はじめに
Googleとマサチューセッツ大学アマースト校と共同で、オープンドメインの長文形式質問応答タスクでSOATを達成したモデルを発表すると同時に、現在の同タスクで使われている評価指標とデータセットに関する問題点を指摘しました。
Progress and Challenges in Long-Form Open-Domain Question Answering
https://ai.googleblog.com/2021/03/progress-and-challenges-in-long-form.html
●論文
Hurdles to Progress in Long-form Question Answering
https://arxiv.org/abs/2103.06332
概要
オープンドメインの長文形式の質問応答 Open-domain long-form question answering (LFQA) はNLPの基本的なタスクのひとつです。特定の質問に関連するドキュメントを取得し、それらを使用して複雑な文章を生成します。Googleとマサチューセッツ大学アマースト校の共同研究チームがRTとREALMを利用したSOATモデルと開発しました。
同時に、現在のベンチマークと評価指標に関する問題点として、1)モデルが条件付きの検索を実際に使用しているかどうかわからない、2)入力をコピーしただけなどのベースラインモデルが、RAG / BART + DPRなどの最新のシステムを打ち負かしてしまっている、 3)学習用データセットと検証用データセットに大きな重複がある可能性があることなどを指摘しており、今後の改良の必要性を報告しています。
詳細
研究チームは最先端の結果をだすために以下のモデルを組み合わせたものを利用しています。
・RT(Routing Transformer)
アテンションベースのモデルを長いシーケンスにスケーリングできる最先端のスパースアテンションモデル。
・REALM(Retrieval-Augmented Language Model Pre-Training)
特定のクエリに関連するウィキペディアの記事の検索を容易にする検索ベースのモデル。
また、より事実に基づく根拠を促進するため、回答を生成する前に、特定の質問に関連するいくつかの取得されたウィキペディアの記事からの情報を組み合わせます。これらのモデルは、ELI5(LFOAタスク向けに公開されている唯一の大規模なデータセット)でSOATを達成しました。しかし、同時にELI5の問題点も明らかになりました。
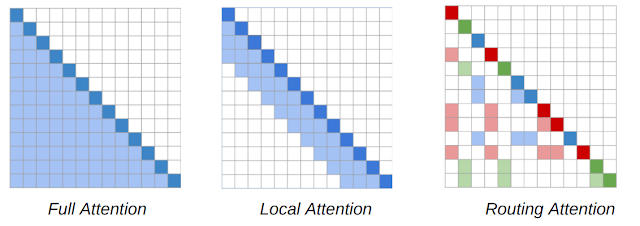
RTについて
通常のTransformerはシーケンス長Nに対して、N**2になります。それに対して、RTモデルは、動的なコンテンツベースのスパースアテンションメカニズムを導入し、Transformerモデルのアテンションの複雑さをn**2からn**1.5に減らします。これにより、単語がすぐ近くにある単語にしか対応できないTransformer-XLなどの方法とは異なり、各単語はテキスト全体のどこにでも他の関連する単語に対応できます。
RTの基本的なアイディアは、他のすべてのトークンに対応する各トークンは冗長であることが多く、ローカルとグローバルのアテンションの組み合わせによって概算される可能性があるということです。ローカルアテンションにより、各トークンはモデルの複数のレイヤーにわたってローカル表現を構築できます。各トークンは近くのローカル表現に参加し、ローカルの一貫性と流暢さを促進します。ローカルアテンションを補完するために、RTモデルはミニバッチk-meansクラスタリングも使用して、各トークンが最も関連性の高いトークンのセットにのみ参加できるようにします。
REALM REALMについて
LFQAのタスクにおけるRTモデルの有効性を実証するために、REALMからの取得と組み合わせます。REALMモデルは、最大の内積検索を使用して、特定のクエリまたは質問に関連するWikipediaの記事を検索する検索ベースのモデルです。モデルは、NaturalQuestionsデータセットでのファクトイドベースの質問応答用に微調整されました。
REALMは、BERTモデルを利用して質問の適切な表現を学習し、SCANNを使用して質問表現とトピックの類似性が高いウィキペディアの記事を取得します。次に、これをエンドツーエンドでトレーニングして、QAタスクの対数尤度を最大化します。
REALMの基本的なアイディアは、質問の表現を重視し、その教師回答に近づきながら、ミニバッチ内の他の回答から分岐することです。これにより、システムがこの質問表現を使用して関連アイテムを取得するときに、教師回答に「類似した」記事が返されるようになります。

評価
KILTベンチマークの一部であり、現在公開されている唯一の大規模LFQAデータセットであるELI5データセットを使用して、モデルをテストしました。
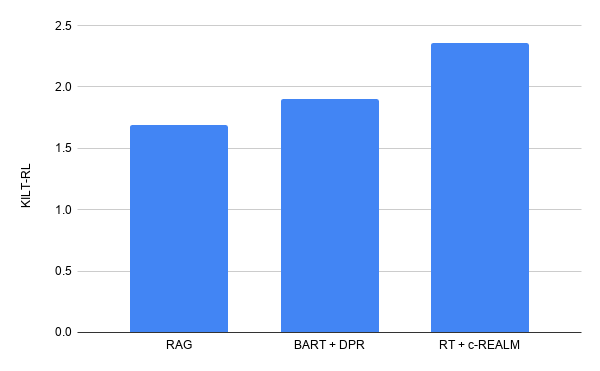
KILTベンチマークは、Precision(R-Prec)を使用したテキスト検索と、ROUGE-Lを使用したテキスト生成を測定します。2つのスコアを組み合わせて、リーダーボードでのモデルのランキングを決定するKILTR-Lスコアを算出します。事前にトレーニングされたRTモデルを、KILTのELI5データセットのc-REALMからの取得とともに微調整します。
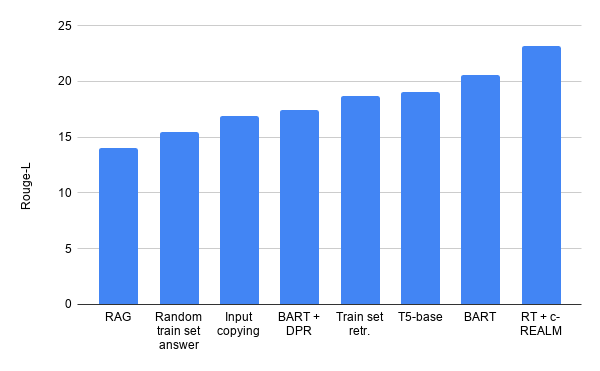
研究チームはELI5でのKILTリーダーボードで最先端の結果をだしました。(KILTR-Lの合計スコアは2.36です。)リーダーボード上の他のモデルと同様の数のパラメーターを持ちながら、BART + DPRの以前のリーダーボードエントリ(KILT R-Lスコア1.9)からの改善がみられます。テキスト生成の品質に関しては、T5、BART + DPR、RAGに比べてそれぞれ+ 4.11、+ 5.78、+ 9.14Rouge-Lの改善が見られます。
懸念事項
しかし、実験結果を詳細に分析してみると、下記の問題が発生している可能性があることがわかりました。
(1) 本システムが生成した回答は、実際には検索した文書に基づいていない。
(2) ELI5にはトレーニングとテストの重複が多く、ELI5の検証問題の少なくとも81%がトレーニングセット内で言い換えられた形で発生している。
(3) ROUGE-Lは、生成された回答の品質を測る指標としては有益ではなく、容易に不正が可能である。
(4) 他のテキスト生成タスクで使用された人間による評価は、LFQAでは信頼性が低い。

また、入力文をコピーしただけの粗雑なベースラインモデルでも、現在の最先端モデルよりもよい精度が出てしまっています。
これらの問題点を軽減するため、今後のLFQAの研究をより厳密なものにし、有意義なものにしていく必要があると提言しています。
まとめ
今回、ベンチマークと評価指標の問題点が指摘されました。ベンチマークではよい成果を残すが現実では実用に耐えないなどの問題はNLPだけでなく画像処理などでも問題視されていることであり、研究が進められています。ベンチマークにモデルそのものが過剰適合してしまっている、そもそもベンチマークの設計に問題があるなど多くの可能性が指摘されていますが、今後重要な研究テーマとなりそうです。