教師あり学習
概要
与えられたデータ(入力)を元に、そのデータがどんなパターン(出力)になるのか、その間にどのような関係があるのかを識別・予測する手法。
ここでいう「教師」とは、出力データのことを指し、多くの場合、人間がこの役割を担っている。
また、予測したいものによって2種類の予想問題に分けられ、それぞれの問題に応じた代表的な手法が数多く存在する。
回帰問題
数字(連続する値)を予測する問題
ex.)過去の売上から、将来の売上を予測する
分類問題
離散値(連続しない値)を予測する問題
ex.)与えられた動物の画像が、なんの動物なのかを識別する
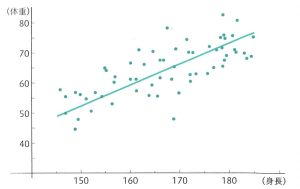
線形回帰
回帰問題
既知のデータ(の分布)があったときに、そのデータに最も当てはまる直線、未知のデータの値を予測するもの。
統計でも用いられる手法であり、最もシンプルなモデルの1つ。
ロジスティック回帰
線形回帰を拡張し、目的変数が2クラスを取る場合などに使われる分類手法。
名前に「回帰」とついているが、回帰問題ではなく分類問題に用いられる。また、シグモイド関数をモデルの出力に用いる。
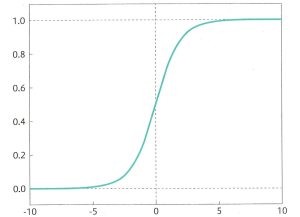
任意の値を0~1の間に写像するシグモイド関数を用いることによって、与えられたデータが正例(+1)になるか、負例(0)になるかの確率が求まる。出力の値が0.5以上ならば正例、0.5未満ならば負例、と閾値を設定し、データを2種類に分類できるようになる。閾値は基本的には0.5であるが、設定を0.7や0.3にしたり、分類の調整を行うことができる。
2種類以上の分類を行いたいというケースでは、シグモイド関数の代わりにソフトマックス関数を用いる。
サポートベクトルマシン
(入力に用いる)異なるクラスの各データ点との距離が最大となるような境界線を求めることで、パターン分類を行うというもの。
この距離を最大化することを、マージン最大化という。また、
・扱うデータが高次元
・データが線形(直線で)分類不可
という問題を想定し、対処する必要がある。前者であれば直線ではなく超平面を考えればよいが、後者では何をもってマージン最大化となるかを考える必要がある。
→ あえてデータを高次元に写像することで、その写像後の空間で線形分類出来るようにするというアプローチがとられる。
この写像に用いられる関数のことをカーネル関数と言い、その際に計算が複雑化しないよう式変形を行うテクニックのことをカーネルトリックと言う。
分類問題,回帰問題どちらのタスクにも利用可能、分類問題の方が多い。
自己回帰モデル(AR)
回帰問題
ある時刻tの値を、時刻t以前のデータを使って回帰する、時系列データを対象とするモデル。
特に、自己相関の高い時系列データのモデリングに対して有効であり、株価の推移や世界人口の年ごとの推移など、将来の数値の予測、分析に用いられる手法。
※時系列データ
時間軸に沿ったデータのことを指す。
時系列データ分析のことを時系列分析とも言う。
式,ベクトル自己回帰モデル
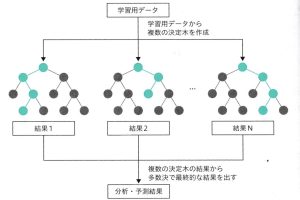
ランダムフォレスト
機械学習に決定木を用いたアンサンブル手法。
回帰と分類があり、決定木同様の解釈性の高さが特徴。データが複雑になると決定木である分岐路の組み合わせが複数考えられるようになるが、ランダムフォレストでは特徴量をランダムで選び出すため、ランダムに複数の決定木が作られることになる。
予測結果はそれぞれの決定木で異なる場合が発生することになるので、それぞれの結果を用いて多数決をとり、最終的な出力を決定する。
このように、複数のモデルで学習させることをアンサンブル学習、全体から一部のデータを用いて複数のデータを用いて学習する方法をバギングと言い、ランダムフォレストはバギングの中で決定木を用いている手法という位置づけとなる。
分類問題,回帰問題どちらのタスクにも利用可能
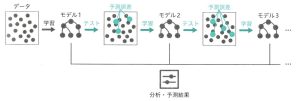
ブースティング
予測データ分析のエラーを減らすために機械学習で使用される方法であり、一部のデータを繰り返し抽出し、複数のモデルを学習させるアプローチをとる。
バキングは複数のモデルを一気に並列に作成するのに対し、ブースティングはまず1つのモデルを作成し、そこで誤認識してしまったデータを優先的に正しく分類できるように学習する。こうして順次、前のモデルで誤ったデータに重みを付けて学習を進めていき、最終的に1つのモデルとして出力を行う。
モデル部分では決定木が用いられている。
ランダムフォレストに比べ、ブースティングのモデルの方が良い精度が得られるが、並列処理ができないため、学習にかかる時間が多くなってしまう。
分類問題,回帰問題どちらのタスクにも利用可能