
はじめに
最近(2020年7月)話題のOpenAIが発表したGPT-3(Generative Pretrained Transformer‐3)についてご紹介します。
発表論文
Language Models are Few-Shot Learners
https://arxiv.org/abs/2005.14165
GPT-3概要
GPT-3とは
・OpenAIが作成した文章生成言語モデル。
・特徴は圧倒的スケールであり、1750億個ものパラメータがある。(2019年発表のGPT-2で15億個)
・結果としてタスクごとの学習を必要としない「ゼロショット」または少しのサンプルだけでよい「小数ショット」で様々なタスクに精度よく対応することができるようになった。
⇒文章だけでなく、ウェブページやUI画面、アルゴリズムを手軽につくることができる。
・一方でスケールアップの限界も明らかになった。
・生成される文章のなかには人種差別や誹謗中傷などの発言があり、改めて精査することが難しい大量のネットデータから学習することの問題点が浮き彫りになった。
・一般には公開されておらず、APIによる利用に限定されている。
※API限定利用について
近年、AIの技術は一般的にはオープンソースとして公開されることが多いですが、GPT-3はマイクロソフトのクラウドプラットフォームAzureからOpenAIによって許可された利用者のみAPI経由で利用できます。これはOpenAIが、GPT-3について①フェイクニュースを簡単に作ることができるなど悪用される危険性があると判断し、また②今後の研究開発のための資金調達源として商業利用することを決定したためです。
GPT-3の評価
GPT-3は当初、多くの人からGPT-2をスケール面で改良しただけのモデルとして受け止められており、そこまで注目度が高かったわけではありません。しかし、普通の言語生成だけでなくプログラミングのようなことが簡単にできるということが一部の利用者から報告され、そこに投資家が反応したことで爆発的に注目されるようになったということのようです。つまり、技術的な革新性からの評価が高いというよりは、単純な性能の向上によりそれまでできなかったことがいろいろできるようになったことがシンプルに多くの人々を引き付けているといえます。イメージとしてはGPT-3は膨大なテキスト(インターネット上から収集)から、何百万、何千万というテキストの断片をつくり、それらを集めた巨大なスクラップブックのようなものを所持し、要求に応じてそこから適切に切り出すような作業をしているのですが、そのスクラップブックの量と質が向上したことでそれまでできなかったことができるようになり、評価されるようになったということです。(実際には受け取ったテキスト入力に対して、膨大なデータから統計的にもっともらしい応答を生成しています。)さらにGPT-3はほんの少しのサンプルを加えることで新たなタスクにも対応することができるようになるため、言語モデルのなかでもかなり完成度の高い汎用モデルのように一部の人からは認知されています。
具体的には以下のようなことができたことが確認されています。
・WEB用のパーツを話し言葉でデザイン・生成
・架空のタイトルとアーティストから音楽を作曲(ギターのタブ譜を生成)
・ビジネスアイデアを生成
・昔話を大量に生成
・検索エンジンを作成(質問をすると対応するURLを返す)
特に実際の開発風景として、シャリフ・シャミーム氏がGoogleの検索画面をつくる様子などは有名です。(簡単な指示であっという間にみなれた画面がつくられていく様子は多くの人々に驚きをもたらしました。)
https://twitter.com/sharifshameem?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1282676454690451457%7Ctwgr%5E&ref_url=https%3A%2F%2Fwww.technologyreview.jp%2Fs%2F213942%2Fopenais-new-language-generator-gpt-3-is-shockingly-good-and-completely-mindless%2F
ただし、もちろん、課題も指摘されています。
GPT-3の課題
GPT-3に対しては、一方ですでに各方面から問題点が指摘されています。ここでは特に詳しい研究者のMax Woolf氏の指摘をもとに、簡単に問題点を列挙したいとおもいます。(Max Woolf氏のブログ:https://minimaxir.com/2020/07/gpt3-expectations/)
①生成速度がとても遅い
OpenAI APIの利用者の報告によると、GPT-3は1分間におよそ150単語しか生成しないとされています。(これは機械翻訳ライブラリと比較すると2000倍近く遅いとされます)そのため修正することにも大きな時間がかかるため、ユーザー体験は著しく損なわれると考えられます。
②よい結果を必ず生成するわけではない
他モデルよりは優れているとはいえ、それでも生成の成功率は30~40%であるということは、逆に言えば60~70%は失敗することを意味しています。たとえば、使用可能なReactコンポーネントの生成には平均して3試行かかってしまいます。
③OpenAI APIの利用者は全員同じGPT-3を使用するため、競争優位性が生まれない。
全員がおなじAPIを利用するということは、結果も同じということを意味します。また、プロンプトはリバースエンジニアリングされる可能性をもっており、利用を促進する要素が少なくなっています。(ただし、OpenAIのCTOが微調整機能を追加することを示唆しています。)
④人種差別や誹謗中傷の発言が存在する。
ウェブ上にある誹謗中傷やヘイトスピーチなどの有害なバイアスをも学習してしまっているため、不適切な発言をしてしまう可能性あり、利用するためにはそのことへの対応が必要とされています。ドメインによってその度合いは異なるものの、利用する際には多くの調整が求められる可能性が高いため、精度とコストのバランスのなかで判断されることになると考えられます。
⑤OpenAIの動向に左右される。
APIによる利用のため、OpenAIの動向にあわせて利用することを求められるようになっています。また、現在のAPIの利用料は無料ですが、リリース版は有料化されることが決定しています。FP16でも16GBメモリのGPUを22枚必要とするモデルサイズを考えると利用料は安くないことが想定されます。
⑥汎用モデルに近いといえどもどんなことにでも対応できるわけではない。
簡単な文章の応答や、翻訳やプログラミングなど、指示と答えがある程度1対1対応のものに関してはかなり高い精度を示している一方で、答えがないもののや複雑なステップをふまないと答えを導き出せないものに関しては不得意であるとされています。
チューリングテストの結果
海外ではGPT-3に対してチューリングテストを行ってみたという報告もあります。(Giving GPT-3 a Turing Test:https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html)
チューリングテストとは、20世紀前半に活躍した数学者アラン・チューリングが提唱したもので、質問に対する応答から相手が人間か、コンピュータかを判定するというテストです。質問者である人間が応答から両者を区別することができなくなった場合、コンピュータが人間のレベルに達したといえるのではないかというものです。
今回のテストでは、GPT-3は普通の会話では違和感なく答えることができ、従来では難しいとされていた常識問題にも答えることができたとされています。(ただし、論文のなかでは「チーズを冷蔵庫にいれたら溶けるのか」など、普通に質問されることはないような物理的常識問題に答えることはできなかったことが指摘されています。)特に雑学問題に対してはほとんど間違えることなく回答することができたと報告しています。一方で、答えがない問題(アメリカが存在しない年代のアメリカ大統領を問う問題)やあいまいな答えを要求される問題に対して、「わからない」や「問題が誤っている」というような反応ができず、勝手に創造した答えを答えてしまうという問題点もわかったそうです。また簡単な引き算のような問題(100万引く1は?)なども間違ってしまうことが明らかにされています。ほかにも短期記憶の問題(箱の中に靴が2足あります。この箱に鉛筆1本を入れて靴1足を取り出した場合、箱の中には何がありますか?)などが解けないことも指摘されており、結論からいえばチューリングテストを合格するほどとはいえないのではないかということです。
GPT-3詳細解説:これまでのモデルとはなにが違うのか?
これまでのモデルの歴史
ここ10年間で、ディープニューラルネットワーク(DNN)は自然言語処理(NLP)の分野で一般的になりました。(以前は統計的知識をもとにした機械学習モデルが主流でしたが、初期のGoogle翻訳のようにDNN以前のNLPはあまりパフォーマンスがよくありませんでした。)2010年代から、NLPの研究者たちはDNNを全面的に採用しました。
最初の重要な革新は、DNNを使用して単語ベクトル表現を生成することです。機械学習アルゴリズムで単語自体を使用する代わりに、単語を数学的なベクトルとして表すという考え方からきています。(Word2vecの論文は2013年に発表されました。)Wordをベクトル表現することで、単語の関係性を利用しやすくなりました。有名なものとして、パリーフランス+イタリア=ローマなどです。)
次に重要な革新は、文を「読み取る」ためのリカレントニューラルネットワーク(RNN)の使用です。RNNには、任意の長い単語シーケンスを供給できるという利点があり、文章の一貫性を維持できます。(Seq2seq論文は2014年に発表されました。)2016年には、Googleは以前の統計的機械翻訳(SMT)エンジンから新しいニューラル機械翻訳(NMT)エンジンに切り替えました。ただし、RNNにもあまりに長い依存関係を反映できないなど、多くの問題がありました。
最も新しい革新的な出来事は、文章内の単語や文章同士の関係性を利用するトランスフォーマーモデルの利用です。(Transformer論文は2017年に発表されました。この論文に関する詳しい記事も書きましたので、よろしければご参照ください。「自然言語処理の必須知識 Transformer を徹底解説!:https://deepsquare.jp//2020/07/transformer/」)トランスフォーマーを利用するアーキテクチャは、より深いニューラルネットワークの作成を可能にしました。コンピュータビジョンでは、より深いDNNがより豊かな抽象を作成できることがすでに示されていました。より深いネットワークに拡張できるトランスフォーマーの能力のおかげで、多くの研究チームがこれまでにない大きなモデルを公開し始めました。GoogleのBERTベースには1億1千万のパラメーターがあります。(BERT-largeは、公開時に多くのパフォーマンスレコードを破りましたが、なんと3億4,000万のパラメータを持っています。SalesforceのCTRLは、16億もの巨大なパラメーターをもつモデルです。)
これらのモデルのほとんどは、自己相関言語モデルであり、文が与えられると、ランダムな単語(またはトークン)が「マスク」された文の次の単語(またはマスクモデル)を予測しようとし、予測しようとします。この「マスクされたトークンがどうあるべきか。」というアプローチは、教師なし学習に適していました。モデルは人間が作成したラベルを必要とせず、任意のテキストから学ぶことができます。これは、膨大なデータのコーパス、またはインターネット全体でのトレーニングへの扉を開きました。
トランスフォーマーモデルはNLP研究の世界を大きく変えました。たとえば、BERTは、高性能TPUのクラスターを使用して、かなりのテキストコーパス(ほとんどのWikipedia、およびいくつかの追加コーパス)についてGoogleによって事前トレーニングされています。その後、事前にトレーニングされたモデルをタスク固有のパイプラインに組み込むことができます。これは、word2vecとGloVeが使用され、より小さなトレーニングセットで微調整された方法とほぼ同じです。
ただし、トランスフォーマーモデルにも欠点があり、それはコストがかかることです。トレーニング速度が大変遅く、多くのパラメーターがある場合にはより一層遅くなります。そのためトランスフォーマーモデルを利用する研究者は、最先端のインフラストラクチャに大量のクラウドコンピューティング能力を必要とします。このことが意味することは、現在のNLPの世界で新しいモデルを提案できるのは、世界でも最大かつ最も資金のあるチームだけということです。ダウンストリームタスクと微調整であっても、トレーニングには1000または10,000のサンプルとGPUを備えた強力なコンピューターが必要とされます。そのような状況では、最小のバグですら非常にコストがかかる可能性があり、学習を複数回繰り返すことはすぐに非常にコストがかかることに直結します。
このような前提のもと、NLPモデルとしてGPTシリーズがOpenAIから発表されてきました。そして、今回2020年にGPT-3が発表されるに至りました。
GPTシリーズとは
前項の説明でもわかるように近年のNLP分野では、単純なスケールアップ(データサイズ・モデルサイズ・訓練時間を同時に上げる)によってパフォーマンスを改善するという方法が非常にうまく機能しています。更にそのうえで、今年の初め、OpenAIはTransformerモデルについて「スケーリングの法則」を提唱する論文(Scaling Laws for Neural Language Models:https://arxiv.org/pdf/2001.08361.pdf)を発表しています。いくつかの異なるTransformerベースのモデルの性能データに基づいて、OpenAIは、モデルの性能(この場合、テストデータセットでの交差エントロピー誤差を性能としています。)は、モデルパラメータの数、データセットのサイズ、トレーニングに使用される計算量と力の法則的な関係があると結論づけています。つまり、これら3つの変数のいずれかを増やすことで、性能が向上するということです。(今回のGPT-3はそれを忠実に体現したといえます。)なお今回のGPT-3もこのようなスケールアップさせるトランスフォーマーモデルの潮流にあるものであり、性能は大幅に向上していますが技術的にはTransformerが提唱されたときのような画期的なイノベーションを提案しているとまではいえません。もちろん細かい工夫などで新たに評価される点もありますが、従来モデルと最も重要な違いはそのスケールといえるとおもいます。
はじめのGPTには、BERTベースと同じ1億1千万のパラメーターがありました。そこから昨年発表されたGPT-2は、さらに大幅に増加させ、最大で16億個のパラメーターを備えていました。GPT-2モデルは、まとまりのあるテキストを生成するのに非常に優れていたため、OpenAIは当初、オープンソースにすることを拒否したことで有名です。GPT-2はWeb上の様々なドメインの文章を事前学習することで、与えたコンテキストに沿ってあらゆる文章を生成することができます。これは従来のように質疑応答や翻訳などの特定のデータセットで学習するのではなく、Web上の大量の未分類の文章で「次に来る文章」の予測を事前学習させている点に特徴があります。GPT-2では、特別な訓練をせずに質疑応答や翻訳といった個別のタスクを遂行することが可能になるほど、後続する文章の予測精度が上がりました。これを「ゼロショット」といいます。GPT-2では個別のデータセットで学習せずに読解・翻訳・文章要約・質疑応答など様々なタスクを実行できるということを意味します。この特徴を引継ぎ、さらに性能を高めたのが、GPT-3となります。
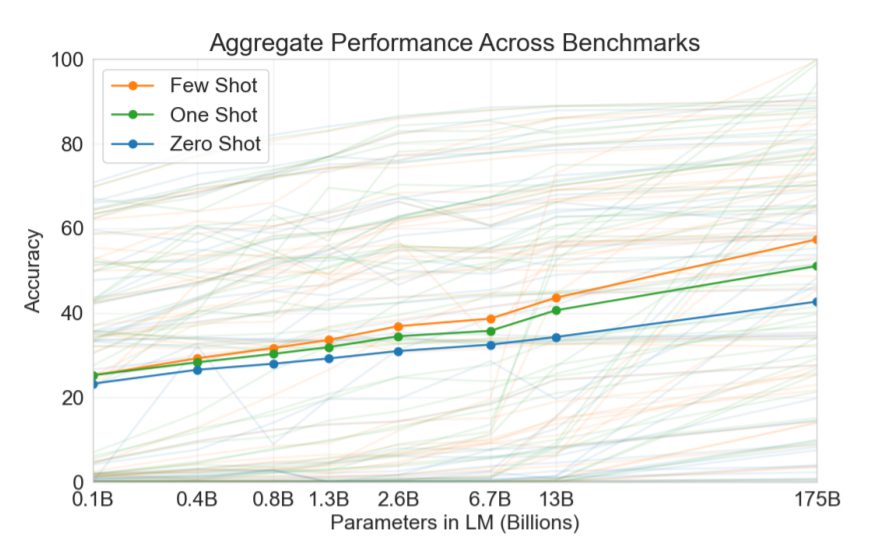
GPT-2までのモデルでも一般の企業や研究者などからすれば、到底構築することができませんが、GPT-3はそれらとは更に一線を隠す、1,750億ものパラメーターがあります。(これはLambda Labsによると最低価格のGPUクラウドで単一のトレーニングを実行したとしても、最低355年と460万ドルかかるそうです。)つまり、GPT-3はGPT-2のパラメータ数を約100倍にした超大規模モデルです。GPT-3は、ウェブやデジタル化された書籍から集められた約4900憶個もの単語トークンのコレクションを使って、同社がマイクロソフト社に支払って構築した数十万個のプロセッサーを搭載したスーパーコンピューター上で訓練されています。GPT-3はタスクの説明・少数の実例・プロンプトに沿って文章を生成します。論文では実例 (モデルに実行してほしいタスクのサンプル) の数が多いほど、タスクを正確に実行すると報告されています。なお、GPT-2と比べて、スケールが大幅に向上しただけで、言語処理するうえでの技術的向上はあまりないようです。
以上をまとめると、GPT-2からGPT-3の変更点は①「ゼロショット」から「小数ショット」になり、②大規模なモデル(15億個のパラメータ)から、さらに大規模なモデル(1750億個のパラメータ)、③大規模なデータセット(約100億トークン)からさらに大規模なデータセット(約4900億トークン)の三つとなります。なお、ゼロショットから小数ショットにあえて増やすことで、より多くのタスクに手軽に対応することができるようになりました。
これまでのモデルとGPT-3(及びGPTシリーズ)の違いについて
基本的にこれまでのNLPモデルと最も違うのはそのスケールですが、それでも目指すべき在り方の違いなどでほかのモデルとは異なる部分があります。
GPTモデルがほかのモデルとは最も際立って異なるのは、すべてのタスクに同じもモデルを利用することを目指しているということです。BERTなどのほかのモデルでは、タスクごとの微調整をする必要があり、例えば感情分類をするためにBERTを利用するときにはそのために追加のレイヤーを組み込む必要があります。ほかにも対応するために、転移学習を基礎としていました。
OpenAIはGPT-2のときから微調整なし(ゼロショット)での利用の可能性を示していました。今回のGPT-3は更にその汎用性がたかまり、ほとんど調整を必要とせず、タスク用の新たなサンプルを少し学習させるだけで、新たなタスクに対応することができるようになっています。実際には、モデルに「タスクの説明」「いくつかの例」「プロンプト」を与えることで、モデルがタスクに必要なことを学習します。
この違いがそれまでのモデルと異なる「汎用性」と「手軽さ」を生んでいるといえるかと思います。
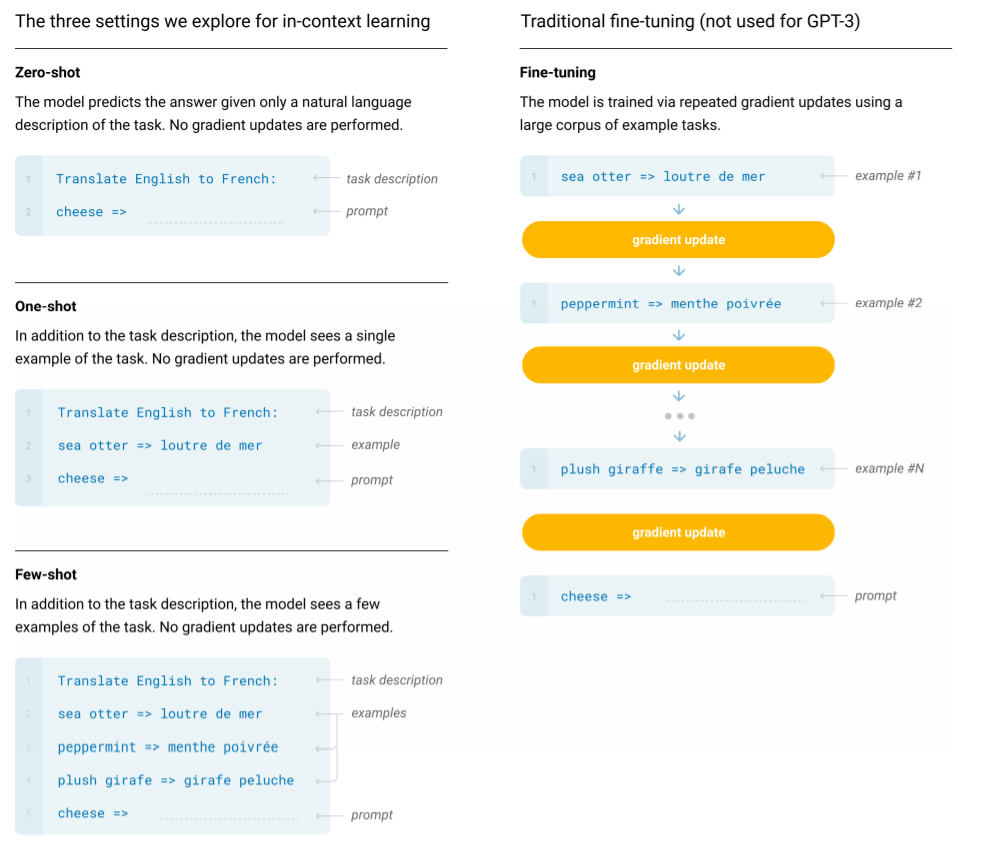
論文説明
今回のGPT-3に関する論文の概要を説明します。
・モデルの大きさ
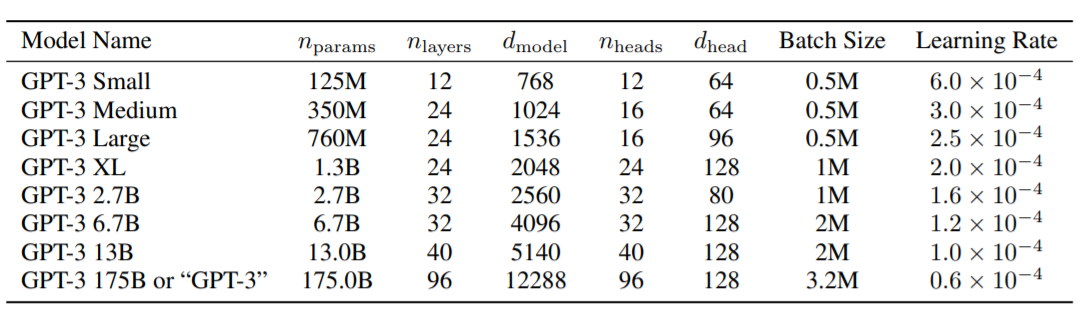
論文ではGPT-3には、125Mから175Bまでの8つのサイズが用いられています。
最小のGPT-3モデル(125M)は、おおよそBERTベースと同サイズです。
最大のGPT-3モデル(175B)は、以前の最大モデルよりも1桁大きくなっています。
・モデルアーキテクチャ
GPT-2などと同じAttentionベースのautoregressive language(自己回帰型言語)アーキテクチャです。
autoregressive languageアーキテクチャとはそれまで学習された単語をもとに次の単語を予想する言語モデルのことです。
最小のGPT-3モデル(125M)には12のAttentionレイヤーがあり、それぞれに12×64次元ヘッドがあります。
最大のGPT-3モデル(175B)は96のAttentionレイヤーを使用し、それぞれに96x 128次元のヘッドがあります。
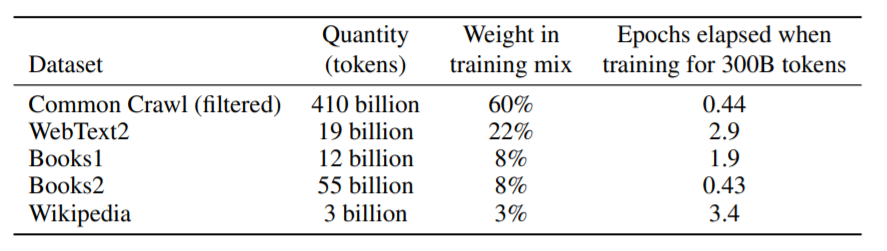
・トレーニングデータ
データのサイズはモデルによってスケーリングされていますが、最大のモデルに対しては4900億個のトークンでトレーニングされています。(なお、内訳は一般的なWebクロールから4100億個、WebText2から190億個、Books1から120億個、Books2から550億個、Wikipediaから30億個となっています。)
なお、これだけスケールがアップしたことで、GPT-3が対処しなければならない1つの新しい課題として、データの汚染があります。トレーニングデータセットがインターネットから供給されているため、トレーニングデータが一部のテストデータセットと重複する可能性(汚染)があります。GPT-2でもこのことは問題視されていましたが、GPT-3では特に問題に対処することが喫緊の課題となっています。
そのため、論文内では汚染を排したクリーンなテストデータセットを作ったことで、汚染の影響を調査しています。(クリーンの方法は、13グラムが重複する例を同じものとして排除するというもの)比較したところ、ほとんどのパフォーマンスは変化しなかったものの、タスクによっては大きな影響をうけたものが確認されており、OpenAIでは今後も検討することにしているようです。
・実験結果
GPT-3論文では多くの実験がされており、そのうち重点をおかれて解説されていたものの結果をご紹介します。
言語モデル評価
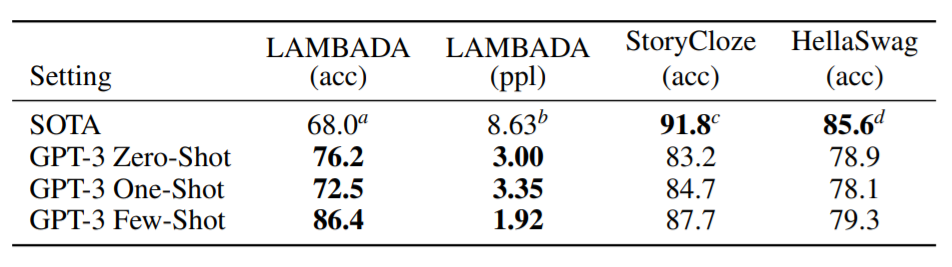
穴埋めや次の文章の予測など、オーソドックスなNLPのタスクをやった結果、多くのタスクでSOTAと同じくらいか、それを上回る結果を出しました。特にLAMBADA(長期依存を確認するタスク)ではSOTAをすべてのショットモデルが上回りました。
知識解答実験
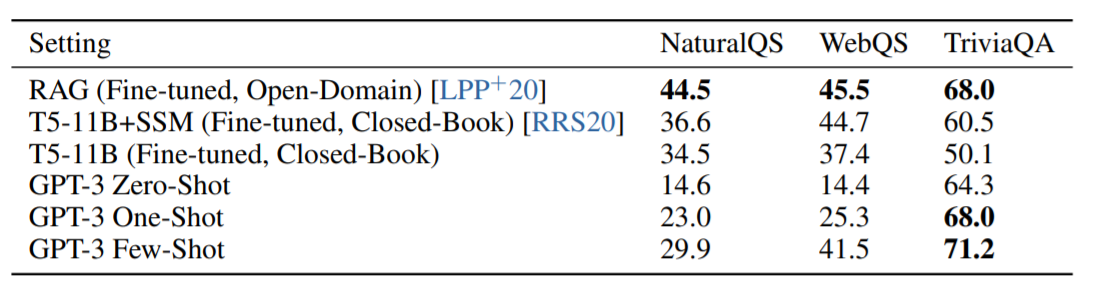
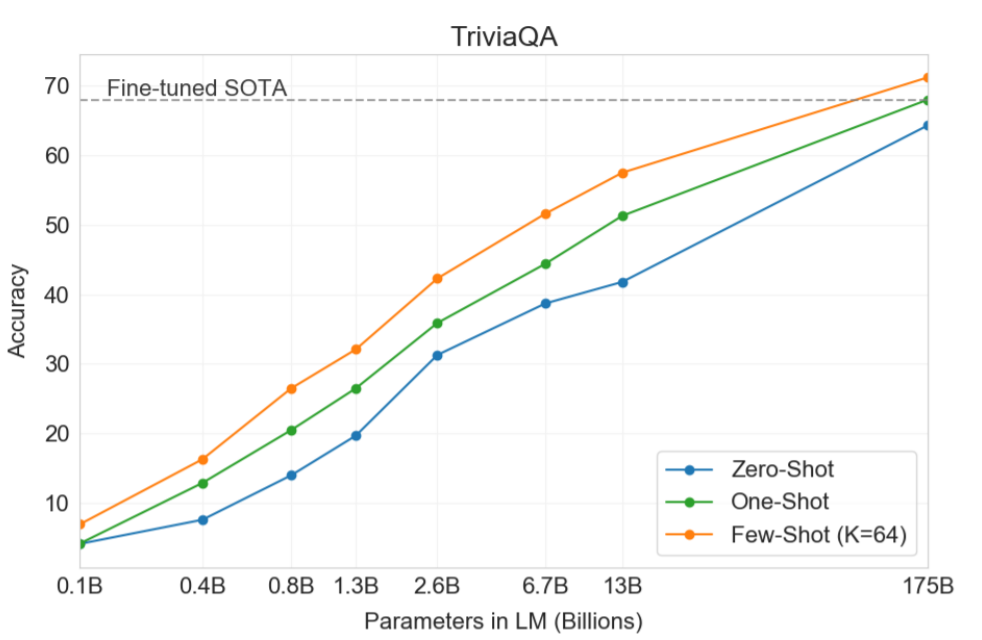
事実知識を答える実験でもGPT-3は優秀な結果を残しています。とくにTriviaQAというテストでよい結果を出しています。なお、NaturalQSのテストではあまり成果がよくありませんが、論文ではテストがより細かいことを問うようになっているため、GPT-3の容量では対応できていないのではないかという見解を出しています。
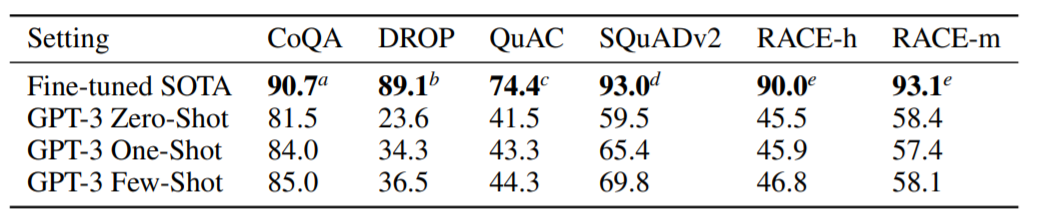
翻訳実験
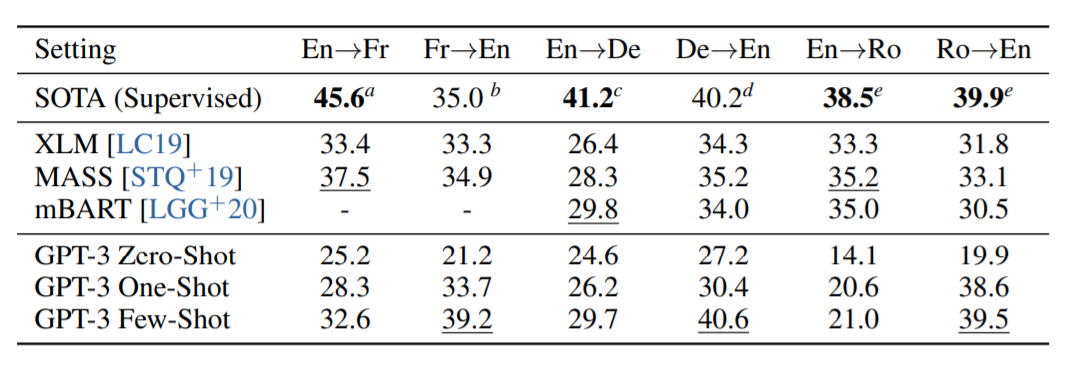
翻訳実験を行った結果です。結果からいうとファインチューニングされたSOTAモデルのほうが多くの場合、精度がたかいことが報告されています。ただし、このSOTAモデルは教師あり学習であるため、GPT-3の場合はファインチューニングもしない教師なしモデルのため、この結果は評価できるのではないかと論文では述べています。
![]()
代名詞あてタスク
ウィノグラードスキーマチャレンジは、NLPの古典的なタスクであり、代名詞が文法的にあいまいであるが意味的にはあいまいでない場合に、代名詞が参照する単語をあてられるかを確認するタスクです。一部ではよい結果がでていますが、ファインチューンされたSOTAモデルには基本的にこえられませんでした。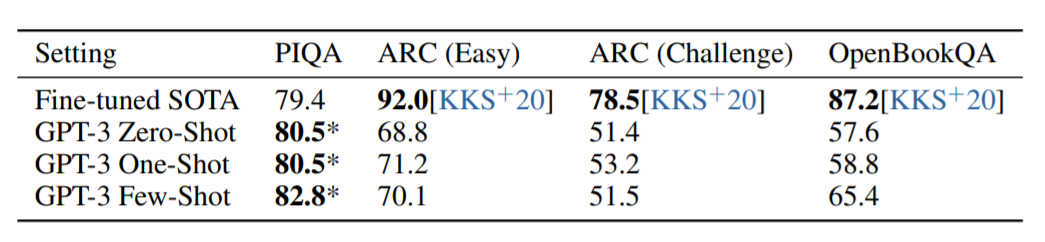
常識解答タスク
科学的もしくは物理法則にのっとる常識を解答するタスクです。ここではあまりよい結果がだせないことがわかりました。
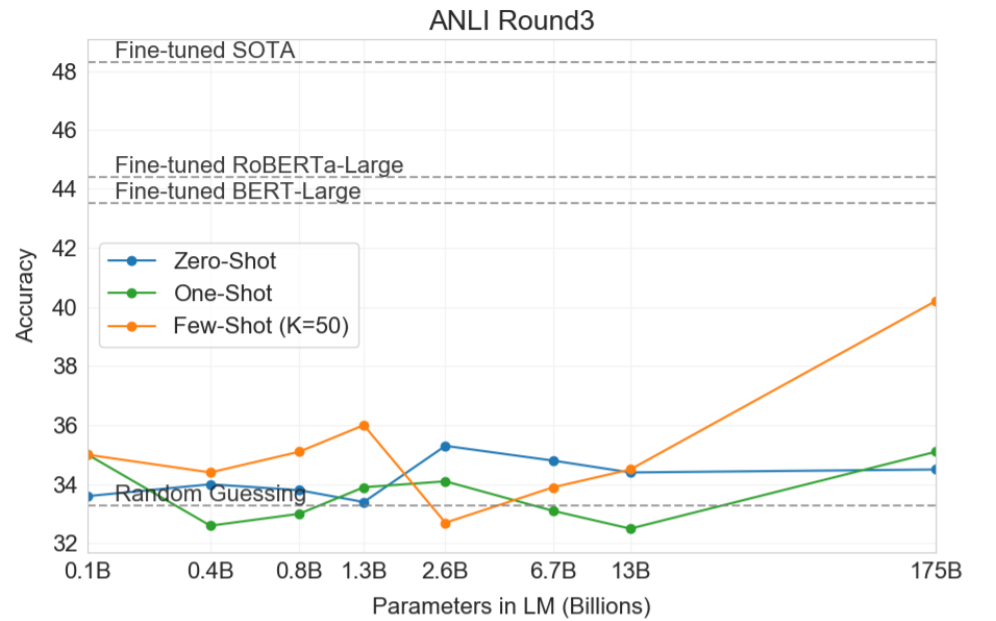
文書間関連性認識タスク
NLIという二文間の関係性を理解する能力をはかるタスクです。GPT-3はあまりよい結果を出せているとは言い難いですが、ほかのモデルもあまり結果は芳しくないことから、この分野はまだ機械学習においては難しい分野であると結論付けています。
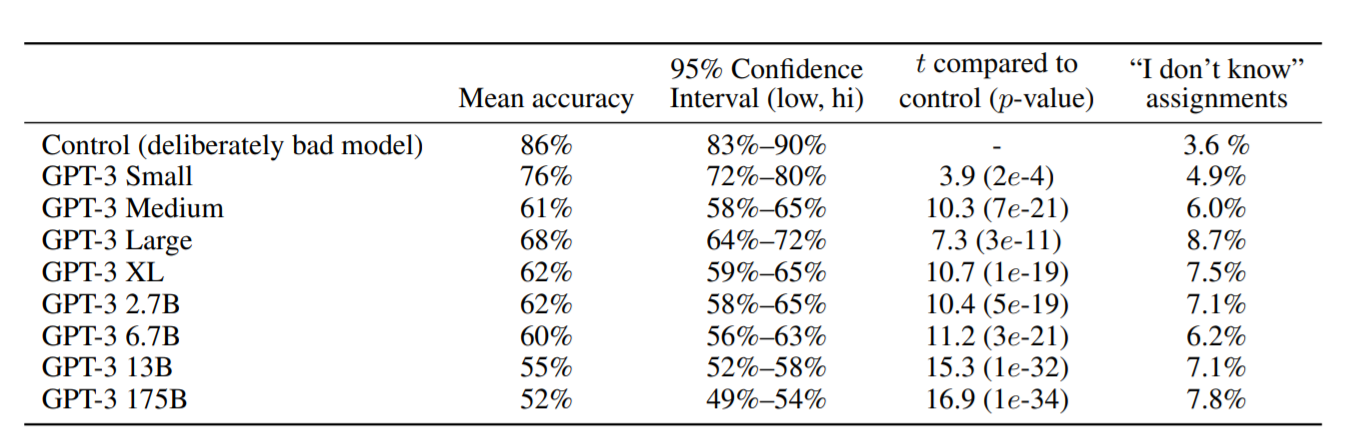
文章生成タスク
機械が生成した文章と人間が書いた文章を判別するタスクです。最も大きいモデルではほとんど判別がついていないことがわかります(平均で52%)。このことが、悪用される危険性があるという判断につながっています。
・誹謗中傷・偏見的発言について
GPT-3では、論文作成者が論文内で言及するほど、そのモデルの発する偏見や誹謗中傷について問題視しています。
細かくは論文やそれを論じた記事(How Biased is GPT-3?:https://medium.com/fair-bytes/how-biased-is-gpt-3-5b2b91f1177)を確認頂ければと思いますが、地域や人種、宗教などでどのような差別的な発言が行われているのかを確認しています。GPT-2ではすでにモデルの修正やデータセットの修正によって、出力する割合を減らすことができることが確認されており、GPT-3でも同様の試みの必要性が訴えられています。ただし、これらはモデルが生み出したというよりは、ネット上から情報を集めてきた結果であり、そもそもの問題点は人間にあるともいえます。こうした結果を生み出してしまっているということ自体が、世の中はそうした偏見や誹謗中傷が多くあるということを反映していることであることは意識する必要があるでしょう。
まとめ
現在、話題が集中しているGTP-3モデルですが、その理由は端的にいえば技術的に革新があるということよりも、性能が人間が利用する上でいよいよ無視できないレベルにはじめて達したという点にあるかといえます。
これから多くのチームがGPT-3を超えるモデルを発表するかとおもうと、生活が大きく変化していきそうです。
参考URL
Tempering Expectations for GPT-3 and OpenAI’s API
https://minimaxir.com/2020/07/gpt3-expectations/
OpenAI’s GPT-3 Language Model: A Technical Overview
https://lambdalabs.com/blog/demystifying-gpt-3/
GPT-3: The First Artificial General Intelligence?
https://towardsdatascience.com/gpt-3-the-first-artificial-general-intelligence-b8d9b38557a1
How Biased is GPT-3?
https://medium.com/fair-bytes/how-biased-is-gpt-3-5b2b91f1177
GPT-3のバイアスはどのようなものなのか?
https://ainow.ai/2020/07/20/224713/
OpenAIが文章生成AIのGPT-3を商用化
https://www.axion.zone/openai-releases-gpt3/
超巨大高性能モデルGPT-3の到達点とその限界
https://medium.com/@akichan_f/%E8%B6%85%E5%B7%A8%E5%A4%A7%E9%AB%98%E6%80%A7%E8%83%BD%E3%83%A2%E3%83%87%E3%83%ABgpt-3%E3%81%AE%E5%88%B0%E9%81%94%E7%82%B9%E3%81%A8%E3%81%9D%E3%81%AE%E9%99%90%E7%95%8C-867dfdc99189