はじめに
Googleから新たに姿勢推定に関するアルゴリズムPr-VIPEが提案されたので、ご紹介します。
Recognizing Pose Similarity in Images and Videos
https://ai.googleblog.com/2021/01/recognizing-pose-similarity-in-images.html
論文
View-Invariant Probabilistic Embedding for Human Pose
https://arxiv.org/abs/1912.01001
GitHub
https://github.com/google-research/google-research/tree/master/poem
Pr-VIPE概要
動作を画像や動画から推定することは、多くの活用の可能性があります。しかし、動作自体は三次元の動きに対して、それを捉えている画像や動画は二次元情報であることで情報が部分的に失われてしまうため、簡単なタスクとはいえません。一般的に、二次元情報から三次元のアクションを捉える精度は、カメラの位置に大きく依存してしまっています。
今回、Googleの研究チームは、体の動きで重要となるポイントを視点に依存しない形で埋め込むことで、カメラの位置に依らずに体の動きの類似性を正しく認識するアルゴリズム(Pr-VIPE:“View-Invariant Probabilistic Embedding for Human Pose” )を開発しました。このアルゴリズムはポーズ検索、アクション認識、アクションビデオ同期など様々なタスクで利用することができます。
設定データでトレーニングされたモデルは、適度に優れた2Dポーズ推定器(PersonLab、BlazePoseなど)があれば、すぐに実際の環境で利用できます。モデルはシンプルかつコンパクトな埋め込みが可能で、15個のCPUを使用することで約1日でトレーニングできるとしています。
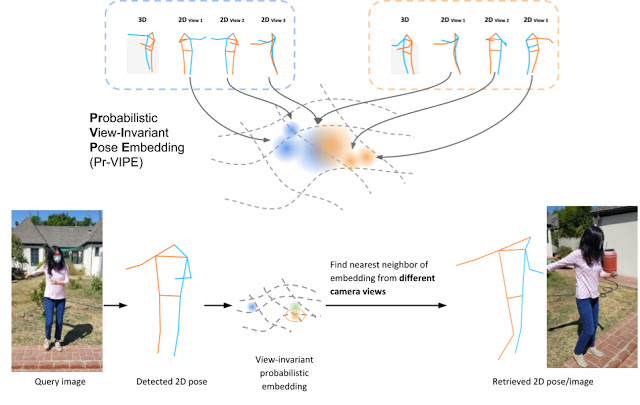
Pre-VIPEの特徴
Pr-VIPEの特徴は以下の三点です。
(1)視点に依らず利用できる(視点独立性)
(2)2D入力のあいまいさを捉えるために確率的に構成されている
(3)学習もしくは推論のどちらにもカメラパラメーターを必要としない
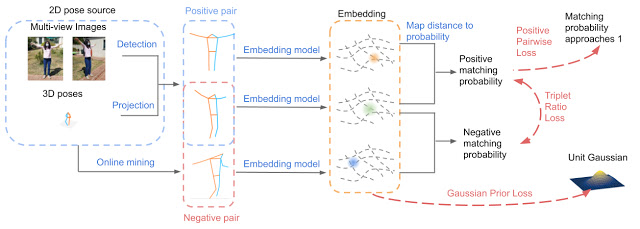
これは以下の洞察から得られた知見を利用して設定されました。
①同じ3Dポーズは、視点が変わると2Dでは大きく異なるように見える場合がある。
このことで視点独立性が必要となります。そのため、類似確率が導入されました。なお、この類似確率の学習にはTriplet lossが利用されています。
②同じ2Dポーズを異なる3Dポーズから投影できる必要がある
二次元上からは同じ姿勢にみえても三次元で確認すると異なる場合があることを言っています。そのため決定論的マッピングではなく、確率分布モデルを利用することで解決しています。なお確率分布には多変量ガウス分布を利用しています
実験と新しいベンチマークの提案
同じアクションを異なる視点からみても同じと判定できるかどうかのクロスビュー検索ベンチマークを提案しています。結果は、Pre-VIPEが既存のモデルと比べてよい精度を残しました。
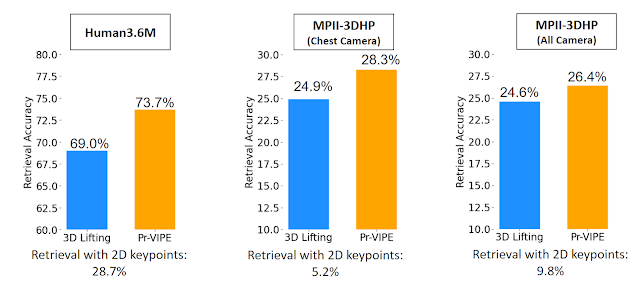
一般的な3D姿勢推定方法(例えば、単純なベースライン上記の比較のために、SemGCN、及びEpipolarPoseなどが利用されました)は、直接推定するのではなく視点独立性があるカメラ座標系から3Dポーズを予測します。そのため3Dポーズは、すべてのクエリとインデックスのペア間の厳密な配置が必要となります。これは、特異値分解(SVD)が必要なため、計算コストが高くなります。対照的に、Pr-VIPE埋め込みは、後処理なしで、ユークリッド空間での距離計算に直接使用できます。
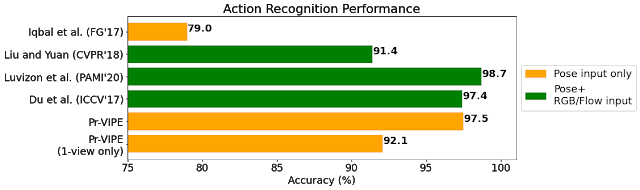
Pr-VIPEを使用してベンチマークアクションデータセットを埋め込んだうえで、ターゲットデータセットに微調整せずに使用すると、競争力の高い認識精度が得られることが示されました。さらに、Pr-VIPEは、インデックスセットの単一視点からのビデオのみを使用して比較的正確な結果を達成することができることも明らかにしました。
まとめ
姿勢推定は現在でもある程度の精度が確認されていますが、Pr-VIPEはカメラの位置によらずに精度を期待できることが大きな利点といえるとおもいます。GitHub上で実装されており、今後利用が高まることが期待されます。