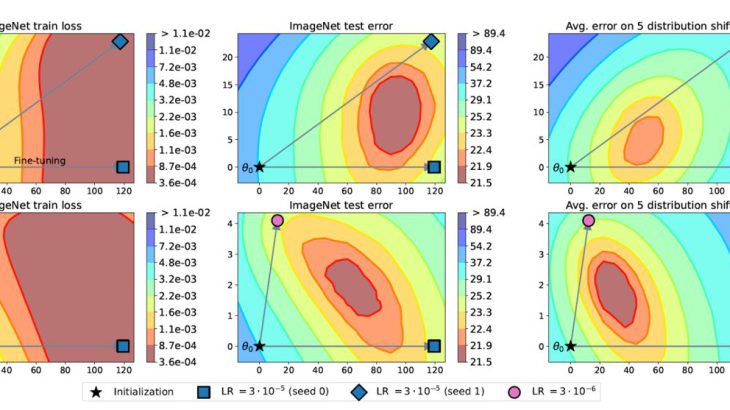
異なるハイパーパラメータで学習された複数のファインチューニングモデルの「重み」を平均化することで、精度を向上させる手法 Model soups について紹介していきます。
基本情報
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
概要
Model soups は、異なるハイパーパラメータで学習された複数のファインチューニングモデルの「重み」を平均化することで、精度とロバスト性を向上させる手法です。
以下が、論文の要点となります。
・アンサンブルとは異なり、Model soupsは推論時に余分な計算を必要としない。
・「CLIP、ALIGN、ViT-G」などで単一モデルよりも高い精度を達成。
・ゼロショット転移の性能が向上することを確認。
・画像のみでなく、自然言語などのタスクにも利用できることを確認。
問題・背景
従来、モデルの精度を最大化するためには、一般的に
(1)様々なハイパーパラメータ構成でモデルをファインチューニングする。
(2)最もよい性能を示すモデルを選択し、残りのモデルは破棄する。
という手順が取られていました。
この「残りのモデルを破棄する」ということに対して、以下の2点が懸念されます。
①選択されたモデルが最高の性能を発揮するとは限らない、という点です。特に、多くのモデルの出力を集めたアンサンブルは、 推論時に高い計算コストになるものの、最良の単一モデルを上回る性能を発揮することがあります。
②下流タスクでモデルをファインチューニングすると、性能が低下することがある。
という点もデメリットとして挙げられます。
その為、破棄するモデル(の重み)を有効活用できないか?というのがこの研究の背景です。
新規性
先行研究と比較して Model soups は以下の点で新規性があると言えます。
●モデルの重みの平均について
・初期化を共有するが独立して最適化したモデルの重み平均を利用する点。
・ FrankleらやNeyshaburらの先行研究とは異なり、様々なハイパーパラメータ構成を持つ多くのモデルの平均化を考慮する点。
●事前学習とファインチューニングについて
・初期化時にモデルを正則化する、調整する層を選択する、学習過程で層を再初期化する、あるいはデータ依存の ゲーティングで複数の事前学習済みモデルを使うことにより、転移学習を改善することが試みられていますが、model soups では、エンドツーエンドのファインチューニングモデルを探求している点。
●アンサンブルモデルについて
・アンサンブルとは異なり、 Model soups は推論時に余分な計算を必要としない点。
結果
・uniform soup:全てのモデルを一律組み込んで平均する。
・greedy soup:検証データに対して精度が良かったもののみを平均する。
・learned soup:勾配ベースのミニバッチ最適化によって重みを補完する。
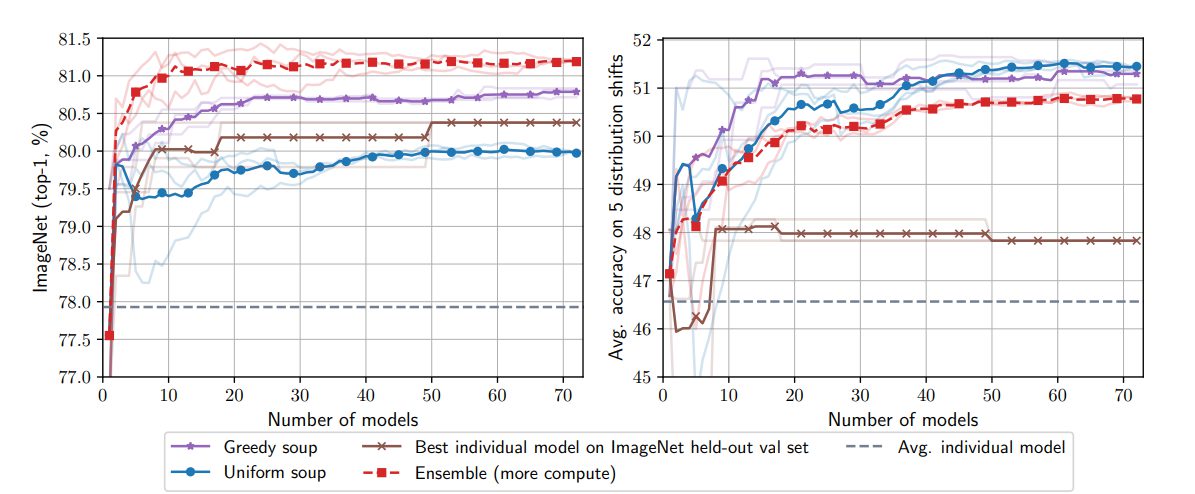
x軸はモデルの数、y軸は精度を示しています。 Uniform soup と Greedy soup の性能、および、これまでの最良の単一モデルとアンサンブルの精度とモデル数の関数を示しています。
(1)Greedy soup は ImageNet では、Uniform soup より良く、分布外では Uniform soup と同程度の精度を示す。
(2)アンサンブルは ImageNet では Greedy soup より優れているが、分布外では劣る。
(3)すべての方法は、同じ量の学習と推論時の計算コストを必要とするが、アンサンブルは例外で、各モデルを個別に通過させる必要がある。
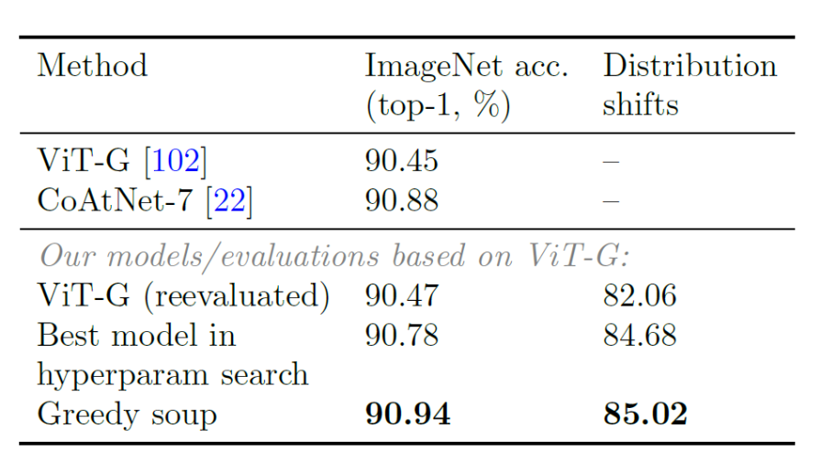
ということが明らかとなりました。JFT-3Bで事前学習したViTG/14モデルをImageNet上でファインチューニングした場合、個々の最適なモデルよりも精度を向上。
分布シフト下でのモデル性能を評価するために、ImageNet-V2, ImageNet-R, ImageNet-Sketch, ObjectNet, ImageNet-Aの平均精度を比較し、Greedy soupの精度が上回ることを確認しています。
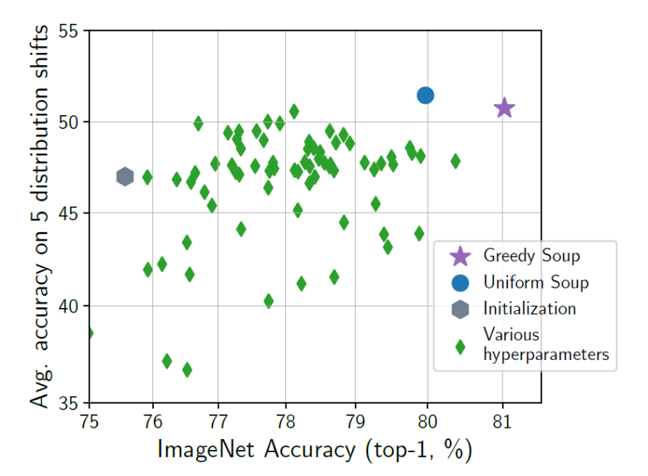
Uniform soup(青丸)は、学習率、重み減衰、反復、データ増大、混合、ラベル平滑化に関するランダムハイパーパラメータ探索において、すべてのファインチューニングモデル(緑の菱形)を平均化したものです。
ImageNet上のCLIP ViT-B/32モデルを大規模かつランダムにハイパーパラメータ探索し、ファインチューニングを行った場合、model soupは個々の最適なモデルよりも精度を向上させます。
詳細はこちらのスライドを参考下さい。
まとめ
Model soups は、アンサンブルとは異なり、推論コストやメモリコストをかけることなく、多くのモデルを平均化することができます。また、CLIP、ALIGN、JFT で事前学習した ViT-G を利用することで、ImageNet で最良のモデルよりも大幅に改善し、90.94% のトップ1精度を達成しました。また、画像のみではなく自然言語などのタスクにも有用性が確認されています。
本手法は、モデルの重み最適化手法として一つの有効な手法だと感じました。