「Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models」という論文は、OpenAIの大規模言語モデルChatGPTと同様に高度な視覚タスクを処理できるようになった、新しいモデルであるVisual ChatGPTについてまとめたものです。このモデルは、自然言語処理とコンピュータビジョンを融合させることによって、テキスト、絵画、写真などの視覚的な情報を扱うことができます。Visual ChatGPTは、人間のように自然な対話を行い、同時に、画像の生成や編集などのタスクにも対応しています。この論文は、Visual ChatGPTのアーキテクチャと性能について詳細に説明し、将来的な展望についても論じています。
基本情報
参照URL:https://arxiv.org/abs/2303.04671
PDF版は以下を参考下さい。
- 1. イントロダクション
- 2. 関連研究
- 3. Visual ChatGPT
- 4. 実験
- 5. 制限事項
- 6. 結論
イントロダクション
近年、大型言語モデル(LLMs)の開発は驚くべき進歩を遂げており、その中でも特にChatGPTは、InstructGPTをベースに構築され、一般的な会話方式でユーザーと対話するように訓練されたことで、現在の会話の文脈を維持し、フォローアップ質問を処理し、それ自体が生成した答えを修正することができるようになりました。
ただし、ChatGPTは単一の言語モダリティでトレーニングされているため、視覚情報の処理能力に限界があります。一方、Visual Foundation Models(VFMs)は、コンピュータビジョンにおける膨大な可能性を持ち、LIP ModelやStable Diffusionなどは共に画像を理解と合成を行うエキスパートです。しかし、タスク仕様の性質上、入出力形式が固定されているため、VFMは人間と機械の対話における会話型言語モデルよりも柔軟性に欠けるという課題があります。
そこで、ChatGPTのようなシステムを拡張し、画像の理解と生成をサポートするシステムを作成することを目指します。マルチモーダルな会話モデルを学習させるという直感的なアイデアもありますが、そのようなシステムを構築するには大量のデータと計算資源が必要であり、言語や画像だけでなく、動画や音声などのモダリティも取り込みたい場合にはさらに課題があります。
本論文では、ChatGPTを直接基盤として、新しいマルチモーダルシステムであるVisual ChatGPTを構築し、さまざまなVFMsを組み込むことを提案します。これにより、人間と自然な対話を行いながら、画像の生成や編集などのタスクを行うことができるようになります。
また、ChatGPTとVFMsとの間のギャップを埋めるために、Prompt Managerが次の機能をサポートすることを目指しています。
1)各VFMの能力をChatGPTに明示的に伝え、入力-出力形式を指定します。
2)異なる視覚情報(例えばpng画像、深度画像、マスク行列)を言語形式に変換してChatGPTが理解できるようにします。
3)Prompt Managerは異なるVisual Foundation Modelsの履歴、優先順位、競合を処理します。
ChatGPTはPrompt Managerの助けを借りて、これらのVFMsを活用し、反復的にフィードバックを受け取ることができます。これにより、ChatGPTは視覚情報を含む多様なタスクに適応できるようになります。
関連研究
2.1. 自然言語とビジョン
言語と視覚は、様々なモダリティ(音、視覚、映像など)に囲まれた現代の生活において、情報を伝達する2つの主要な媒体です。自然言語と視覚は自然なリンクがあり、満足のいく結果を得るためには、この2つの流れの共同モデリングが必要です。
例えば、視覚的質問応答(VQA)は、画像とそれに対応する1つの質問を入力として受け取り、与えられた画像内の情報に基づいて回答を生成することが求められます。
大規模言語モデル(LLMs)の成功により、InstructGPTなどのモデルとの対話や自然言語形式でフィードバックを得ることができるようになりましたが、これらのモデルは視覚情報を処理することができません。視覚処理能力をLLMsに融合させるためには、大規模な言語モデルや視覚モデルを訓練することが困難であり、適切に設計された指示や面倒な変換が必要です。そのため、LLMsに視覚処理能力を融合させるためには、いくつかの課題があります。
いくつかの作品は、事前学習されたLLMsを活用してVLタスクのパフォーマンスを向上させることを探求していますが、これらの方法は特定のVLタスク(言語から視覚または視覚から言語)をサポートし、訓練にラベル付きデータが必要です。
2.2. VL タスクのための事前学習済みモデル
視覚的な特徴をよりよく抽出するために、初期の作品では事前学習された画像エンコーダーが採用されており、最近のLiTではCLIP事前学習モデルや学習済みViTモデルが適用されています。また、LLMsから知識を活用することも重要です。事前学習されたLLMsは強力なテキスト理解および生成能力を示しており、VLモデリングでは、視覚特徴をテキスト空間に合わせるために、事前学習済みLLMsに追加アダプタモジュールを追加しています。ただし、モデルパラメーターの数が増えると、事前学習されたLLMsを訓練することが難しくなるため、VLタスクに事前訓練されたLLMを直接活用する取り組みがなされています。
2.3. VLタスク用プレトレーニングLLMsのガイダンス
複雑なタスクとして、例えば、常識的な推論を対処するために、LLMsの多段階推論能力を引き出すChain-of-Thought(CoT)が提案されています。具体的には、CoTはLLMsに最終結果のための中間回答を生成するよう求めています。既存の研究は、この技術をFew-Shot-CoTとZero-Shot-CoTの2つのカテゴリーに分類しており、Few-Shot-Cotでは、LLMsがCoT推論を行い、LLMsが複雑な問題を解決する能力をよりよく獲得できることがわかりました。さらに、LLMsがゼロショット設定下で自己生成された根拠を活用して自己改善できることが示されています。
これまでの研究は主に言語モダリティに焦点を当てたものでしたが、近年、言語と視覚モダリティを組み合わせたMultimodal-CoTが提案され、根拠生成と回答推論を分離した2段階フレームワークが提案されています。しかし、この方法は特定のシナリオ下でのみ優位性を示すことが分かっており、本研究ではCoTの可能性を大量のタスクに拡張しています。具体的には、テキスト-画像生成、画像-画像変換、画像-テキスト生成などが含まれます。
Visual ChatGPT
Visual ChatGPTの概要
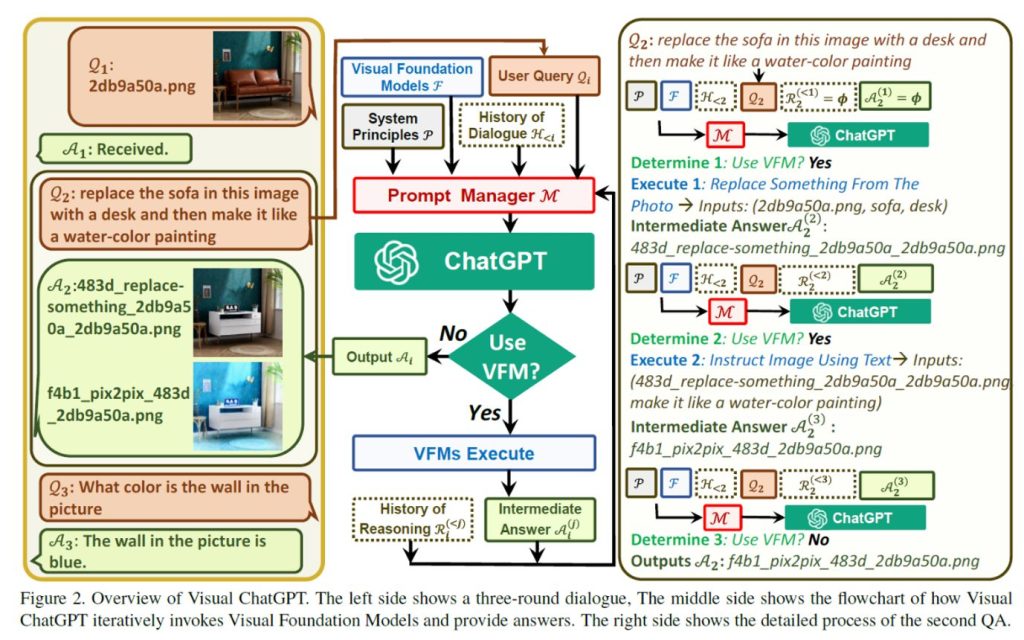
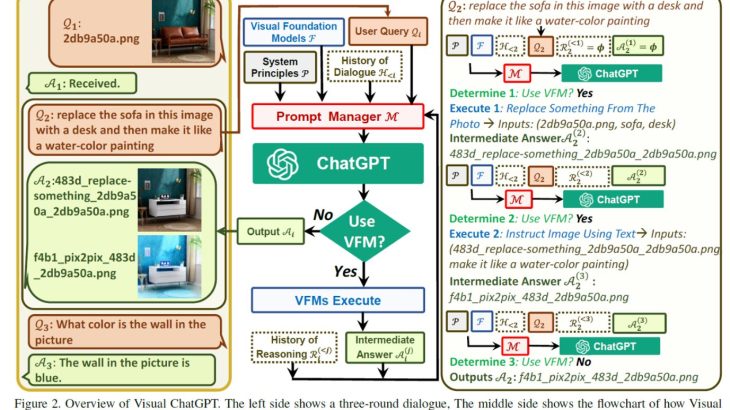
左側は、3ラウンドの対話を示していており、中央は、Visual ChatGPTがVisual Foundation Modelsを反復的に呼び出し、回答を提供するフローチャートを示しています。そして、右側は、2番目のQAの詳細なプロセスを示しています。
Visual ChatGPT
𝑆 = {(𝑄1, 𝐴1),(𝑄2, 𝐴2), …,(𝑄𝑁 , 𝐴𝑁 )} を 𝑁 個の質問-回答ペアを持つ対話システムとします。𝑖 回目の会話から応答𝐴𝑖を得るために、複数の VFMs とそれらのモデルからの中間出力A𝑖^((𝑗))が関与し、𝑗 は 𝑖 回目のラウンドで 𝑗 番目の VFM(F)からの出力を示します。最後に、システムはA𝑖^((𝑗))を出力し、それが最終応答として示され、それ以上の VFM は実行されません。
Visual ChatGPTの定義式
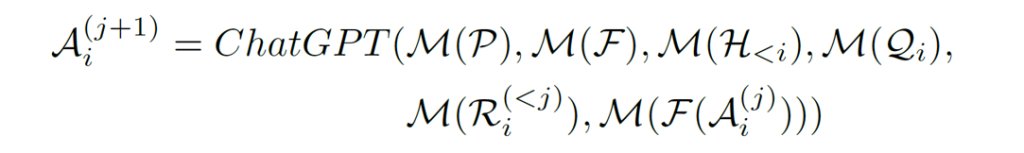
システムプリンシプル 𝑷
Visual ChatGPTに基本的なルールを提供します。
例えば、画像のファイル名に敏感であることや、チャット履歴に基づいて結果を生成するのではなく、VFMを使用して画像を処理すること。など
Visual Foundation Model 𝑭
Visual ChatGPTの中核は、さまざまなVFMs:𝐹 = {𝑓1, 𝑓2, …, 𝑓𝑁 } の組み合わせからできています。各基礎モデル𝑓𝑖は明確な入力と出力を持つ決定された関数を含んでいます。
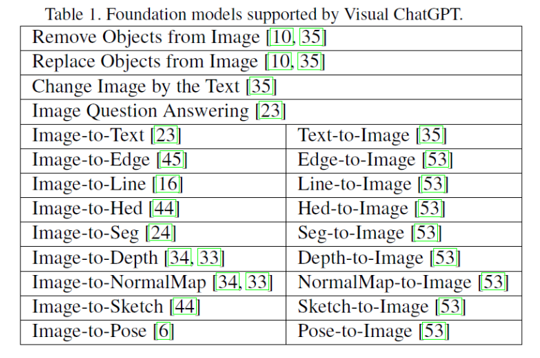
Visual ChatGPT がサポートしているFoundation modelsが表になります。
対話履歴 𝑯(<𝒊)
𝑖 番目のラウンドの対話履歴を、過去の質問回答ペア、すなわち {(𝑄1, 𝐴1),(𝑄2, 𝐴2), · · · ,(𝑄(𝑖−1), 𝐴(𝑖−1))} の文字列連結したものと定義します。対話履歴を最大長で切り捨てて、ChatGPTモデルの入力長に合わせます。
ユーザークエリ 𝑸𝒊
Visual ChatGPTでは、言語クエリだけでなく視覚クエリも含むことができます。
推論履歴 𝑹𝒊^((<𝒋))
複雑な質問を解決するために、Visual ChatGPTは複数のVFMの協力が必要な場合があります。𝑖 回目のラウンドの会話について、 𝑹𝒊^((<𝒋)) は 𝑗 番目に呼び出されたVFMsからのすべての以前の推論履歴です。
中間回答 𝑨^((𝒋))
Visual ChatGPTは、複雑なクエリを処理する場合、異なるVFMを論理的に呼び出すことで、複数の中間回答を生成し、ステップバイステップで最終回答を得ようとします。
Prompt Manager M
プロンプトマネージャーは、 ChatGPTモデルが理解できるように、すべての視覚信号を言語に変換するよう設計されています。
Prompt Manager の全体図
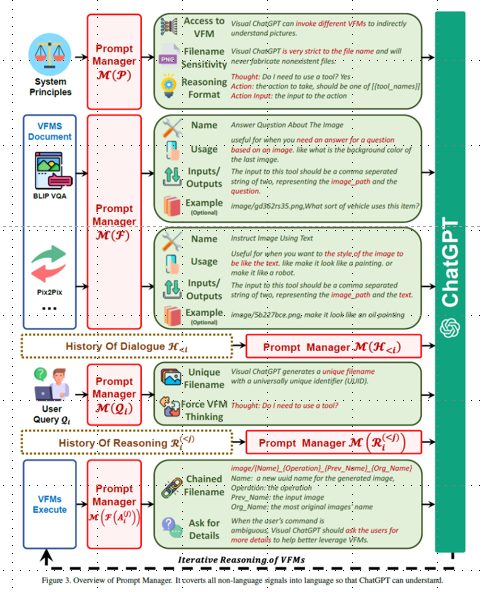
3.1. システムプリンシプルのPrompt Managing M(P)
Visual ChatGPTは、視覚情報を理解し、応答する答えを生成するために、さまざまなVFMを統合するシステムです。そのためには、システムの原理をカスタマイズし、ChatGPTが理解できるようなプロンプトに変換する必要があります。このプロンプトには、以下のような目的があります。
VFMs へのアクセス
Visual ChatGPTは、さまざまなVLタスクを解決するためのVFMsリストにアクセスできます。どの基礎モデルを使用するかは、完全にChatGPTモデル自身が決定するため、新しいVFMsやVLタスクに対応しやすくなっています。
ファイル名感度
Visual ChatGPTはファイル名によって画像ファイルにアクセスし、正確なファイル名を使用することが重要です。これは、1回の会話に複数の画像とその異なる更新バージョンが含まれる場合があり、ファイル名の誤用が現在議論されている画像について混乱を招く可能性があるためです。そのため、Visual ChatGPTはファイル名使用に厳格であり、正しい画像ファイルを取得および操作することを確実にします。
Chain-of-Thought
1つの見かけ上単純なコマンドでも複数のVFMsが必要な場合があります。(本論文の漫画風の赤い花の例)より複雑なクエリをサブ問題に分解して対処するために、CoTがVisual ChatGPTに導入されており、次の実行または最終応答を返すためのVFMsを決定・活用・ディスパッチするのに役立ちます。
推論形式の厳格化
Visual ChatGPTは厳密な推論形式に従わなければなりません。そのため、推論結果を精巧な正規表現で解析し、ChatGPTモデルが次の実行を決定するための合理的な入力形式を構築します。(例えば、新しいVFMをトリガーとしたり、最終応答を返します。)
信頼性
言語モデルであるVisual ChatGPTは、画像ファイル名や事実を捏造する可能性があり、システムの信頼性を低下させる可能性があります。このような問題に対処するために、Visual ChatGPTがVision Foundation モデルの出力に忠実であり、画像の内容やファイル名を生成しようとするプロンプトを設計されています。また、複数のVFMの連携によりシステムの信頼性が向上するため、会話履歴に基づいて結果を生成するのではなく、VFMを優先的に活用するようChatGPTを誘導するプロンプトを構築しています。

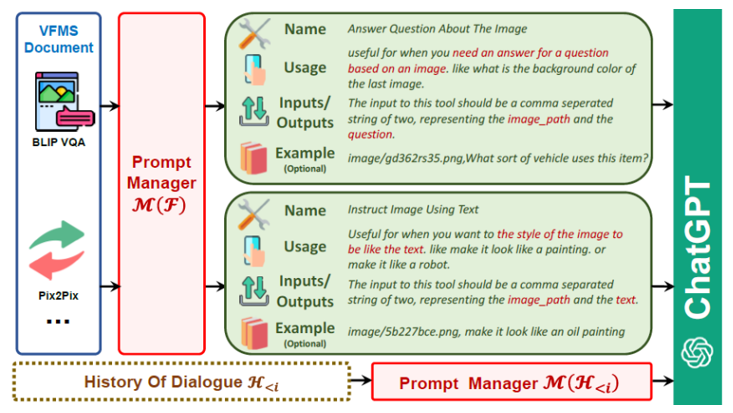
3.2 Foundation modelの Prompt Managing M(F)
Prompt Managerは次項の側面を特定して、Visual ChatGPTが正確にVLタスクを理解し処理できるようにします。
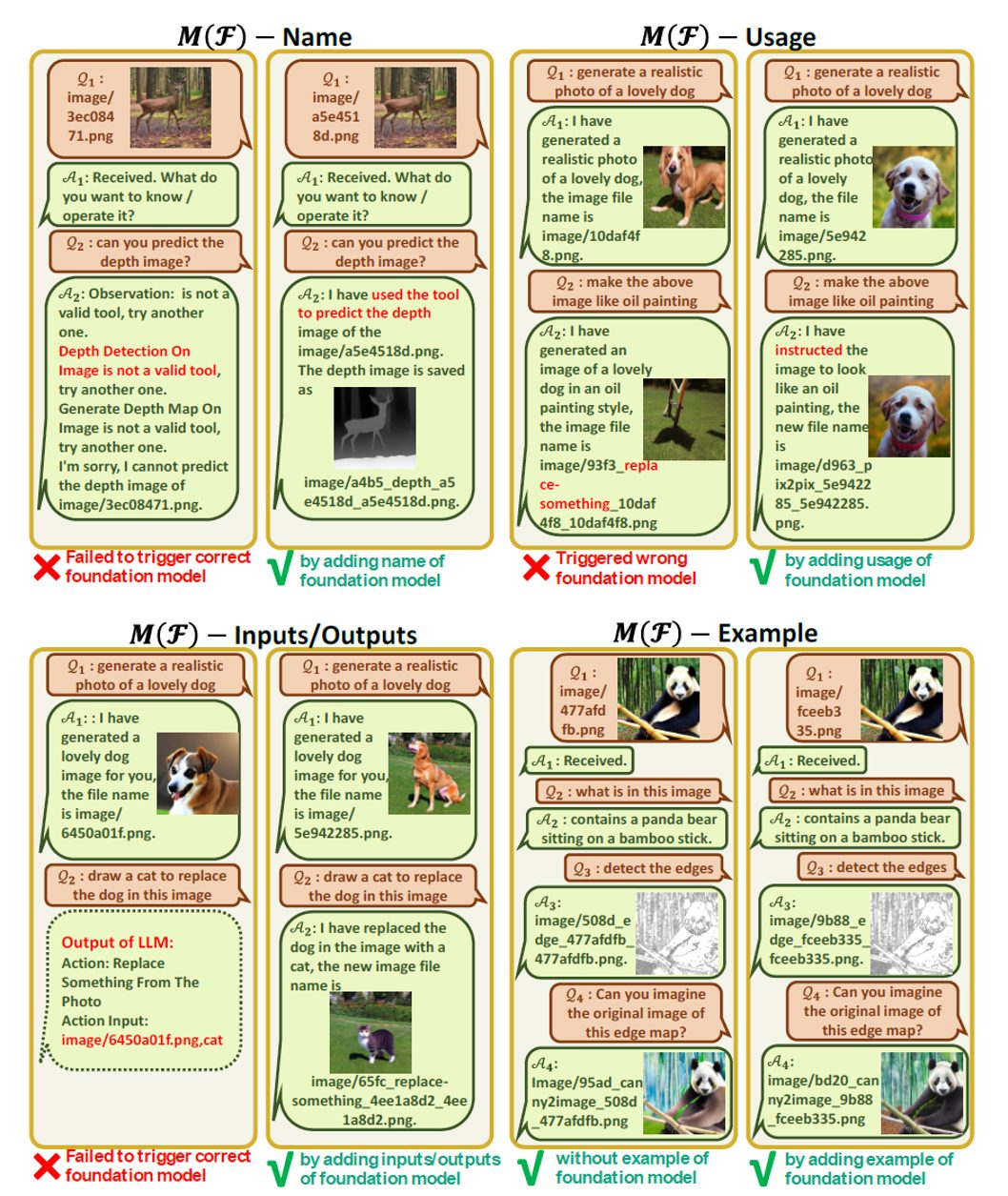
名前
プロンプトは、Visual ChatGPTがVFMの目的を簡潔に理解するのに役立つだけでなく、VFMへの入口として機能します。
使用法
使用法プロンプトはVFMが使用されるべき具体的なシナリオを説明します。
例えば、Pix2Pixモデルは、画像のスタイル変更に適し、この情報提供はVisual ChatGPTが特定のタスクにどのVFMを使用するか決定する際に役立ちます。
入力 / 出力
入力および出力プロンプトは、各VFMで必要とされる入力および出力形式の概要を示します。
例(オプション)
例プロンプトはオプションです。Visual ChatGPTが特定の入力テンプレート下で特定のVFMの使用方法をよりよく理解し、複雑なクエリを処理する際にも役立ちます。
3.3. ユーザークエリのPrompt Managing 𝑴(𝑸𝒊)
Visual ChatGPTは、言語または画像、単純なものから複雑なものまで、さまざまなユーザークエリに対応しています。
Prompt Managerは次の2つの側面からユーザークエリを処理します。
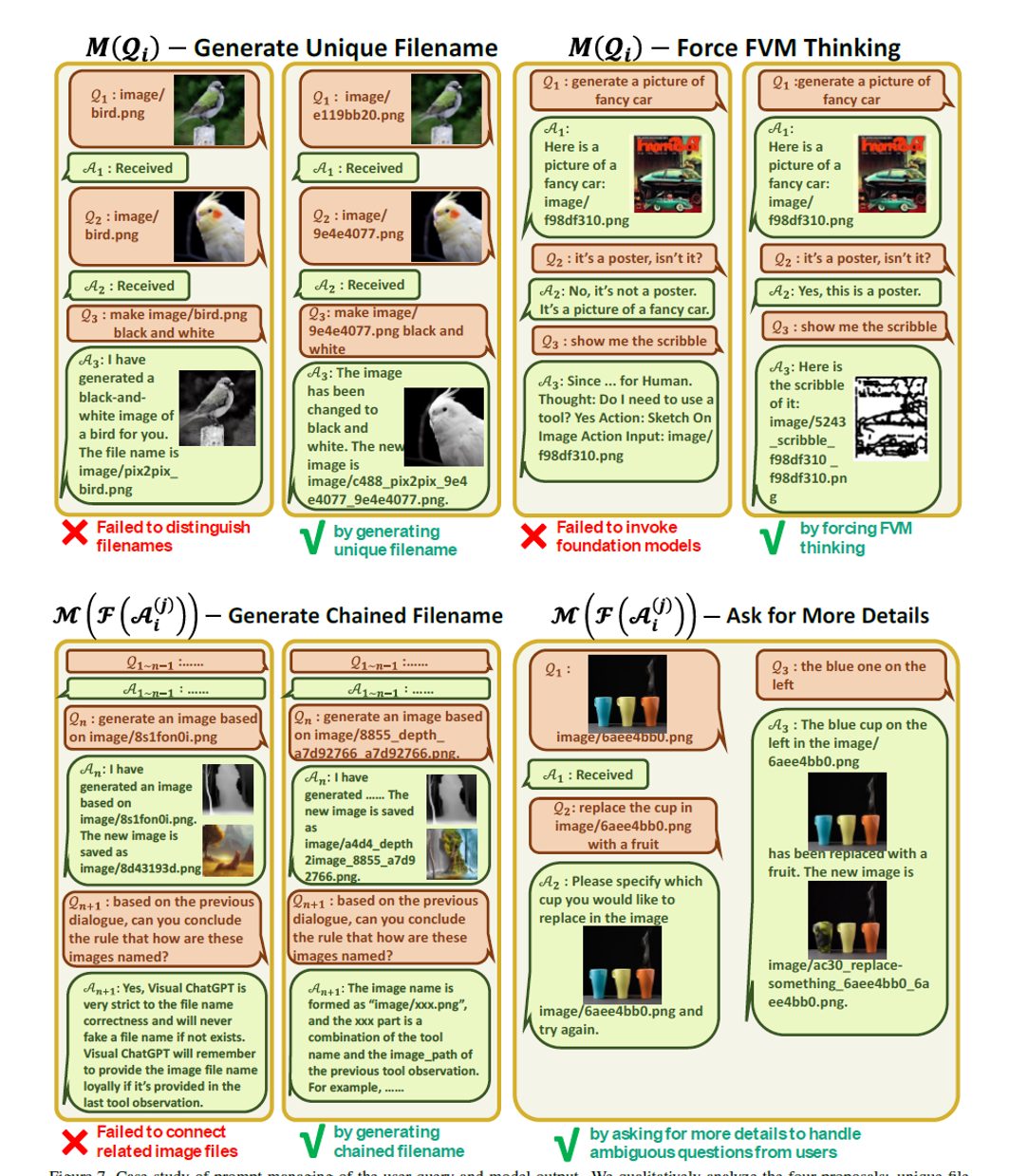
ユニークなファイル名の生成
Visual ChatGPTは、新しくアップロードされた画像と、既存の画像を参照する画像の 2 種類の画像関連クエリを処理することができます。
新規にアップロードされた画像に対して、Visual ChatGPT は UUID(universally unique identifier) を持つユニークなファイル名を生成し、相対ディレクトリを表すプレフィックス文字列 “image” を追加します(例:“image/{uuid}.png”)。
アップロードされた画像はChatGPTに入力されないが、画像のファイル名を示す質問と画像を受信したことを示す回答を含むための対話履歴が生成されます。
既存の画像を参照するクエリについて、Visual ChatGPTはファイル名のチェックを無視します。(ChatGPTは、UUID名などの曖昧さがなければ、ユーザークエリのファジーマッチングを理解する能力があるため、このアプローチは有益であると証明されています。)
VFM思考の強制
Visual ChatGPTのVFMのトリガーを成功させるために、(𝑄𝑖)に接尾辞promptを付加しています。
「VisualChatGPTはテキスト言語モデルなので、VisualChatGPTは想像ではなく、イメージを観察するためのツールを使用する必要があります。Visual ChatGPTはテキスト言語モデルであるため、Visual ChatGPTは想像ではなくイメージを観察するツールを使用しなければなりません。Thought: ツールを使う必要があるか」。
このプロンプトには以下の2つの目的があります。
1)VisualChatGPTが想像力だけに頼らず、Foundationモデルを使うように促す。
2)VisualChatGPTが「ここにいるよ」といった一般的な応答ではなく、Foundationモデルによって生成された具体的なアウトプットを提供するように促す。
3.4 Foundation ModelアウトプットのPrompt Managing 𝑴(𝑭(𝑨𝒊^((𝒋))))
異なるVFMsからの中間出力𝐹(𝐴𝑖^((𝑗)))について、Visual ChatGPTは暗黙的に要約し、その次の対話のためにChatGPTに供給します。すなわち、他のVFMsを呼び出して、終了条件に達するまで、またはユーザーにフィードバックを与えるまで、更なる操作を行う。内部ステップは以下のように要約できます。
連鎖したファイル名の生成
Visual ChatGPTの中間出力は、次の暗黙的な会話ラウンドの入力になります。そのため、これらの出力をより論理的にする必要があります。
命名規則等
Visual Foundation Modelsから生成された画像は「image/」フォルダーに保存されます。次の文字列が画像名を表すことを示唆します。次に、画像は「{Name} {Operation} {Prev Name} {Org Name}」と命名されます。ここで、{Name} は上記のUUID名であり、{Operation} は操作名、{Prev Name} は入力画像の一意の識別子、{Org Name} はユーザーがアップロードした画像またはVFMsによって生成された元の画像名です。例えば、「image/ui3c edge-of o0ec nji9dcgf.png」は入力「o0ec」のキャニーエッジ画像であり、「ui3c」と名付けられます。この画像の元の名前は「nji9dcgf」で、このような命名規則により、ChatGPTに中間結果属性(例えば画像)とそれが一連の操作からどのように生成されたかを示唆することができます。
VFMの追加呼び出し
Visual ChatGPTの中核の一つは、ユーザーのコマンドを完了するために、自動的にVFMを追加で呼び出すことができます。具体的には、ChatGPTが現在の問題を解決するためにVFMが必要かどうか自問自答し続けるように、各世代の末尾に「Thought: 」という接尾語を末尾につけます。
詳細な情報を求める
ユーザーのコマンドが曖昧な場合、Visual ChatGPTはVFMsをより活用するために、ユーザーに詳細を求めます。LLMは、特に入力された情報が不十分な場合に、ユーザーの意図を恣意的に改ざんまたは推測することが許可されていないので、このデザインが安全かつ重要です。
実験
4.1. セットアップ
LLMをChatGPT(OpenAI「text-davinci-003」バージョン)で実装し、LangChain1でLLMをガイドします。HuggingFace Transformers からFoundationモデルを収集し、Maskformer 3およびControlNet 4からFoundaitonモデルを収集します。
すべての22 VFMsの完全な展開には4つのNvidia V100 GPUが必要であるが、ユーザーはGPUリソースを柔軟に節約するために少ないFoundationモデルをデプロイすることができます。チャット履歴の最大長さは2,000であり、過剰なトークンはChatGPTの入力長に合わせるため切り捨てられます。
4.2. 複数ラウンド対話のフルケース
図はVisual ChatGPTの16ラウンドマルチモーダル対話ケースです。このケースでは、ユーザーがテキストと画像両方の質問を尋ね、Visual ChatGPTはテキストと画像両方で応答します。この対話には、複数の画像の議論、複数のFoundationモデルの処理、および複数ステップが必要な質問の処理が含まれます。
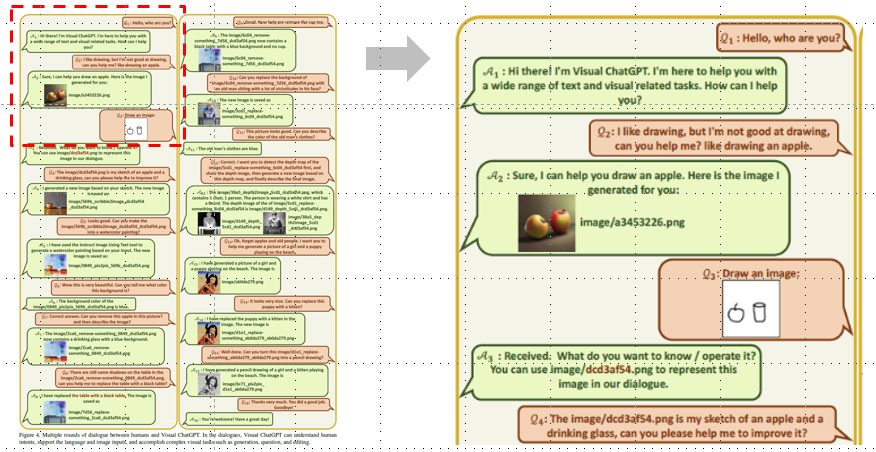
対話では、Visual ChatGPTは人間の意図を理解し、言語と画像の入力をサポートし、生成、質問、編集などの複雑な視覚タスクを達成することができます。
4.3. プロンプトマネージャーのケーススタディ
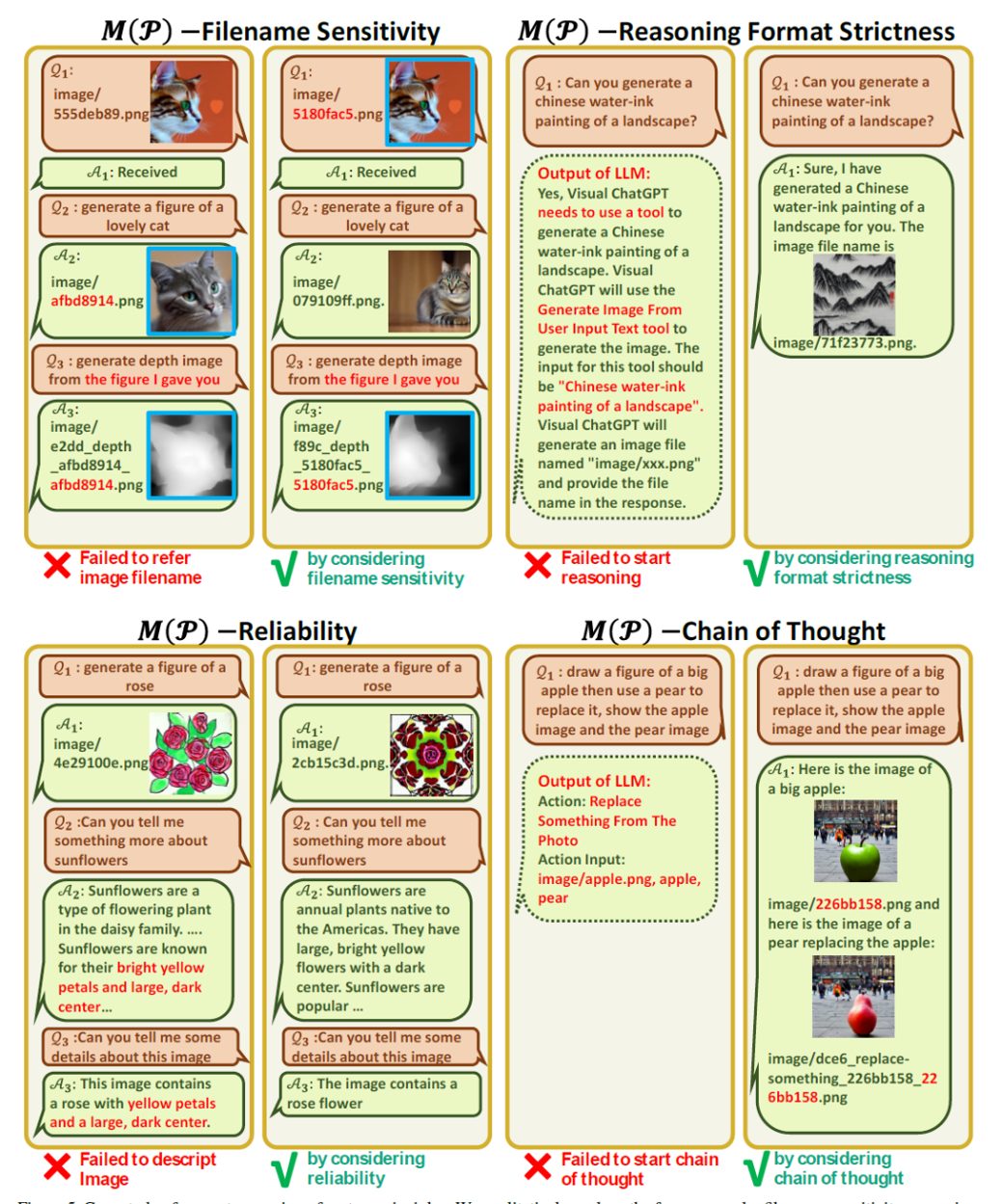
システム原則のプロンプト管理のケーススタディ
ファイル名感度、推論形式の厳格性、信頼性、思考の連鎖といった4つの提案を定性的に分析しています。プロンプトの有効性を検証するため、システム原理において様々な部分を削除し、モデル性能を比較検討しています。各削除により、異なる程度の性能劣化が確認されています。
基礎モデルのプロンプト管理のケーススタディ
名前、使用法、入力/出力、例の4つの提案を定性的に分析しています。
ユーザークエリとモデル出力のプロンプト管理のケーススタディ
ユニークなファイル名、VFM思考強制、チェーンされたファイル名、詳細を求める4つの提案を定性的に分析しています。
制限事項
ChatGPTおよびVFMsへの依存
Visual ChatGPTは、タスクを割り当てるためにChatGPTに、タスクを実行するためにVFMsに重点を置いています。したがって、Visual ChatGPTのパフォーマンスはこれらのモデルの正確性と効果に大きく影響されます。
プロンプトエンジニアリングが重い
Visual ChatGPTには、VFMsを言語に変換し、これらのモデルの説明を識別可能にするために、かなりの量のプロンプトエンジニアリングが必要です。このプロセスは時間がかかる場合があり、コンピュータビジョンと自然言語処理の両方の専門知識が必要です。
リアルタイム機能の制限
Visual ChatGPTは一般的な目的で設計されています。そして、複雑なタスクを自動的にいくつかのサブタスクに分解しようとします。したがって、特定のタスクを処理する際には、Visual ChatGPTは複数のVFMsを呼び出す場合があり、特定のタスクに特化した専門モデルと比較して、リアルタイム機能が制限される可能性があります。
トークン長の制限
ChatGPTの最大トークン長は、使用できる基礎モデルの数を制限する可能性があります。基礎モデルが数千または数百万ある場合は、ChatGPTに供給されるVFMsを制限するためにプレフィルタモジュールが必要になる場合があります。
セキュリティとプライバシー
基礎モデルを簡単に接続および切断できる能力は、特にAPIを介してアクセスされるリモートモデルの場合、セキュリティとプライバシー上の懸念を引き起こす可能性があります。機密データが公開または漏洩されないようにするために、注意深い検討と自動チェックが必要です。
結論
まとめ
本研究では、異なるVFMsを組み込み、ユーザーが言語形式を超えてChatGPTとやりとりできるオープンシステムであるVisual ChatGPTを提案しました。それにより、視覚情報をChatGPTに注入するための一連のプロンプトを細心の注意を払って設計することで複雑な視覚的な問いに段階的に対処することができます。
また、大量の実験と選ばれたケースにより、Visual ChatGPTが異なるタスクにおいて優れた潜在能力と能力が示されました。
課題
前述の制限事項に加えて、VFMsの失敗やプロンプトの不安定性により、生成結果が不満足な場合があることが懸念されます。
そのため、実行結果と人間の意図との整合性を確認し、適切な編集を行う自己訂正モジュールが必要となります。しかし、このような自己訂正行動はモデルの思考を複雑化させ、推論時間の大幅な増加をもたらす課題があります。