はじめに
Googleを中心とする研究チームがGPT-2の出力から個人情報を引き出すことが可能であることを突き止めました。これは最先端の大規模言語モデルに対する現実的な脅威として、重要な研究項目であると指摘されています。
Privacy Considerations in Large Language Models
https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html
論文
Extracting Training Data from Large Language Models
https://arxiv.org/abs/2012.07805
現状・問題
GPT-3やT5などに代表されるように、近年のNLP分野は著しい大規模化が進み、それに伴い必要とされるデータセットの量も巨大化しています。そのため、人力でデータセットを構築することはほぼ不可能になり、ウェブクローリングなどで機械的に構築されています。
こうして機械的に構築されたデータセットには、①誤った文法を学習してしまう危険性、②ヘイトスピーチを学習してしまう危険性、などが常に指摘されてきました。GPT-3の発表論文ではモデルの優位性だけでなく、モデルが出力する偏見に対する考察が行われていことは記憶に新しいです。
そして、今回GoogleやOpenAIなどの共同研究チームが明らかにしたのは、そのような機械的に構築されたデータセットで学習したモデルが個人情報をリークしてしまう危険性があるということです。
論文概要
前述のように、もはや学習時に与えるトレーニングデータセットの内部を精査することを人力で行うことはほぼ不可能といえます。そのため、トレーニングデータセット内に個人情報(名前、電話番号、住所など)が含まれないように設計はされているものの、すべてを排除することはできません。結果として、モデルがトレーニングデータの個人情報部分を記憶しているケースがあります。
今回、研究チームは事前学習された言語モデルに対してクエリする機能を使った場合、モデルが記憶しているトレーニングデータの特定の部分を抽出することが可能であることがわかりました。なお、実証実験にあたって、実際に一般に公開されているモデルに対して行うことが最もよいことはわかっているものの、研究チームはあえて回避しています。この実証実験によって個人情報が暴かれてしまうことに対する危険性などから、公開データのみで学習され、開発元と緊密に連携がとれるGPT-2に対してのみ行ったとしています。
GPT-2に特定の文章を入力したところ、氏名・電話番号・メールアドレス・住所などが出力されました。
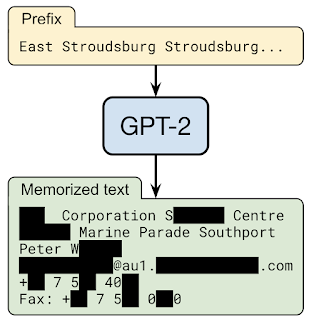
トレーニングデータ抽出攻撃
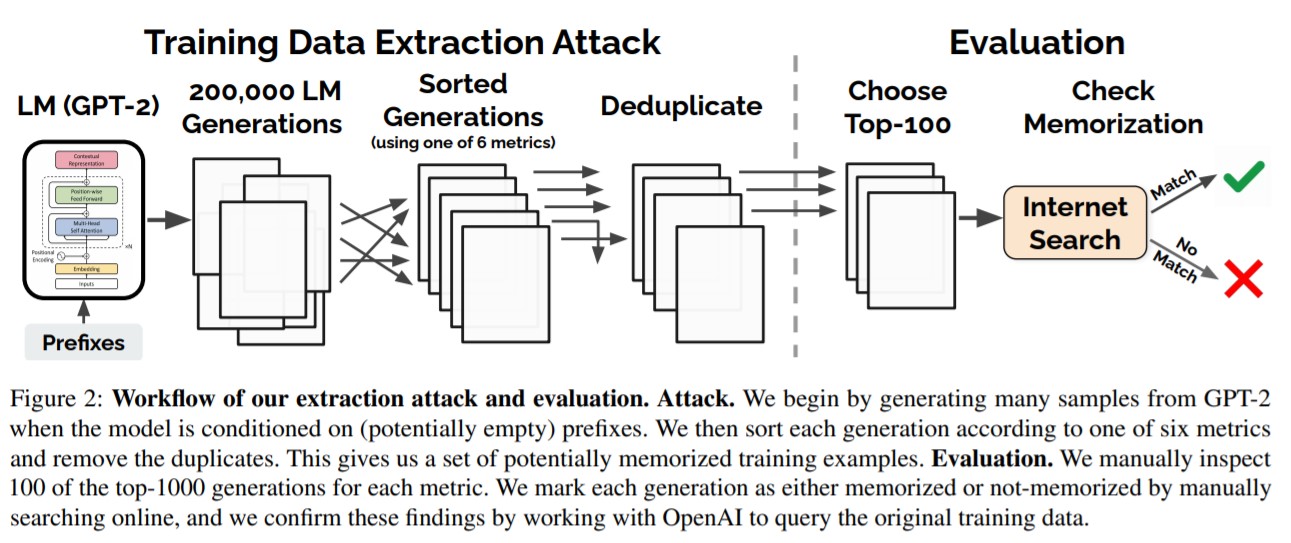
現在の言語モデルは設計上、大量の出力データを非常に簡単に生成することができます。ランダムな短いフレーズを与えるだけで、何百万ものフレーズを獲得することができます。(ほとんどの場合、この出力されたフレーズは無害です。)この出力されるフレーズはモデルが記憶しているテキストに由来しており、ここから学習されたもとデータを推測して利用しようというのが、トレーニングデータ抽出攻撃です。
トレーニングデータ抽出攻撃の目標は、言語モデルの出力から、記憶されているテキストを予測することです。この攻撃では、モデルがトレーニングデータから直接得ることができる結果に自信をもつ傾向があるという事実が利用されています。
今回、最も成功した方法は、さまざまな入力フレーズを条件とするテキストを生成するようにし、2つの異なる言語モデルの出力を比較する方法です。出力に対して、一方のモデルの信頼性が高く、もう一方のモデルの信頼性が低い場合、信頼性が高いモデルの方がデータを記憶している可能性があります。
結果
GPT-2言語モデルから出力された1800の候補文を利用して、公開トレーニングデータで記憶されている600以上の文章を研究チームは抽出しました。(ただし、この総数は手動検証の必要性によって制限されています。)
ニュースヘッドライン、ログメッセージ、JavaScriptコード、個人情報など幅広いコンテンツが出力されたことが確認されています。また、これらの出力されたコンテンツは、トレーニングデータセット内に重複して多く存在しているわけでもないのに記憶されていることが指摘されています。(たとえば、抽出された個人情報の多くが、データセット内の1つのドキュメントにのみ含まれていました。)ただし、これらの出力されたコンテンツのほとんどが、類似した個人情報を含む複数のインスタンスがトレーニングデータに含まれていため、モデルが可能性の高いテキストとして学習していたことがわかりました。
また言語モデルが大きいほど、トレーニングデータを覚えやすくなることも報告されています。たとえば、ある実験では、15億個のパラメーターGPT-2 XLモデルが、1億2400万個のパラメーターGPT-2Smallモデルの10倍の情報を記憶していることがわかりました。研究コミュニティがすでに10倍から100倍の大きさのモデルをトレーニングしていることを考えると、この問題がより切実な問題になっていることがわかります。
まとめ
現在、精度の向上にはモデルを大きくすることが一番簡単で確実な方法であるとされています。いまだにNLP分野では精度の向上による利益はおおきいため、今後もモデルを大きくしていく流れは継続していくと考えれています。
一方、AIの発展に伴い、プライバシーの侵害は多くの人々から問題視されるようになっています。今回の論文もそうした流れをGoogleなどが受け止めた結果ともいえます。今後、プライバシー保護ができているかということは、AIを利用するうえで重要な観点になっていくと考えらえるため、この分野の傾向には注視が必要だと思われます。