、環境内の実行可能な行動の結果を予測することが可能となります。このようなモデルは、ロボット工学、シミュレーション、強化学習などの分野から広く関心を持たれており、シミュレートされた2Dカーレースタスクの解決方法の発見や、Atariゲームでの人間レベルのパフォーマンスの達成など、既に多くの成果を出しています。しかし、ゲーム環境は、実環境の複雑さと多様性に比べると、依然として比較的単純であり、現実への応用に関してはさらなる改良が期待されていました。
新規性
Pathdreamer は未知の建物内領域を高解像度360度で予測できる世界モデル
ICCV 2021で公開された論文「Pathdreamer: A World Model for Indoor Navigation」は、限られたシード観測(seed observations)と、提案されたナビゲーション軌道(proposed navigation trajectory)のみを使用して、エージェントが見たことのない建物内領域に対して高解像度360度視覚観測を生成する世界モデルを提示しました。
以下のビデオに示すように、Pathdreamer モデルは、単一の視点から没入型シーン(immersive scene)を合成し、エージェントが新しい視点に移動した場合、または角を曲がったところなど、完全に見えない領域に移動した場合に何が見えるかを予測できます。

図2 Pathdreamer は角を含む元の場所から最大6~7メートル離れた高解像度の360度の観測を合成します。その他の結果については、ビデオ全体を参照してください。
Pathdreamer はどのように機能するか
入力と予測はどちらも、RGB、セマンティックセグメンテーション、深度画像で構成されています。
以下は、Pathdreamer が環境内の表面形状を表現する様子です。

図3 Pathdreamaer が環境内の表面形状を表現する様子
内部的には、セマンティックラベル(上)とRGBカラー値(下)の両方を含む3Dポイントクラウドを介して環境内の表面を表します。新しい観測値を生成するために、点群を介して新しい場所に「移動」し、再投影された点群画像をガイダンスとして使用しています。
ガイダンス画像を現実的な出力に変換するために、Pathdreamer は2つの段階で動作します。最初の段階である構造ジェネレータはセグメンテーションと深度画像を作成し、2番目の段階である画像ジェネレータはこれらをRGB出力にレンダリングします。どちらの段階も、畳み込みニューラルネットワークに基づいています。
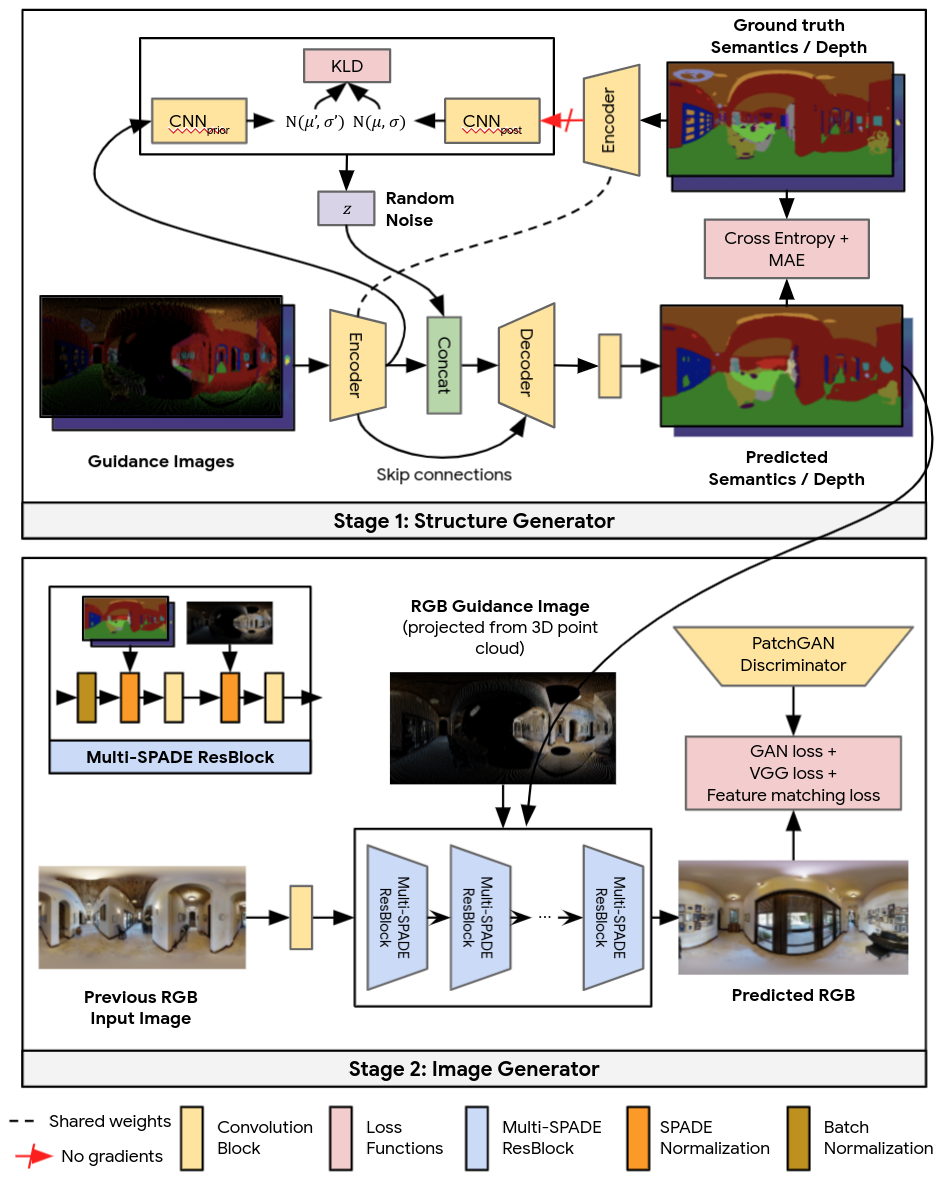
図4 Pathdreamerは2つの段階で動作します。最初の段階はシーンのもっともらしい高レベルのセマンティック表現を提供し、2番目の段階ではそれをリアルなカラー画像にレンダリングします。
多様な生成結果
Pathdreamer は、角を曲がった場所や見えない部屋など、不確実性の高い領域に対して、複数のもっともらしい画像を生成することができます。構造ジェネレータは、ガイダンス画像にキャプチャされていない次の場所に関する確率的情報を表すノイズ変数を条件としており、複数のノイズ変数をサンプリングすることで、多様な生成結果をサンプリングできるようにしています。
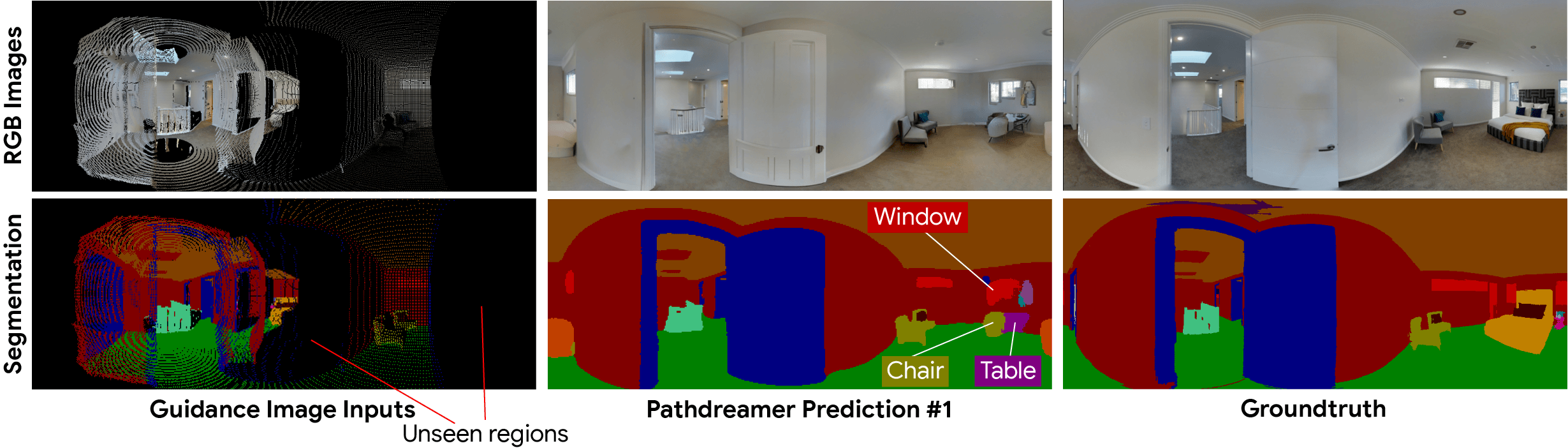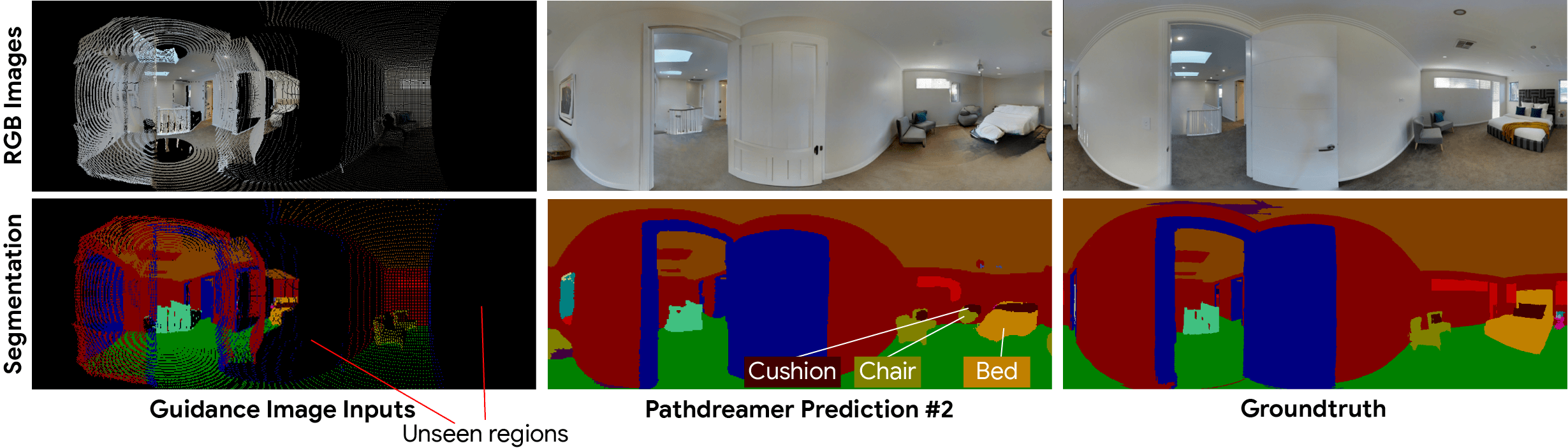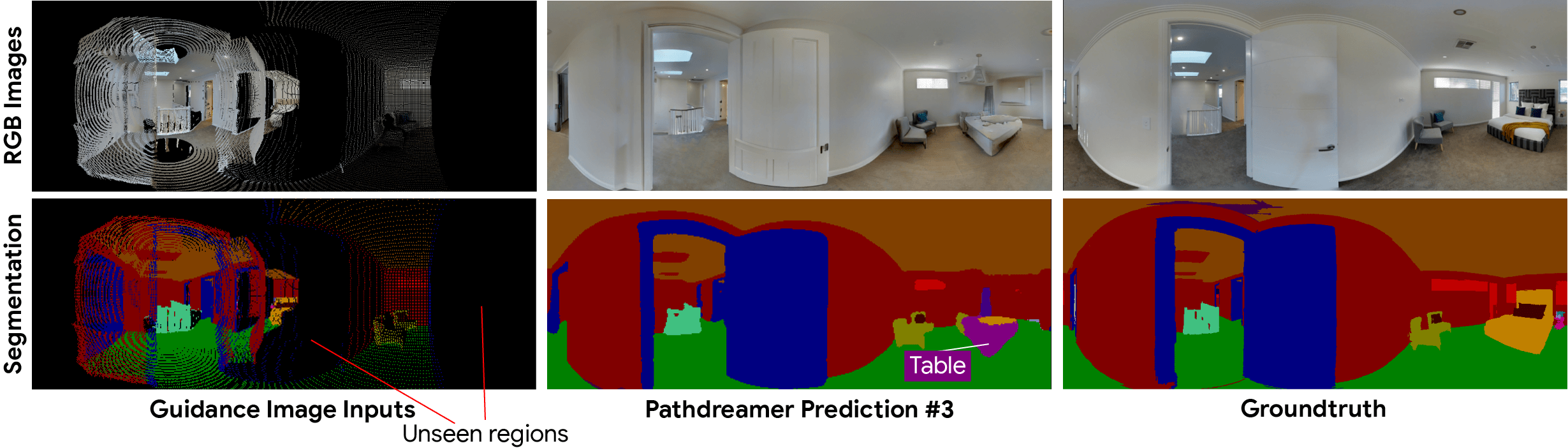
図5 Pathdreamerは、多様な画像を生成できます。
視覚的なナビゲーションタスクへの適用
研究チームは、Pathdreamer が視覚的な世界モデルとして下流タスクのパフォーマンスを向上させる可能性を実証するために、Vision-and-Language Navigation(VLN)タスクに適応させ検証しました。このタスクでは、エージェントが自然言語の指示に従って、現実的な3D環境の場所に移動する必要があります。
その結果、Pathdreamer設定でVLNエージェントは50.4%のナビゲーション成功率を達成し、Pathdreamer なしのベースライン設定での40.6%成功率よりも大幅に高くなりました。これは、Pathdreamer が実際の屋内環境に関する有用でアクセス可能な視覚的、空間的、および意味論的知識をエンコードしていることを示唆しています。
まとめ
これらの結果は、複雑な具体化されたナビゲーションタスクに Pathdreamer などの世界モデルが有用である可能性を示しています。Pathdreamer が、指定された物体やLVNタスクのナビゲーションなど、具体的なナビゲーションタスクに挑戦するために役立つことが期待されます。