はじめに
2017年に仏 Université Paris-Est, École des Ponts ParisTech の研究チームから発表された ResNet の改良モデル WideResNet について解説します。なお、ResNet の知識が前提になるため ResNet の知識に不安がある場合は、参考記事をご参照下さい。
Wide Residual Networks
https://arxiv.org/pdf/1605.07146.pdf
●GitHub
https://github.com/szagoruyko/wide-residual-networks
概要
画像認識( Computer Vision : CV )の世界では、 ResNet の誕生によって大きく進歩しました。それまで勾配消失の問題によって層を深くすることが難しかったニューラルネットワークに対して、Residual Block (残差ブロック)を利用することで深くすることに成功しました。層を深くすることに成功した ResNet は大きく性能を向上させ、以降のCVの世界でデファクトスタンダードモデルになりました。
今回紹介する WideResNet は ResNet 改良したモデルになります。ResNet は層を深くすることを目的として 1000層にしても学習を進めることができるようになりましたが、一方で層を深くするにつれて性能に対する計算効率が悪くなるという問題も抱えていました。(精度を1%向上させるごとに、レイヤー数がほぼ2倍になると論文では指摘記されています。)これは「特徴再利用の減少」問題とよばれる層の重みの多くが無意味になってしまうことに原因があると考えられ、WideResNet はこの問題の解決のために開発されました。
WideResNet は Residual Block 内の畳み込みに対してチャネル数を増やす=幅 wide を広げることや、ドロップアウトを実装することで対応しました。結果として、16層のWideResNetでも、従来の1000層のResNetよりも良い精度をだすことができ、計算時間も大幅に削減することができました。
WideResNet 論文のポイント
詳細
背景
もともと浅いネットワークと深いネットワークの問題は、機械学習で長い間議論されており、浅い回路は深い回路よりも指数関数的に多くのコンポーネントを必要とする可能性があることが示されていました。そのため層を深くしたいというモチベーションは常にありましたが、勾配消失問題によって層を深くすると学習がうまく進まないという問題がありました。
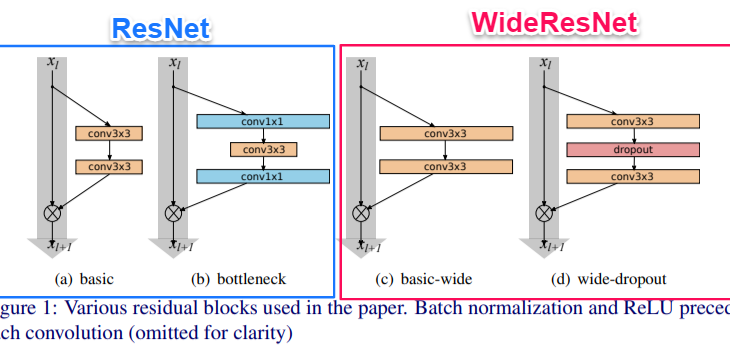
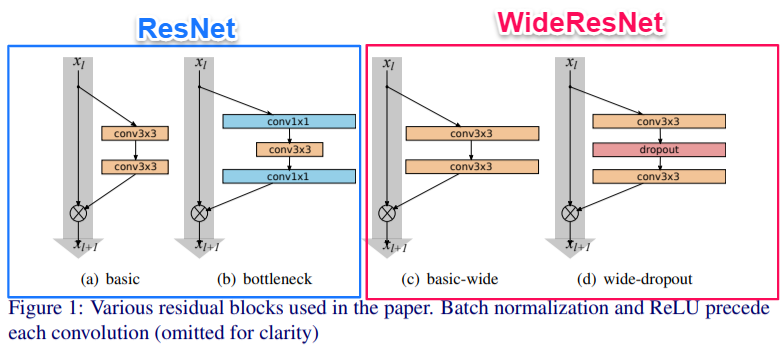
ResNet は Residual Block を開発し、Identity mapping とよばれる「もとの入力」と「Residual Block の出力」を組み合わせて次の入力にする手法を組み込むことでニューラルネットワークを深くすることに成功しました。しかし、この Identity mapping は ResNet に「特徴再利用の減少」という問題を発生させました。
これは、いくつかのブロックのみが有用な表現を学習し、多くのブロックが最終的な結果にほとんど貢献しないという問題のことです。これは Identity mapping には誤差逆伝播時に勾配が残差ブロックの重みを強制的に経由させる仕組みがないため、学習中に何も学ばないということが起こりうるためです。層が深くなることで、無意味なブロックが多くなり、結果として性能に対する計算効率が悪化していきます。
ResNet の開発時にもこの問題には注意が払われており、層を増やしてパラメータを少なくするために、できるだけ1層あたりの内部構造を薄くしようとしました。さらに、ResNetブロックをさらに薄くする「ボトルネックブロック Bottleneck Block」が導入されました。
WideResNet はこの問題を Residual Block 内の畳み込み層のチャネル方向を広げる=幅 wide を広げることで解決しようとしました。
WideResNet ( Wide Residual Networks )
基本方針を変えずに ResNet を改良するために、Residual Block の改良を研究チームは考えました。(基本的な Identity mapping の式は変えず、Residual Block の改良を行うことで ResNet の改良を行います。)
Identity mapping の式
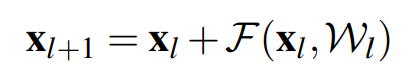
シンプルに Residual Block の表現力を向上させる方法は以下の3つが考えられます。
- ・ブロックにより多くの畳み込み層を加える
- ・より多くの特徴平面を加えることで畳み込み層を広げる
- ・畳み込み層のフィルターサイズを大きくする
ただし、最後のフィルターサイズを大きくすることは、小さいフィルターの方が効率的であることがこれまでの研究では明らかになっているため、3×3よりも大きいフィルターサイズは利用しないことにしたとしています。
そのため、研究チームは「ブロック内により多くの畳み込み層を加える」ことと「より多くの特徴平面を加える(=チャンネル数を増やす)ことで畳み込み層を広げる」ことの効果を検証しました。
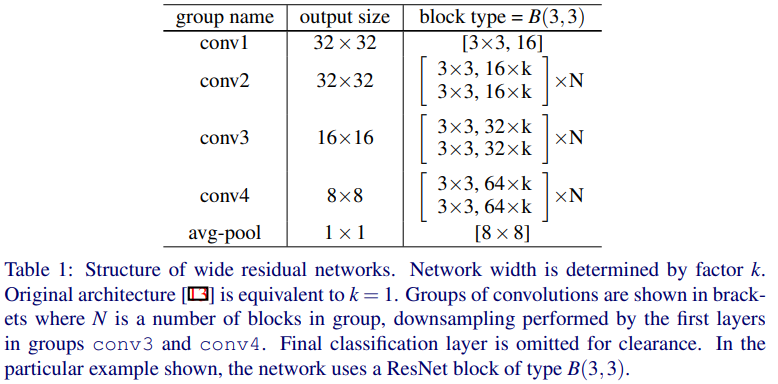
各文字は以下の内容を示します。
- l : 深さ(depth) ブロック内の畳み込みの数
- k : 広さ(width) 畳み込み内の特徴平面の数(チャネル数)を k 倍することを意味する。
- B(M) : Residial Block (残差ブロック)のこと
- M :ブロック内の畳み込み層のカーネルサイズのリスト
- WRN-n-k : n層の畳み込みをもち、幅k をもつ Wide Residual Networks
- (パラメータの数と計算量は k の二乗になる。k=1 のとき、もとのResNetと同じで、k>1のときWideResNetとなる。)
ベースとなるWide Residua Networks
基本設定
- オプティマイザー:SGD(ネステロフのモーメンタム)
- 学習率:初期0.1
- 荷重減衰:0.0005
- モーメンタム:0.9
- ミニバッチサイズ:128
ブロック内の畳み込み層の組み合わせ
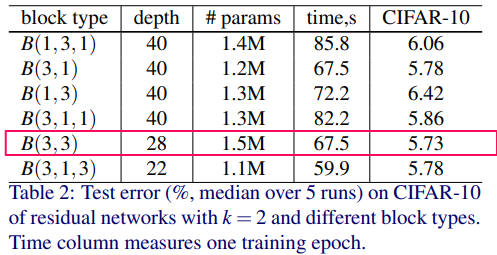
ResNetの3×3畳み込みがどの程度重要なのかをCIFAR-10で測ります。
1.B(3, 3) – 3×3-3×3のオリジナルResNetのResidial Block
2.B(3, 1, 3) – 1×1の畳み込みを加える
3.B(1, 3, 1) – すべての畳み込みが同じ次元をもつ、ボトルネック層
4.B(1, 3) – 1×1-3×3の畳み込みに変える
5.B(3, 1) – 3×3-1×1の畳み込みに変える
6.B(3, 1, 1) -更に1×1の畳み込みを加える
K=2 の時の性能比較を行っています。
オリジナルの畳み込み形式 B(3, 3)の性能が最も良いことがわかります。
結果、1×1と組み合わせるよりも、この3×3の畳み込みが有力であることがわかります。
ブロックの組み合わせ結果
層の深さの組み合わせ
WRN-40-2 をベースに様々な l の値(=畳み込みの数)で性能比較を行っています。
これは、l=1 のとき、B(3)を意味し、l=4 のとき、B(3, 3, 3, 3)を意味しています。
l=2 のとき、最も良い結果になりました。これはl=1では表現力がたりず、l が3以上のときは残差接続が減少したため最適化が難しくなったことが要因であると考えられます。
結果、3×3-3×3 の畳み込みを利用することになります。
層の深さの組み合わせの結果

幅の広げ方の組み合わせ
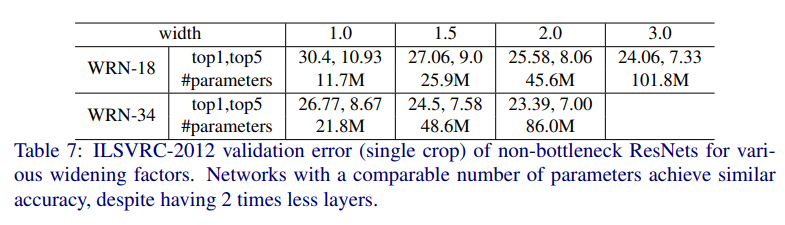
幅と深さを変更しながら、CIFAR-10 と CIFAR-100 で性能を検証しています。
幅を広げることがある程度有力であることがわかりましたが、一方で単純に幅を広げることが性能改善につながるとも言えないことがわかりました。
幅の広さと層の深さの組み合わせの結果
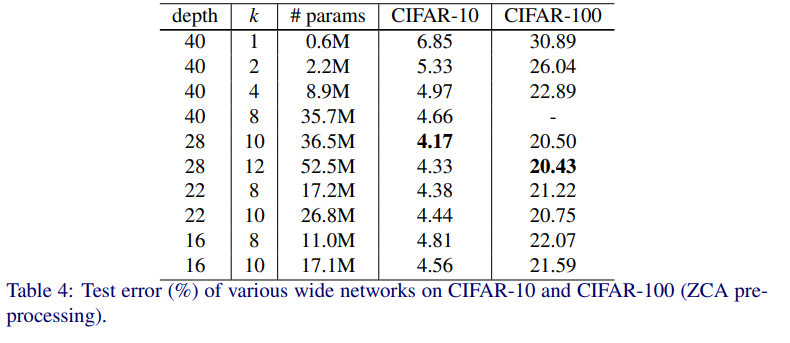
他のモデルとの性能比較
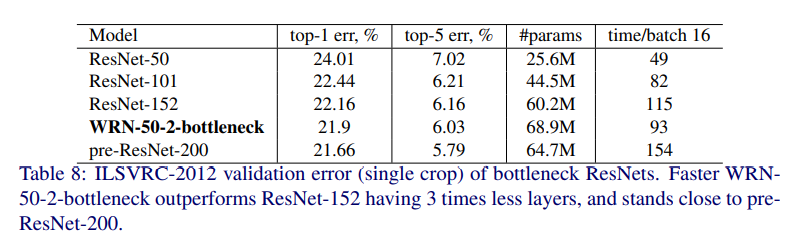
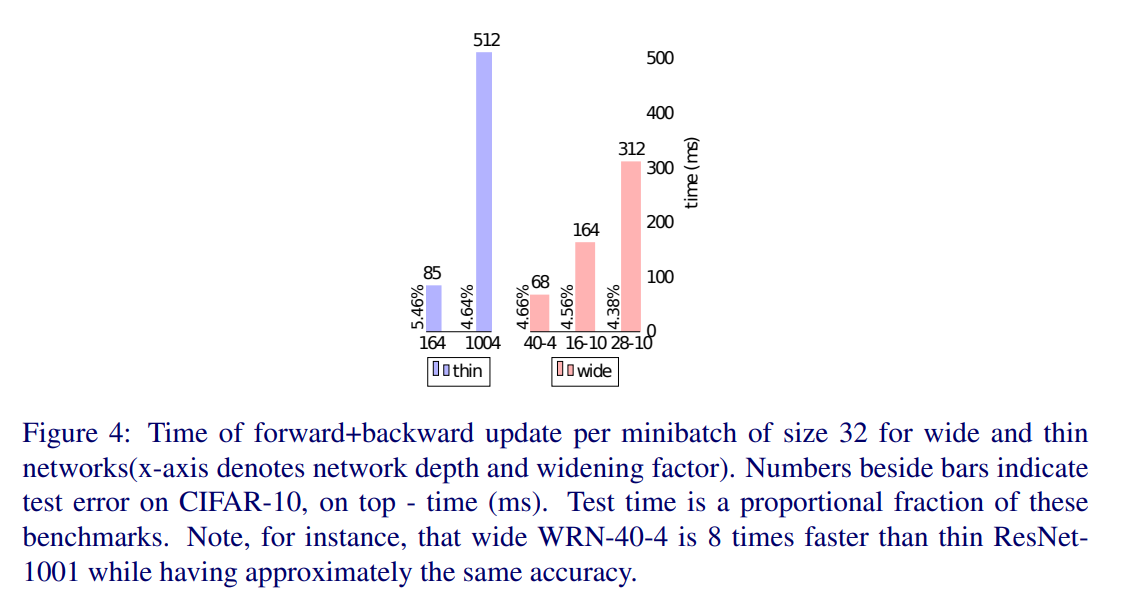
以上を踏まえて、他のモデルとの性能比較を行った結果、SoTAであることが確認されました。なお、ResNet-1001 よりも WRN-40-4 の方がパラメータ数は大幅に削減(10.2×10**6⇒8.9×10*6)されているものの、性能がよく、8倍高速になったことが指摘されています。
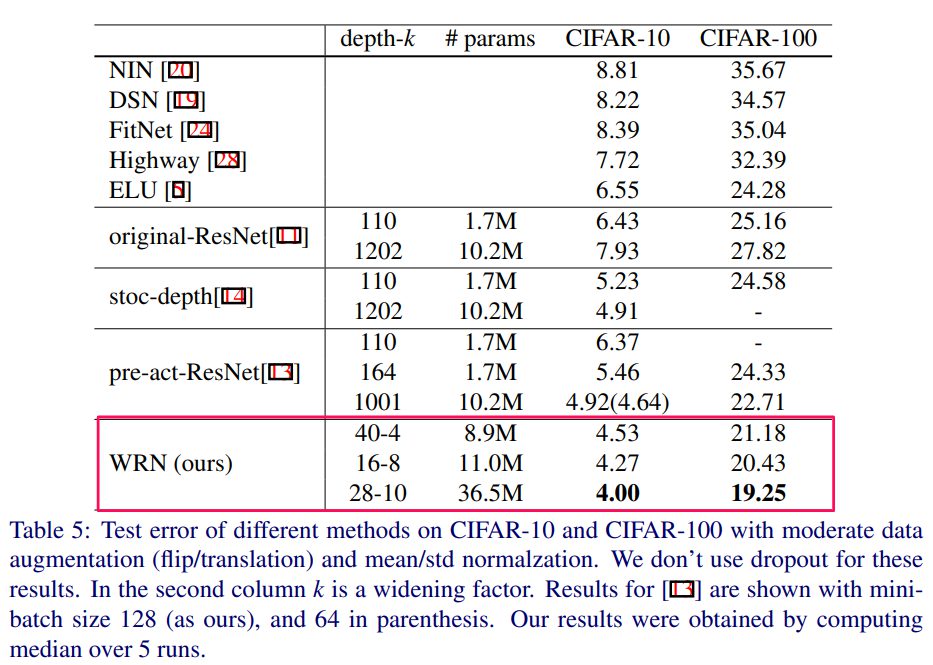
結論
以上から、以下の結論が導かれています。
・異なる深さでも幅を広げることは、性能を改良する。
・パラメータの数が多くなりすぎて、強力な正規化が必要になるまで、幅と深さを増やすことは有効に働く
・通常のResNetよりもWRNの方がよりよい表現を学習でき、またResNetが深くなると計算量が増大するのに対してWRNは効率よく学習することができる。
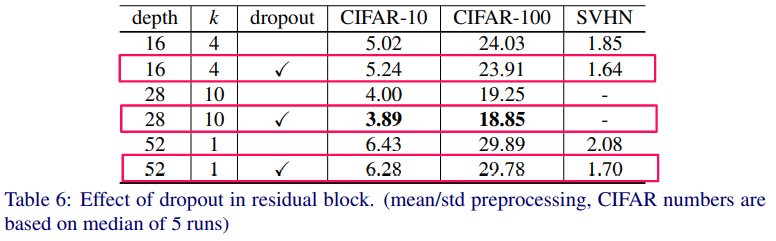
ドロップアウトの効果
ドロップアウトは、前述の「特徴の再利用減少」問題を解決する有力な手段であるため、ブロック内に適用する実験が行われました。
結果は、適応した場合の方が性能がよくなることが確認されました。
ドロップアウト有と無の性能比較
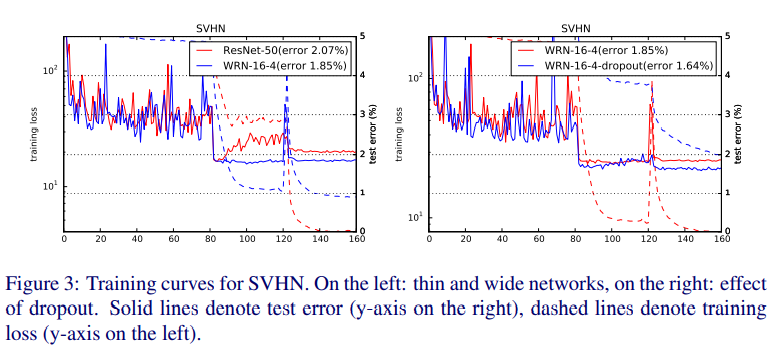
学習時の損失曲線
(左)ResNet と WideResNet の比較 (右)WideResNet のドロップアウト有と無の比較
最終的な比較
以上より、以下のモデル図になるように WideResNet は設計されています。これらを利用して性能比較が行われています。
WideResNet の幅や深さを変更したときの性能比較
オリジナルの ResNet との比較
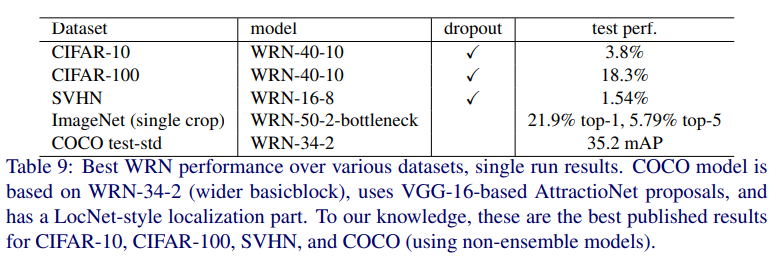
各データセットに対する WideResNet の結果
当時、CIFAR-10、CIFAR-100、SVHN、COCOに対してアンサンブル学習を利用しないモデルのなかでSOTAを達成しました。
オリジナルのResNetとの精度と計算時間の比較
より高速に計算しながら、精度が向上していることがわかります。
まとめ
ResNet の改良モデル WideResNet を解説しました。ResNet は非常に重要なベースモデルであり、ほかにも様々な改良系が存在します。ここで紹介したテクニックや発想はさまざまなところで応用が利くものであるため、理解しておくとよいと思います。