Scene Graphsから、画像を生成する手法が発表されていましたので、実装してみました。
■論文
https://arxiv.org/abs/1804.01622
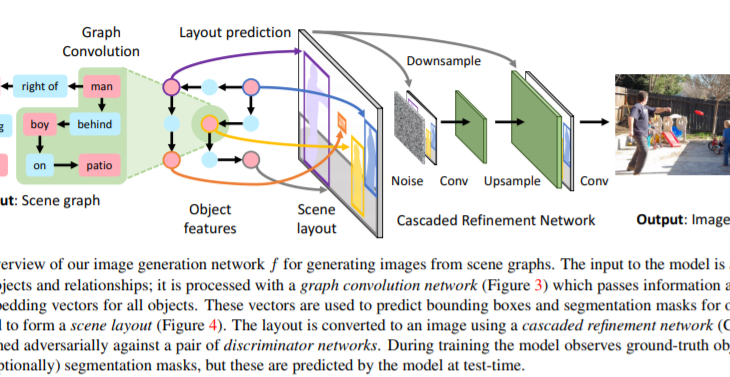
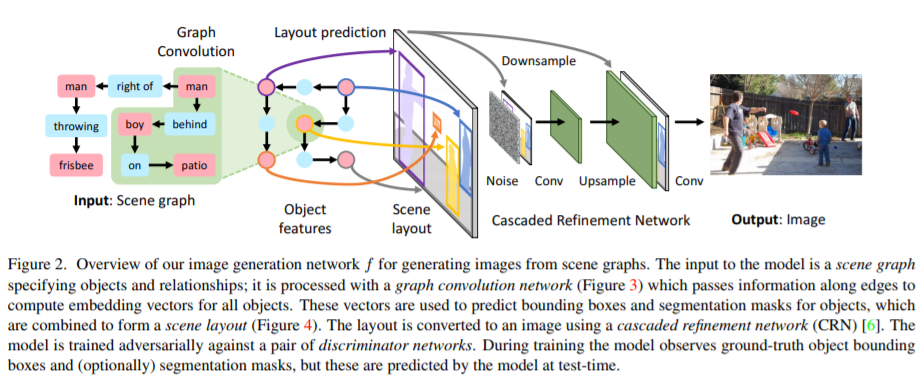
手法としては、文内の単語関係をグラフ構造化(Scene Graph)し、各オブジェクト表現についてGraph Convolutionで畳み込みます。そして、その特徴量を利用してオブジェクト領域/セグメンテーションを予測します。そしてGANのようにGeneratorとDiscriminatorを使用し、学習しています。
実際に実装してみましたが、Scene Graphの構造は、json形式のファイルを見るとよりわかりやすいと思います。例えば、画像に「空」、「草原」、「羊(2匹)」、「木」、「海」、「ボート」を登場させたい場合、以下のような書き方になります。
“objects”: [“sky”, “grass”, “sheep”, “sheep”, “tree”, “ocean”, “boat”],
わかりやすいですね。
そして、このそれぞれのオブジェクトにの位置関係を指定します。
・草原の上に雲がある
・羊は草原にいる
・2匹の羊はそばにいる
・羊の後ろに木がある
・木のそばには海がある
・海にボートがある
こちらをjson形式に書き換えたのが以下です。
“relationships”: [
[0, “above”, 1],
[2, “standing on”, 1],
[3, “by”, 2],
[4, “behind”, 2],
[5, “by”, 4],
[6, “in”, 5]
]
これもイメージがつきやすいですね。
この条件で画像を生成すると以下のようになります。

羊がかわいいですね(笑)
その他の結果も見ていきます。
例えば、
“objects”: [“sky”, “water”, “person”, “wave”, “board”,],
“relationships”: [
[0, “above”, 1],
[2, “by”, 1],
[2, “riding”, 3],
[2, “riding”, 4]
]
と指定すると、
・水の上に空がある
・人のそばに水がある
・人が波に乗っている
・人がボードに乗っている
となりますので、以下のような出力になります。

また、
“objects”: [“bus”, “street”, “line”, “sky”],
“relationships”: [
[0, “on”, 1],
[2, “on”, 1],
[3, “above”, 1]
]
と指定すると、以下のような出力になります。

生成物の位置関係は指定できるので、あとはそれぞれの物体の生成の精度を上げてみたいと思いました。