
はじめに
FAIR(Facebook AI Research)が新たに動画解析モデルTimeSformerを発表したのでご紹介します。
『TimeSformer: A new architecture for video understanding』
https://ai.facebook.com/blog/timesformer-a-new-architecture-for-video-understanding/
●論文
『Is Space-Time Attention All You Need for Video Understanding?』
https://arxiv.org/abs/2102.05095
概要
TimeSformer(Time-Space Transformer)は初めてTransformerのみをベースに動画解析のために利用したモデルです。
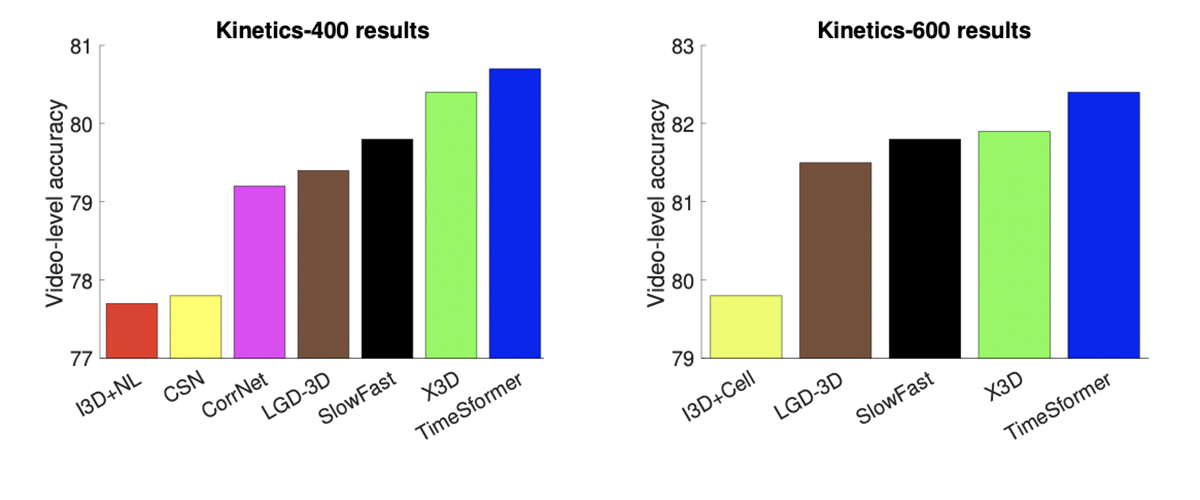
・Kinetics-400を含む行動認識ベンチマークでSoTAをだしました。
・CNNモデルに比べおおよそ3倍近く学習時間が早くなり、推論のために必要な計算量も1/10未満になりました。
⇒この結果は、将来的なリアルタイム処理のために重要になってきます。
・従来モデルより長い時間の動画クリップで学習することができます。
⇒このことは現在の行動予測よりもより複雑な行動を理解できるようになる可能性を示唆しています。
詳細
従来の問題点
従来までは3次元CNNが利用されてきました。3次元CNNモデルは、局所的な時空間領域内の短距離パターンをキャプチャするのに効果的ですが、小さな受容野を超えて広がる時空間依存性をモデル化することが難しいという問題があります。
TimeSformer
TimeSformerは、セルフアテンションを利用して、動画全体にわたる時間を捉えることができます。Transformerの構造を利用するために、入力動画を、個々のフレームから抽出された画像パッチの時空間シーケンスとして解釈しています。また動画内の他のパッチと比較することにより、各パッチのセマンティクスをキャプチャします。
計算コストを低く維持するため、TimeSformerは、1)ビデオを重複しないパッチの小さなセットに分解し、2)パッチのすべてのペア間の徹底的な比較を回避するセルフアテンションの形式を適用しています。基本的なアイデアは、時間的アテンションと空間的アテンションを別々かつ次々に適用することです。
時間的アテンションが使用される場合、各パッチ(たとえば、下の図で青色で色付けされた正方形)は、他のフレームの同じ空間位置にあるパッチ(緑色の正方形)とのみ比較されます。動画にTフレームが含まれている場合、パッチごとにT時間の比較のみが行われます。空間的アテンションが適用されると、パッチは同じフレーム内のパッチ(赤色のパッチ)とのみ比較されます。したがって、Nが各フレーム内のパッチの数である場合、分割された時間・空間アテンションは、パッチごとに合計で(T + N)の比較のみを実行します。これに対して、時間・空間アテンションを同時に完全に行うと必要な比較数は(T * N)になります。さらに、前者の分割したアテンションの方が、同時に行うアテンションよりも効率的であるだけでなく、より正確であることがわかりました。

TimeSformerのスケーラビリティにより、超長距離の時間モデリングを実行するために、非常に長いクリップ(たとえば、102秒の時間範囲にまたがる96フレームのシーケンス)で動作することができます。これは、最大で数秒のクリップの処理に制限されている現在の3D CNNからの大幅な更新を表しており、長い形式のアクティビティを認識するための重要な要件です。
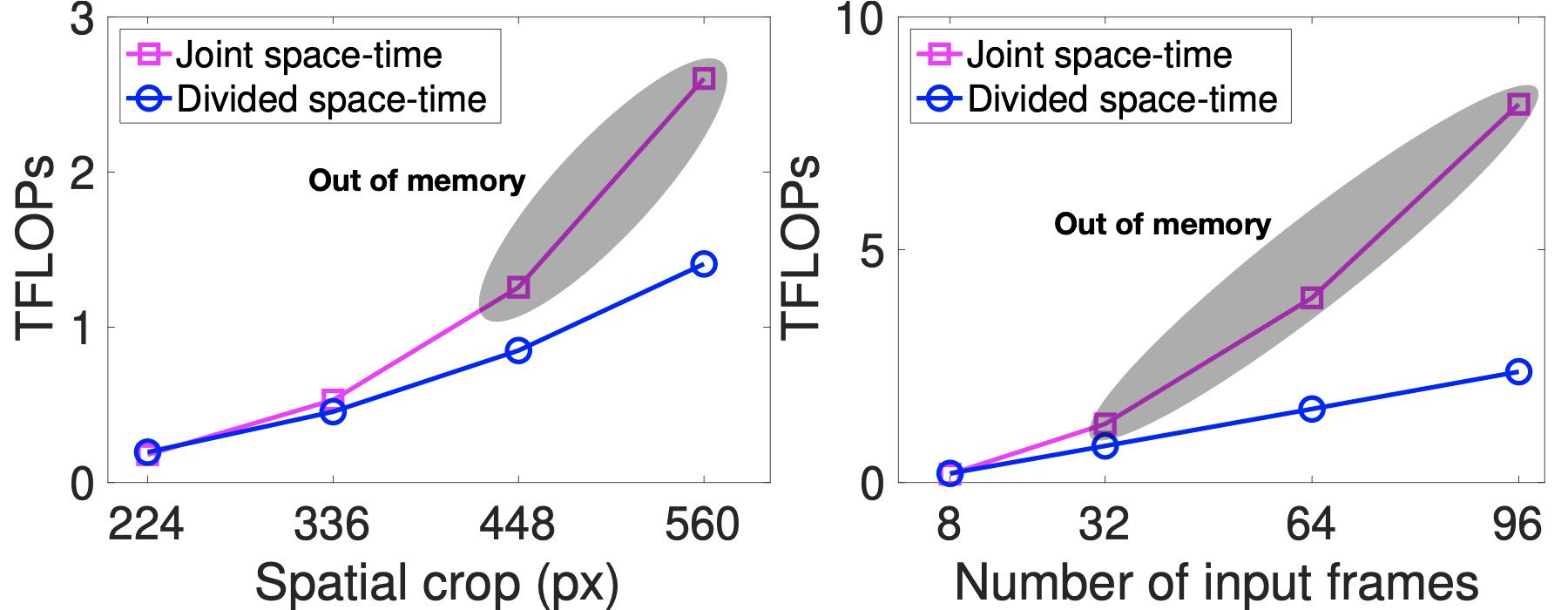
TimeSformerの効率により、高い空間解像度(たとえば、最大560×560ピクセルのフレーム)および長い動画(最大96フレームを含む)でモデルをトレーニングできます。これらのプロットは、空間解像度(左)と動画の長さ(右)の関数としての動画分類コスト(TFLOP単位)を示しています。これらのプロットから、特に大きなフレームや長いビデオに適用した場合に、時間・空間を同一に行うアテンションよりも分割するアテンションの方が計算量が少ないことが確認できます。実際には、空間フレームの解像度が448ピクセルに達するか、フレーム数が32に増えると、GPUメモリのオーバーフローが発生し、大きなフレームや長いビデオには適用できなくなります。
まとめ
TimeSformerを使用すると、最大数分の長さのはるかに長いビデオクリップでトレーニングすることができます。これにより、ビデオ内の複雑な長い形式のアクションを理解するようにマシンに教える研究が劇的に進歩する可能性があります。これは人間の行動の理解を目的とした多くのAIアプリケーション(AIアシスタントなど)にとって重要なステップとなると考えられます。