はじめに
OpenAIより幅広いタスクでゼロショット転移(タスクごとのFine-tuningを必要としない)が可能な事前学習画像分類モデルCLIPが発表されたので、論文をもとに詳細解説します。簡単にまとめた記事も掲載しておりますので、お時間がない方はこちらをご参照下さい。(自然言語と画像を結びつけて高い汎化性能を実現したOpenAIのCLIPを紹介!)なお、この記事で用いた画像はすべて下記論文より引用したものです。
Learning Transferable Visual Models From Natural Language Supervision
https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf
OpenAIブログ
CLIP: Connecting Text and Images
https://openai.com/blog/clip/
概要
CLIPの特徴
CLIPの特徴は以下の三つにあるといえます。
●カテゴリーを利用者側で自由に設定できる自然言語教師型画像分類モデル
学習するデータが、一般的な画像とラベル(=自由度が低い)の組み合わせで構成されたものではなく、画像と画像を説明するためのテキスト(=自由度が高い)であるため、ラベルに設定できるカテゴリーが限定されずカテゴリー設定の自由度が向上しています。
●巨大な自然言語教師データ「WebImageText」の利用
インターネットを利用して構築された巨大な4億組の自然言語教師データ(=Natural Language Supervision:画像と画像を説明する自由テキストのペアのデータセット)「WebImageText」を利用しています。
●多様なタスクに対するゼロショット転移で転用可能
多様なタスクに対してゼロショット転移(=Zero-Shot Transfer:タスク特有のデータセットで学習をしないで事前学習データで学習したモデルを直接タスクに転用すること)で優れた精度を出しました。
論文詳細
OpenAIが公表した論文に従って、解説します。
論文の構成
1.イントロダクションとモチベーション
2.アプローチ
3.実験
4.人間のパフォーマンスとの比較
5.利用データの重複についての分析
6.限界
7.インパクト
8.関連研究
9.結論
なお、8.関連研究については、論文の本筋ではないため本記事では解説していません。
詳細を知りたい方は、論文を直接参照下さい。
また、PPT版はこちらを参考下さい。
イントロダクションとモチベーション
自然言語分野では、事前学習を未加工の文章から直接学習することが試みられており、GPT-3に代表されるような優れたゼロショット転移を可能にしてきました。
今回のCLIPは、画像処理分野でも未加工の画像と文章から直接学習することはできないのか、というモチベーションから行われています。同様の発想からVirTexや、ICMLM、ConVIRTなどがテキストから画像表現を学習するモデルとして発表されています。
しかし、それでも(ラベル化されていない)未加工の自然言語の教師データをそのまま画像表現の学習に利用する試み自体盛んとはいえません。理由は、総じてベンチマークテストに対して既存の他の方法より精度が低いためです。
この未加工の自然言語を付随しただけの教師なし学習と普通のラベル型教師あり学習との間を補完する形で弱教師学習も行われています。(例えば、Instagram画像上のImageNet関連のハッシュタグを予測する学習などがあげられます。)これらの試みは、自然言語の汎用性を活かしてより広範囲の視覚的概念を表現する教師ラベルとして自然言語を利用しています。弱教師モデルは比較的よい精度をベンチマークテストで出すことに成功していますが、予測を実行するために静的なソフトマックス分類器を使用しており、動的な出力メカニズムを欠いています。これは、柔軟性を著しく制限し、「ゼロショット」の能力を制限することにつながっています。
CLIPの研究チームは、弱教師モデルとこれまでの自然言語から直接画像表現を学習するモデルに性能の差を生み出している決定的な違いは、データセットの規模にあると考えました。前者が100万~10億という単位で画像を利用しているのに対して、後者はおよそ20万程度でした。CLIPでは、この差を埋めて学習した際の自然言語型教師モデルの可能性を探ることが目的のひとつでした。(結果、利用する学習データとしてインターネットから画像とテキストを集め、4億組の大規模なデータセットを構築しました。)そのため、モデルの改良は論文の主眼にはなく、利用しているモデルは、VerTexを参考に、ConVIRTをよりシンプルにしたモデルとなっています。
・ほぼ2桁の計算量にまたがる8つのモデルを学習してCLIPのスケーラビリティを研究し、伝達性能が計算量の滑らかな予測可能な関数であることが確認できました。
・30以上のベンチマークテストに対して、ゼロショット転移である程度の精度を出すことができました。
・ImageNetモデルのSOATモデルよりも効率がよいことがわかりました。
・ゼロショットCLIPモデルは同等の精度の教師付きImageNetモデルよりもはるかにロバストであることがわかり、タスクに依存しないモデルのゼロショット評価がモデルの能力をより代表することが示唆されました。
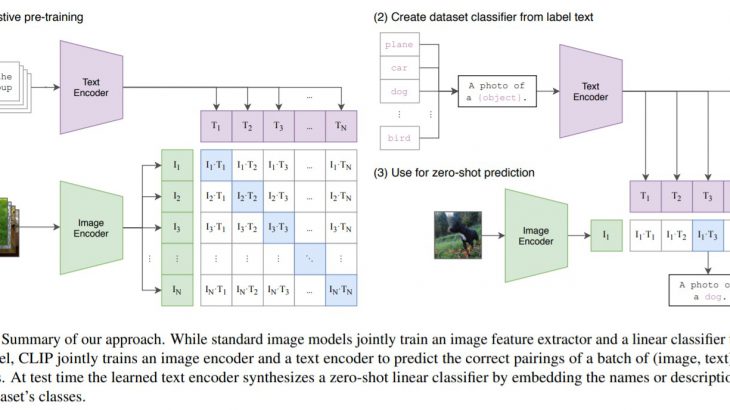
アプローチ
論文の姿勢、データセット、メトリックス、モデルの細かい調整などについて解説しています。
●自然言語教師 Natural Language Supervision
アプローチの中心的な発想は、自然言語に含まれる表現から画像表現が指し示すものを学習するという点にあります。ただし、(この学習に対する表現方法は教師なし学習、自己教師学習、弱教師あり学習、教師あり学習など色々ありますが)この発想自体は決して新しい発想ではないことも強調されています。CLIPの中心にあるのは特定の手法ではなく、自然言語の表現を学習指標として取り込みたいという発想とその実現にあります。
自然言語表現から直接学習することのメリットは、普通のラベルセットよりも拡張性が高くなることにあります。加えて、ただ学習しているだけでなく、ゼロショット転移を可能にする言語表現同士の関連性も獲得しているということにあります。
●十分に大きなデータセット
モデルの表現力を活かすため、インターネット上から4億組の画像とテキストのデータセットを構築しました。
収集するのは、タイトルもしくは説明がファイル名に反映されている画像データです。構築する際には、できるだけ幅広い視覚的概念をカバーするために、50 万個のクエリの中からテキストが含まれているペアを検索しています。
ベースとなる検索リストは、英語版ウィキペディアで100回以上出現するすべての単語です。これに、ある検索ボリューム以上のウィキペディアの記事のタイトルと同様に高い相互情報を持つ単語で補強されています。最後に、クエリリストに含まれていないすべてのWordNetのsynsetが追加されます。おおよそ、ひとつのクエリから約2万のペアが含まれるようになっています。最終的な収集数は、GPT-2で利用したWebTextのワード数に匹敵しています。
こうして構築されたデータセットをWIT:WebImageTextと呼称しています。
●評価指標としての「効率性」
現在のSOTAであるNoisy Studentの効率モデルが1000程度のクラスでも大変な計算資源を必要とすることから、より大きなクラスを学習することになるCLIPをスケールアップする鍵は「効率性」にあるとしています。そのため、最終的な手法を選択するうえでの評価指標は「効率性」に設定されています。
●モデル概要
はじめは、VirTexと同様にCNNとテキストTransformerを利用していましたが、効率性が悪いことからより効率性のいいモデル(VisionTransformerを利用したモデル)に変更されました。
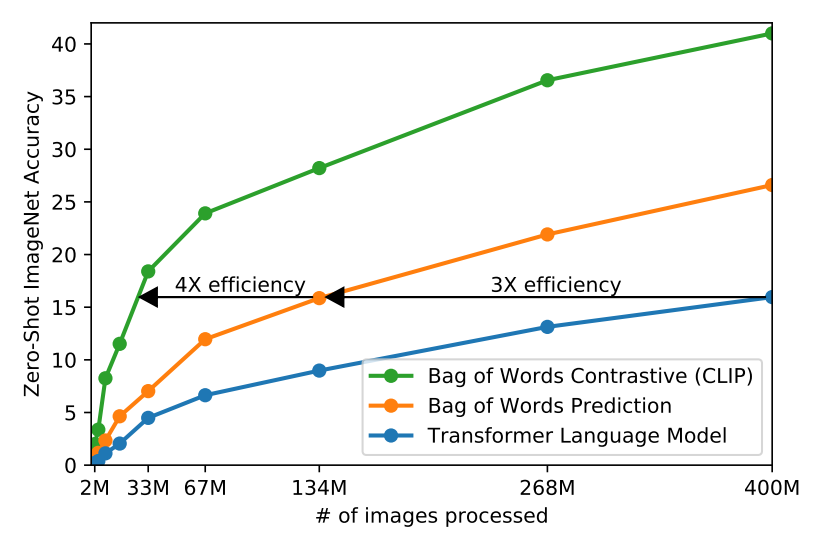
また正確な言葉を予測しようとすると非常に難しく、一方で対象表現学習でも同程度の精度がだせることが最近の研究でわかってきています。また、生成モデルは学習により多くのデータが必要になることもわかっています。以上から、テキストのなかの正確な単語ではなく、テキスト全体がどの画像とペアになっているかだけを予測するという、より簡単な代理タスクを解決するためのモデルとなりました。(実際に試したところ、Bag-of-Words エンコーディングのベースラインに対して、予測目的語を対照目的語に置き換えたところ、ImageNet へのゼロショット転送率がさらに 4 倍に向上したことが確認されました。)
最終的なモデルは、N個のペアのバッチが与えられると、CLIPは、バッチ全体でN×N個の可能性のあるペアリングのうち、どのペアリングが実際に発生したかを予測するように訓練されます。実際にCLIPでは、画像エンコーダーとテキストエンコーダーを一緒に訓練し、バッチ内のN個の実ペアの画像とテキストのエンベッディングのコサイン類似度を最大化する一方で、不正確なペアのエンベッディングのコサイン類似度を最小化することで、マルチモーダルエンベッディング空間を学習します。
・事前学習データセットのサイズが大きいため、過学習の問題には対処していません。
・画像エンコーダをImageNetの重みなどで初期化せずに、ゼロからCLIPを訓練してます。
・各エンコーダの表現からマルチモーダル埋め込み空間にマッピングするために線形射影のみを使用しています。(なお、非線形射影と線形射影の間の学習効率の違いはわからず、非線形射影は、現在の画像のみの自己教師付き表現学習法の詳細と共同適応される可能性があると推測しているようです。)
・事前学習データセットに含まれるペアの多くが単一文のみであるため、テキストから一様に単一文をサンプリングするテキスト変換関数tuを削除しています。
・画像変換関数tvを単純化します。(リサイズされた画像からのランダムな正方形の切り抜きが、トレーニング中に使用される唯一のデータ補強です。)
・ソフトマックスのロジットの範囲を制御する温度パラメータτ は、ハイパーパラメータにならないように、学習中に対数パラメータ化された乗算スカラーとして直接最適化されます。
●モデル詳細
<画像エンコーダ部分>
モデル1⃣(比較ベースモデル)
ResNet-50(He et al., 2016a)の改良版を利用します。
・グローバル平均プーリング層をアテンションプーリング機構に置き換えます。アテンションプーリングは、クエリが画像のグローバル平均プーリングされた表現に基づいて条件付けされる「Transformerスタイル」のマルチヘッドQKVアテンションの単一レイヤとして実装されています。
モデル2⃣(より洗練されたモデル)
基本的にVisionTransformerと同じものです。
・違いは、Transformerの前にパッチと位置の埋め込みを組み合わせたものに追加のレイヤ正規化を追加し、わずかに異なる初期化スキームを使用した点のみです。
<テキストエンコーダ部分>
基本的にTransformerを利用します。
・ベースサイズとして、8つのアテンションヘッドを持つ63Mパラメータの12層512ワイドモデルを使用します。
・49,152個のボキャブサイズを持つテキストの小文字のバイトペアエンコーディング(=BPE)表現で動作します。
・計算効率のため、最大シーケンス長は76に制限します。
・テキストシーケンスは[SOS]と[EOS]トークンで括られ、[EOS]トークンにおけるトランスフォーマーの最上位層の活性化は、層を正規化した後、マルチモーダル埋め込み空間に線形投影されたテキストの特徴表現として扱われます。
・事前に学習した言語モデルで初期化したり、補助的な目的として言語モデルを追加したりする能力を維持するために、マスクドセルフアテンションが使用されています。(なお、詳しいことは将来の研究にゆだねるとしています。)

●学習
学習させたモデルは以下の8つになります。
5 × ResNets
ResNet-50、ResNet-101、RN50x4、 RN50x16、RN50x64
3 × Vision Transformers
ViT-B/32、ViT-B/16、 ViT-L/14
なお、ViT-L/14については、性能を向上させるために、より高い336ピクセルの解像度で1つのエポックを追加して事前学習が行われています。このモデルを論文ではViT-L/14@336pxと表記しています。ViT-L/14@336pxが最も性能が高く、論文で「CLIP」とされているものは基本的にこのモデルを指しています。
・エポック数
すべての学習は 32 エポック行われました。
⇒学習時間
最大のResNetモデルであるRN50x64は592個のV100 GPU上で18日間
最大のVision Transformerは256個のV100 GPU上で12日間
・最適化関数
Adam(重み減衰正規化とコサイン関数を利用した学習率の減衰を組み合わせたもの)を利用しています
・ハイパーパラメータ
計算量を制約するためにヒューリスティックに適応させています。
・学習可能な温度パラメータτ
0.07に相当するものに初期化され、学習の不安定性を防ぐために必要であることがわかった100以上でロジットをスケーリングしないようにクリップされた。
・ミニバッチ
32,768という非常に大きなミニバッチサイズを使用しています。
・その他
トレーニングを高速化し、メモリを節約するために、Mixed-precision (Micikevicius et al., 2017)という手法と、追加のメモリを節約するために、gradient checkpointing(Griewank & Walther, 2000; Chen et al., 2016)、 half-precision Adam statistics(Dhariwal et al., 2020)、半確率的に丸められたテキストエンコーダの重みが使われています。
実験
実験では、主にゼロショット転移(Zero-Shot Transfer)の性能を測っています。
論文では「ゼロショット転移」(一般的には、未知のオブジェクトカテゴリーに対する画像分類のことを指す)を、未知のデータセットに対する画像分類として使っています。基本的にゼロショット転移や教師なし学習は、表現学習として注目されてきましたが、CLIPの研究チームはゼロショット転移学習をタスク学習能力を測るものとしてみなしています。ただし、ベンチマークテストで使われるデータセットは実践のタスクに向いているとは言い難く、タスク一般化能力ではなく分布移動やや領域一般化に対するロバスト性を測るためのものとしています。
●ゼロショット転移に対してCLIPを利用する方法
CLIPは、画像と文章のペアを予測するモデルです。各データセットについて、データセット内のすべてのクラスの名前を潜在的なテキストペアリングの集合として使用し、CLIPに従って最も確率の高い(画像、テキスト)ペアを予測します。
まず、画像の特徴埋め込みと、それぞれのエンコーダーによる可能性のあるテキストのセットの特徴埋め込みを計算します。次に,これらの埋め込みのコサイン類似度を計算し,温度パラメータτでスケーリングし,ソフトマックスを用いて確率分布に正規化します。(この予測層は、L2正規化された入力、L2正規化された重み、バイアスなし、温度スケーリングを持つ多項ロジスティック回帰分類器であることに注意が必要です。)
CLIPの事前学習の各ステップは、クラスごとに1つの例を含み、自然言語記述によって定義された総クラス数32,768のコンピュータビジョンデータセットに対して、ランダムに作成されたプロキシの性能を最適化していると見ることができます。ゼロショット評価のために、テキストエンコーダーによって計算されたゼロショット分類器を一度キャッシュし、その後のすべての予測のために再利用します。これにより、ゼロショット分類器の生成コストをデータセット内の全ての予測値に対して償却することが可能となります。
●プロンプトエンジニアリング
ゼロショットでベンチマークデータセットを利用するうえで以下の問題が発生しました。
⑴多義語だけ問題
文章がない単語だけのカテゴリーリストでは、多義語の意味が定まらないという問題です。普通のデータセットでも、別のクラスに分類されていながら同じ単語のものがある。
(例)①cranes(動物の鶴と重機のクレーン)②boxer (動物の犬種とスポーツ選手)
⑵単語だけ問題
CLIPの学習時に単語だけというケースが珍しく、与えるカテゴリーリストが単語だけでは高い精度での予測ができないという問題です。
対応
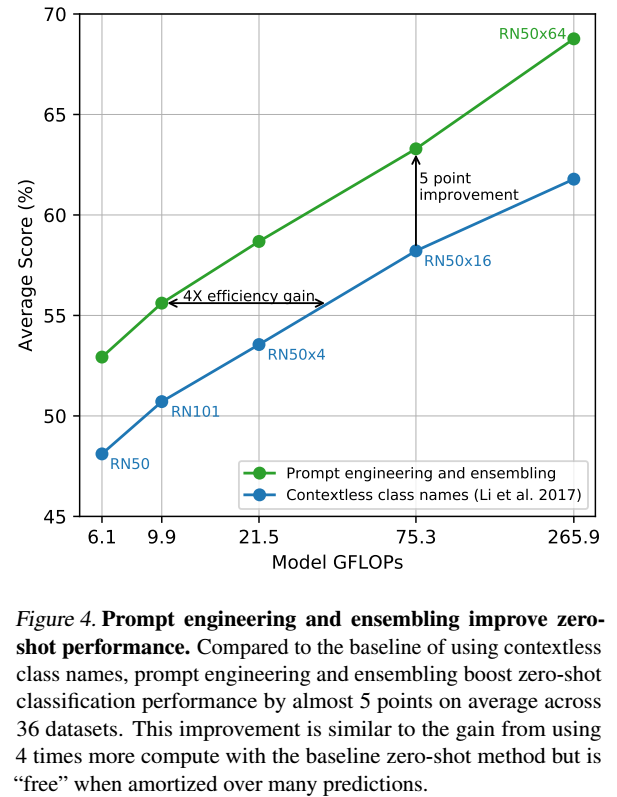
与えるプロンプトを工夫することでCLIPでは上記の問題に対応しています。まず、プロンプトを“ a photo of a {label}”と単語ではなく長くすることでうまく機能することがわかりました(ImageNetの場合、1.3%の性能の改善につながった)。また” a photo of a {label}, a type of pet” など、ベンチマークデータセットのタイプがわかっている場合は情報を追加で表現することで多義語の問題に対応しています。この応用はほかにも適用することができ、OCRデータセットでは認識したいテキストや数字の周りに引用符を付けることや、衛星画像の照合データセットでは画像がどの形式のものであるかを特定できる ” a satellite photo of a {label}. “といった形にするなどの工夫で精度が上昇することが確認されています。
加えて、プロンプトのアンサンブル学習(80の異なるプロンプトを利用)することで3.5%の精度上昇が確認されました。結果、両方の利用でおおよそ5%の上昇を実現できます。
●CLIPとVisual N-Gramの比較(概念実証実験)
Visual N-Grams(単純な自然言語教師型モデル)とCLIPを比較して、モデルが向上することを確認することで概念実証を行います。結果は精度の上昇が確認され、最高のCLIPモデルは、ImageNet上での精度を11.5%から76.2%に向上させています。
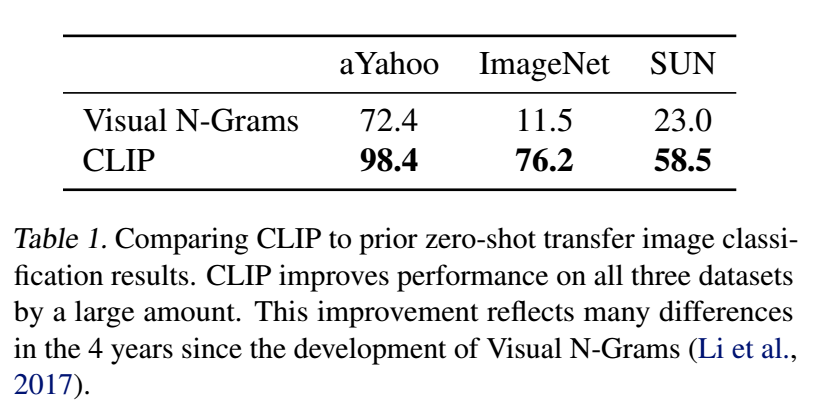
●ゼロショットCLIPと完全教師あり学習した線形分類器との比較
CLIPと完全教師あり学習した線形分類器をもつResNet-50比較しています。(27個のデータセット中16個で精度がうわマりました。)
良かったデータセット
STL10(限られたラベルデータから効率的に学習するように設計されたデータセット)から最も精度がよい(99.3%)が得られました。動画のデータセット(Kinetics700, UCF101)でもよい結果が得られました。ImageNet の名詞中心のオブジェクト教師データに比べて、WITには動詞を含む視覚的概念が広く含まれているためではないかと推測されています。
悪かったデータセット
特定の分野に特化したもの、複雑なもの、抽象的なものでは精度が出せませんでした。
・衛星画像分類(EuroSAT、RESISC45)
・リンパ節腫瘍検出(PatchCamelyon)
・合成シーン内のオブジェクトのカウント(CLEVRCounts)
・ドイツの交通標識認識(GTSRB)
・最寄り車までの距離認識(KITTI Distance)
普通の人間なら簡単にできるタスクがあることは、改良の余地があることを意味しています。一方で、人間でも専門家しかできないようなものをゼロショット転移学習でこなすことができるようになることに意味があるのかは議論の余地があるとしています。
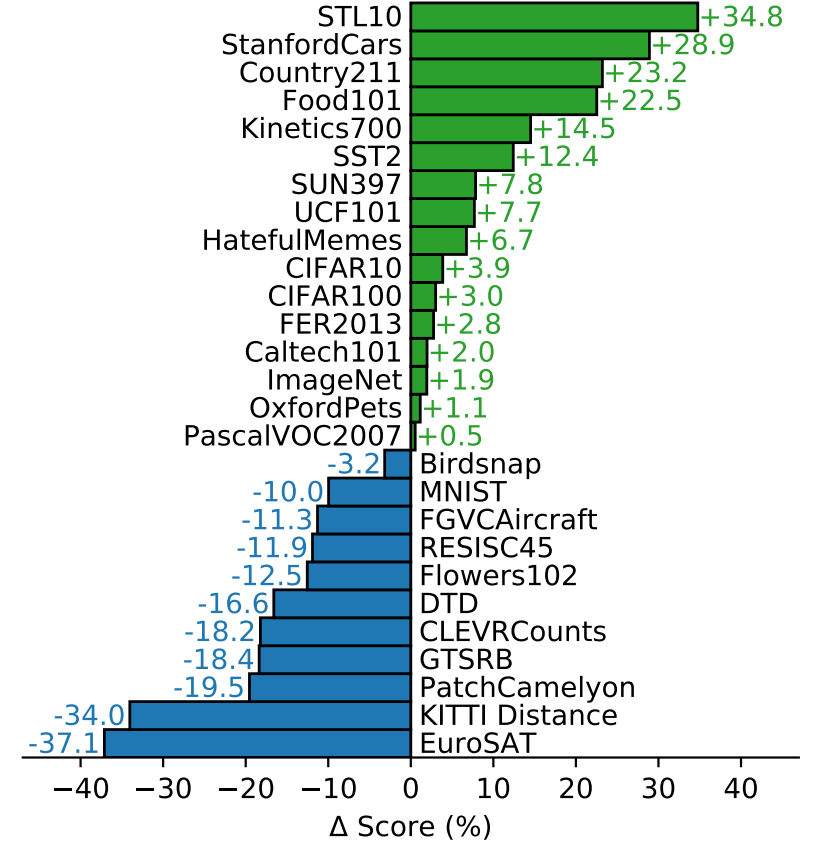
●ゼロショットと小数ショットの比較
精度の向上は、ゼロショット<小数ショットが直観的ですが、実際にはそうならないことが実験でわかりました。実際には4ショット目でようやく同じになります。これは、ゼロショットと数ショットのアプローチの違いが影響していると考えられます。
CLIPのゼロショット分類器は自然言語を介して生成されるため、視覚的な概念を直接指定(「伝達」)することができます。対照的に、「通常の」教師あり学習では、訓練例から間接的に概念を推論しなければなりません。そのため、特にワンショット学習の場合では、多くの異なる概念がデータと一致する可能性があるという欠点から、正しい学習が妨げられる可能性が高くなります。(ショット数が多くなれば(=データ数が多くなれば)、データと一致する概念が一意に定まってくるので、正しい学習ができるようになります。)
ゼロショットと少数ショットの性能の間の性能における矛盾を解決する可能性があるのは、CLIPのゼロショット分類器を少数ショット分類器の重みの優先順位として使用するものです。生成された重みにL2ペナルティを加えることで可能な簡単な実装ですが、結果として得られる少数ショット分類器が「もとのゼロショット分類器」と同じになってしまう可能性が高くあります。ゼロショット学習における概念の伝達の強さと少数ショット学習の柔軟性を組み合わせたより良い方法の研究が、今後の研究で求められています。
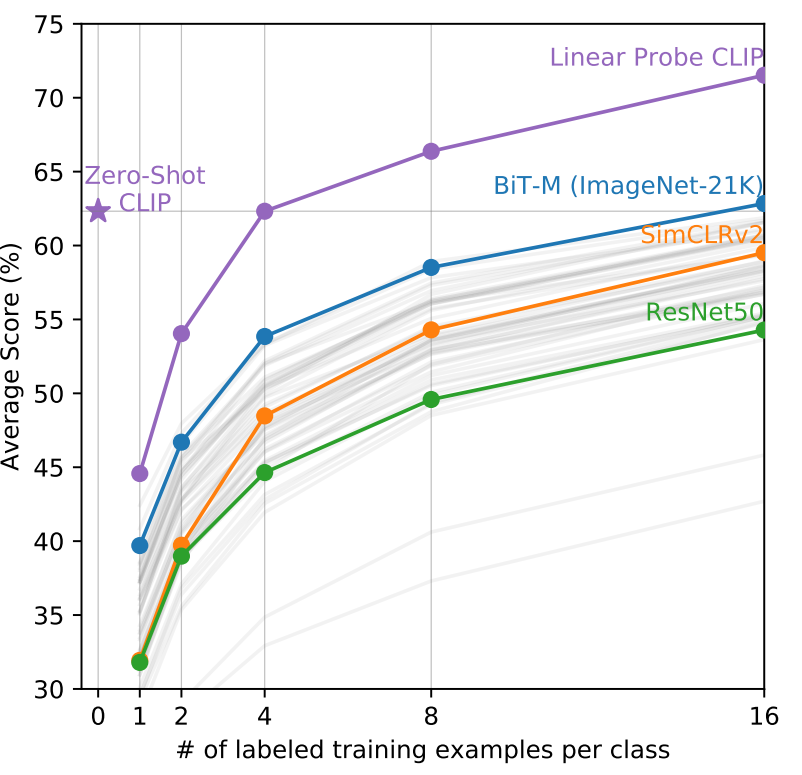
各データセット毎に、ゼロショット同等の精度を出すために必要なショット(=教師データ)の平均数を表示した図
(データセット毎に大きく効率が異なる(最大184~最小1以下)がわかりました)
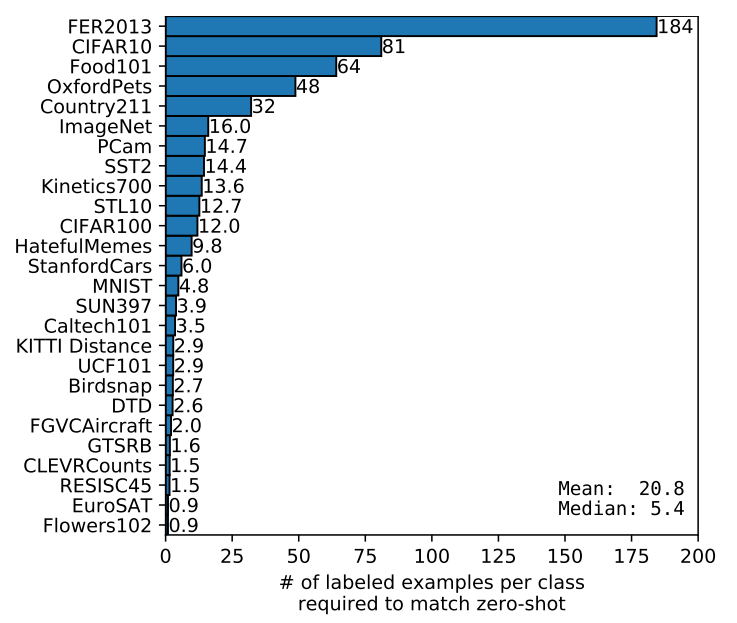
●CLIPのゼロショットと完全教師あり線形分類器の性能比較
評価データセットが十分に大きく、その上で訓練された線形分類器のパラメータが十分に推定されていると仮定すると、CLIPのゼロショット分類器も線形分類器であるため、完全教師付き分類器の性能(つまり、現在のSOTAモデル)は、ゼロショット転送が達成できることの上限を大まかに設定していると想定できます。
下図はCLIPのゼロショット性能と完全教師付き線形分類器の性能をデータセット間で比較したものです。破線のy = x線は、完全教師付き線形分類器と同等の性能を持つ「最適な」ゼロショット分類器を表しています。ほとんどのデータセットにおいて、ゼロショット分類器の性能は完全教師付き分類器を10%から25%も下回っており、CLIPのタスク学習能力とゼロショット転送能力を向上させるための余地がまだ十分にあることを示唆しています。
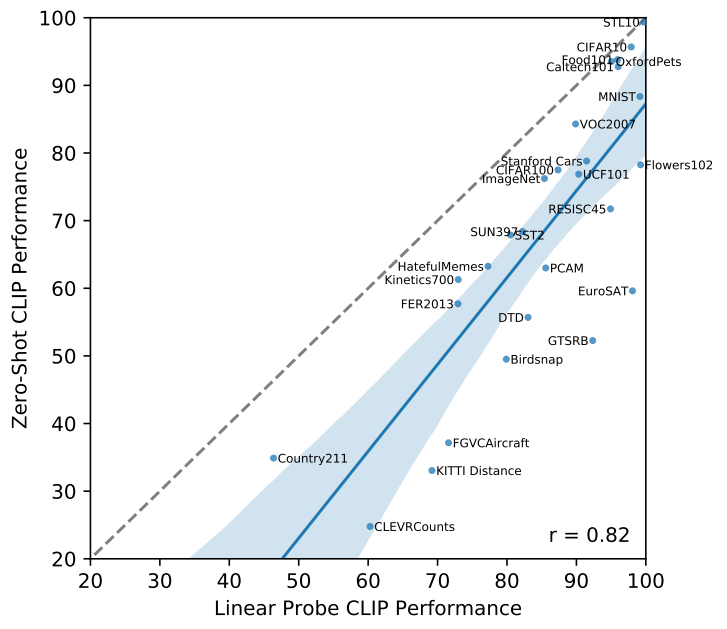
またCLIPはTransformer型のため、学習と精度の向上が比例関係にあると仮定できるはずですが、個々のタスクでは単純な比例関係にあるとはいえません(下図のうすい線が相当)。ただし、下図で示されているように全体の平均をとると、滑らかな比例関係がみえます。これは個々のタスクでは分散の違いなどがあり、ノイズになっていると推測されています。
●表現学習能力の比較
CLIPの表現学習の能力をはかるために、他のモデルと比べています。なお、現在、表現学習の能力を測る際には、事前学習に表現学習を利用してFine-tuningした際の精度向上から表現学習能力をはかる方法が一般的ですが、研究チームは単純な線形分類器を追加する旧来の手法で表現学習能力を計測しています。これはFine-tuningした際に、柔軟性・ロバスト性が追加され事前学習時の失敗が補われてしまい、事前学習本来の柔軟性・ロバスト性がわからなくなってしまうためです。
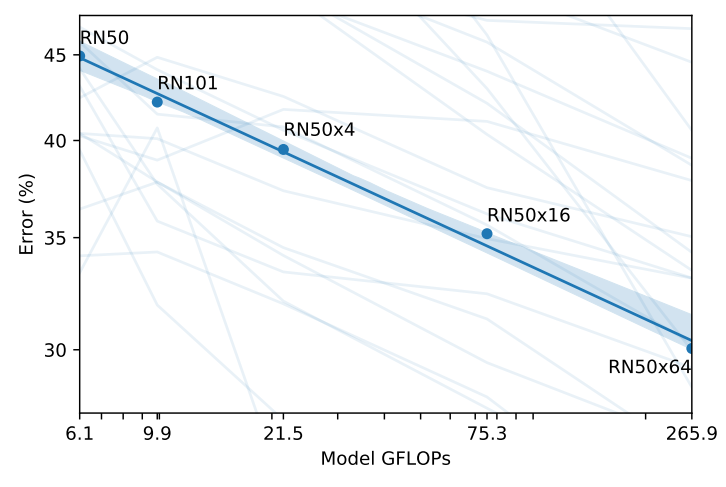
実験結果は、下図に示されているとおりです。小規模だとEfficientNetの方がCLIPよりも精度が高いものの、スケールを大きくすると他のモデルよりも精度が高くなることが確認されました。また、CLIPのベースとしては、ResNetよりもVisionTransformerを用いた方が3倍学習効率がいいこともわかりました。最高の総合モデルViT-L/14(データセットの336ピクセルの高解像度で1エポックを追加して微調整されたもの)は、評価群の中で、既存の最高のモデルよりも平均2.6%優れていることがわかりました。
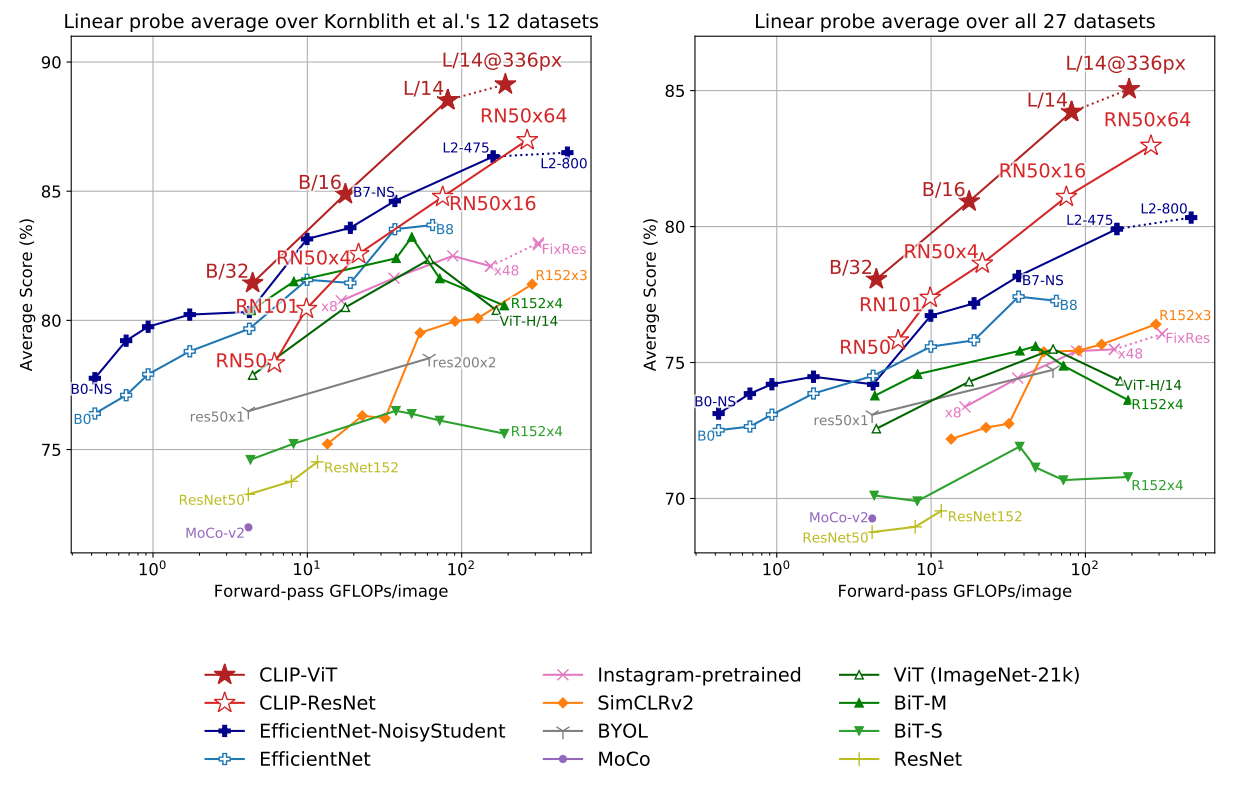
なお規模に関係なく、すべてのCLIPモデルは計算効率の点ですべてのモデルを上回りました。最優秀モデル(ViT-L/14)の平均スコアは、以前のモデルと比較して2.6%~5%向上しています。また、CLIP以外にも、より広範な評価スイートでは自己教師ありシステムの方が顕著に優れていることもわかりました。例えば、以前の研究で示されている12のデータセットによる計測ではSimCLRv2はBiT-Mを平均でまだ下回っていますが、今回の27のデータセットの評価スイートでは、SimCLRv2はBiT-Mを上回っています。これらの知見は、モデルの「一般的な」性能をよりよく理解するために、タスクの多様性とカバー率を拡大し続ける必要があることを示唆しています。また、VTABのような追加的な評価の試みも有用であると指摘しています。VTABはGoogleの研究チームが提唱している様々なタスクを行い総合的な表現力を評価する指標です。
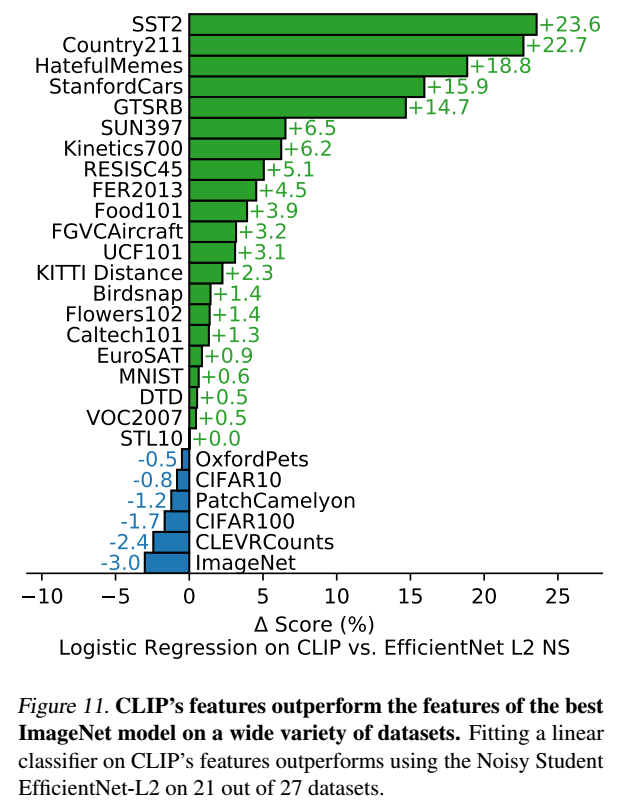
●ImageNetのSOTAモデルとの比較
ベストCLIPを利用して、各データセット毎に現在のImageNetをベースとして最も精度がよいモデル(Noisy Student EfficientNet-L2)と精度比較を行ったのが下の図です。27個のタスク中21個でCLIPの方がよい精度を出しました。対して、EfficientNetよりも最も精度がわるいものは、ImageNetであることがわかります。これはImageNetが視覚概念の狭い範囲しか反映していないという問題がある可能性があることを表しています。また、CIFAR系の画質が悪いものもCLIPが苦手にしていることがわかります。これはデータ拡張がCLIPでは行われていないことが原因ではないかと推測されています。
●現実世界でのロバスト性実験
実際の現実世界では、ベンチマークテストで計測されたほどの性能はだせないのが一般的です。原因はおそらくトレーニングデータの特徴をモデルが捉えすぎていることにあると考えられます。ImageNetに多くのモデルが最適化してしまっているという現状があり、既存の研究ではImageNetモデルが現実の分布シフトに対応できていないことが指摘されています。
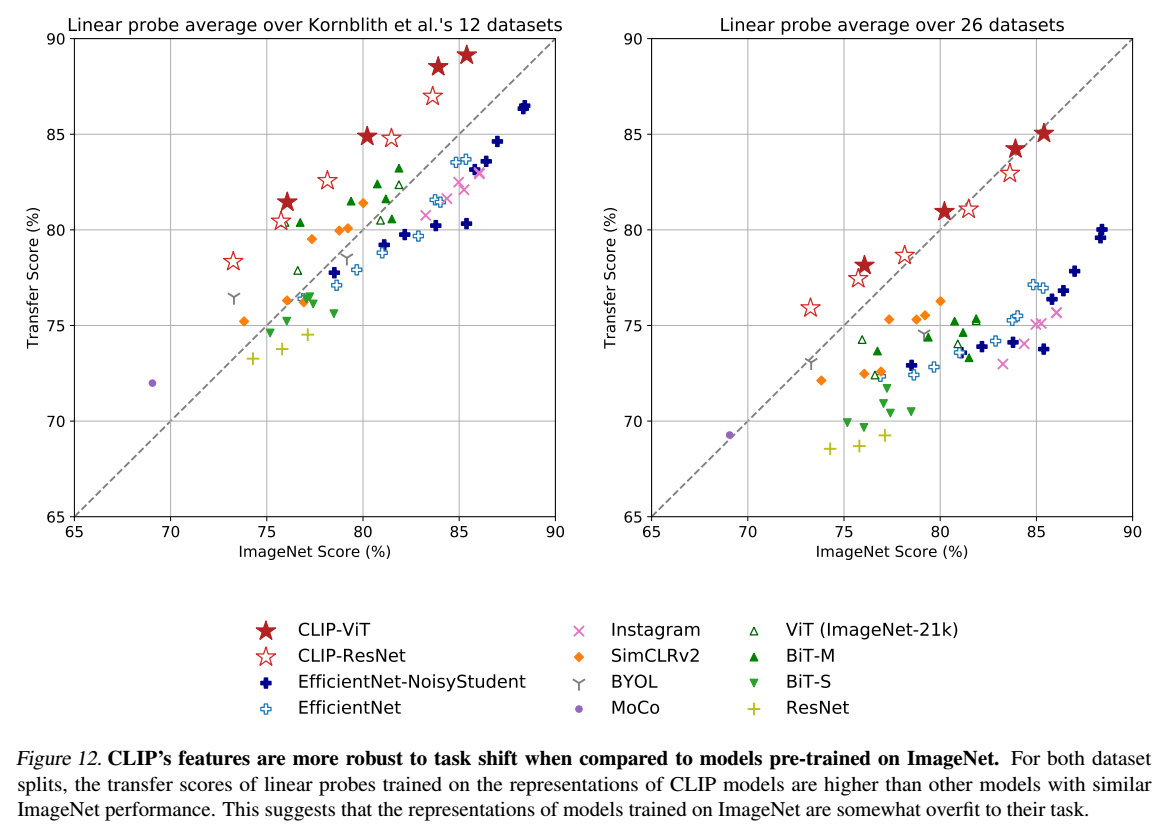
ResNet-101は、ImageNetの検証セットと比較して、現実の分布シフトで評価した場合、5倍のミスが発生しています。ただし既存の研究で、分布シフトの下での精度は、ImageNetの精度とともに増加し、ロジット変換された精度の線形関数としてよくモデル化できることが発見されています。この研究成果から、ロバスト性解析は有効ロバストネス(effective robustness)と相対ロバスト性(relative)に分けるべきとされています。有効ロバスト性は分布内精度と分布外精度の間の明示された関係によって予測される分布シフトの下での精度の改善を測定するものです。相対ロバスト性は、分布外精度の改善を捉えるものです。ロバスト性の技術は、有効ロバスト性と相対ロバスト性の両方を向上させることを目指すべきであると考えられています。

ゼロショット転移学習は、特定の分野に偏った学習はしていないため、ロバスト性が高いと考えられます。実際、CLIPとImageNetモデルを現実の分布シフト上で精度比較すると、すべてのゼロショットCLIPモデルは有効ロバスト性を大幅に向上させ、ImageNetの精度と分布シフト時の精度とのギャップの大きさを最大75%まで縮小させています。
より巨大で多様な事前学習用のデータセットの利用や自然言語の使用などからも、ゼロショットか微調整かにかかわらず、CLIPは従来よりもはるかに頑健なモデルとなる可能性があります。このことを確認する初期実験として、L2正則化ロジスティック回帰分類器を使ってImageNetの分布に適応させた後に、ImageNetのトレーニングセット上のCLIP特徴に適合させることで、CLIPモデルの性能がどのように変化するかを測定しています。
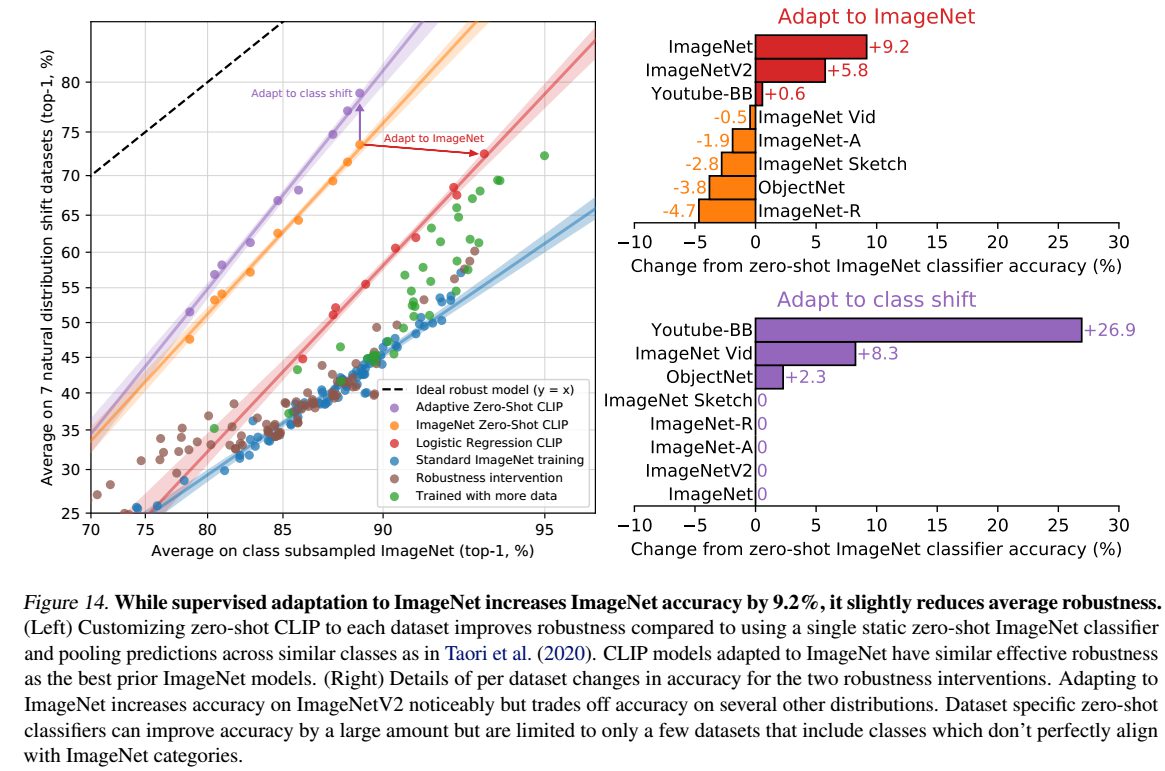
上図はゼロショット分類器から性能がどのように変化するかを可視化したものです。CLIPをImageNet分布に適応させることで、ImageNet精度は全体で9.2%増加して85.4%となり、Mahajanら(2018)の2018年SOTAの精度に匹敵しますが、分布シフトの下での平均精度はわずかに低下します。 精度が9.2%向上すること自体はSOTAの約3年間の改善に相当するため驚異的なことといえますが、分布シフト下での平均性能の向上には至らなかったということは問題です。
また、ゼロショット精度と線形分類器の精度の違いが図では示されていますが、1つのデータセット、ImageNetデータセットで9.2%の精度向上が可能なのに、分布シフトの下では精度がほとんど向上しない理由について明確な根拠は明らかに出来ていません。(「スプリアス相関を利用したためなのか」「CLIP、ImageNetデータセット、研究した分布シフトの組み合わせに特有のものなのか、より一般的な現象なのか」「線形分類器だけでなく、エンドツーエンドの微調整にも当てはまるのか」など多くのことが不透明なままになっています。)
ゼロショットCLIPは効果的なロバスト性を向上させますが、図では、完全教師あり設定ではその効果がほとんどなくなっていることも示されています。この違いをよりよく理解するために、ゼロショットから完全教師ありまでの連続体において、効果的なロバスト性がどのように変化するかを調査しています。
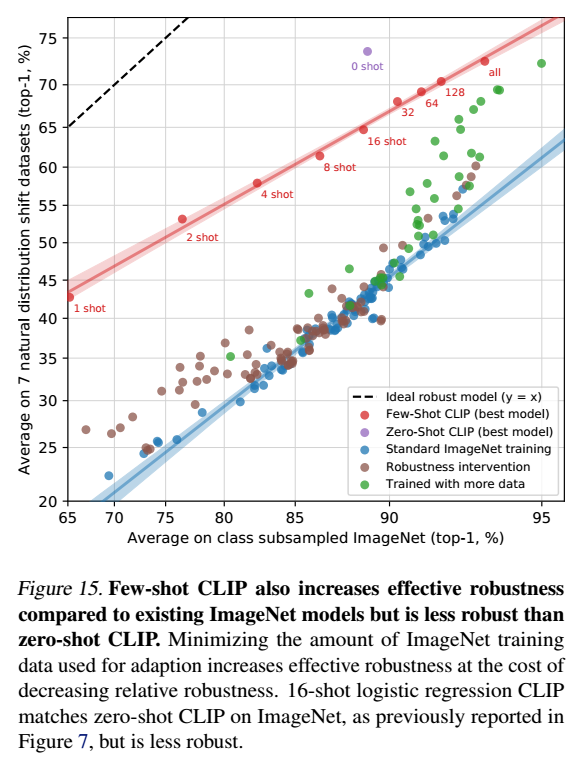
●ロバスト性の変化実験
ゼロショットから完全教師ありまでの連続体において、効果的なロバスト性がどのように変化するかを実験しています。下図から、ショット数が増えるごとにCLIP特有の効果的なロバスト性が失われていくことがわかります。(最終的にはほとんど失われています。)高い効果的なロバスト性は、モデルがアクセスできる分布固有のトレーニングデータの量を最小化することで得られることがわかりました。一方で、データセット固有の性能を低下させることにもなります。
人間のパフォーマンスとの比較
CLIPの論文では、CLIPの性能改善には直接関係ありませんが、ゼロショットや数ショット学習にどのような将来性があるか、という観点から、人間にもゼロショットや数ショットのタスク実験を行っています。人間にCLIPと同じ分類タスクを教師データなしの状態(=ゼロショット)で行ってもらい、その後1~2枚のサンプルを見せて改善度合いを計測します。(なおSTL-10データセットでは94%、注目チェック画像のサブセットでは97~100%という高い精度が得られ、人間の作業への信頼度が向上したことも合わせて報告されています。)
5人の異なる人間に、Oxford IIT Petsデータセットを用いて実験した。ゼロショット実験では、人間には犬種の例が与えられず、インターネット検索などせずにできる限りのラベル付けをしてもらいます。ワンショット実験では、人間は各品種のサンプル画像を1枚ずつ与えられ、ツーショット実験では、人間は各品種のサンプル画像を2枚ずつ与えられました。実験の懸念される点としては、ゼロショット実験では人間の作業者のモチベーションが十分ではなかったことが挙げられています。
成果に関しては、以下の図のようになりました。
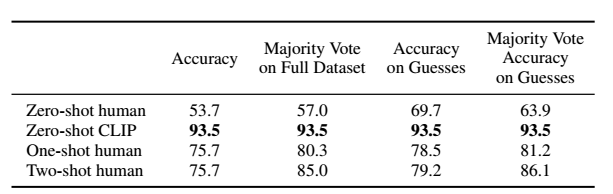
Oxford IIT Petsでの人間のパフォーマンスの比較。評価指標はクラスあたりの平均分類精度です。「Guesses」とは、参加者が「わからない」以外の回答を選んだ場合のデータセットに限定した精度を示し、「Majority Vote」とは、画像ごとに最も頻度の高い(同点を除く)回答を選んだ場合のことです。
人間は1クラスに1つのトレーニング例の追加(=ワンショット)で平均54%から76%に精度を大幅に向上できること、一方で追加のトレーニング例(=ツーショット)による精度の向上がほとんど確認できないという結果が得られました。ゼロからワンショットへの精度の向上は、最初は不確実だった画像のほとんどが対象となっています。これは、人間が「何がわからないかを知っている」ことを示唆しており、1つの例に基づいて最も不確実な画像の優先順位を更新することができることを示していると考えられます。
このことは、数ショットに対する学習の在り方に根本的な違いがあることを示していると考えられ、根本的なアルゴリズムの改善が今後の研究で必要になります。CLIPは少数ショット時に事前知識を有効に利用できていなう一方、人間は有効に利用していると考えられるため、事前知識を少数ショット学習に適切に統合する方法を見つけることが、CLIPのアルゴリズム改善の重要なステップであると推測されています。
高品質の事前学習モデルの特徴の上に線形分類器を使用することは、少数ショット学習のための最先端に近いものですが、最高の少数ショット機械学習手法と人間の少数ショット学習の間にギャップがあることを示唆しています。
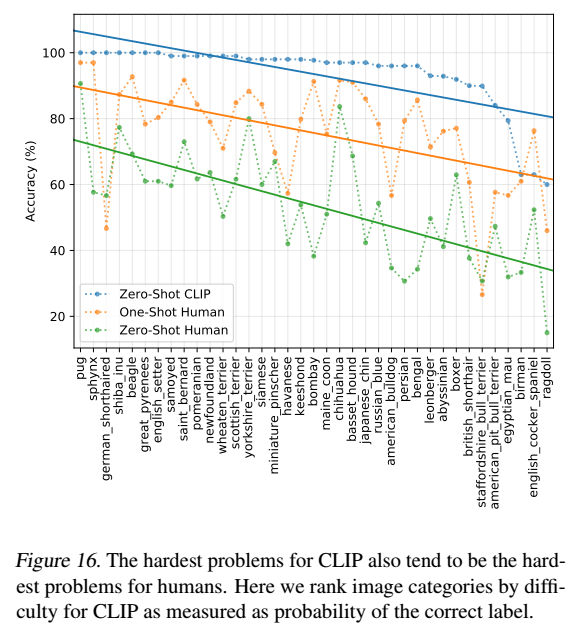
人間の精度とCLIPのゼロショット精度をプロットしたものが上図です。CLIPにとって最も難しい問題は人間にとっても難しいことがわかります。エラーが一貫している範囲では、⑴データセット内のノイズ(誤ラベル化された画像を含む)と、⑵分布外の画像が人間とモデルの両方にとって難しいことが原因であると考えられます。
利用データの重複についての分析
インターネットを経由して機械的に大量のデータセットで学習しているため、CLIPにはベンチマークテストで利用する検証用のデータを(先んじて)学習してしまっている危険性(=オーバーラップ)があります。評価データセットの完全なコピーが事前学習データセットに使われていることが最悪の場合であり、この時一般化のテストとしての評価が無効になります。
オーバーラップを防ぐための1つの方法は、モデルを訓練する前に、すべての重複を識別して削除することです。これにより、真のホールドアウト性能の報告が保証されることになりますが、一方でモデルを利用して評価する可能性のあるすべてのデータを事前に制限する必要があることを意味します。これは、ベンチマークと分析の範囲を制限するという問題を生み出します。新しい評価を追加すると、高価な再訓練が必要になったり、オーバーラップのために定量化されていない結果を報告するリスクが生じます。
リスクや問題が多いため、今回は重複したものを完全に削除する代わりに、「オーバーラップがどの程度発生しているのか」、また「オーバーラップによってパフォーマンスがどのように変化するのか」を明示することで対応します。
以下の手順に従て確認します
1) 各評価データセットについて、その例題に対して重複検出器を実行します。次に、発見された最も近いデータを手動で検査し、再現性を最大化しながら高精度を維持するために、データセットごとにしきい値を設定します。このしきい値を使用して、2つの新しいサブセットを作成します。ここで、Overlapは「しきい値以上の訓練例とそれと類似性を持つすべての例」を指し、Cleanは「しきい値以下のすべての例」を指します。また変更されていない完全なデータセットをAllとします。データの汚染度を、Overlap と All の比として記録します。
2) 次に、3つに分けられたデータ上でCLIP(RN50x64)によるゼロショット精度を計算し、指標All – Cleanとして報告します。これは汚染による精度の差を示します。正の場合は、データセットで報告された全体的な精度が、重複するデータにオーバーフィットすることでどれだけ改善されたかの推定値を意味します。
3) 重複の量が小さいことが多いため、二項有意性検定も実行します。帰無仮説としてCleanでの精度を使用して、Overlapサブセットの片側(大きい方)のp値を計算します。また、もう1つのチェックとして、Dirtyでの99.5% Clopper-Pearson信頼区間を計算します。
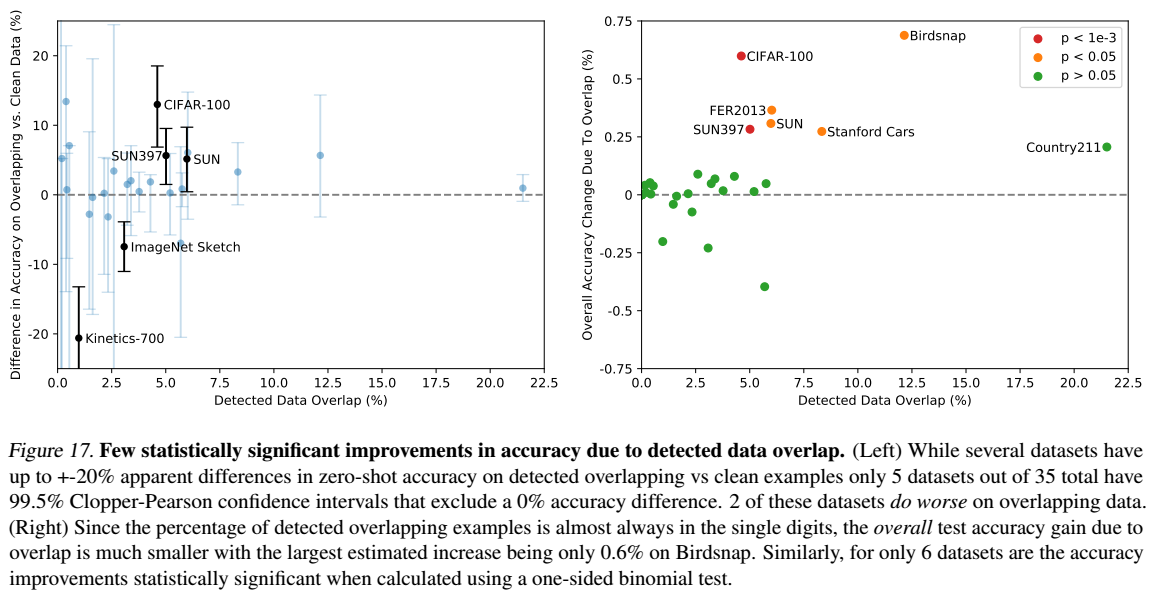
調査結果が上図になります。調査した35個のデータセットのうち、9個のデータセットではオーバーラップが全く検出されませんでした。これらのデータセットの多くは、合成データや特殊なデータセットであるため、インターネット上で通常の画像として公開される可能性が低い(MNIST、CLEVR、GTSRBなど)か、あるいは、学習に利用したデータセット(WIT)が作成された日以降の新しいデータ(ObjectNetやHateful Memes)が含まれているため、オーバーラップがないことが保証されています。
また、オーバーラップしているものに関しても、そのことによる精度の大幅な向上は確認されなかったため、大きな問題にはならないと考えられます。
ただし、この分析には2つの潜在的な懸念があることが報告されています。
第一に、検出器が完全でないという懸念です。代理学習タスクでは100%に近い精度を達成しており、手動検査と閾値の調整により、非常に高い精度と、発見された最も近いものの中での良好な再現性が得られますが、4億個の例の中では再現性を確認することはできませんでした。
もう一つの潜在的な懸念は、基礎となるデータ分布がオーバーラップサブセットとクリーンサブセットの間でシフトする可能性があることです。(例えば、Kinetics-700では、多くの「オーバーラップ」は実際にはすべて黒の遷移フレームです。これがKinetics-700でオーバーラップの精度が20%低下した理由であると考えられます。)実際には、もっと微妙な分布の変化があるのではないかと考えられます。もしくは精度の変化は、複製された画像のクラス分布や難易度の変化によるものかもしれませんが、このような分布や難易度の変化は、オーバーフィットの影響を覆い隠してしまっている可能性があります。
限界
CLIPは多くの分野で優れた成果を出しましたが、一方で限界も認識されています。
●SOTAに匹敵する精度の向上
現在はResNetをベースにしてないSOATモデルが各タスクごとにあります。すべてのタスクでSOATの結果を出そうとした場合、CLIPのタスク学習能力と転移学習能力を向上させる作業が大幅に必要です。これまでのところスケーリングによって性能は着実に向上しており、継続的な改善の道筋が示唆されていますが、ゼロショットCLIPが全体的に最先端の性能に到達するには、約1000倍の計算量の増加が必要であると推定されています。これは現在のハードウェアで訓練するには無理があります。CLIPの計算効率とデータ効率を向上させる必要があります。
●特定タスクでの精度向上
CLIPのゼロショット性能はいくつかの種類のタスクではまだかなり弱いことが明らかになっています。
⑴細かい分類タスク
自動車、花、航空機の種別などの細かい分類タスク。
⑵抽象的で体系的なタスク
画像内のオブジェクトの数を数えるような、より抽象的で体系的なタスク。
⑶データセットに含まれないような新しいタスク
写真の中で最も近い車までの距離を分類するなど、CLIPの事前学習データセットには含まれていないであろう新しいタスク。(性能がほとんどでたらめに指し示した程度しかないタスクです。このようなCLIPのゼロショット性能が確率レベルに近いタスクは、まだまだたくさんあるとされています。)
●一般化能力の向上
ゼロショットCLIPは、多くの自然な画像分布に対して一般化していますが、それでもまだ対応していない画像分に対しては一般化しにくいことがわかりました。
例えば、CLIPは高精度のOCRが可能ですが、これはデジタルテキストに限定されたものです。MNISTの手書き数字に対しては88%の精度しか達成していません。なお、これは単純なロジスティック回帰モデルよりも精度が低い結果です。事前学習データセットにはMNISTの数字に似た画像がほとんどないことが確認されました。
このことは、CLIPがディープラーニングモデルが持つ脆弱な一般化という根本的な問題の解決策を提示しているわけではないことが示唆されています。その代わりにCLIPでは、大規模で多様なデータセットで学習することで、すべてのデータが効果的な分布内に収まることを目指したといえます。ただし、これは(MNISTが実証したように)簡単に崩壊してしまうナイーブな仮定です。
●分類以外への応用(キャプションの生成など)
CLIPは多様なタスクやデータセットに対して柔軟にゼロショット分類器を生成することができますが、それでも与えられた概念からのみ選択することに制限されています。これは、新しい出力を生成できる画像キャプションのようなモデルと比べると、大きな制限であることがわかります。
利用価値CLIP の効率とキャプションモデルの柔軟性を組み合わせることを期待して、対照的目的語と生成目的語の共同訓練を行うことです。別の代替案として、与えられた画像の多くの自然言語説明にわたって推論時間に検索を実行することができます。
●データ効率の悪さ
CLIPは、ディープラーニングモデルがもつデータ効率の悪さには対処できていません。その代わりに、訓練データを大きくスケールすることでデータ効率の悪さを補償しています。しかし、これには計算時間が増幅するという問題が常につきまといます。(もしCLIPモデルの訓練中に利用されたすべての画像が1秒に1枚の割合で処理されたとすると、32の訓練エポックで利用された128億枚(4億×32)の画像を反復処理するのに405年かかることになります。)
CLIPを自己教師あり学習および自己学習手法と組み合わせることで、標準的な教師あり学習よりもデータ効率を向上させる能力ことが期待されます。
●方法論の問題
ゼロショット転移に焦点を当てているにもかかわらず、CLIPの開発を導くために、完全な検証セットでの性能測定を繰り返し行っています。これらの検証セットには多くの場合、数千の例があり、これは現実のタスクで真のゼロショットを計測する場合に期待できる検証セットの数ではありません。
もう一つの課題は、評価データセットの選択です。既存研究に基づく12のデータセット評価スイートを標準化したコレクションとして結果を報告していますが、CLIPの開発と能力との共同適応であることは否定できない27のデータセットの(やや行き当たりばったりに組み立てられた)コレクションを使用しているともいえます。既存の教師付きデータセットを再利用するのではなく、幅広いゼロショット転送能力を評価するために明示的に設計されたタスクの新しいベンチマークを作成することが求めらています。
●データの問題
利用したデータは厳密なフィルタリングなどがされていないため、多くの社会的バイアスを含んだ状態です。そのため、CLIPは社会的バイアスを学習してしまっています。
●自然言語による画像分類の限界
多くの複雑なタスクや視覚的な概念を自然言語だけで指定するのは難しいと考えられます。このことがゼロショットと数ショットの間にある一時的なパフォーマンスの低下につながっていると考えられます。CLIPの強力なゼロショット性能と効率的な少数ショット学習を組み合わせた手法の開発が求められています。
社会的インパクト
CLIPは、再訓練を必要とせずに、分類のための独自のクラスを簡単に作成することができます(「独自の分類器をロールできる」)。この能力は、GPT-3のような他の大規模な生成モデルを特徴づける際に見られるものと似たような課題に対して対峙する必要があります。以下の二つの事項に対して与える社会的インパクトについて分析しました。
⑴バイアス
この論文で研究した30以上のデータセットに加えて、FairFaceベンチマークでCLIPの性能を評価し、探索的なバイアス証明を実施しました。
⑵監視
タスクのひとつである「監視」におけるモデルの性能を特徴づけ、他の利用可能なシステムと比較してその有用性を議論します。CLIPの機能の多くは、本質的に一般的に有用なものなものですが、測定された能力のいくつかは、行動認識、物体分類、ジオローカリゼーションから顔の感情認識まで一般市民に有用でない「監視」に使用することができるためです。
●バイアス
アルゴリズムの決定、トレーニングデータ、およびクラスがどのように定義され分類されるかについての選択(これを論文では「クラスデザイン」と呼びます)はすべて、AIシステムの使用から生じる社会的なバイアスや不平等に寄与し、増幅する可能性があります。特にクラスデザインは、CLIPのようなモデルでは、自由にクラスを定義することができるため、重要になります。
CLIPにおけるバイアスのいくつかの予備的な分析を提供します。モデル内のバイアスの具体的な例を見つけることを目的とした探索的バイアス調査を実施します。顔画像データセットFairFace上でのゼロショットCLIPの性能を分析することから始め、クラスデザインを含む追加のバイアスとバイアスの発生源を表面化するためにモデルをさらに明らかにします。
FairFaceのデータセット上で2つのバージョン「ゼロショットCLIPモデル(ZS CLIP)」と、CLIPの特徴量の上にFairFaceのデータセットにフィットした「線形回帰分類器(LR CLIP)」の性能を確認しました。
LR CLIPが、実行したほとんどの分類テストにおいて、ResNext-101 32x48d InstagramモデルとFairFace独自のモデルの両方よりも高い精度を得ていることを明らかにしました。一方で、ZS CLIPのパフォーマンスはカテゴリによって異なり、いくつかのカテゴリではFairFaceのモデルよりも悪く、他のカテゴリでは良くなっています。
さらに、FairFaceデータセットで定義されている交差する人種と性別の分類について、LR CLIPとZS CLIPモデルの性能を検証しました。性別分類に関するモデル性能は、すべての人種カテゴリで95%以上であることがわかりました。
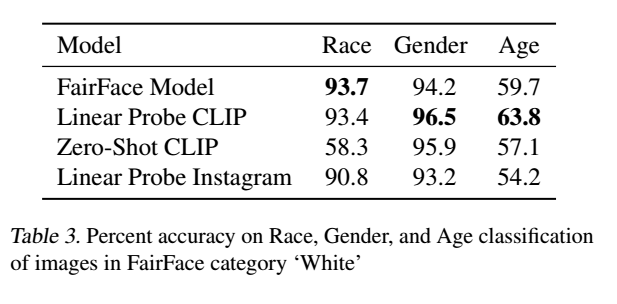
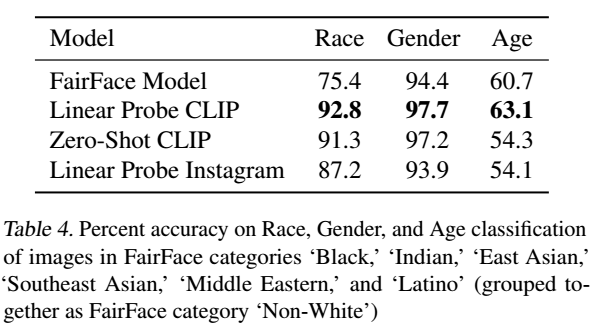
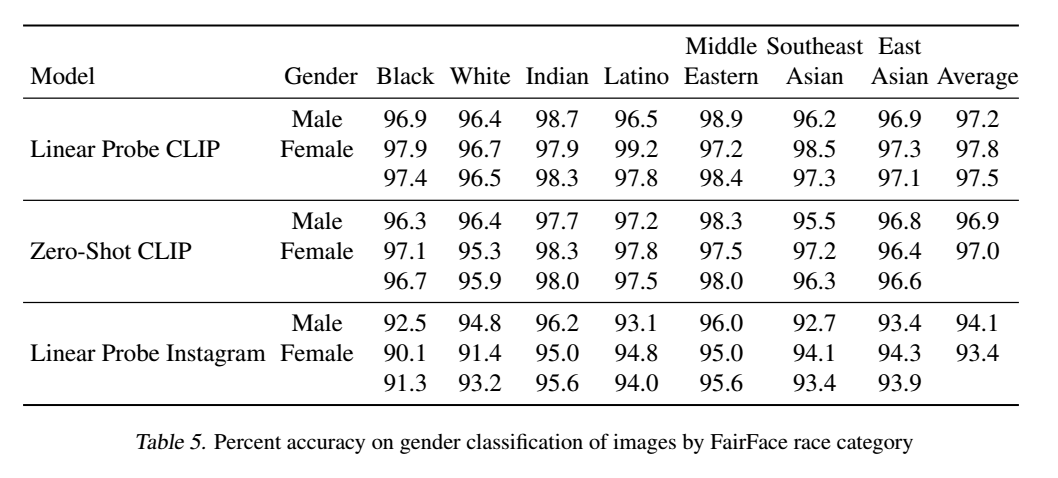
LR CLIPは、FairFaceベンチマークデータセットにおいて、画像の性別、人種、年齢の交差カテゴリ別分類においてLinear Probe Instagramモデルよりも高い精度を達成しています。しかし、ベンチマークでの精度はアルゴリズムの公平性の1つの近似値に過ぎず、実世界の文脈での公平性の意味のある尺度としては失敗することが多いことが既存の研究で指摘されています。モデルの精度が高く、異なるサブグループに対するパフォーマンスの格差が低い場合でも、インパクトの格差が低くなるわけではありません。
バイアスを探るための顔分類ベンチマークの使用は、顔分類が問題のない作業であることを暗示するものではなく、また配備されたコンテキストでの人種、年齢、性別の分類の使用を推奨することを意図したものでもないことが明言されています。
また、表現が差別的である分類用語(いわゆるヘイト表現)を用いてモデルを検証しています。
実験
FairFaceのクラスに加えて、「動物」、「ゴリラ」、「チンパンジー」、「オランウータン」、「泥棒」、「犯罪者」、「不審者」という不適切なクラスを追加して、FairFaceデータセットから1万枚の画像を分類します。
結果
4.9%(信頼区間4.6%~5.4%)の画像が、人間以外のクラス(「動物」、「チンパンジー」、「ゴリラ」、「オランウータン」)のいずれかに誤って分類されていることがわかりました。これらの中で、「黒人」画像の誤分類率が最も高かった(約14%、信頼区間は[12.6%~16.4%])のに対し、他のすべての人種の誤分類率は8%未満でした。0~20 歳の人は、このカテゴリーに分類される割合が最も高く、14%でした。
また、男性画像の16.5%が犯罪に関連したクラス(「泥棒」、「不審者」、「犯罪者」)に誤分類されていたのに対し、女性画像では9.8%でした。異なる年齢層の人の画像(20~60歳では約12%、70歳以上では0%)と比較して、0~20歳の人の方が犯罪関連のクラスに分類される可能性が高いことがわかりました(約18%)。また犯罪関連用語については、人種間での分類に有意な格差が見られました。
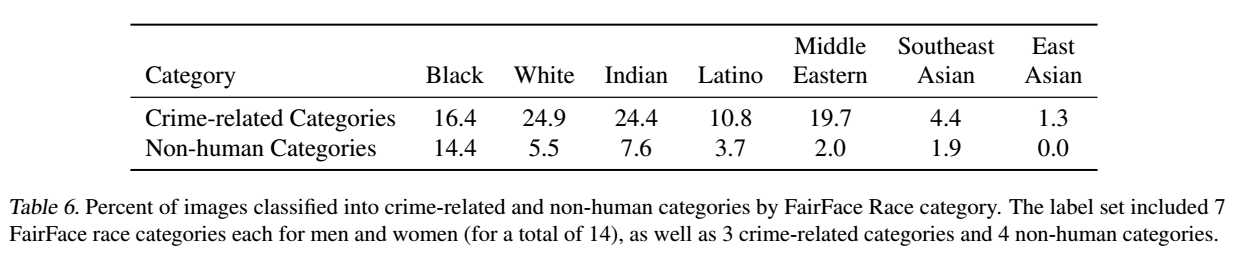
20歳未満の人が犯罪関連と非ヒト動物の両方のカテゴリに分類される可能性が最も高いことが観察されたため、追加カテゴリがモデルの分類を変え、年齢別にヘイトをシフトさせるかどうかを確認します。
実験
同じクラスに「子供」というカテゴリを追加して画像分類実験を行いました。
結果
20歳未満の人の画像が、犯罪関連のカテゴリーもしくは非人間カテゴリーに分類される数が劇的に減少することがわかりました。
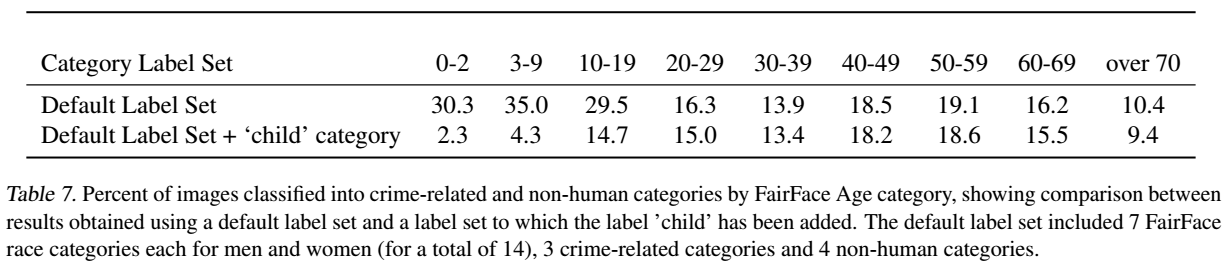
このことは、クラスデザインがモデルの性能とモデルが示す可能性のある不要なバイアスや行動の両方を決定する重要な要因となる可能性があることを示唆しています。一方で、そもそもこのようなラインに沿って人を自動的に分類するための顔画像の使用そのものが議論されるべきであるともいえます。
ラベルのしきい値を決定するなどの追加のモデルデザインが、出力するラベルにどのような影響を与え、バイアスがどのように現れるかを明らかにします。利用したデータセットは以下の3つになります。
⑴性別ラベルデータセット(議員の画像)
⑵職業ラベルデータセット(約300の職業)
⑶画像ラベルデータセット(Google Cloud Vision、Amazon Rekognition、Microsoft Azure Computer Visionが画像に対して付与しているラベル)
⑴性別ラベルデータセット(議員の画像)
議員の画像(Members of Congressデータセット)についてモデルの性別予測性能を簡単に調べました。その結果、モデルは100%の精度で画像を認識できることがわかりました。(これは、FairFaceデータセットにおけるモデルの性能よりもわずかに優れています。)理由の一つは、FairFaceデータセットとは異なり、データセットの画像がすべて高品質で鮮明で、人物が中央にはっきりと配置されていたことにあると考えられます。
⑵職業ラベルデータセット(約300の職業)
返されたラベルのバイアスがラベル確率のしきい値にどのように依存するかを調べるために、閾値を0.5%と4.0%に設定した実験を行いました。その結果、閾値が低いほどラベルの質が低いことがわかりました。
しかし、この閾値の下ではラベルの分布が異なっていても、バイアスのシグナルを保持することもできます。例えば、0.5%のしきい値では「乳母」や「家政婦」のようなラベルが女性に出現し、「囚人」や「暴力団員」のようなラベルが男性に出現することがわかりました。より高い4%のしきい値では、男女をまたいで最も確率の高いラベルは、「法律家」、「立法者」、「議員」を含みます。しかし、低い確率でもラベルの中にこれらのバイアスが存在することは、システムを展開するための「十分に」安全な行動とはどのようなものかについてのより大きな疑問を示唆しています。
⑶画像ラベルデータセット(Google Cloud Vision、Amazon Rekognition、Microsoft Azure Computer Visionが付与しているラベル)
髪や外見に関するラベルを男性よりも女性に不釣り合いに付けていることがわかりました。例えば、「茶髪」、「金髪」、「ブロンド」などのラベルは、女性の方がかなり頻繁に表示されていました。さらに、CLIPは「エグゼクティブ」や「ドクター」など、ステータスの高い職業を表すラベルを男性に多く付けていました。唯一女性に多いとされた4つの職業のうち、3つは「ニュースキャスター」、「テレビ司会者」、「ニュースリーダー」で、4つ目は「裁判官」でした。なお、このラベルのセットに対して閾値を0.5%に下げると、男性を記述するラベルは「スーツ」、「ネクタイ」、「ネクタイ」などの外見重視の単語にもシフトしていることがわかりました。「軍人」や「幹部」のような職業志向の言葉が多く、4%の高い閾値では女性のイメージを記述するのに使われませんでしたが、0.5%の低い閾値では男女ともに使われており、これが男性のラベルの変化の原因となった可能性があります。また女性に同じような変化は現れませんでした。女性を描写するために使われる記述的な言葉は、男性ではまだ珍しいものであったと考えられます。
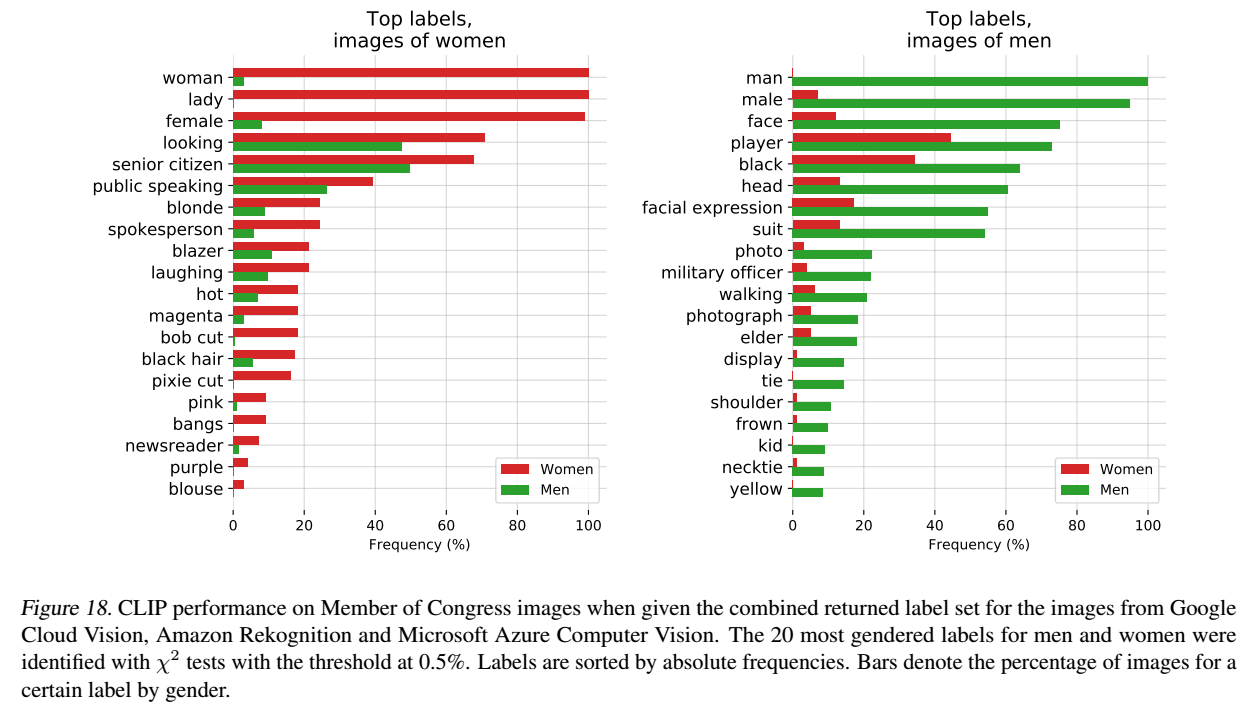
・総括
モデル構築のあらゆる段階でのデザイン決定は、バイアスがどのように現れるかに大きく影響を与えます。そして、これはカテゴリーを自由に設定できるCLIPの柔軟性を考えると特に強く当てはまります。クラスデザインやしきい値などの決定は、モデルが出力するラベルを変化させ、ある種の害を高めたり低めたりすることがあります。クラスデザインの決定は、モデルの性能だけでなく、モデルのバイアスがどのように、どのような文脈で顕在化するかについても重要な決定要因となります。これらの実験は包括的なものではありません。これらの実験は、クラス設計やその他のバイアスの発生源に起因する潜在的な問題を説明しており、質問を喚起することを意図しています。
●「監視」
次に、社会的に重要な「監視」に関連するタスクに対して、モデルの性能を特徴づけることを試みました。分析の目的は、上述した特性化アプローチをより具体化し、今後ますます汎用化していくコンピュータビジョンモデルの潜在的な影響を研究コミュニティに伝え、そのようなシステムに関する規範やチェックの開発を支援することにあります。
監視カメラ(CCTVカメラなど)から撮影された低解像度の画像でモデルの性能をテストしました。
結果
どのような人や物がいるかなどの粗い大まかな分類では、モデルの精度は91.8%というトップ1の精度を持っていることがわかりました。一方で、より細かく画像内の物体の有無を判定する検出では、ゼロショットモデルの性能は低く、結果はランダムに近いものでした。
有名人の写真を利用して、身元検出に対するモデルの性能を評価しました。
※仮説
インターネット上の画像の数が多い有名人のデータセットでテストしていますが、モデルが顔と名前を関連付けるために必要な事前学習データの画像の数は、モデルがより強力になるにつれて減少し続けるという仮説のもと行われています。これは自然言語処理における最近の発展を反映したもので、インターネットデータ上で訓練された最近の大規模な言語モデルは、比較的マイナーな公人に関連する情報を提供できることが確認されています。
結果
100クラス内では59.2%のトップ1の精度を持っていることを発見しました。しかし、クラスサイズを1kに増やしたとき、この性能は43.3%に低下しました。(この性能は、Googleのセレブリティ認識(Google)のような本番レベルのモデルと比較した場合、競合することができるレベルにはありません。)ただし、ゼロショット識別能力のみでの精度としては十分高いといえます。
・総括
CLIPは、データが比較的少ないタスクには大きなメリットがあるといえますが、顔認識などのタスクでは、大規模なデータセットと高性能な教師ありモデルが存在しており、CLIPは利用するメリットが低いモデルです。
しかし、CLIPは訓練データが少ない特定の監視ユースケースを可能にし、そのようなアプリケーションを構築するためのスキル要件を低下させる可能性があります。
●今後の取り組み
この予備的な分析は、汎用コンピュータビジョンモデルが直面する課題のいくつかを説明し、その偏りや影響を垣間見ることを目的としています。この作業が、このようなモデルの能力、欠点、バイアスの特性化に関する将来の研究の動機付けになることを期待しています。私たちは、CLIPのようなモデルの能力をさらに特徴づけるためのコミュニティの探究が良い一歩になると信じていますし、重要なのは、CLIPが有望な性能を持っているアプリケーション分野と、性能が低下する可能性のある分野を特定することです。このような特徴付けのプロセスは、研究者がモデルが有益に利用される可能性を高めるのに役立ちます。
⑴研究プロセスの早い段階でモデルの有益な下流利用の可能性を特定し、他の研究者が応用を考えることができるようにする。
⑵重要な感度を持ち、多くの社会的利害関係者が存在する課題を明らかにする。(政策立案者の介入を必要とする可能性がある。)
⑶モデルのバイアスの特徴をよりよく把握し、他の研究者に懸念される分野や介入すべき分野を警告する。
⑷CLIP onのようなシステムを評価するための一連のテストを作成することで、開発サイクルの早い段階でモデルの能力をよりよく特徴づけることができます。
⑸潜在的な故障モードと今後の作業領域を特定する。
まとめ
CLIPは画像分類モデルとして、カテゴリーを利用者側で自由に設定できることで、新たな汎用利用の可能性を開いたと言えます。この高い汎用性を誇ることを考えると、CLIPの特性を理解し、うまく扱えるようになることで、色々なタスクを一定程度の精度で労力をかけずに利用できる可能性もあります。ただし、実際にタスクを遂行する上では、SOTAモデルがタスクごとに存在するということも念頭にいれる必要があります。常に精度が高いモデルを望まれる環境・タスク化では利用するメリットが低いということもいえます。
CLIPはGPT以来の巨大化=精度向上を新たに示したモデルであり、今後もモデルの巨大化は止まらないと考えられます。このことはより巨大企業や資金力のある研究機関が強力な存在であり続けることを意味します。今回のOpenAIも資金力の問題からMicrosoftの協業を開始し、それ故に発足当初の市民のためのAIなどの姿勢が疑われています。しかし、CLIPに関してはソースコードや重みも公開しており、今後も研究成果を開かれたものにしてくれることを期待しています。