はじめに
Facebookが多言語NLP用のデータセット、Multilingual LibriSpeech(MLS)を発表したので、紹介します。

A new open data set for multilingual speech research
https://ai.facebook.com/blog/a-new-open-data-set-for-multilingual-speech-research/
論文
MLS: A Large-Scale Multilingual Dataset for Speech Research
https://arxiv.org/abs/2012.03411
データ置き場
http://openslr.org/94/
モデル(GitHub)
https://github.com/facebookresearch/wav2letter/tree/master/recipes/mls
概要
自然言語処理分野は近年飛躍的な成長を見せていますが、すべての言語で平等に進歩しているわけではありません。母語話者が多く、実質的に世界標準語といえる英語のデータが圧倒的に多く、ほかの言語は置いて行かれている現状にあります。そのため、今回、Facebookが新たに多言語モデル開発のためのデータセットMultilingual LibriSpeech(MLS)を公開しました。ただし、欧州で使われる8言語で、アジア圏の言語は含まれていません。
MLS
MLSは、各言語ごとに5万時間分の音声とスクリプトを含んでおり、8言語(英語、ドイツ語、オランダ語、フランス語、スペイン語、イタリア語、ポルトガル語、ポーランド語)で構成されています。また無制限のライセンスで構成されている点も特徴です。トレーニングデータだけでなく、比較用にトレーニングされた言語モデルが提供されています。
構築手法
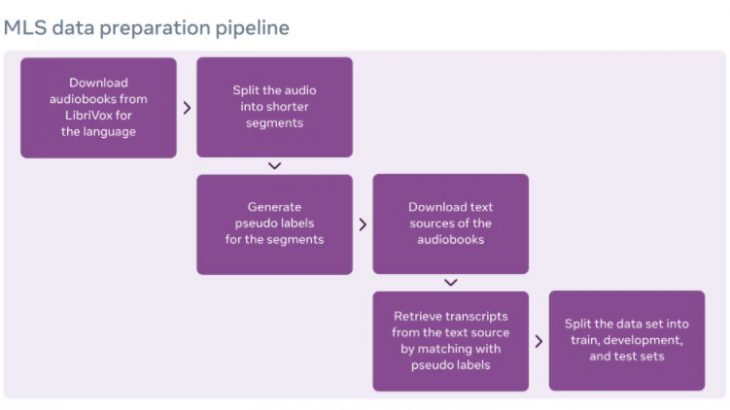
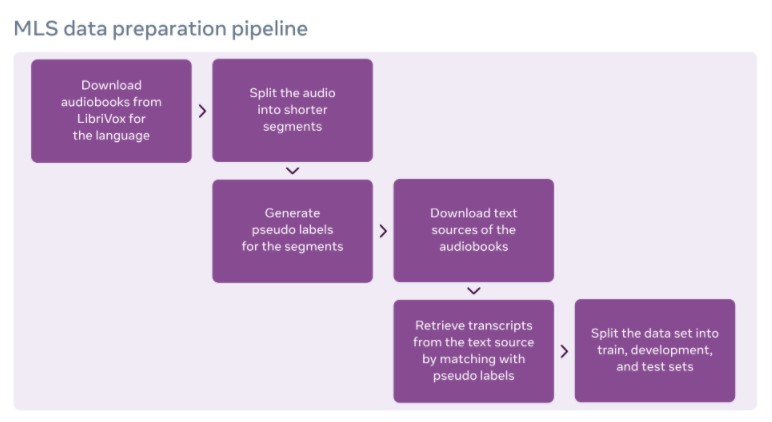
オーディオをセグメント化し、オーディオブックのテキストと並べることで、オーディオセグメントにベストマッチするトランスクリプトを取得しています。実際のオーディオブックは非常に長いので、Facebook AIのオープンソースのwav2letter@anywhereフレームワークを使ってストリーミング推論と整列を行いました。(なお言語モデリングデータの作成には、Project Gutenbergデジタルライブラリのパブリックドメインの書籍が利用されています。)開発セットとテストセットに重複する書籍を慎重にフィルタリングし、言語固有のテキスト正規化を行い、言語モデルコーパスを作成しています。
中身
オーディオブックの音声とそれに対応したトランススクリプトが含まれています。また制約付きもしくは教師なしのASRのベンチマークであるLibri-Lightの成功から、含まれているすべての言語について、制約付きラベル付きデータ(10分、1時間、10時間)のサブセットを提供しています。これにより、自己教師ありや半教師ありなど、少量のラベルデータが利用可能な訓練に適したデータセットとなっています。
有用性
MLSの英語データセットは、LibriSpeechのトレーニングデータの約47倍です。また、無制限なライセンスで提供しているものとしては、ほかにほとんど例がなく、非常に使いやすいトレーニングデータセットになっている点がほかのデータセットと比べ、有用なものとなっています。
ベースラインモデル
ベースライン音響モデルをトレーニングし、各言語の5gram言語モデルを使用してそれらをデコードしました。 MLSの英語サブセットでトレーニングされたモデルは、LibriSpeechの標準的なノイズの多いテストセットで評価すると、LibriSpeechデータを使用してトレーニングされた同じモデルと比較して、単語誤り率が20%向上しました。
まとめ
自然言語処理の発展が英語に偏っている問題は以前から、強く指摘されています。現状では、英語に匹敵するほどの自然言語処理が可能な言語は国家的にAI研究を推進し、開発者も多く、何より話者が圧倒的に多い、中国語くらいではないかとされています。そのため、多言語用のデータセットの公開などは、言語間の平等という意味で非常に重視されています。今回は欧米の8言語だけですが、今後アジア圏の言語も増えることを期待したいところです。