今年度のNeurIPSで発表されたIBMの必要なビット数を抑えることで、より高速かつエネルギー消費を抑える方法に関する論文をご紹介します。
Ultra-Low Precision 4-bit Training of Deep Neural Networks
https://papers.nips.cc/paper/2020/file/13b919438259814cd5be8cb45877d577-Paper.pdf
問題意識
近年、AIモデルは大きくなっていく傾向があり、そのためAIモデルのトレーニングもコストが大きくなっています。コストが大きくなることで、ほとんどの人が実際に計算することができないモデルが多く存在しています。それだけでなく、エネルギーコストの増大は、環境に対してもはや無視できないほどの影響を与えるようになっています。たとえば、研究によると、大規模なAIモデルをトレーニングした場合、平均的な自動車の5台分の生涯二酸化炭素排出量に相当することがわかっています。そのため、より効率的な計算ができる方法が求められてきました。
論文概要
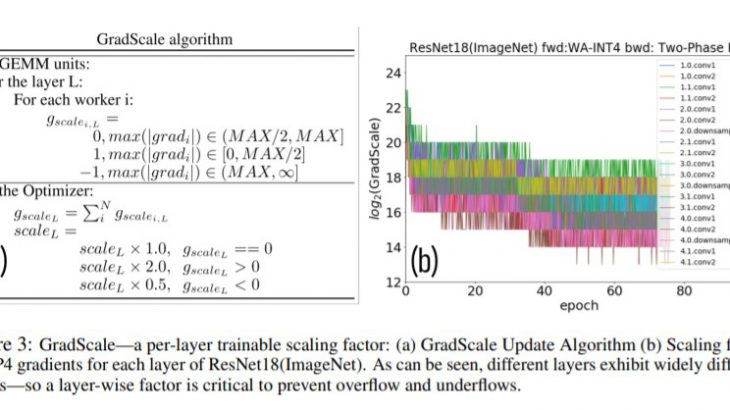
IBMの研究チームは、まず量子化された勾配の範囲と分解能が不十分であるという課題を解決する新しい適応的勾配スケーリング技術(GradScale)を探求し、モデル学習中に観測された量子化誤差の影響を探っています。そのうえで勾配量子化におけるバイアスの役割を理論的に解析し、モデルの収束性に対するこのバイアスの影響を緩和する解決策を提案しています。最後に、コンピュータビジョン、音声、NLPの深層学習モデルを対象に、手法の効果を検証しています。
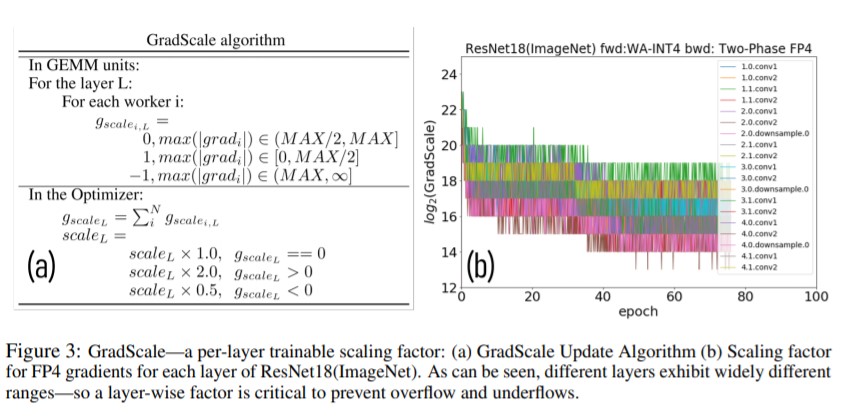
手法
論文ではビット減らした際の精度の減少などを確認する方法などを検証方法について細かく説明しています。今回は結果として研究チームによる、データのトレーニング時に必要なビット数を4ビットまで減らす方法について細かくみていきます。
コンピュータは基本的にビットで情報を保存しています。1ビットで2**1₌2通りの情報をあらわすことができ、8ビットでは2**10=256通りの情報を示すことができます。そのため、4ビットであるということは、2**4=16通りの情報を示せることを意味しています。
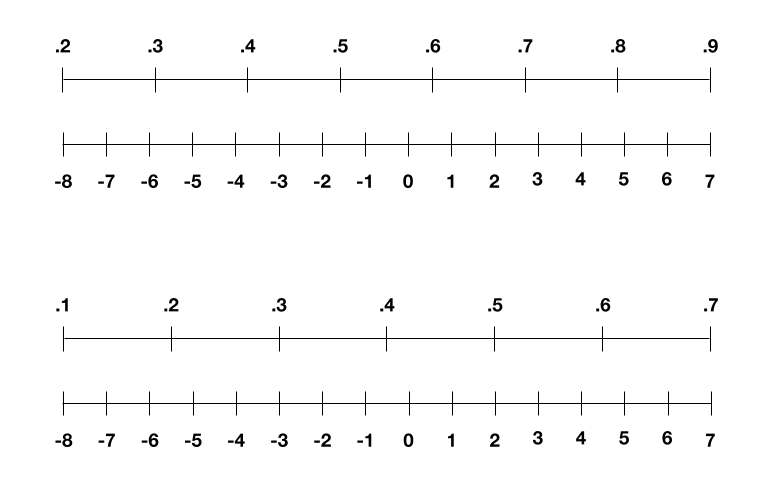
例えば、画像を学習した場合、画像はまず0から1までの数字のリストに正規化されます。この範囲を4ビットで表現しようとすると、-8から7までで表されます。数値のリストを線形にスケーリングするという考え方であるため、値0は-8になり、値1は7になり、小数は4ビット表現の中央の整数にマップされます。
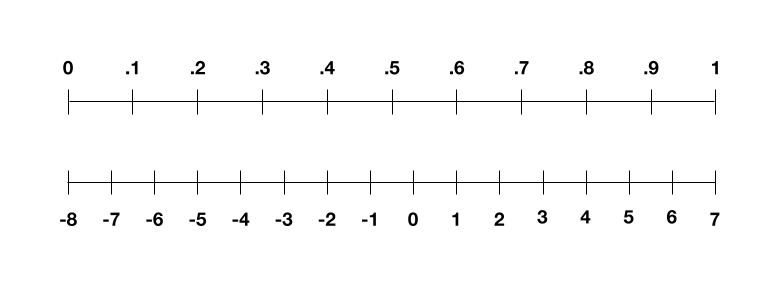
この場合、0.1の値は-6.5であり、-6.5を-7に丸めて整数を表すことになります。このようにして、画像を表現すると、その精度が低下する可能性があります。
これまでもIBMでは低ビットでうまく表現する方法が考えられてきました。重みとアクティベーションはピクセルと同じ方法でスケーリングされますが、アクティベーションと重みもトレーニングのラウンドごとにその範囲が変わります。アクティベーション範囲は、1ラウンドで0.2〜0.9、次のラウンドで0.1〜0.7などです。この変更に対応するために、IBMグループでは、これらの範囲を再スケーリングして、すべてのラウンドで-8から7の範囲に拡張することを提案しました。これにより、精度の低下を効果的に回避できるようになっています。
しかし、この方法ではトレーニング中の中間データが増加した場合に対応できないという問題がありました。
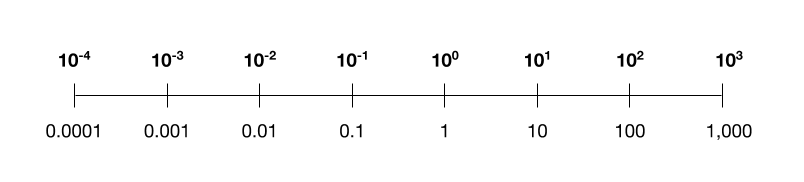
今回のIBMの論文では、中間数を対数的にスケーリングすることで精度を維持することに成功しました。
成果
以下のような成果が発見されました。
①アプリケーションの領域では有意な精度の低下を示さず、ハードウェアの高速化(最新のFP16システムと比較して7倍以上)を可能にしました。
②これらの利点により、トレーニングがエッジデバイスで可能になり、AIモデルのプライバシーとセキュリティが大幅に向上します。
③ハイブリッドクラウド環境への移行において企業にとってますます重要になっているハイブリッドクラウドインフラストラクチャの技術的アップグレードを提供することができます。
ただし、今回提案された4ビットの深層学習モデルが実用化されるまでには長い道のりがあります。現実の世界で実装するには、設計および開発された新しい4ビットハードウェアが必要としています。