Micorsortが発表した画像処理の汎用化に向けたFoundationモデル「Florence」を紹介します。
1.概要
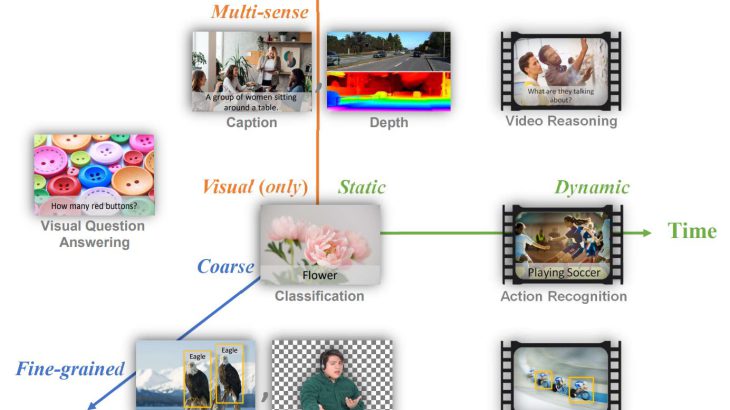
多様でオープンな世界を自動で視覚的に理解するためには、人間の視覚と同様に、特定のタスクに対して最小限のカスタマイズでうまく汎化できるコンピュータビジョンモデルが必要不可欠です。CLIP 、ALIGN 、Wu Dao 2.0 などの既存のビジョン基盤モデルは、主に画像やテキスト表現等のタスクをクロスモーダル共有表現にマッピングすることに焦点を当てていますが、コンピュータビジョンの基礎モデルは、これら全てのタスクのための汎用ビジョンシステムとして機能する必要があります。そこで研究チームは、汎用的なビジョンタスクに対応できるFlorenceの構築に取り組んでいます。Florenceは、粗いもの(シーンレベルの分類など)から細かいもの(物体検出など)、静的なもの(画像など)から動的なもの(動画など)、RGBから複数の感覚(キャプションや深度など)に表現を拡張します。また、Webスケールの画像・テキストデータから普遍的な視覚言語表現を取り込むことで、分類、検索、物体検出、VQA、画像キャプション、動画検索、行動認識などの様々なコンピュータビジョン課題に容易に適用することができます。さらに、新規画像やオブジェクトに対する完全サンプリング微調整、線形プロービング、少数ショット転送、ゼロショット転送といった多くの種類の転送学習において優れた性能を示します。
2.Florenceについて
Florenceは、ノイズの多いWebスケールのデータを用いエンドツーエンドで統一的な目的を持って学習され、モデルが幅広いベンチマークでクラス最高の性能を達成することを可能にしました。Florenceを構築するためのシステムは、以下に示すように、データキュレーション(データの収集・整理)、モデルの事前学習、タスクの適合性、学習インフラで構成されています。
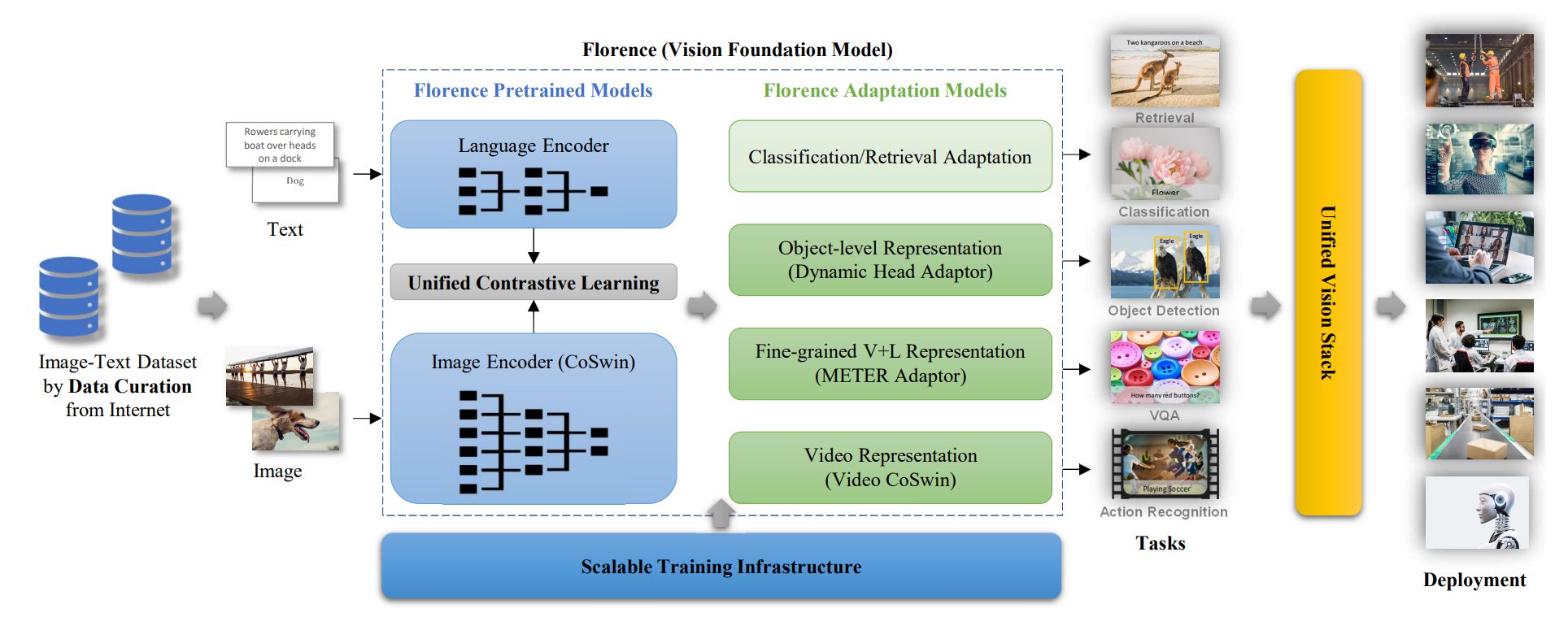
データキュレーション
多様で大規模なデータは、基礎モデルの生命線です。インターネット上で公開されている9億の画像とテキストのペアを学習用の新しいデータセットとして収集・整理します。ウェブクローリングデータは通常ノイズの多い自由形式のテキスト(例:単語、フレーズ、文)であるため、より効果的な学習を達成するために、対照学習と教師あり学習のアプローチよりも改善を示した統一イメージテキスト対照学習目標である、UniCLが導入されています。
モデルの事前学習(表現学習)
画像とテキストのペアから良い表現を学習するために、画像エンコーダと言語エンコーダを含む2塔式アーキテクチャが使用されています。画像エンコーダには、階層的なVision Transformer 、CvT 、Vision Longformer 、Focal Transformer 、CSwin が選択されています。これらの階層的アーキテクチャは画像のスケール不変性をモデル化し、画像サイズに関して線形計算複雑度を持ちます。この特性はオブジェクト検出やセグメント化などの高密度予測タスクに不可欠なものです。
タスクの適合性
Florenceは拡張性と移植性があることが重要です。研究チームは、動的頭部アダプタを用いた空間(シーンからオブジェクトへ)、提案するビデオCoSwinアダプタを用いた時間(静止画像から動画へ)、METERアダプタを用いたモダリティ(画像から言語へ)に沿って学習した特徴表現の拡張を行いました。Florenceは、数ショットおよびゼロショット転移学習によりオープンワールドに効果的に適応するように設計されており、少ないエポックでの追加学習により効率的に展開できます。このモデルは、アプリケーション開発者が利用できる様々なドメイン向けにカスタマイズすることができます。
学習インフラ
エネルギーとコストの両面から、学習基盤の構築は非常に重要です。開発チームは、できるだけ低コストで 学習効率を向上させるため、スケーラブルな学習インフラを開発しました。これは、ZeROなどのいくつかの主要な技術で構成されています。活性化チェックポイント、混合精度学習、勾配キャッシュによりメモリ消費量を大幅に削減し、学習スループットを向上させました。
3.まとめ
汎用ビジョンシステムとして、コンピュータビジョン基盤モデルFlorenceを構築するという試みは、人間のようなAIを目指す統合的なAIシステム構築への一歩となるものです。Florenceのモデルサイズは、今は既存のスケールモデル以下であるが、空間、時間、モダリティに沿った異なるタスクへの拡張に成功し、大きな移植性を持ち、幅広いビジョンベンチマークで新しいSOTA結果を達成しました。
研究チームによると、将来的には、深度や流れの推定、追跡、視覚+言語タスクなど、より多くの視覚タスクやアプリケーションを追加する予定だといいます。Florenceは、何百万もの実世界のビジョンタスクやアプリケーションを強化するビジョン基盤モデル構築への道を開くことが期待されています。さらに、ゼロショット分類と物体検出の予備的な進歩は、教師あり学習との性能差を縮めるためのさらなる研究の動機付けとなる可能性があります。
出典:https://arxiv.org/pdf/2111.11432.pdf
※内容、画像は、上記の論文より引用