
はじめに
Googleがより効率的に長期関係を捉えることができるようにしたTransformerの改良モデル、Sparse Attentionについて解説していたのでご紹介します。
Constructing Transformers For Longer Sequences with Sparse Attention Methods
https://ai.googleblog.com/2021/03/constructing-transformers-for-longer.html
〇論文
Long Range Arena: A Benchmark for Efficient Transformers
https://arxiv.org/abs/2011.04006
概要
TransformerはAttentionメカニズムを利用してデータ間の関係性を学習するモデルで、NLP分野で非常に成功をおさめてきました。それまで主流であったLSTMから一気にNLP世界の主役となりました。しかし、強力なTransformerにも欠点があり、それがフルセルフアテンションをすると入力データの長さの二乗分の計算コストとメモリが必要となるという点です。このことは入力データの長さが長くなりすぎると計算できなくなることを意味しており、質疑応答タスクや要約タスクなどでは問題になってきます。
Googleは入力データ間でも注目すべき関係性に強弱があることに注目し、一部のデータ同士の関係性をより重視して計算するSparse Attentionメカニズムの改良を行ってきました。
Sparse Attention
現状のハードウェアでは、512トークンくらいが限界とされます。そのため、長いテキストを必要とするタスク、質疑応答や文章要約などのタスクに利用しづらいという問題が生じていました。そのため、より長い関係性を学習できるモデルとして、フルセルフアテンションではなくスパースセルフアテンションの可能性が模索されてきました。スパースセルフアテンションが通常のフルセルフアテンションと同等の表現力や柔軟性が維持できれば、より長い依存関係を学習することができます。Googleでは、ETCとBigBardの二つのモデルが開発されました。
Extended Transformer Construction (ETC)
拡張トランスフォーマー構造(Extended Transformer Construction:ETC)がまず開発されました。これは、スパースアテンションの新しい方法であり、構造情報を使用して、計算されるAttentionスコアのペアの数を制限します。これにより、データの入力長に計算コストが2次的に依存していたものが線形に減少し、よりよい結果が得られます。
セルフアテンションの構造化されたスパース化を達成するために、Global-Localアテンションメカニズムが開発されました。これは入力データを①無制限にトークン同士の関係性を計算することになるグローバル入力、および②グローバル入力もしくはローカル近隣トークン同士のみと関係性を計算することになるローカル入力のふたつに分けて、それぞれに固有のアテンションを適用します。これによりアテンションの計算量を線形スケーリングすることが可能となり、ETCが入力長を大幅にスケーリングできるようになります。
なお、長いドキュメントの構造をさらに活用するために、ETCは追加のアイデアとして、シーケンス内の絶対位置を使用するのではなく、相対的な方法でトークンの位置情報を表します。

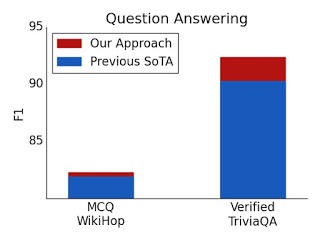
結果、従来の応答タスクでよりよい結果を残すことができました。
BIGBIRD
ETCはもとのデータに存在する構造に関するドメイン知識が利用できる場合に有効な手法です。そのため、ドメイン知識が利用できない場合でもより一般的に利用できるように開発されたのが、BigBirdと呼ばれる別のスパースアテンションメソッドです。また、BigBardは理論的に提案されたスパースアテンションメカニズムが2次フルトランスフォーマーの表現力と柔軟性を維持することも示しています。
アテンションメカニズムを有向グラフと考えることで、BigBirdは理解しやすくなります。トークンはノードで表され、類似度スコアはエッジで表されるトークンのペア間で計算されます。このアプローチの背後にある中心的な考え方は、線形数の類似性スコアのみを計算するように、スパースグラフを注意深く設計することです。
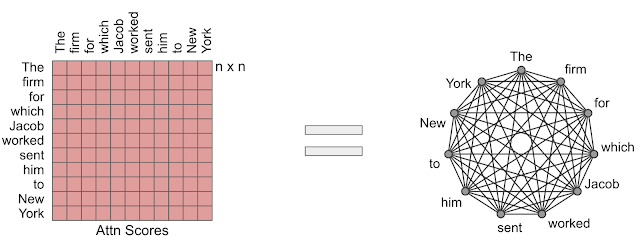
BigBirdでは、トークンの数も線形であり、Transformersで使用されるアテンションメカニズムの一般的な代替であるスパースアテンションメカニズムが利用されています。ETCとの違いは、BigBirdではソースデータに存在する構造に関する前提知識を必要としません。BigBirdモデルのスパースアテンションは、次の3つの主要部分で構成されます。
① 入力シーケンスのすべての部分に対応するグローバルトークンのセット
② ローカル隣接トークンのセットに参加するすべてのトークン
③ ランダムトークンのセットに参加するすべてのトークン
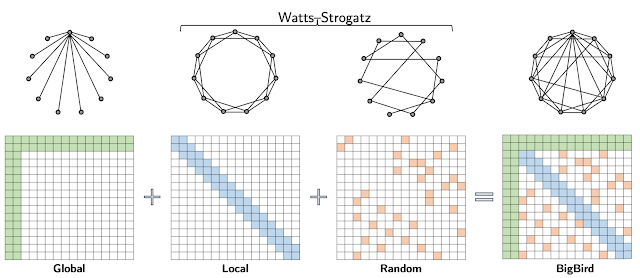
重要なアイディアは、計算するアテンションスコアの数と、異なるノード間の情報の流れとの間に固有の関係があることです(つまり、1つのトークンが相互に影響を与える能力)
グローバルトークンは情報フローの導管として機能し、グローバルトークンを使用したスパースアテンションメカニズムがフルアテンションモデルと同じくらい強力である可能性があることが証明されています。特に、BigBirdは、元のTransformerと同じくらい表現力があり、計算上普遍的であり、連続関数の普遍近似器であることが示されています。また、ランダムグラフの使用が情報の流れをさらに容易にするのに役立ち、ランダムアテンションコンポーネントの使用を動機付けることができることが研究では示唆されています。
BigBirdの設計では、構造化タスクと非構造化タスクの両方で、はるかに長いシーケンス長に拡張できます。トレーニング時間をシーケンスの長さとトレードオフすることによる勾配チェックポインティングを使用することで、さらにスケーリングを行うことができます。これにより、効率的なスパーストランスフォーマーを拡張して、エンコーダーとデコーダーを必要とする生成タスクを含めることができます。
実装上の重要なアイディア
スパースアテンションが主流にならない問題のひとつに、スパース操作が最新のハードウェアでは非常に非効率的であるためです。ETCとBigBirdの重要な改良点に、スパースアテンションメカニズムの効率的な実装を行うことを可能にした点が挙げられます。GPUやTPUなどの最新のハードウェアアクセラレータは、連続するバイトのブロックを一度にロードする合体メモリ操作の使用に優れていますが、スライディングウィンドウ(ローカルアテンション用)またはランダム要素クエリ(ランダムアテンション用)によって引き起こされる小さな散発的な検索を行うことは効率的ではありません。代わりに、スパースなローカルおよびランダムなアテンションを密なテンソル演算に変換して、SIMDハードウェアを最大限に活用します。これを行うには、最初にアテンションメカニズムを「ブロック化」して、ブロックで動作するように設計されたGPU / TPUをより有効に活用することが必要になります。その後、形状変更、ロール、収集などの一連の単純な行列演算を使用して、スパースアテンションメカニズムの計算を密なテンソル積に変換します。
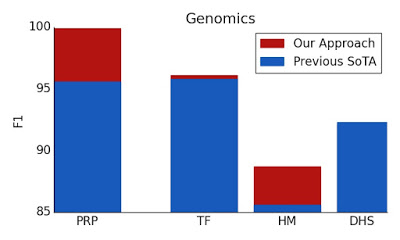
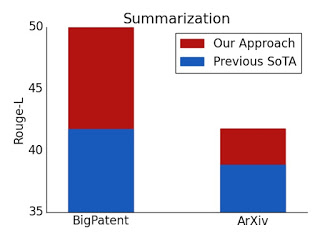
結果は、BigBirdモデルが、対応するモデルとは異なり、パフォーマンスを犠牲にすることなくメモリ消費を明らかに削減することを示しています。
注意深く設計されたスパースアテンションは、元の完全な注意モデルと同じくらい表現力があり、柔軟である可能性があることを示します。理論的な保証に加えて、非常に効率的な実装を提供し、はるかに長い入力に拡張できるようにします。その結果、質問応答、ドキュメントの要約、ゲノムフラグメントの分類に関して最先端の結果が得られます。
まとめ
Transformerの重要性が高まる中で、GPT-3などのハードウェアの力をより大きくすることでモデルの巨大化を成功させる方法がありますが、資金力のある限られた団体にしか利用できない手法です。一方で、スパースモデリングはより効率的なモデリング手法として注目を浴びており、利用可能性が高まることからも、今後もより有効な手法として新たなモデルの発表が期待されます。