はじめに
カリフォルニア大学サンディエゴ校がロボットが医療現場の臨床環境や救急部門でも適切に挙動できるように、より正確なナビゲーションシステムとして強化学習アルゴリズムを利用したSafeDQNを開発しました。また、研究チームはロボットのナビゲーションのためのオープンソースデータを将来的に公開することも明らかにしました。
This system helps robots better navigate emergency rooms
https://jacobsschool.ucsd.edu/news/release/3280
〇論文
Social Navigation for Mobile Robots in the Emergency Department
http://cseweb.ucsd.edu/~lriek/papers/taylor-icra-2021.pdf
概要
ロボットが物資や資材を適切に届けることが出来れば、医師の負担を減らすことが可能です。しかし、救急科の医師に関しては、医師自身が患者の世話で精いっぱいの時にロボットに適切な指示をだすことは困難です。そのため、今回研究チームは指示がなくてもロボットが適切に挙動し、かつ適切な物資を届けることができるようになるナビゲーションシステムとして、強化学習アルゴリズムを利用したセーフティクリティカルディープQネットワーク(SafeDQN)を作成しました。
SafeDQNは既存の同様のナビゲーションアルゴリズムよりもよい成果を出すことが出来ました。
詳細
SafeDQN
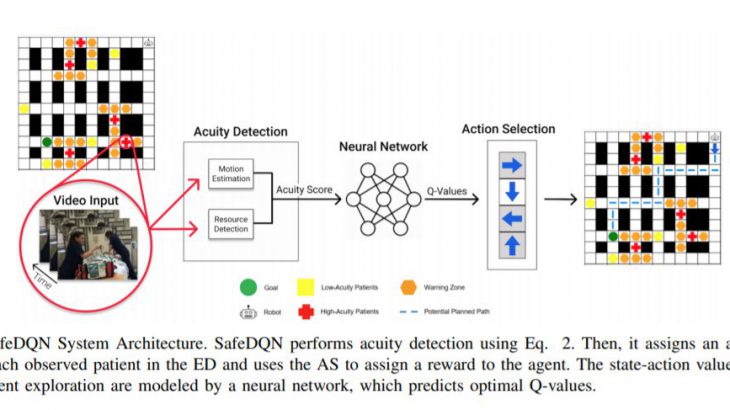
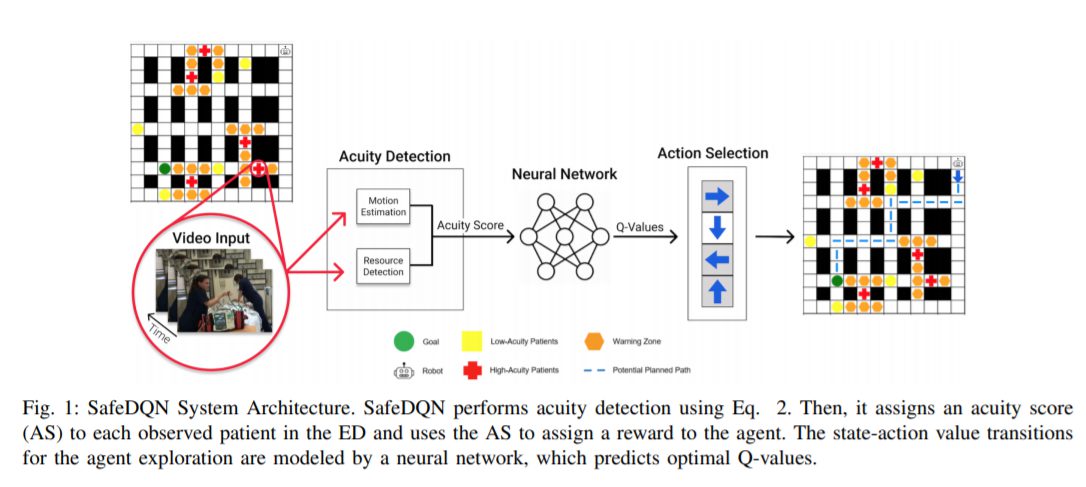
空間内に集まっている人の数と、これらの人がどれだけ速くそして突然動いているかを考慮したアルゴリズムを中心に、ナビゲーションシステムであるセーフティクリティカルディープQネットワーク(SafeDQN)を構築しました。このモデルは救急科での臨床医の行動の観察に基づいており、救急科で発生する可能性のある最悪のシナリオに対処するように設計されています。
患者の状態が悪化すると、チームはすぐに患者の周りに集まり、援助を提供します。ナビゲーションシステムは、邪魔にならないように、これらのクラスター化された人々のグループの周りを移動するようにロボットに指示します。

学習データ
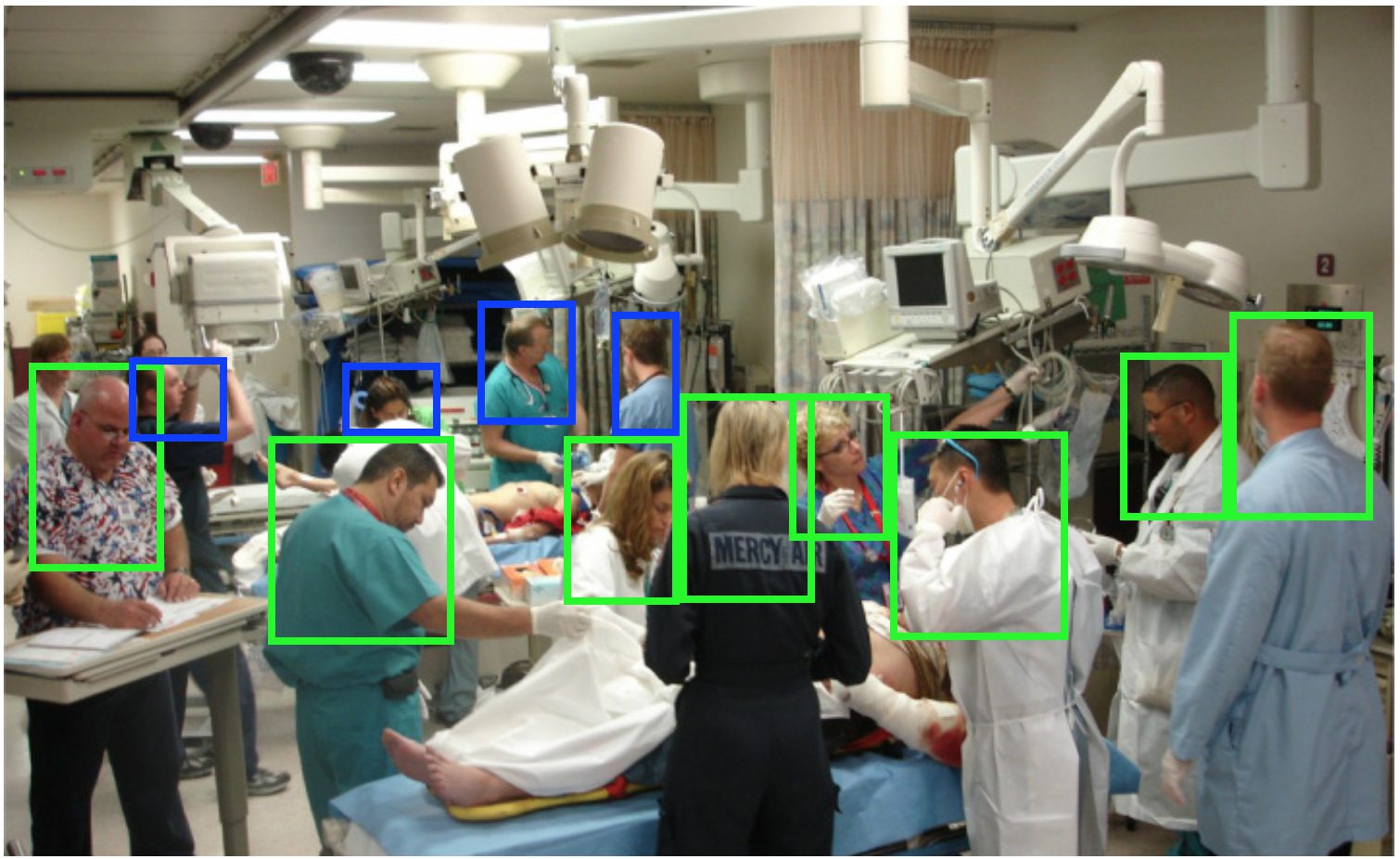
今回の学習のために新たなデータセットが作成されました。Youtube上から救急医療を扱ったドキュメンタリーやリアリティ番組の動画を収集しました[“emergency medicine trauma,” “gunshot wound trauma,” “heart attack trauma,” “traumatic injuries emergency department,” “Untold Stories of the E.R.,” “Trauma: Life in the E.R.,” “Emergency Room: Life + Death at VGH,” “Boston Med,” “Hopkins,” “Save my life,” “NY Med,” “The Critical Hour,” “Boston EMS,” “Big Medicine,” and “medical documentaries.”] これらは700を超えるビデオで構成され、今後他の研究チームが他のアルゴリズムやロボットをトレーニングするために利用できるように公開される予定になっています。

結果
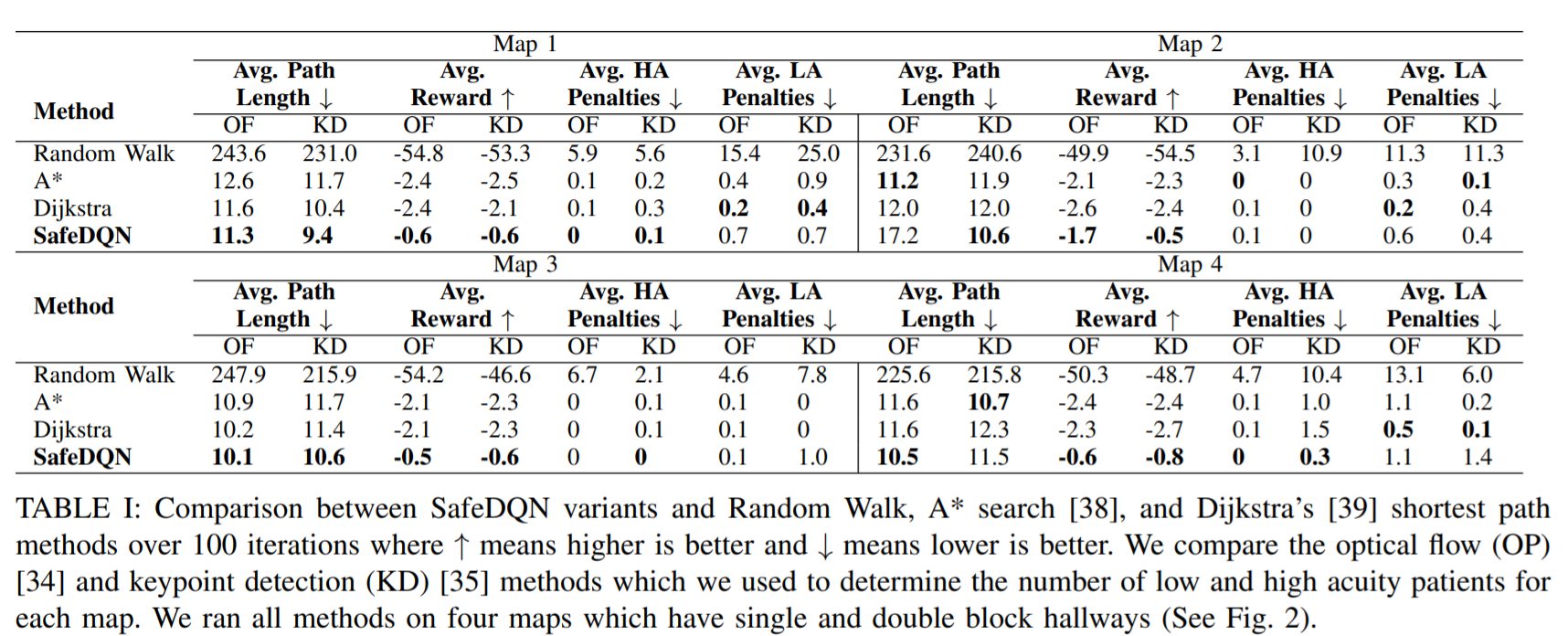
研究者は、シミュレーション環境でアルゴリズムをテストし、パフォーマンスを他の最先端のロボットナビゲーションシステムと比較しました。SafeDQNシステムは、すべての場合で最も効率的で安全なパスを生成しました。
考察
SafeDQNは他のナビゲーションシステムと比べてよい精度を出しているという点ですでに大きな特徴を有していますが、もう1つの重要な特徴は、ライブビデオから推測される患者の緊急性を理解しているという点です。ほかの多くのナビゲーションシステムは理解していないため、EDやその他の臨床環境でのロボットの使用に適する数少ないシステムとなります。
またSafeDQNを利用することで、ロボットは患者の緊急性を視覚的に推測できるため、救命救急処置中に医療提供者の邪魔をすることはありません。 これは、災害対応など、他のセーフティクリティカルな設定でも役立つ場合があると考えられます。 そのほかの利点としてSafeDQNは拡張性が高く、他のタイプのニューラルネットワーク、例えばDoubleQ-LearningやDuelingQ-Networksなどの他のDeepQ-Learningアプローチに簡単に拡張できます。
一方で、SafeDQNの限界として、シミュレーション環境でのみしか評価されていない点があげられます。 実際の環境下で移動ロボットを動かすことは現在想定されていない問題が多くあると考えられます。 たとえば、救急科内の移動ロボットでは、閉塞、ノイズ、プライバシーの懸念から現実世界の知覚が困難であり、視覚センサーの使用が困難になるなどがあげられます。 またSafeDQNは視覚情報に基づいて患者の状態を判断するため、実際の環境でどれだけうまくいくかについて疑問がすでに存在しています。
まとめ
強化学習アルゴリズムを利用したロボットの制御などは現在計算コストや環境設定の難しさからまだまだ問題が多くありますが、一方でゲームなどで明らかにされているようにうまくいった場合、人間よりも圧倒的にうまくいくことが示されています。今後、ロボット制御の主流になるとも考えられるため、現在から知見を蓄積していくことが重要であると考えられます。