はじめに
Googleとハーバード大学の研究チームが、深層学習の一般化と最適化について新たなフレームワークを提案しました。
A New Lens on Understanding Generalization in Deep Learning
https://ai.googleblog.com/2021/03/a-new-lens-on-understanding.html
●論文
『THE DEEP BOOTSTRAP FRAMEWORK: GOOD ONLINE LEARNERS ARE GOOD OFFLINE GENERALIZERS』
https://arxiv.org/pdf/2010.08127.pdf
概要
(深層学習に限ったことではありませんが)深層学習では、学習時の精度(損失)と実際の精度(損失)が異なります。これは無限のデータで学習すること(=オンライン最適化)は現実的に不可能なため、常に限られたデータ内で学習させる(=オフライン最適化)ことになるためであり、「深層学習モデルの一般化」という問題として存在しています。
Googleとハーバード大学の研究チームは、オンライン最適化とオフライン最適化のギャップを考えることで、深層学習の一般化をより最適化するための新たなフレームワーク「Deep Bootstrap」を提案しました。
詳細
どのようなモデルも、オフライン最適化とよばれる「限られたデータ内で最適化」するように学習することになります。それに対して、現実では常に未知のデータと遭遇することになるため、誤差の程度に差が生じ、一般化という問題が発生します。そのため、無限の情報に対して最適化する「オンライン最適化(Online optimization)」という問題を考える必要が生じます。
今回、研究チームはオフライン最適化(つまり、一般的に行われる最適化)とオンライン最適化(常に新しい情報に対して最適化する)のギャップについて考察し、新たなフレームワークを提案しています。
実験
実験では、現実の学習データ(学習エポックごとにいくつかの枚数で学習済みデータが利用されることになる=オフライン最適化)と、理想的な学習データ(学習エポックごとに常に新しいデータを利用=オンライン最適化)の差を見ることから始めています。
CIFAR-5m
CIFAE-10を学習させた生成モデルから作られた600万枚のデータセットです。オンライン最適化を可能にするため(=リサンプリングされないようにするため)につくられました。

学習
各学習は以下のように行われます。
オフライン最適化:5万サンプルを100エポック学習させます。
オンライン最適化:全てのデータを一回だけ学習させます。
結果
両者に大きな差がないことが確認されました。このことから、「無限データで迅速に最適化するモデルは、有限データで適切に一般化するモデル」であると考えることができます。
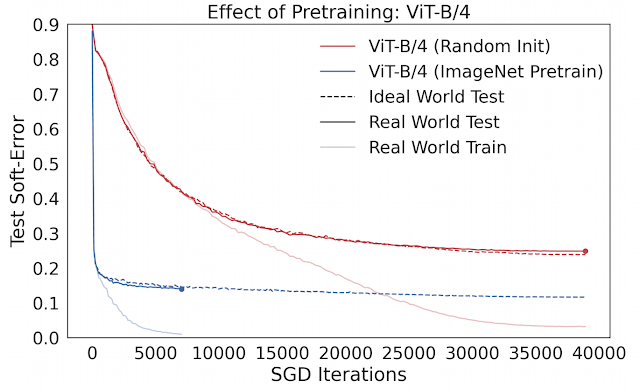
ここでの重要な観察結果は、実世界(オフライン最適化)と理想世界(オンライン最適化)のモデルは、実世界が収束するまで(<1%のトレインエラー)、すべてのタイムステップでテストエラーが近いままであるということです。そのため、「モデルの一般化」が2つのフレームワークの下での最適化パフォーマンスの観点から理解できることを意味します。
オフライン最適化:実世界の学習エラーが収束する速度はどれくらいか
この観察に基づくと、優れたモデルとトレーニング手順とは、(1)理想的な世界では迅速に最適化され、(2)現実の世界ではあまり迅速に最適化されないもの、といえます。
考察
現実の世界での一般化に影響を与える変更(アーキテクチャ、学習率など)を行うときはいつでも、(1)テストエラーの理想的な世界の最適化(速いほど良い)と(2)学習エラーの現実の世界の最適化(遅いほど良い)への影響を考慮する必要があります。
理論上の多くの一般的なアプローチとは対照的に、一般化が純粋に最適化の考慮事項によって特徴付けられることは特に興味深いことであることが示唆されています。重要なのは、オンラインとオフラインの両方の最適化を検討することであるとされます。これらを個別に行うだけでは不十分であり、一緒になることで一般化の程度を決定します。
まとめ
今回提案されている手法はモデルの一般化に関する興味深いものです。深層学習モデルだけではないですが、深層学習モデルに関してはベンチマークテストに対する結果がまるで現実でも適用できるように報告され、人々に過大な期待を持たせていることが不安視されています。今後、実際に利用するモデルに対してはこのような一般化に関する手法を取り入れていきたいところです。