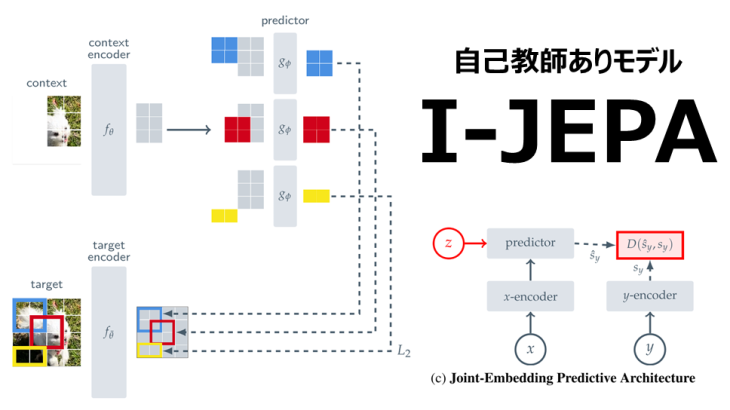
本稿では「Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture」にて紹介された、画像からの自己教師あり学習のための非生成アプローチである画像ベースの結合埋め込み予測アーキテクチャ(I-JEPA)を紹介します。I-JEPAは、一つのコンテキストブロックから同じ画像内の複数のターゲットブロックの表現を予測する手法です。具体的には、十分なスケールでターゲットブロックをサンプリングし、空間的に分散した情報量の多いコンテキストブロックを使用します。このアプローチはスケール性に優れており、線形分類からオブジェクトカウント、深度予測までの幅広いタスクで高い精度を実現しました。
基本情報
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
参照URL:
https://www.slideshare.net/DeepLearningJP2016/dlselfsupervised-learning-from-images-with-a-jointembedding-predictive-architecture
PDF版は以下を参考下さい。
イントロダクション
自己教師あり学習には一般に不変性ベースの方法と生成的な方法の2つがあります。
不変性ベースの方法は、異なるビュー、変換、ノイズから生成された同一のオブジェクトに対して同じ表現を学習することを目指します。そのため、この手法は「不変性」に重点を置いており、データの特定の変換に対するモデルの「不変性」を向上させることを目指しています。例えば、画像をランダムに回転させたり、ズームしたりすると、それらの変換に対する不変性を持つ特徴が学習されます。
生成的な手法は、マスクノイズアプローチとも呼ばれ、ピクセルレベルまたはトークンレベルでの予測を行います。この手法は、画像モダリティを超えて一般化が可能ですが、得られる表現の意味レベルが低いという課題があります。
これらの手法の利点を最大限に活用するためには、より複雑な適応メカニズム(例えばエンドツーエンドの微調整)が必要とされています。
そこで、画像変換によるエンコードの過度な事前知識を避け、自己教師あり学習での表現の意味レベルを向上させる方法を提案し、その具体的な手法として「共同埋め込み予測アーキテクチャ(I-JEPA)」を提案しました。
I-JEPAの基本的なアプローチ
- 抽象的な表現空間における欠落情報の予測:具体的には、特定のコンテキストブロックが与えられた場合に、同じ画像内の様々なターゲットブロックの表現を予測します。
- 抽象的な予測ターゲットの利用:既存のピクセル/トークン空間での予測による生成的手法と比べ、I-JEPAは抽象的な予測ターゲットを利用します。これにより、不必要なピクセルレベルの詳細を排除し、モデルがより多くの意味的特徴を学習する可能性を提供します。
- マルチブロックマスキング戦略の提案:情報量の多い(空間的に分布した)コンテキストブロックを用いて、画像中の十分に大きなターゲットブロックを予測することの重要性を強調します。
関連研究
アーキテクチャの比較

(a) 互換性のある信号 x と y に対しては、モデルは同様の埋め込みを出力するように学習します。一方、互換性のない入力に対しては、モデルは異なる埋め込みを生成するように学習します。
(b) モデルは、互換性のある信号 x から信号 y を直接再構成するように学習します。この再構成をより容易にするため、追加の(潜在的な)変数 z を基にしたデコーダネットワークを使用します。
(c) モデルは、互換性のある信号 x から信号 y の埋め込みを予測するように学習します。予測をより容易にするために、追加の(潜在的な)変数 z を基にした予測ネットワークを使用します。
視覚表現学習では長年にわたり、欠損や破損した感覚入力の値を予測する方法が研究されてきました。その例として、ノイズ除去オートエンコーダー、コンテキストエンコーダー、欠損した画像の着色をノイズ除去タスクとして扱う手法が挙げられます。最近では、マスクされた画像モデリングの文脈でViTを用いて欠損した入力パッチを再構成する手法において、画像のノイズ除去のアイデアが再評価されています。また、MAEではエンコーダーが可視画像パッチのみを処理する効率的なアーキテクチャを提案し、BEiTはトークン化された空間で欠損パッチの値を予測します。さらに、SimMIMは古典的なHistogram of Gradients特徴空間に基づく再構成目標を探求し、ピクセル空間の再構成よりも優れた性能を示しています。一方、JEPAの目指すところは、ダウンストリームタスクで広範なファインチューニングを必要としない意味的な表現を学習することです。
data2vec, Context Autoencoders(CAE)
これらの手法は、I-JEPAに最も近いものといえます。data2vecはオンラインターゲットエンコーダを通じて表現を学習し、一方CAEは再構成損失とアライメント制約の和を最適化して表現を学習します。これらの手法はいずれも欠損パッチの表現の予測に焦点を当てています。しかし、これらと比較すると、I-JEPAは計算効率の大幅な改善を示し、さらに意味的な既成表現を学習します。
DINO, MSN, iBOT
結合埋め込みアーキテクチャに基づく手法は、事前学習の段階で意味的な画像表現を学習するために、手動によるデータ拡張に依存しています。特に、MSNは事前学習時にマスキングを追加的なデータ拡張として使用し、一方iBOTはdata2vecスタイルのパッチレベル再構成損失と視覚的不変性の損失を組み合わせています。これらの手法は各入力画像の複数のユーザー生成ビューを処理する必要があり、このためスケーラビリティが制限されるという共通の問題を抱えています。I-JEPAは各画像の単一のビューのみを処理するだけで良いため、この問題を解消しています。例えば、I-JEPAで学習したViT-Huge/14は、iBOTで学習したViT-Small/16よりも計算量が少なくて済むという利点があります。
手法
I-JEPAは次のような手順で進行します。
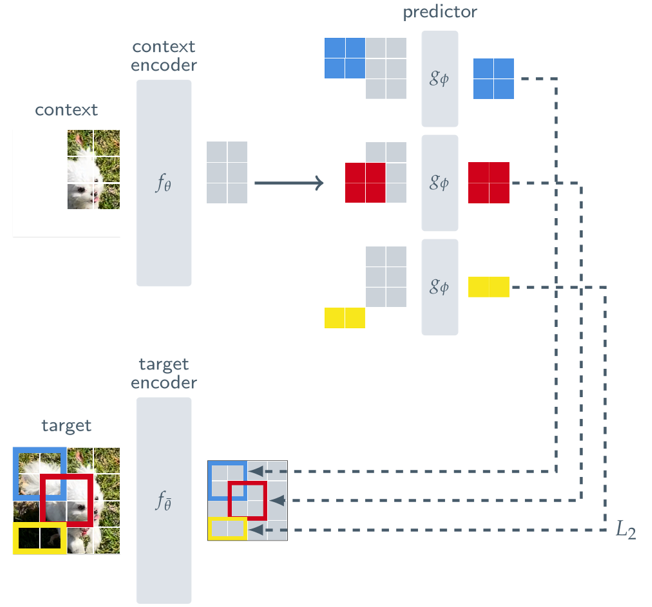
(1) 与えられたコンテキストブロックを利用して、同一画像内の複数(デフォルトは4つ)のターゲットブロックの表現を予測します。
(2) コンテキストエンコーダ、ターゲットエンコーダ、予測器にはViTを使用します。これはMAEに類似していますが、I-JEPAは非生成的であり、予測は表現空間内で行われます。
(3) 予測器はコンテキストエンコーダの出力を受け取り、位置トークン(色で示される)を条件として、特定の位置のターゲットブロックの表現を予測します。ターゲットの表現はターゲットエンコーダの出力に対応し、その重みはコンテキストエンコーダの重みの指数移動平均によって更新されます。
context
I-JEPAは、(0.85,1.0)の範囲のランダムなスケールと単位アスペクト比を用いて、画像から1のブロック X をサンプリングします。これにより、context(コンテキスト)を得るための初期情報が生成します。コンテキストブロックから重複する領域を除去することで、自明でない予測タスクが保証されます。その後、マスクされたコンテキストブロック xはコンテキストエンコーダにより処理され、対応するパッチレベル表現が得られます。
target
I-JEPAは、target(ターゲット)を画像ブロックの表現として対応させます。入力画像はN個の非重複パッチのシーケンスに変換され、それらはターゲット・エンコーダーによってパッチレベル表現 Syに変換されます。この変換により、各パッチは自身の意思の表現 Syを獲得します。ターゲットの表現 Syから M個のブロック(重複可能)をランダムにサンプリングし、損失のターゲットを確立します。通常、Mは4と設定され、アスペクト比(0.75.1.5)とスケール(0.15~0.2)の範囲でブロックをサンプリングします。特徴は、ターゲット・ブロックが入力するのではなく、ターゲット・エンコーダの出力をマスクすることで生成されます。
コンテキストとターゲット・マスキング戦略の例
与えられた画像に対して、特定のスケールとアスペクト比の範囲内からターゲットブロックをランダムに4つサンプリングし、さらに異なるスケール範囲からコンテキストブロックをサンプリングします。この戦略により、ターゲットブロックは意味的な情報を持ち、一方で、コンテキストブロックは豊富な情報を提供し、効率的に処理可能な疎な表現を保証します。

Predication
コンテキスト・エンコーダの出力 Sxから M個のターゲット・ブロック表現 Sy(1),…,Sy(M)を予測します。これらは、予測器(・,・)を用いて行われ、各パッチのマスクトークンとコンテキスト・エンコーダ Sxの出力の入力として、パ地レベルの予測を生成します。マスクトークンは、位置埋め込みが追加された共有学習可能なベクトルによってパラメータ化されます。これにより、ターゲットブロックの予測は対応するマスク・トークンを条件として行われます。これにより、ターゲットブロックの予想 Sy(1),…Sy(M)が得られます。
Loss
損失は、予測されたパッチレベル表現とターゲットパッチレベル表現の間の平均 L2距離を用います。
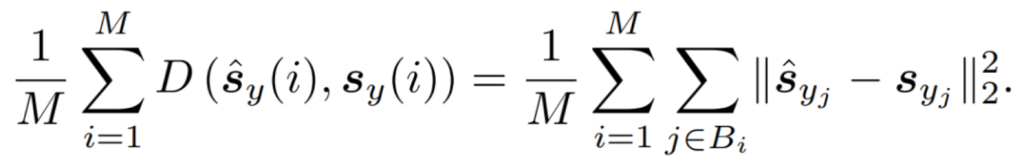
予測器とコンテキストエンコーダθのパラメータは、勾配ベースの最適化によって学習されます。ターゲットエンコーダθのパラメータは、コンテキストエンコーダの指数移動平均によって更新されます。
実験
画像分類
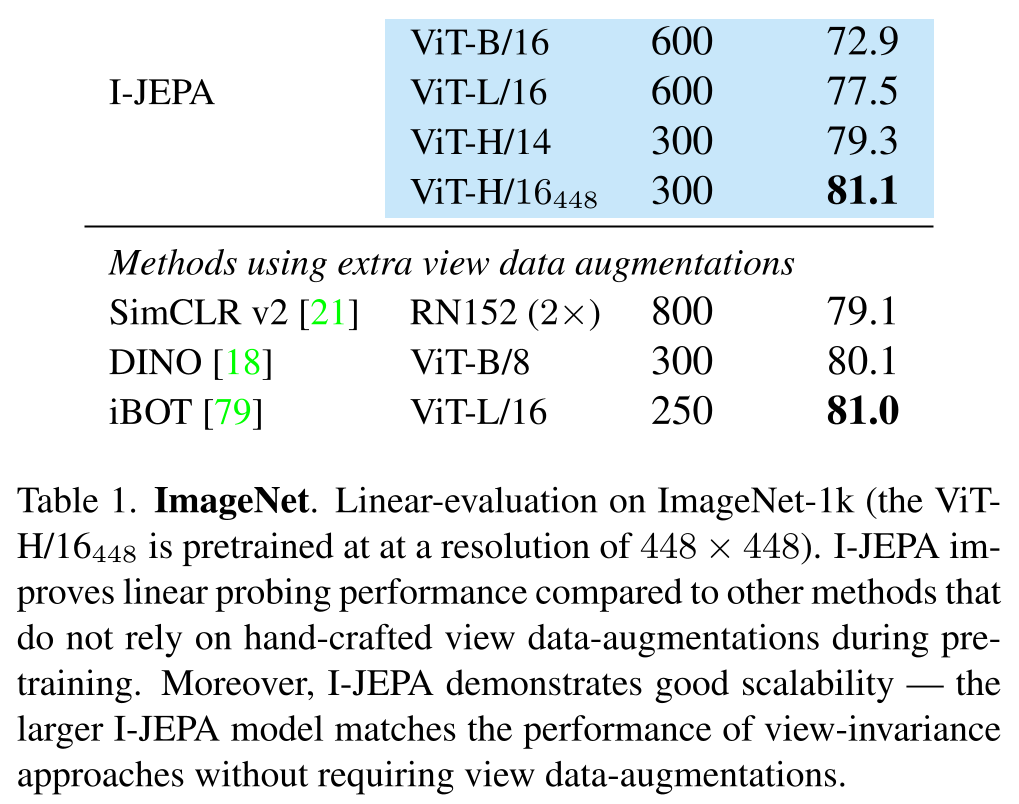
ImageNet を用いた評価
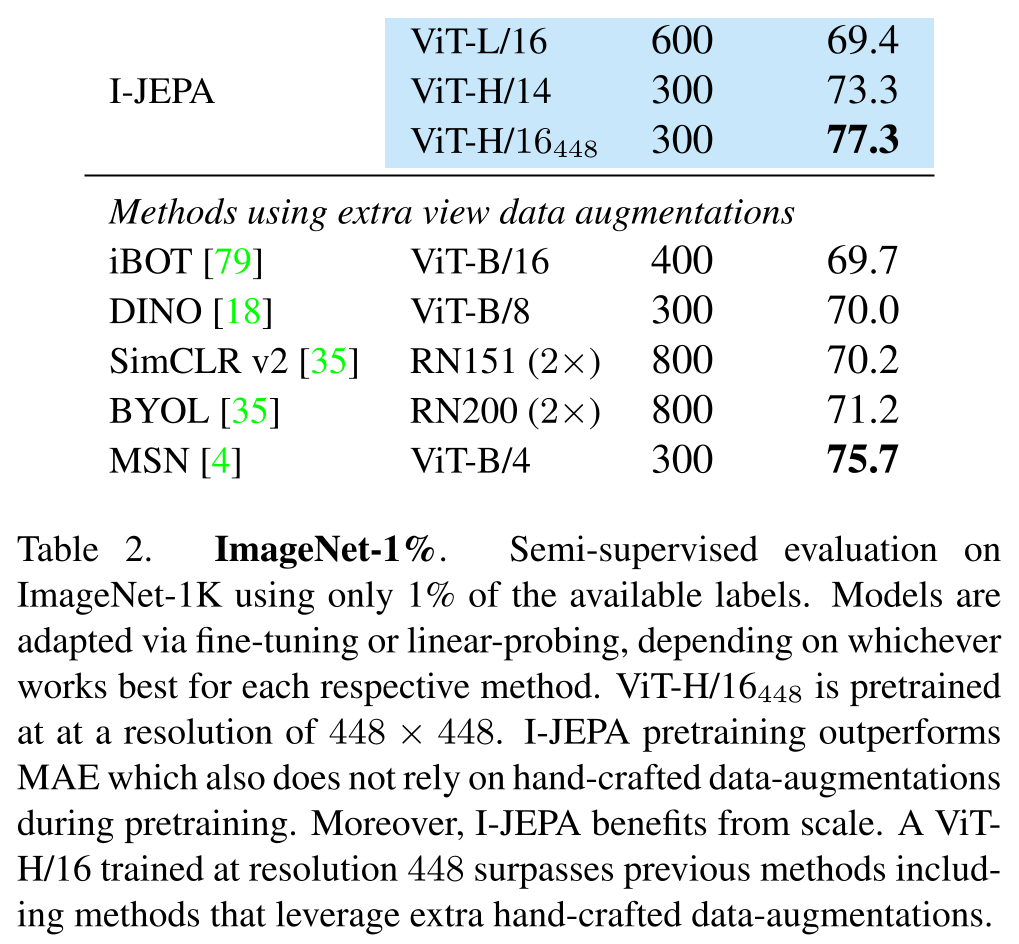
I-JEPAは、手動でのビューデータの拡張に頼らない他の手法と比較して、ImageNet-1k(ViT H/16_448は448×448の解像度で事前学習済み)における線形評価の性能を向上させました。
また、この手法は優れたスケーラビリティを持つため、より大規模なI-JEPAモデルはビューデータの拡張を必要とせずに、ビュー不変性のアプローチと性能が一致します。
ImageNet-1K 1% を用いた評価
I-JEPAは、ViT H/14アーキテクチャを用いた場合、data2vecで事前学習されたViT-L/16と同等の性能を示し、それでいてその計算量は大幅に少ないという利点があります。
さらに、解像度を上げることで、事前学習中に手動でデータ拡張を追加する結合埋め込み手法(MSN、DINO、iBOTなど)を上回る結果を示しました。これはI-JEPAの有効性を示す強力な証拠です。
また、ImageNet-1Kの半教師あり評価で、利用可能なラベルのわずか1%だけを使用した際でも、I-JEPAの事前学習は手動で作成したデータ拡張に依存しないMAE(Masked Autoencoder for Discrete Data)を上回る性能を示しました。この結果から、I-JEPAはスケールの恩恵を大いに受けることができるといえます。
具体的には、解像度448で訓練されたViT H/16は、手動によるデータ拡張を使用する従来の手法を凌駕しました。
Linear-probe transfer
線形プローブを使用した各種のダウンストリーム画像分類タスクでの性能を示します。その結果、I-JEPAはデータ拡張を用いない従来手法(MAE と data2vec)を大幅に上回る性能を示しました。
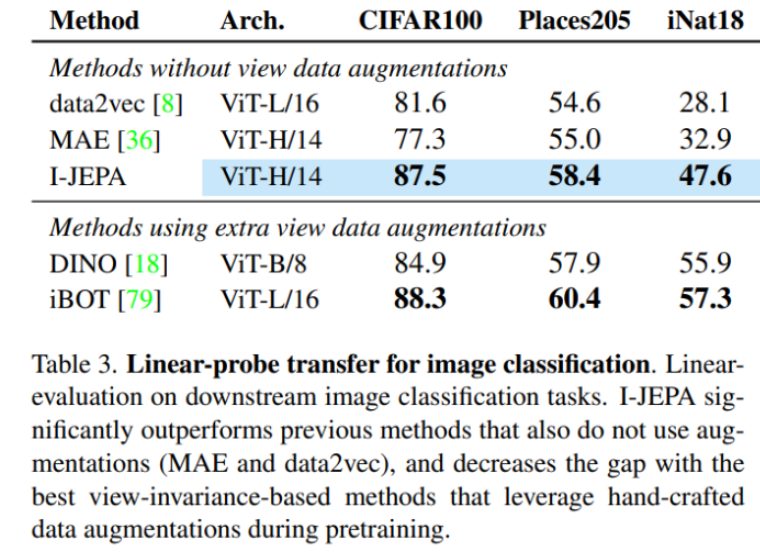
さらに、I-JEPAはデータ拡張を活用する最良のビュー不変性ベースの手法との差を縮めました。線形プローブを使用するCIFAR100とPlace205では、DINOを上回る結果を得ました。
Local Predication Task
Local Prediction task
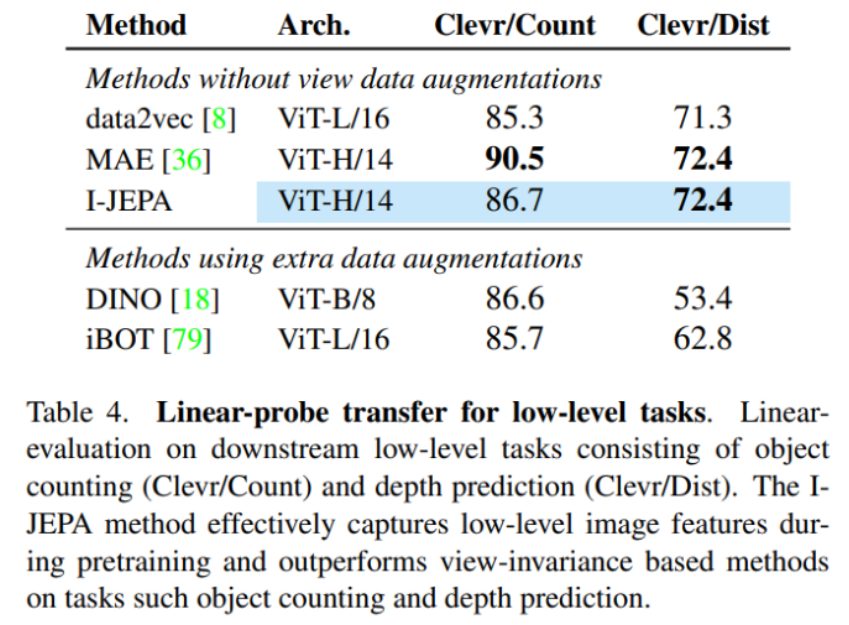
I-JEPAの性能が、低レベルのタスクであるClevrデータセットの物体カウントと奥行き予測において、ビュー不変性ベースの手法(DINOやiBOT等)を上回っていることが示されています。
これはI-JEPAが事前学習中に低レベルの画像特徴を効果的に捉え、その結果として低レベルで高密度な予測タスクに優れた性能を発揮することを確認するものです。
Scalability
モデルの効率性
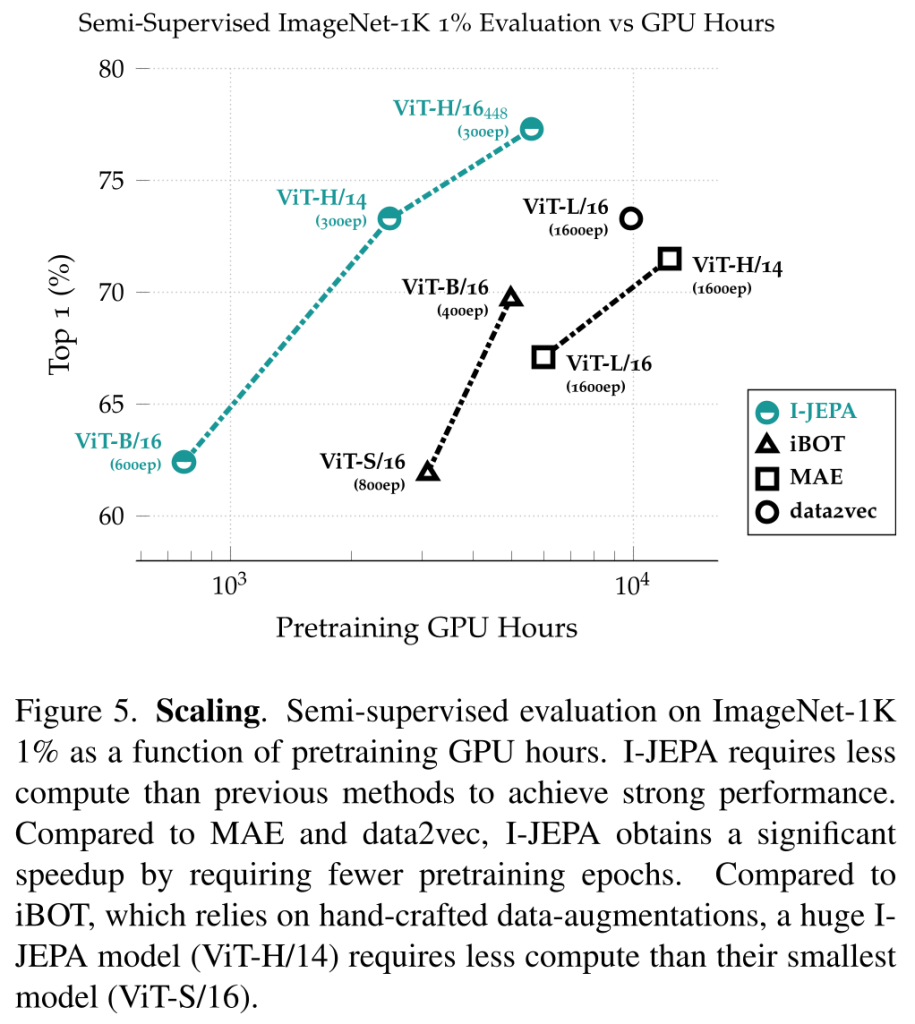
I-JEPAは以前の手法よりも少ない計算量で、データ拡張に頼らずに高い性能を達成しています。具体的には、再構成に基づく手法(例:MAE)と比較して、I-JEPAは表現空間でターゲットを計算することにより余分なオーバーヘッドを導入するものの、約5倍少ない反復で収束し、大幅に計算量を削減できます。
さらに、データ拡張に依存し、各画像の複数のビューを作成・処理するビュー不変性に基づく手法(例:iBOT)と比較すると、I-JEPAは著しく高速に実行される。特に、大きなI-JEPAモデル(ViT-H/14)は、小さなiBOTモデル(ViT-S/16)よりも少ない計算量で済みます。
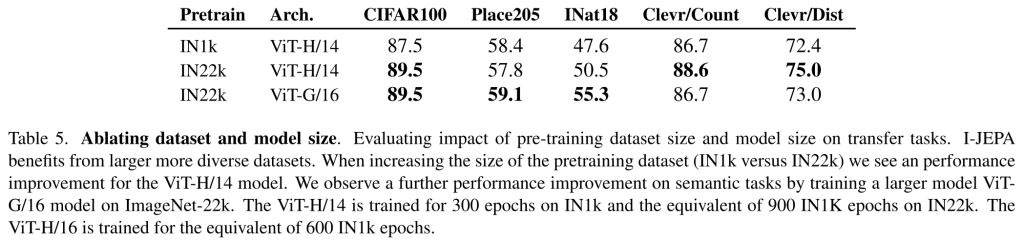
データサイズによるスケーリング
事前学習データセットのサイズを増やすと、意味的なタスクと低レベルのタスクの両方で転移学習の性能が向上することが示されています。これは、より大きく多様なデータセットでの事前学習が、様々なタスクの学習において有益であることを示しています。
モデルサイズによるスケーリング
IN22Kでのプレトレーニング時に、大きなモデルサイズ(具体的には、ViT-G/16)が有効であることを示しています。
ViT-G/16をプレトレーニングすると、ViT-H/14モデルに比べて画像分類タスク(例えば、Place205やINat18)の下流性能が大幅に向上します。しかし、この大きなモデルサイズは低レベルのタスクの性能を向上させません。これは、ViT-G/16がより大きな入力パッチを使用するため、局所的な予測タスクに対しては不利である可能性があるためです。
Predictor Visualizations
予測器の学習効果を評価
予測器がターゲットの位置の不確実性を正確に捉えるかどうかを調査するために、事前学習後に、予測器とコンテキスト・エンコーダの重みを固定し、予測器の出力の平均プーリングをピクセル空間にマップバックするために、RCDM(Representation Conditional Diffusion Model)フレームワークに基づいてデコーダを訓練します。
予測器の出力の視覚化は、予測器が位置の不確実性を正確に捕捉し、高レベルのオブジェクト部分(例えば、鳥の背中や車の上部)を正確に生成できることを示している。しかし、正確な低レベルの詳細と背景情報を破棄する傾向があります。

Ablations
マスキング戦略の比較
マルチブロックマスキングを、画像を4つの大きな象限に分割し、1つの象限をコンテキストとして他の3つの象限を予測することを目的とするラスタライズドマスキングや、再構成ベースの手法で一般的に用いられる従来のブロックマスキングやランダムマスキングなどの他のマスキング戦略と比較しました。
ViT-B/16を300エポック学習した後、利用可能なラベルの1%のみを使用したImageNet-1KでのLinear evaluationにおいて、このマルチブロックマスキング戦略の効果を評価しています。

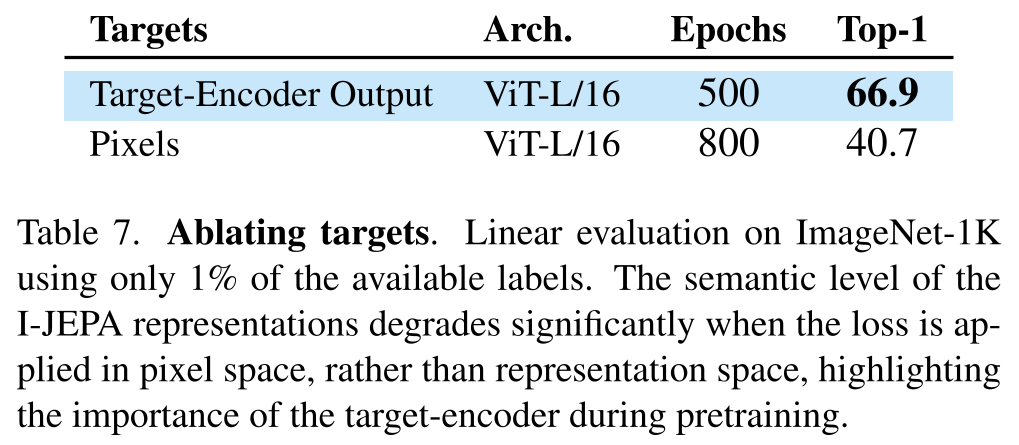
表現空間での予測
ImageNet-1Kの1%のデータで行われた線形プローブを使用した評価により、I-JEPAのローショット性能は、損失がピクセル空間ではなく表現空間で計算されることにより向上することが明らかになりました。これはターゲットエンコーダが抽象的な予測ターゲットを生成する能力を強化するためと推測されます。ピクセル空間での予測は線形プロービング性能を著しく低下させることが示されており、これは事前学習中のターゲットエンコーダの重要性を強調しています。
まとめ
I-JEPAは、手動によるデータ拡張を必要とせずに、高性能な表現を学習する能力を有する新しい自己教師あり学習法です。ImageNet-1Kの線形プローブ、半教師ありの1% ImageNet-1K、及び意味転移タスクにおいて、ピクセル再構成手法(例:MAE)を上回る結果を示すことができました。
意味的なタスクにおいてビュー不変の事前学習アプローチと同等、またはそれ以上の性能を発揮します。さらに、低レベルの視覚タスク(例:オブジェクトのカウントや深度の予測)においても優れたパフォーマンスを達成します。これは、よりシンプルで誘導バイアスの少ないモデルを用いることで、より幅広いタスクに対応可能であることを示しています。
スケーラブルで効率的です。具体的には、ViT-H/14をImageNetで事前学習するのに必要な時間は、iBOTで事前学習したViT-S/16より2.5倍以上速く、またMAEで事前学習したViT-H/14よりも10倍以上効率的です。予測を表現空間で行うことで、自己教師あり事前学習に必要な総計算量を大幅に削減することが可能となります。