
はじめに
米・南カリフォルニア大学の研究チームが発展著しいNLP分野における最新のAIでも常識を踏まえた回答をすることが困難であることを指摘し、新たなデータセット及びベンチマークテスト「CommonGen」を提案しました。
New Test Reveals AI Still Lacks Common Sense
https://viterbischool.usc.edu/news/2020/11/new-test-reveals-ai-still-lacks-common-sense/
論文
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
https://arxiv.org/abs/1911.03705
概要
現在、AIが生成する文章は非常に向上し、人間が書いた文章と区別がつかない場合もあります。しかし、南カリフォルニア大学の研究チームは、そうした文章の多くは学習したものを模倣したものであり、AIが常識的な判断をもって文章を生成しているといえる段階にはないと指摘しています。そのため研究チームは現在のNLP分野で利用されているベンチマークに異議を唱えています。常識に基づいた判断ができるようになることは、ロボットなどが人間の生活環境に普及するうえで重要な要素となるため、適切な発展が望まれます。
従来の問題点
論文では、現在のNLPの常識を測るテストは「判別可能な常識(discriminative common sense)」に焦点があっていることを問題視しています。
これまでのテストは検索空間が小さく、限定的な選択肢に対して応答するものです。(たとえば、質問「大人はどこでスティックのりを使用しますか?」/選択肢=A:教室・B:オフィス・C:机の引き出し、など)こうしたテストに対して、広範なモデルトレーニングにより、すでに高い正解率をAIはだすことができます。しかし、一方で文章を生成させると文法的には正しくても常識的には問題を感じる文章が多いという問題があることを研究チームは発見しました。
今回の論文では、そのためAIによる常識の生成的な側面を測るベンチマークを提案しています。
実験
研究チームは、最新のモデルに対して一般的な名詞と動詞のセットを与えて、生成される文章からAIがどの程度常識的な文章を生成することができるのかを確認しました。確認された文章の多くは文法的にはただしいが、常識的に問題があることが多々ありました。(例えば、「犬、フリスビー、スロー、キャッチ」という単語を使用して最先端のモデルによって生成された文章は「2匹の犬がお互いにフリスビーを投げています」というものでした。)

さまざまなモデルを評価するために、CommonGenと呼ばれる制約付きテキスト生成タスクを開発しました。これは、マシンが生成する文章の常識をテストするためのベンチマークとして使用できます。また77,449文に関連する35,141の概念からなるデータセットを研究チームは提供しています。このデータセットを利用すると、最高のパフォーマンスを発揮するモデル(GPT-2やT5など)でさえ、人間の63.5%に対して31.6%の正解率しか達成していないことを発見しました。
CommonGenについて
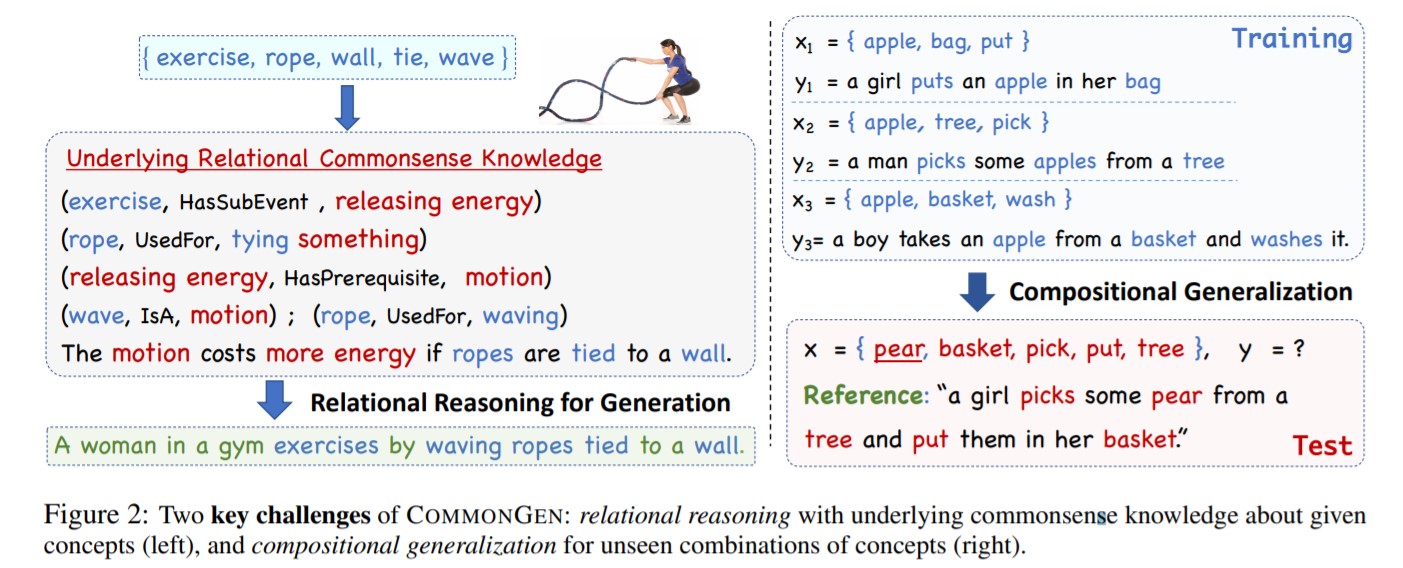
CommonGenでは、与えらた概念(学習していない概念を含む)から常識敵に破綻していない文章を生成することがもとめられます。そのため、各モデルは
①常識的知識に基づいた論理的な関係推論能力(relational reasoning)
②学習していない概念を組み合わせる包括的汎用能力(compositional generalization)
が問われることになります。
このテストによって、新たに出会った概念でも適切な類似をすることができるということになっています。(ただし、生成された文章に対する評価は人間によって判断されます。)

Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, Xiang Ren. CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning. submitted to arXiv, 2020