本論文は、人工知能研究者である、Yann LeCun さんが発表された論文です。
厳密な技術論文・学術論文ではなく、人間や動物により近い自律的機械知の実現に向けて提案されているポジションペーパーとなります。
提案内容は、実験に基づくものではありませんが、これまでのAI研究の要素・アイディアを盛り込み、一貫した全体像を組み立てている点が興味深いため、取り上げました。今後の発展・進歩を考える上でも、非常に示唆に富む内容だと感じています。
詳細はこちらのスライドを参考下さい。
基本情報
参照URL:https://openreview.net/pdf?id=BZ5a1r-kVsf
概要
本論文の主な貢献は以下の4つあります。
- 1. すべてのモジュールが微分可能で、その多くが訓練可能な全体的な認知アーキテクチャを提案
- 2. JEPA と 階層的JEPAを提案
- 3. 情報量が多く予測可能な表現を同時に生成する、非対称型自己教師あり学習 を提案
- 4. 不確実性の下で予測世界モデルの基礎として、階層型JEPAを使用する方法 を提案
すべてのモジュールが微分可能な汎用AIを提案している点、
その構成の中でも重要な役割を担っている「JEPA」というアーキテクチャについて、特に取り上げていきます。
問題・背景
現在、AI研究が取り組むべき課題は大きく3つあると述べられています。
- 1. 機械は観察によって、どのようにして世界を表現すること、予測することを学び、行動することを学ぶことができるのか?
- 2. 機械はどのようにして、勾配に基づく学習と互換性のある方法で推論し、計画を立てることができるのか?
- 3. 知覚や行動計画を、階層的に複数の抽象度で、複数の時間スケールで表現することを、機械はどのように学習するのだろうか。
特に、人間や動物が世界の仕組みを学ぶことができるように、どのように機械に効率的に、汎用的に学習させるか、と言う点に課題意識があります。
人間や動物は、少ないインタラクションと観察を通して、世界の仕組みと背景知識を学ぶことができるようです。これは、しばしば常識と呼ばれるものを基礎を構成していると仮定きます。常識的な知識は、単に将来の結果を予測するだけでなく、時間的、空間的に欠落した情報を補うことができます。常識とは、何がありそうで、何がありえないかを教えてくれる世界モデルの集合体と見ることができます。
このような世界モデルを用いると、ほとんど試行することなく新しい技能を習得することができます。動物たちは、自分の行動のシーケンスを予測し、推論し、計画し、探索し、問題に対する新しい解決策を想像することができると考えられます。そのため、教師なし(または自己教師あり)方式で世界モデルを学習し、そのモデルを用いて予測、推論、計画を行うことを可能にする学習パラダイムとアーキテクチャを考案することが、AIとMLの主要課題の1つであると考えられています。
本論文の一つの仮説は、動物も人間も前頭前野のどこかにたった一つの世界モデルエンジンを持っているという仮説です。
その世界モデル・エンジンは、目の前のタスクに合わせて動的に設定可能である。すべての状況に対して個別のモデルを持つのではなく、単一の設定可能な世界モデル・エンジンがあれば、世界の仕組みに関する知識がタスク間で共有されるかもしれないと考えられています。
そして、これにより、ある状況に対して設定されたモデルを別の状況に適用することで、類推による推論が可能になるかもしれない、と考えられています。
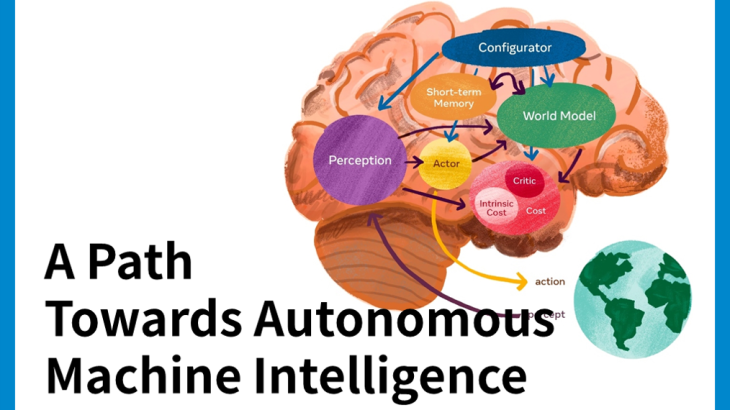
自律知能のためのモデル・アーキテクチャ
AIシステムが動物や人間のように学習し、推論するために、6つの個別のモジュールで構成されるアーキテクチャを提案。
各モジュールは微分可能であると仮定し、自身の入力に対する目的関数の勾配推定を容易に計算し、勾配情報を上流のモジュールに伝搬させることができるとしています。
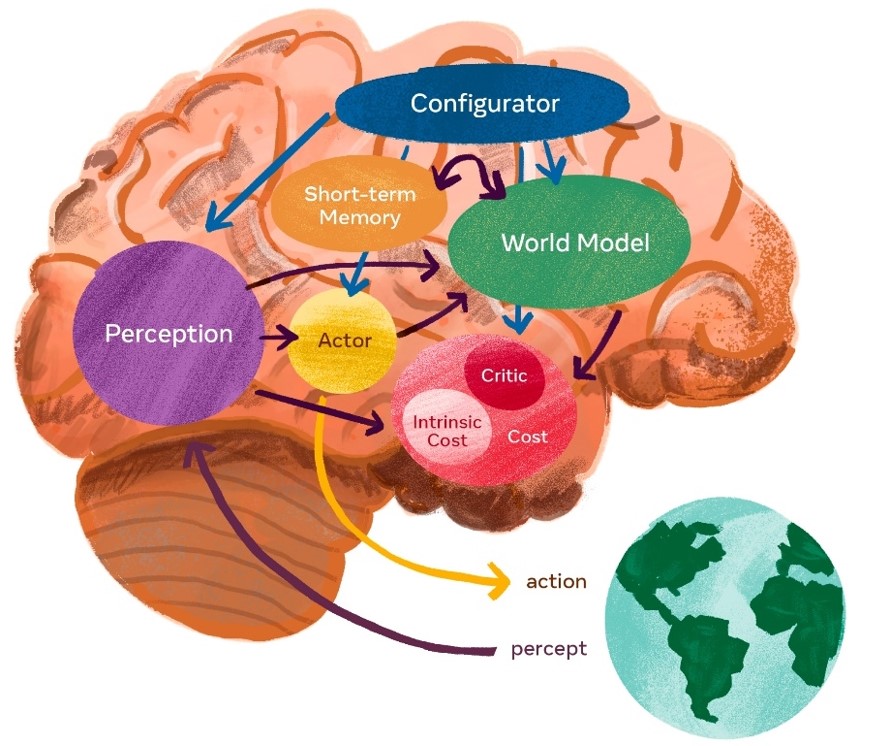
1.Configurator モジュール
実行制御を行うモジュール。実行すべきタスクが与えられると、知覚モジュール、世界モデル、コスト、およびActorを目前のタスクのために設定します。
2.Perception (知覚)モジュール
センサーから信号を受け取り、世界の現在の状態を推定を行う。あるタスクでは、知覚された世界の状態のごく一部だけが関連し、有用である。Configuratorモジュールは、目前のタスクに関連する情報を知覚モジュールから抽出します。
3.World Model モジュール
アーキテクチャの中で最も複雑な部分を構成。その役割は2つあります。
(1) 知覚によって世界の状態に関する不足情報を推定すること。
(2) 世界のもっともらしい将来の状態を予測すること。です。
世界モデルは、世界の自然な進化を予測したり、Actorモジュールが提案する一連のアクションの結果として将来の世界の状態を予測することができる。世界モデルは、タスクに関連する世界の部分の一種のシミュレ ータである。世界は不確実性に満ちているので、モデルは複数の可能な予測を表すことができなければなりません。
例)交差点に近づくドライバーは、交差点に近づく他の車が一時停止標識で止まらない場合に備えて、速度を落とすかもしれない。と予測します。
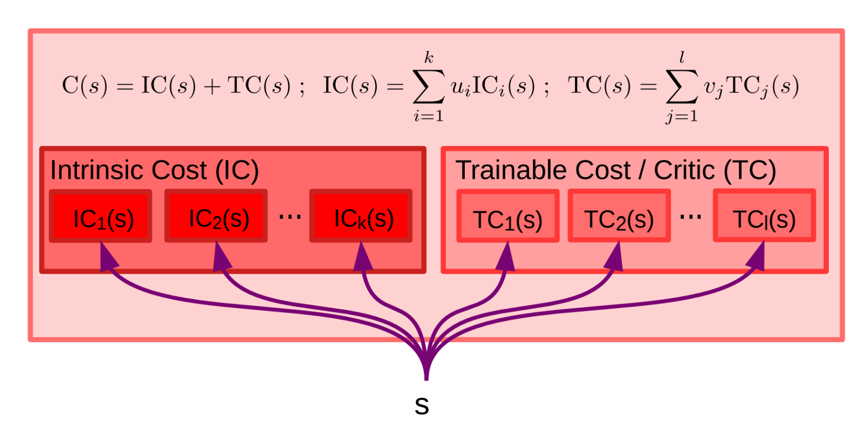
4.Cost モジュール
エージェントの「不快感」のレベルをエネルギーと呼ばれるスカラー量として測定します。エネルギーは、不変(訓練不可能)であり、即時の不快感(エージェントの損傷、ハードコードされた行動制約の違反など)を計算する固有コストモジュールと固有コストの将来の値を予測する訓練可能なCriticモジュールの和です。これらは、平均エネルギーを最小にするような状態に留まるように行動することを目的とし、コストモジュールは微分可能でることから、コストの勾配を他のモジュールに逆伝播して、計画、推論、学習を行うことができます。
5.Actor モジュール
一連の動作の提案を計算し、動作を出力する。Actorは、世界モデルに対して行動シーケンスを提案します。世界モデルは行動シーケンスから将来の世界状態シーケンスを予測し、コストに供給する。このとき、コストは提案された行動シーケンスに関連する将来の推定エネルギーを計算します。提案された行動シーケンスに関する推定コストの勾配にアクセスできるので、勾配に基づく方法を用いて推定コストを最小化する最適な行動シーケンスを計算することができます。
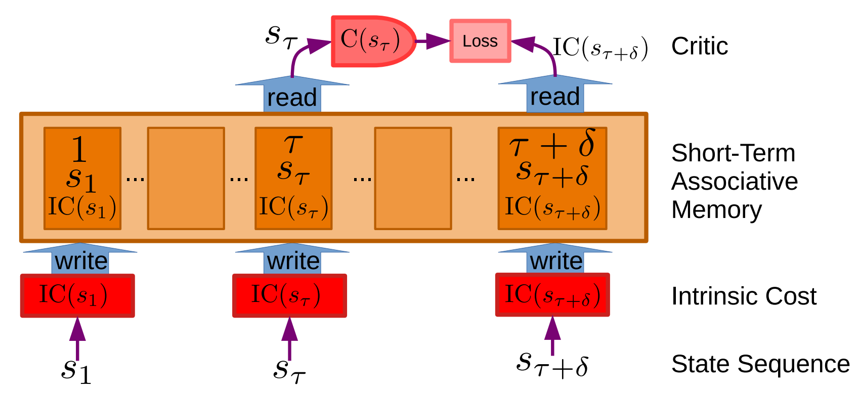
6.Short-term Memory モジュール
世界の過去、現在、未来の状態に関する関連情報と、それに対応する固有コストの値が格納されます。世界モデルは、将来(または過去)の状態を時間的に予測しながら、また、現在の世界の状態について欠落した情報を空間的に補完したり矛盾した情報を修正しながら、短期記憶にアクセスし更新する。世界モデルは短期記憶にクエリーを送り、取り出された値を受信したり、状態の新しい値を保存したりすることができます。
World model の設計と育成
典型的な知覚-行動ループ
知覚-行動ループを行うにあたり、センサからの入力情報を基に世界の現在の状態を推定を行う知覚モジュールと一連の動作の提案を計算し動作を出力するActorモジュールを用います。そしてこれらは、2つのモードによって動かすことができると考えられます。
モード1:反応行動
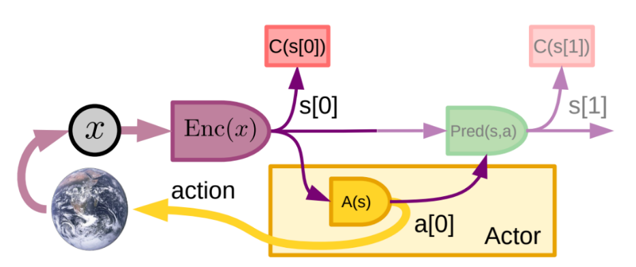
これは、複雑な推論を伴わず、知覚の出力と可能な限りの短期記憶モジュールから直接行動を起こすものです。そして、Kahnemanの「システム1」との類似性から、これを「モード1」と呼びます。
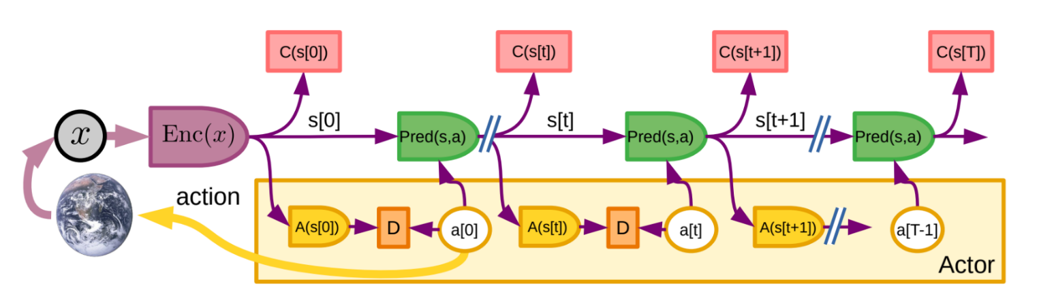
知覚モジュールは、エンコーダを介して、タスクに関連する情報を含む世界の表現 s[0] = Enc(x)を抽出します。F[0]の= C(s[0])とし、s[0],f(0)の短期メモリに格納します。Actorのコンポーネントであるポリシーモジュールは、状態の関数としてアクションを生成します。a[0] = A(s[0]),a[0])と関連するエネルギーf[0]=C(s[0])を用いて次の状態を予測します。取られた行動の結果として次の観測が利用可能になった時点で、世界モデルを調整すること可能になります。
世界モデルを用いることで、エージェントは行動のコースを想像し、その効果や結果を予測することができます。これにより、外界で複数の行動を試し、その結果を測定することができます。
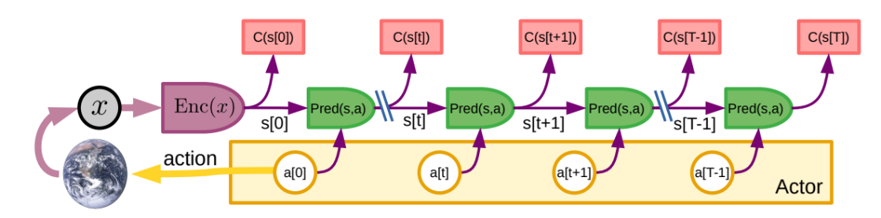
モード2:世界モデルを使った推論と計画
これは、世界モデルとコストを通じて推論と計画を行うものです。そして、Kahnemanの「システム2」になぞらえて「モード2」と呼びます。ここでいう「推論」とは、エネルギー最小化を意味する広義の言葉として使用します。
知覚モジュールは世界の状態をs[0]を推定します。Actorは一連の行動 a[0],a[1],…a[t],a[t+1],…a[T]を提案します。世界モデルはs[t+1] = Pred(s[t],a[t])を用いて、世界の状態の推定値を再帰的に予測します.コストC(s[t])は予測された各状態のエネルギーを計算し、それらの合計を総エネルギーとします。
最適化または探索手順により、Actorは総エネルギーを最小化するアクションのシーケンスを推論する。そして、そのシーケンス内の最初のアクションをエフェクタに送信します。コストとモデルは微分可能なので、勾配に基づく方法を用いて最適な行動シーケンスを探索することができます。状態と固有コストと学習可能なCriticから対応するエネルギーの組は、その後のCriticの訓練のために短期メモリに保存されます。
「モード2」から「モード1」へ:新しいスキルの習得
モード2 の仕様は、負担が大きい。エージェントは1つの世界モデルしか持っておらず、一度に一つのタスクにしか使用することができません。( 図にモード2の最適化の結果得られる行動を近似的に実現するためのポリシーモジュールA(s[t])の学習方法を示します。)
システムは、まずモード2 で動作し、最適な一連の動作()を生成します。次に、最適な行動とポリシーモジュールの出力との間の発散 D(a[t]),A(s[t])を最小にするようにポリシーモジュールのパラメータが調整されます。一旦訓練されると、ポリシーモジュールはモード1における行動 a ~[0] = A(s[0])を直接生成するために使用することできます。また、モード2最適化の前に、初期行動を再帰的に計測することもできます。
s[t+1] = Pred(s[t],a[t]); a~[t+1] = A(s[t+1])
この結果、ポリシーモジュールは、償却推論を行い、良いアクションシーケンスの近似を生成します。このポリシーモジュールは、モード1において反応的に行動を生成したり、モード2の推論の前に行動列を初期化し、最適化を促進するために用いることができます。このプロセスにより、エージェントはその世界モデルと推論能力をフルに活用して新しいスキルを獲得し、それを「コンパイル」して、慎重な計画を必要としない反応的なポリシーモジュールとすることができます。
行動の原動力となるコストモジュール
コストモジュールは、不変IC(s)と、Critcまた訓練可能なコストTC(s)から構成されます。ICとITは共に複数のサブモジュールはその出力は線形に合成されます。線形結合の重み(ui)と(vj)はConfiguratorモジュールによって決定されます。これにより、エージェントが異なるサブゴールに集中することを可能にします。
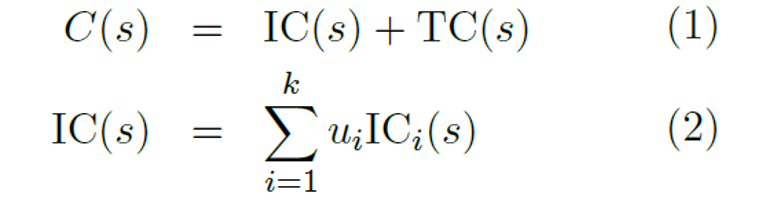
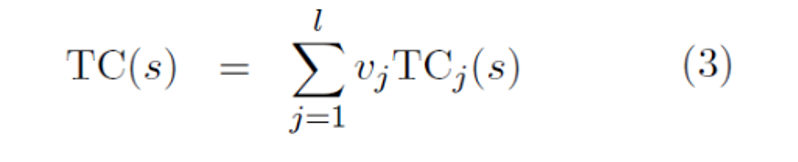
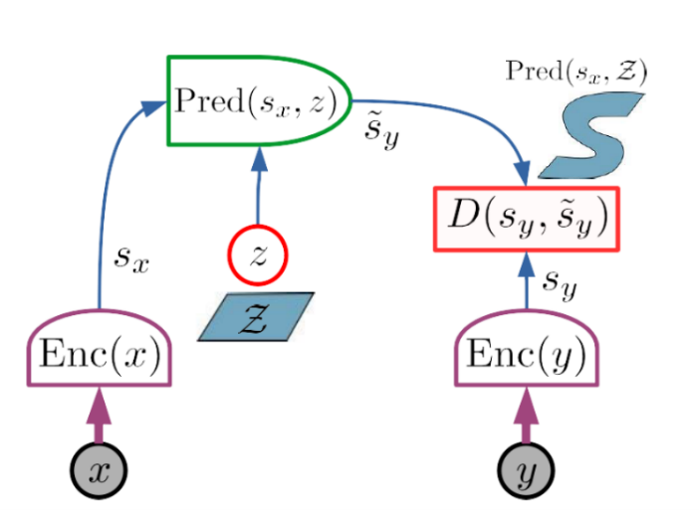
Joint-Embedding Predictive Architecture (JEPA)
2つのエンコーディングブランチから構成される。最初のブランチは 𝑥 の表現である 𝑠𝑥 を計算し、2 番目のブランチは 𝑦 の表現である 𝑠𝑦 を計算します。𝑥 から yの予測を明示的に生成することなく 𝑥 と 𝑦 の依存関係を捉えます。
予測器モジュールは、潜在変数 𝑧 の入力を受け、𝑠𝑥 から 𝑠𝑦 を予測します。2 つのエンコーダーは異なっていて良く、同じアーキテクチャである必要はありません。パラメータを共有する必要もありません。このため、𝑥 と 𝑦 は異なる性質を持つことができます。(例: ビデオとオーディオ)。
予測器モジュールは 𝑥 の表現から 𝑦 の表現を予測する。予測器は潜在的な変数 𝑧 に依存することがあります。
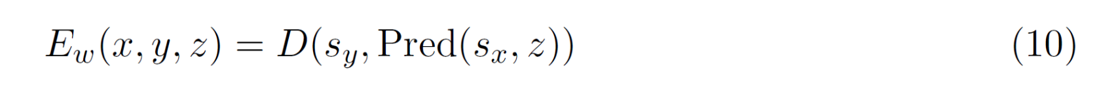
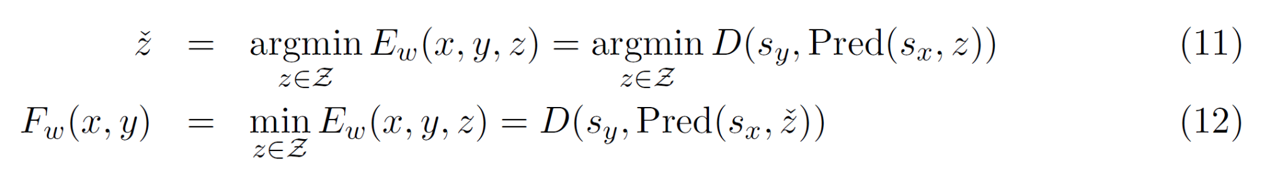
JEPAの主な利点
エンコーダーによって表現空間で予測を行い、𝑦 のすべての詳細を予測する必要をなくし、無関係な詳細を除去できます。
①エンコーダ関数 𝑠𝑦=𝐸𝑛𝑐(𝑦) は、異なる 𝑦 の集合に対して同じ 𝑠𝑦 を生成させる不変性を持たせることを期待している。
②潜在変数 𝑧 は、集合𝑍上で変化させたとき、もっともらしい予測の集合を生成することができます。
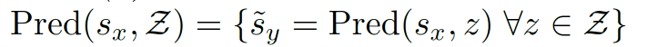
𝒙, 𝒚, 𝒔𝒙, 𝒔𝒚, 𝒛 の具体例
𝑥が分かれ道に差し掛かった車の映像の場合、𝑠𝑥、𝑠𝑦は、分岐前と分岐後の車の位置、姿勢、速度などの特性をそれぞれ表し、道路に接する木や歩道の質感などの無関係な部分は無視されます。z は、道路左側の分岐を進むか、右側の分岐を進むかを表します。
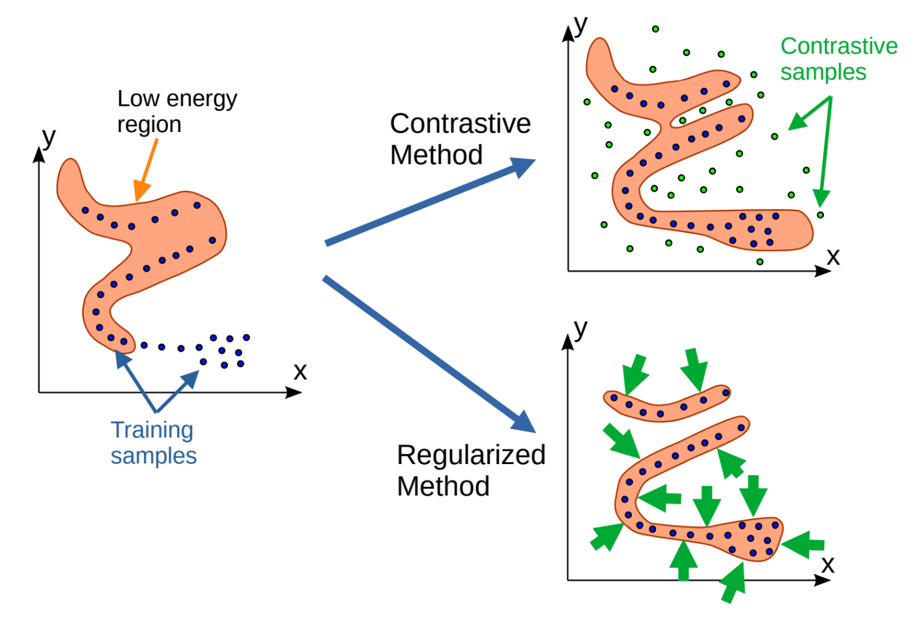
エネルギーベースモデル(EBM)のトレーニング
対照法
・学習サンプルのエネルギー(青い点)を押し下げ、適切に配置された対照サンプルのエネルギー(緑の点)を引き上げます。
・対照法は、対照サンプルが置かれた場所でのみエネルギーが引き上げられます。対照サンプルの数が、𝑦空間の次元に比例して指数関数的に増加することが欠点です。
正則化法(非対照法)
・学習サンプルのエネルギーを押し下げ、低エネルギー領域の体積を最小化するような正則化項を使用します。この正則化は、エネルギー関数の柔軟性が許す範囲で、データ密度の高い領域を低エネルギー領域内に「収縮」させる効果があります。
EBMトレーニングのための対照法と正則化法
※学習サンプルは青い点。エネルギーの低い領域はオレンジ色で表されています。
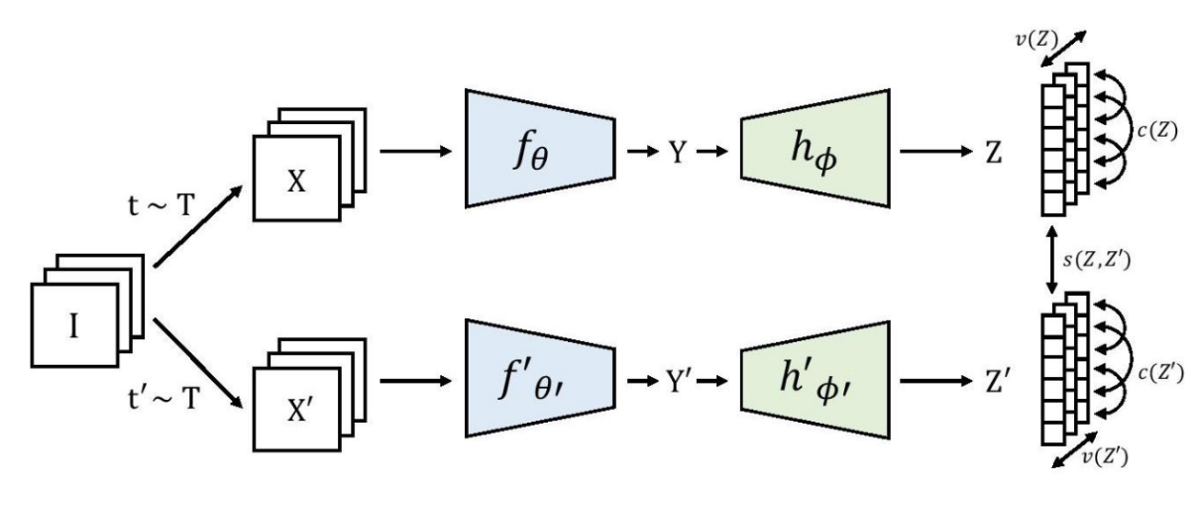
VICReg(Bardes et al., 2021)
(Variance-Invariance-Covariance Regularization For Self-Supervised Learning)
分散、不変性、共分散正則化を用いたJoint-Embedding Architectures。画像 I のバッチが与えられると、異なるビュー X と X’ の2つのバッチが生成され、表現 Y と Y’ に符号化されます。同じ画像からの2つの埋め込み間の距離は最小化され、バッチ中の各埋め込み変数の分散は閾値以上に維持され、バッチ中の埋め込み変数のペア間の共分散は0に引き寄せられ、互いの変数が非相関化される。2つのブランチは同一のアーキテクチャを必要とせず、重みも共有しません。
各次元に沿った埋め込み値の分散に対する単純な正則化項により、崩壊問題を回避します。

JEPA の学習
JEPAは、正則化法(非対照法)を工夫して学習させます。(対照法は高次元では非効率になる傾向があります。)
JEPA の場合、以下の4 つの基準によって行うことができます。
① – I(𝑠𝑥)の最大化 : 𝑥 に関する 𝑠𝑥 の情報量を最大化します。
② – I(𝑠𝑦)の最大化 : 𝑠𝑦 の 𝑦 に関する情報量を最大化します。
③ D( 𝑠𝑦, 𝑠𝑦 ) の誤差の最小化 : 𝑠𝑦 から容易に予測できるようにします。
④ R(z)の最小化 : 予測に用いる潜在変数 𝑧 の情報量を最小化します。
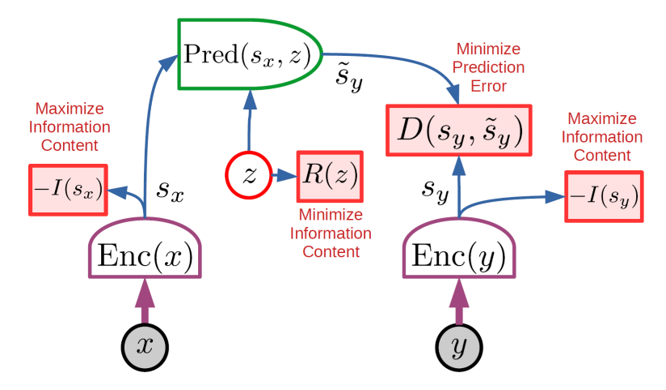
①、②は、情報的な経過によってエネルギー表面が平坦になることを防ぎます。
③は、エネルギー項 𝐷( 𝑠𝑦, 𝑠 ̃𝑦 )によって強制し、𝑦 が以下のものから予測可能であることを保証する。 𝑥 を表現空間に配置します。
④は、潜在能力からの助けをできるだけ借りずに 𝑠𝑦 を予測するようモデルに強制することで、システムが別のタイプの情報の欠落の犠牲になるのを防ぎます。
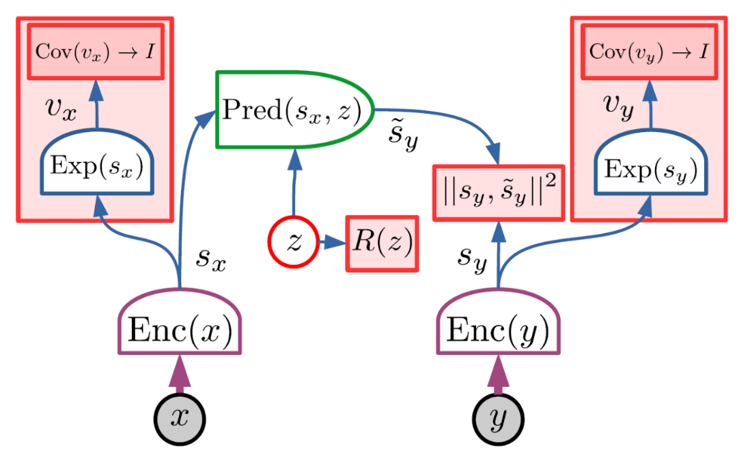
VICReg を用いた JEPAの学習
① 𝑣𝑥=𝐸𝑥𝑝(𝑠𝑥) Conv(𝑣𝑥) → I
② 𝑣𝑦=𝐸𝑥𝑝(𝑠𝑦) Conv(𝑣𝑦) → I
③ 表現予測誤差 𝐷( 𝑠𝑦, 𝑠 ̃𝑦) の最小化
④ 𝐷( 𝑠𝑦, 𝑠 ̃𝑦 )= 𝐷( 𝑠𝑦, 𝑠𝑥 ) = ‖ 𝑠𝑦 − 𝑠𝑥 ‖^2 の最小化
𝑠𝑥 と 𝑠𝑦 は、拡張器( 𝐸𝑥𝑝() )を通して高次元の埋め込み 𝑣𝑥 と 𝑣𝑦 にマッピングすることで最大化します。サンプルのバッチ上で計算された2つの微分可能な損失項を持つ損失関数を使うことで、埋め込みの共分散行列を恒等式に向かわせます。
階層型JEPA (H-JEPA)
JEPA はエンコーダーを訓練して、入力の無関係な細部を排除し、表現をより予測可能なものにできます。抽象的な表現を学習できるため、階層的な積み重ねが可能である。JEPA-1が低レベルの表現を抽出し、短期予測を行います。
JEPA-2は、JEPA-1が抽出した表現を入力とし、より長期的な予測が可能な高次の表現を抽出する。より抽象的な表現は、長期予測が困難な入力の詳細を無視し、より粗い世界の状態の記述で長期予測を行うことができます。
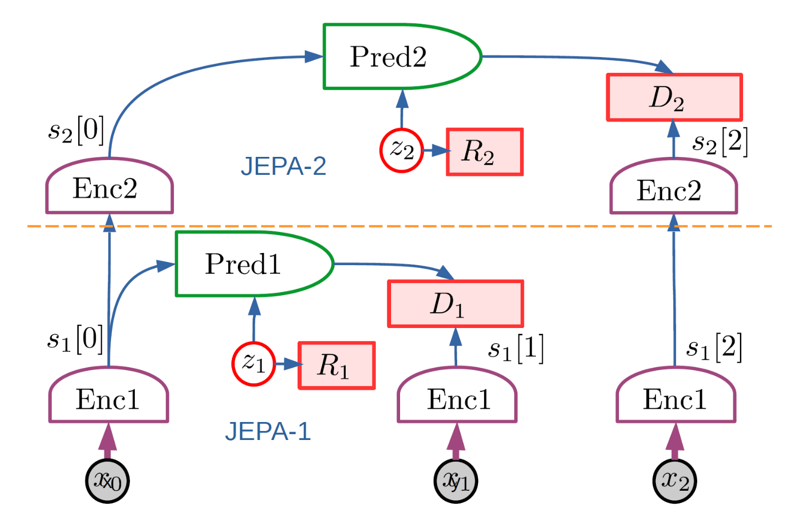
具体例
短期予測:数秒間にハンドルやペダルを操作する一連の動作です。
→同じ時間内の自分の車の軌跡を正確に予測することができます。
長期予測:他の車や信号機、歩行者などの予測不可能な外的要因に左右されます。
→より長い時間の軌跡を予測することは困難です。しかし、高い抽象度であれば正確な予測をすることができます。
階層的プランニング
マルチスケール世界モデルの階層性を利用した階層的なモード2をプランニングするためのアーキテクチャです。知覚は、エンコーダーのカスケードによって、複数の抽象化されたレベルの表現にコード化されます。
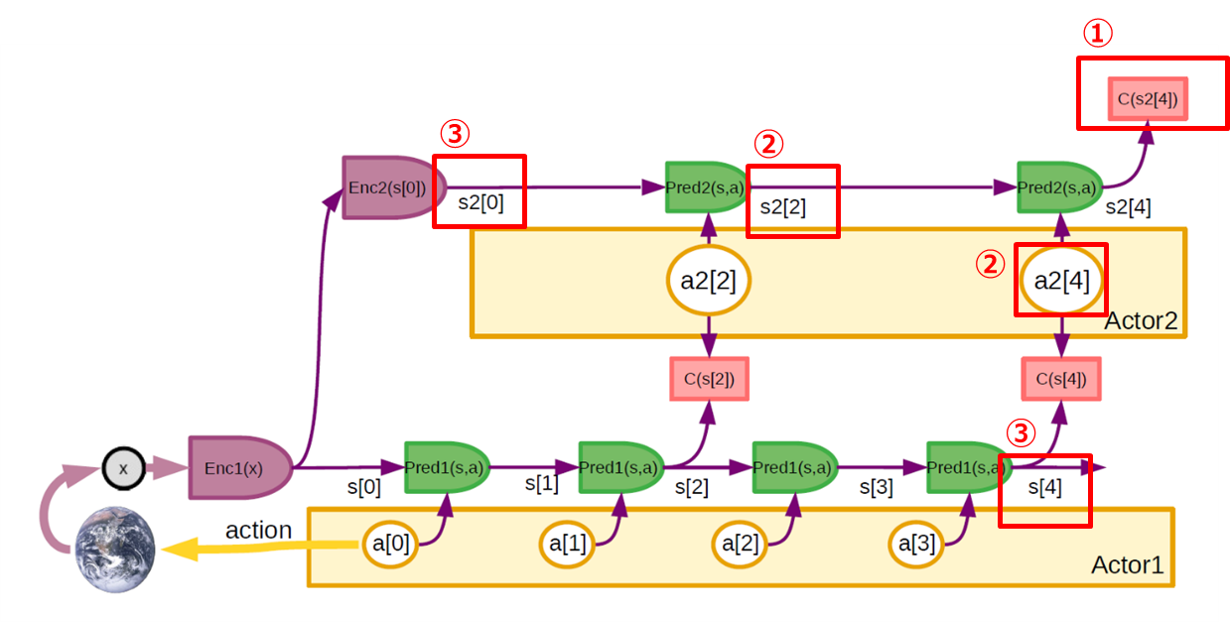
①複雑なタスクは、高レベルの世界状態表現 𝐶(𝑠2[4])から計算される高レベルのコストで定義されます。
②𝐶(𝑠2[4])を最小化する高レベルの抽象アクション(𝑎2[2], 𝑎2[4])のシーケンスが推論されます。
③推論された抽象アクションは、下位層のサブゴールを定義する下位コストモジュール 𝐶(𝑠[2]), 𝐶(𝑠[4]) に供給されます。
そして、下位層はサブゴールコストを最小化する行動シーケンスを推論する。※ここでは2層しか示していませんが、多層も同様です。
不確実性への対応
現実的な環境は、高度に抽象化された表現を用いても、完全に予測できるわけではありません。予測に関する不確実性は、潜在変数を持つ予測変数で処理することができます。
潜在変数(赤丸)には、事前観測から得られない予測に関する情報が含まれています。潜在変数は、エネルギー崩壊を防ぎ、その助けなしに可能な限り予測するようにシステムを強制するために、正則化されなければなりません。(R1、R2は、潜在変数に対する正則化)
計画時には、正則化にギブス分散を適用した分布から潜在変数をサンプリングします。各サンプルはそれぞれ異なる予測につながります。一貫性のある潜在的な配列を生成するために、正則化器のパラメータは以前の状態や検索された記憶の関数とすることができます。
各潜在変数がk個の可能な離散値を持つ場合、可能な軌道の数は𝑘_𝑡 、ここで𝑡は時間ステップの数として成長します。このような場合、直接探索と枝刈り戦略を採用しなければなりません。複数の予測軌道があれば、平均コスト、あるいはリスクを最小化するためにコストの平均と分散の組み合わせを最小化する最適な行動シーケンスを計算することができます。
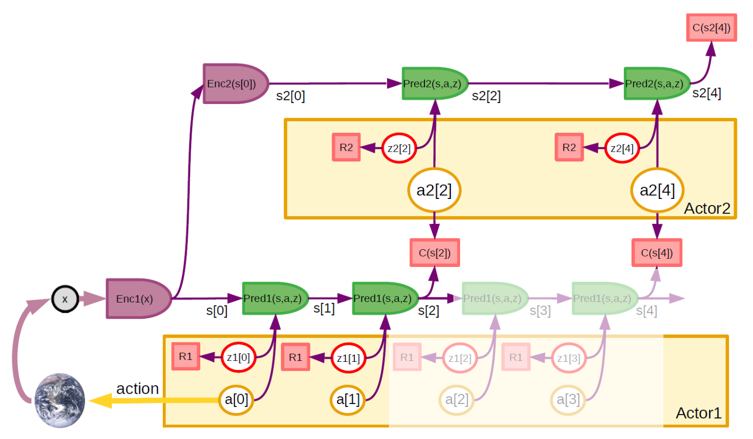
Actor の設計と育成
アクターモジュールの役割は、3つです。
1. 世界モデルによるMode-2行動の予測から、コストを最小化する最適な行動系列を推論します。
2. エージェントが知らない世界の状態の部分を表す潜在的な変数の複数の構成を生成します。
3. モード1アクションを生成するためのトレーニングポリシーネットワーク。
Actionと潜在的な変数の間に概念的な違いはありません。
両方の変数セットの構成は、Actorによって探索されなければなりません。
潜在変数については、不確実性の下で計画するために、構成を探索しなければなりません。行動変数については、コストを最小化する最適なものを生成するために、構成を探索しなければなりません。敵対的なシナリオ(ゲームなど)では、コストを最大化する潜在的な構成を探索しなければなりません。事実上、アクターは、最適化と探索の両役割を果たします。
世界モデルとコストが良好に振る舞うとき、アクターモジュールは勾配に基づく最適化処理を用いて最適な行動シーケンスを推論することができます。そのために、コストと展開された世界モデルを通して勾配を逆伝播することによって計算されたコストの勾配の推定値を受信します。そして、その推定値を用いて行動シーケンスを更新します。
Configurator の設計
コンフィギュレータは、エージェントのメインコントローラです。他のすべてのモジュールから入力を受け、そのパラメータと接続グラフを調整します。
変調は、信号をルーティングしたり、サブネットワークを活性化したり、注意を集中させたりすることができます。予測器と知覚エンコーダの上位層がトランスフォーマーブロックであるシナリオでは、コンフィギュレータの出力はこれらのトランスフォーマーブロックへの追加入力トークンであり、それによってそれらの接続グラフと機能を変更することができます。
コンフィギュレータモジュールの利点
ハードウェアの再利用と知識の共有ができること。
(ある環境に対して学習させた世界モデルは、わずかな変更でさまざまなタスクに利用できる。)
コンフィギュレータモジュールの欠点
エージェントが一度に一つのタスクしか達成できないこと。
コンフィギュレータの最も重要な機能は、エージェントにサブゴールを設定し、このサブゴールのためのコストモジュールを設定することです。コストを設定可能にする簡単な方法は、初歩的なコストサブモジュールの線形結合の重みを変調することです。これに対して、より洗練されたアーキテクチャでは、コストのTrainable Critic部分を柔軟に変調させることができると想像されます。
予測器と同様に、高レベルのコストがオブジェクト間の望ましい関係のセットとして定式化されている場合(例:ナットはネジにセットされているか?)、世界の状態が満たされるべき条件からどの程度乖離しているかを測定するように訓練された変換器アーキテクチャを使用することができます。予測器と同様に、トークン入力を追加して関数を調節することができます。
考察・まとめ
関連研究
本論文で紹介されているアイデアのほとんどは新しいものではなく、認知科学、神経科学、最適制御、ロボット工学、AI、機械学習、特に強化学習において様々な形で長く議論されてきたものである。と述べられています。
特に結びつきの強い研究
・学習済みWorld Model
・モデル予測制御
・階層的Planning
・エネルギーベースモデル(EBM)
・Joint-Embedding Architectures
・ヒトと動物の認知
提案モデルに欠けているもの
動画から階層型JEPAを構築し、学習させることができるのか、という問題です。
提案されたアプローチの広範な妥当性
Q.動物の知能モデルの基礎になりうるか?
提案するアーキテクチャは、単一の世界モデルエンジンを持ち、コンフィギュレータによって手元のタスクに合わせて設定することができる。
もし、脳が独立した設定不可能な世界モデルを多数含むほど大きければ、コンフィギュレータは不要となり、意識の錯覚はなくなると考えられる。と述べられていました。
Q. 機械が常識を獲得する道となり得るか?
世界観測のセルフコンシステント(求めるべき解が自分自身を含むような問題)と相互依存性を捉えた世界モデルを学習することで、エージェントが情報の欠落を補い、世界モデルの違反を検出することで、常識が生まれるのではないかと推測している。と述べられていました。
Q.スケーリングが全てなのか?報酬は本当に十分か?
スケーリングだけでは不十分です。現在のモデルは非常に限定的な推論しかできない。と述べられていました。
Q. 推論に記号は必要なのか?
勾配に基づく探索方法が勾配を用いない探索方法よりも効率的であることから、世界モデルの学習手順が、計画・推論問題が離散問題を構成する階層的な表現を見つける方法を見つけたい。ここで提案された推論が、人間や動物が持つすべての推論を網羅できるかどうかはわからない。 と述べられていました。
感想
・人工知能を実現する一つのシナリオとして、全体をとりまとめている様子が面白いと感じました。