
強化学習
概要
正解を与える代わりに、将来の報酬や利益を最大化することで、特定の状況下のおける行動を学習する枠組み。
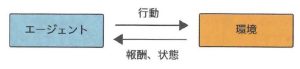
強化学習では、エージェントといわれる何らかの環境に置かれた行動する主体(ロボットのような)が、環境の「状態」を観測し、それに基づいた「行動」を行う。
その結果として環境の状態が変化し、エージェントは環境から「報酬」を受け取ると同時に「新しい状態」を観測する。
この繰り返しによって、エージェントが得る報酬の総和を最大にする行動パターンを身につけることが目標である。
バンディットアルゴリズム
複数案から最適なものをひとつ選ぶとき、報酬が最大となる行動を選択するが、それをランダム的な行動の試行により最適化するためのアルゴリズム。
活用と探索のバランスを取る。
活用
現在知っている情報の中から報酬が最大となるような行動を積極的に選択する。
探索
他にもっと報酬が高い行動があるのではと別の行動を選択する。
マルコフ決定過程モデル
次に起こる事象を確率が、これまでの過程と関係なく、現在の状態によってのみ決定される確率過程。
状態遷移がマルコフ性を満たす。
マルコフ性
「現在の状態から将来の状態に遷移する確率は、現在の状態にのみ依存し、それより過去の状態には一切依存しない」という性質。
価値関数(Q値)
人間が感じる価値と客観的な価値の間には誤差があるという傾向。
最適な方策を直接求める代わりに、状態・行動によって得られる将来の累積報酬をその状態・行動の「価値」とし、その価値が最大となり適切な行動を取るような学習をするアプローチが考えられた。
それぞれの価値を表す関数である、状態価値観数および行動価値関数が導入される。
単純に「価値関数」と言った場合、行動価値関数を指す。
方策勾配
方策
「ある状態からとりうる行動の選択肢、およびその選択肢をどう決定するかの戦略」のことで、各行動を選択する確率表現となる。
方策勾配法
方策をあるパラメータで表される関数とし、累積報酬の期待値が最大となるようにそのパラメータを学習することで、直接方策を学習していくアプローチ。
行動の選択肢が大量にある場合、それぞれの価値を算出するだけでも莫大な計算コストがかかってしまい、学習が行えない懸念がある。
そのため方策勾配法は、ロボット制御など、特に行動の選択肢が大量にあるような課題に用いられる。