
近年のディープラーニングの進化によって画像分類などのタスクにおいて、顕著な結果を得る事が出来る様になりました。しかしながら最近の事例では一般化と堅牢性の為に大きなモデルサイズが必要になることが示唆されており、より少ないリソースで大きなモデルをトレーニングすることがますます重要になって来ています。このための有望なアプローチとして「条件付き計算」の使用を推奨しています。このパラダイムは大規模な言語モデルに対する最近の研究で取り上げられていますが画像関連の分野では十分に検討されてはいませんでした。ここでは、後述する「エキスパートの疎な混合」に基づく新しいビジョンアーキテクチャである『V-MoE』を紹介しています。
Vision Mixture of Experts(V-MoEs)
Vision Transformers(ViT)は、ビジョンタスクに最適なアーキテクチャの1つとして登場しました。ViTはまず、画像を同じサイズの正方形のパッチに分割します。これは言語モデルから受け継いだ用語で、トークンと呼ばれます。しかし、最大の言語モデルに比べ、ViTモデルはパラメータ数や計算量が数桁小さいです。
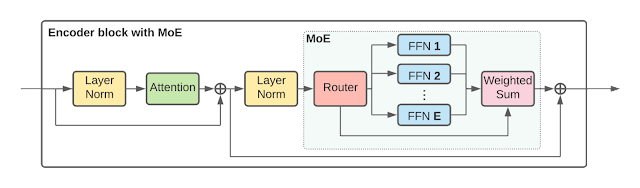
V-MoEは、画像モデルを大規模に拡張するために、ViTアーキテクチャの一部の高密度フィードフォワード層(FFN)を、独立したFFN(エキスパートと呼ぶ)の疎な混合に置き換えます。学習可能なルータ層は、個々のトークンごとにどのエキスパートを選択するか(そしてどのように重み付けするか)を選択します。つまり、同じ画像からの異なるトークンは、異なるエキスパートにルーティングされる可能性があります。各トークンは、合計E人のエキスパート(実験では、Eは通常32人)のうち、最大K人(通常1人か2人)のエキスパートにのみ送られます。このため、トークン1個あたりの計算量をほぼ一定に保ちながら、モデルのサイズを拡張することができます。次の図は論文の中で提示されたエンコーダブロックの詳細な構造です。学習可能なルーターレイヤーは個々のトークン毎に選択されるエキスパートを選択します。
論文では画像の大規模なデータセットである「JFT-300M」を使ったトレーニング結果を掲示していますが、同等の計算量で比較するとV-MoEを使ったモデルが大きく優れている(悪くても同等)とのパーフォーマンスが示されています。
優先ルーティング(BPR)
動的サイズのバッファを使用するのは効率的ではないため、モデルは通常、エキスパートごとにバッファ容量を事前定義します。この容量を超えて割り当てられたトークンはドロップされ、エキスパートが「満員」になると処理されません。
この実装制約を利用して、推論時にV-MoEを高速化します。合計バッファ容量を処理するトークンの数より少なくすることにより、ネットワークは一部のトークンの処理をスキップするように強制されます。モデルは重要度スコアに従ってトークンをソートすることを学習します。これにより、多くの計算を節約しながら、高精度の予測を維持します。以下に示すように、このアプローチをバッチ優先ルーティング(BPR)と呼びます。

大容量では、すべてのパッチが処理されるため、通常のルーティングと優先ルーティングの両方が適切に機能します。ただし、計算を節約するためにバッファサイズを小さくすると、通常のルーティングは処理する任意のパッチを選択するため、予測が不十分になることがよくあります。BPRは重要なパッチにスマートに優先順位を付け、より低い計算コストでより良い予測を実現します。
論文では従来の方法とV-MoEを比較して低容量なモデルで良好な結果を得ています。
ルーティングパターンの考察
ネットワークの内部動作に関しては未だ多くのことがわかっていませんが、1つの仮説としてはルーターが意味論根拠に基づいてトークンを識別し専門家(「車」や「動物」の専門家等)に割り当てることを学習するというものです。論文では特定の画像クラスに対応するトークンに対してエキスパートが選択されることが示唆されています。
最後に
V-MoEに加えて、エキスパートレイヤーで最も有用なトークンのみを処理するモデルを必要とするBPRを導入することによって、比較的少ないトレーニングコストで表現と転移学習を大幅に改善する方法が示されています。これは、コンピュータビジョンの大規模な条件付き計算の始まりにすぎないと考えられています。マルチモーダルモデルとマルチタスクモデル、エキスパート数のスケールアップ等スパースモデルによってモデルの改善がなされ、大規模なビデオモデリング等に役立っていく事と思われます。
出典:Scaling Vision with Sparse Mixture of Experts
URL:https://ai.googleblog.com/2022/01/scaling-vision-with-sparse-mixture-of.html