はじめに
Googleがニューラルネットワークモデルの幅と深さがどのように獲得する内部表現に影響するかの研究を発表しました。
Do Wide and Deep Networks Learn the Same Things?
https://ai.googleblog.com/2021/05/do-wide-and-deep-networks-learn-same.html
〇論文
Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth
https://arxiv.org/abs/2010.15327
概要
精度とコンピュータ資源を最適化する上で、モデルの深さと幅を調整することになります。しかし、その調整がモデルの内部表現などモデルに与えている影響の理解はいまだ限定的なものとなっています。そのため、今回研究チームは隠れ表現と最終出力のレンズを通して同じアーキテクチャ群からニューラルネットワークの幅と深さの関係性を系統的に明らかにしました。
研究では、極端に幅が広い、もしくは深いモデルでは、特徴的な「ブロック構造」が内部表現内に存在することを発見し、同時にこのブロック構造と過剰学習の間の関係性を確立することができました。このブロック構造の有無が、獲得される表現に差異をもたらしていることが示されました。ブロック構造がない場合、層の間で獲得される表現には有意な類似性が示されますが、ブロック構造がある場合、異なる表現が学習されることとなります。既存のデータセットを用いた実験では、深さと幅の間で獲得される表現が異なることでデータセット全体では同じ精度でも、得意とするクラスに差があることが明らかになりました。
詳細
CKAを用いた表現類似性の比較
Centered Kernel Alignment(CKA)手法を活用して、表現分析を行います。この手法は、ニューラルネットワークレイヤーの任意のペアによって学習された表現間の類似性を判断するための堅牢でスケーラブルなものです。CKAは、2つのレイヤーから表現(つまり、アクティベーションマトリックス)を入力として受け取り、0(=まったく類似していない)と1(=同一の表現)の間の類似スコアを出力します。
さまざまな深さと幅のResNetのファミリーにCKAを適用し、一般的なベンチマークデータセット(CIFAR-10、CIFAR-100、およびImageNet)でトレーニングし、表現ヒートマップを使用して結果を示します。各ヒートマップのx軸とy軸は、入力から出力に至るまで、検討中のモデルのレイヤーにインデックスを付けます。各エントリ(i、j)は、レイヤーiとレイヤーjの間のCKA類似度スコアです。
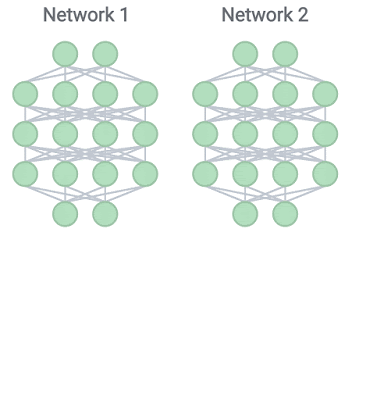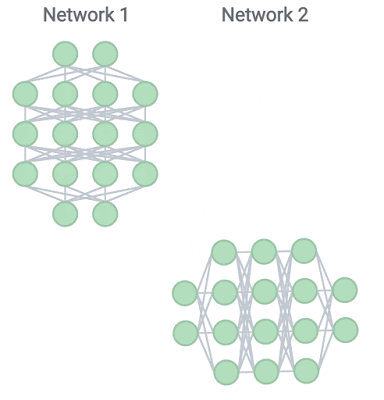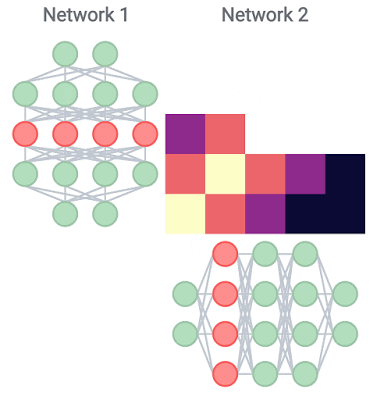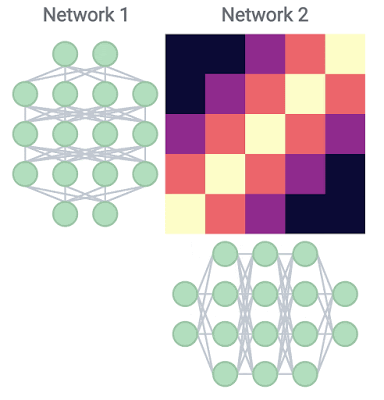
以下は、深さ26と幅乗数1の単一のResNet内で、各レイヤーの表現を他のすべてのレイヤーと比較した場合に得られるヒートマップの例です。なお、チェック柄のようになるのは、スキップ接続(連続的に層を接続しない手法)が利用されているためです。
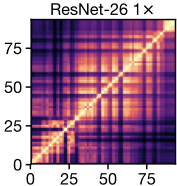
ブロック構造
ヒートマップに黄色の四角として表示される、非常に類似した表現を持つ連続したレイヤーの大規模なセットの出現が、重要です。この構造を「ブロック構造 block structure」と呼びます。
このブロック構造が出現するということは異なる表現が獲得されていることを意味しており、基盤となる層では、ネットワークの表現を期待どおりに段階的に改良するのに効率的ではない可能性があることがわかります。実際、タスクのパフォーマンスがブロック構造内で停滞し、最終的なパフォーマンスに影響を与えることがないため、いくつかの基礎となる層を刈り取ることができることを示しています。
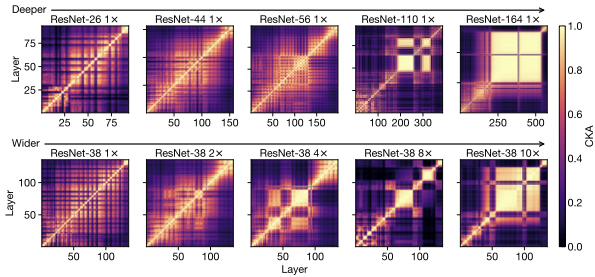
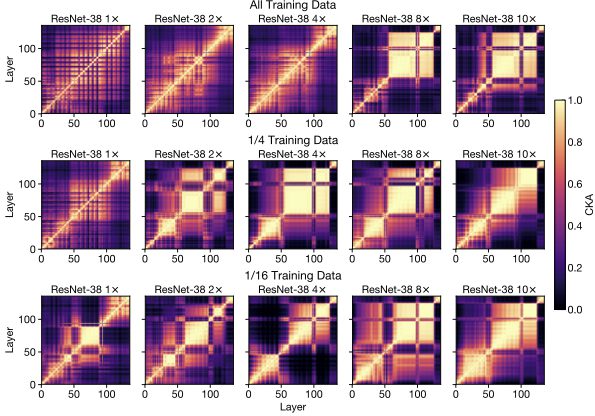
また、このブロック構造が出現するかどうかは、モデルサイズよりもデータセットのサイズの方が影響します。トレーニングデータセットのサイズを小さくすると、ブロック構造が小さくなっていくことが確認されています。
ネットワーク幅を増やし(各行に沿って右に向かって)、データセットサイズを減らして(各列に沿って)、特定のタスクに関する)相対的なモデル容量が効果的に膨らみ、ブロック構造がより小さなモデルに現れ始めます。
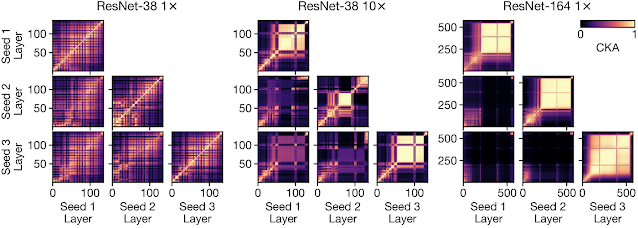
モデル間での表現比較
さらに進んで、さまざまなランダム初期化とさまざまなアーキテクチャのモデル全体の表現に対する深さと幅の影響を研究します。そして、ブロック構造の存在がこの文脈でも大きな違いを生むことを発見します。
ブロック構造がないモデルは幅や深さが違っても同じような表現を学習し、各層で獲得される表現に大きな違いはありません。一方で、ブロック構造が存在する場合、幅や深さの違いから異なる表現を学習するようになります。このことは、たとえ同じような精度を発揮しても幅や深さが異なるモデルでは学習される表現が異なることを示唆しています。
モデルのエラー分析
獲得された表現が結果の多様性にどのように影響するかを確認しました。さまざまなアーキテクチャのネットワークの母集団をトレーニングし、各アーキテクチャ構成がエラーを起こす傾向があるテストセットの例を特定します。
CIFAR-10データセットとImageNetデータセットの両方で、同じ平均精度を持つワイドモデルとディープモデルは、サンプルレベルの予測で統計的に有意な差を示しています。同様にImageNetのクラスレベルの精度にも当てはまり、ワイドモデルは風景に対応するクラスを識別する際に小さな利点を示し、ディープネットワークは消費財で比較的正確です。
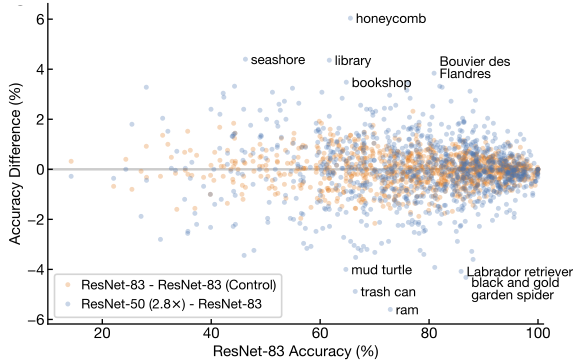
まとめ
今回の研究では、同一精度のモデルでも実用に合わせて深さや幅を調整する必要があること、また精度を向上させることができることを示しています。現在はモデルのサイズや全体の精度に効果的なモデルの深さと幅などがある程度明らかになっているため、あまり顧みられているとは言い難い分野ではありますが、今後より特化したモデルが求められるなかでは、モデルの深さと幅のどちらを深くするかを目的に応じて選択することが必要になることも考えられます。