はじめに
Googleから、訓練データがモデルに与える影響を調べることができるシンプルなメソッド「TrackIn」が提案されました。
TracIn — A Simple Method to Estimate Training Data Influence
https://ai.googleblog.com/2021/02/tracin-simple-method-to-estimate.html
Estimating Training Data Influence by Tracing Gradient Descent
https://arxiv.org/pdf/2002.08484.pdf
概要
深層学習分野ではデータがモデルに与える影響を知る方法に関する研究はあまり進んでいません。今回、Googleの研究チームはシンプルで広範なモデルに利用できる方法として「TrackIn」を開発しました。データを追跡することで、モデルに与える影響を調べます。
背景
深層学習分野では、データが与える影響を測定するのは困難なことだとされてきました。実際、影響を調査する方法はあまり提起されていません。少ない中で提起されている方法としては、①いくつかのデータをドロップして再学習した際の精度の変化を調べる方法か、もしくは②統計的手法⑴入力ポイントの摂動の影響を測る影響関数(「Understanding Black-box Predictions via Influence Functions」)を利用する方法、⑵予測をトレーニング例の重要度加重の組み合わせに分解する表現方法(「Representer Point Selection for Explaining Deep Neural Networks」)などが知られています。
既存の方法の問題点
これらのアプローチは理論的には健全に確立されたものですが、大規模なリソースや、トレーニングにかかる追加の負担が大きく、実用が制限されています。
TracIN
TracInの基礎的な発想は、トレーニングプロセスを追跡して、個々のトレーニング例にアクセスしたときの予測の変化をキャプチャするという単純なものです。TracInは、さまざまなデータセットから誤ってラベル付けされた例や外れ値を見つけるのに効果的であり、各トレーニング例に影響スコアを割り当てることで、(機能ではなく)トレーニング例の観点から予測を説明するのに役立ちます。
TracInは、SGD(または関連するバリアント)を使用してトレーニングする以外の要件がないため、タスクに依存せず、さまざまなモデルに適用できます。
理論
最適化アルゴリズムとしてSGDを利用する場合、トレーニング中に特定のトレーニング例にアクセスし、モデルのパラメータが変更され、その変更によりテスト例の予測/損失が変更されることになります。そのためプロセスを通じてトレーニング例を追跡できれば、テスト例の損失または予測の変化からトレーニング例が与える影響を理解することができます。このとき、トレーニングデータは二つにわけられます。損失を減らすようなデータ「proponents」と、損失を増加させるようなデータ「opponents」です。
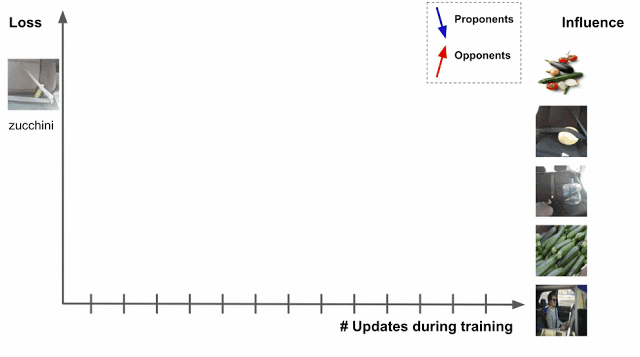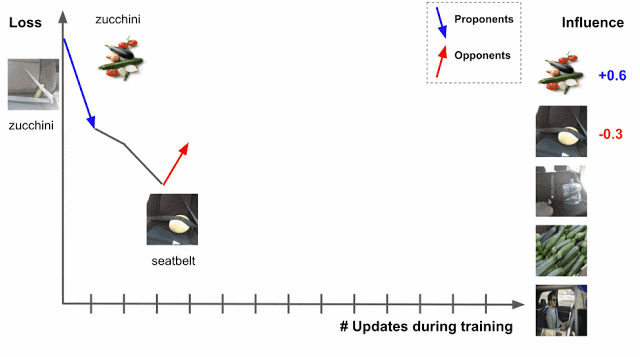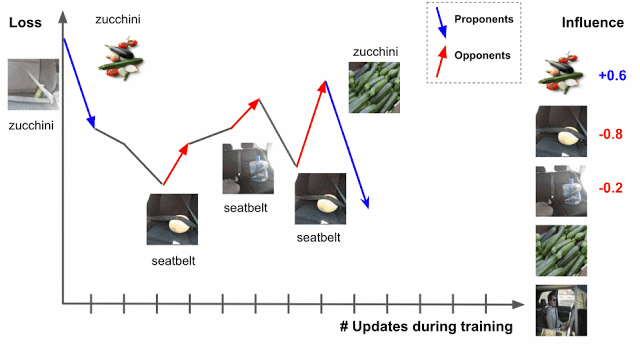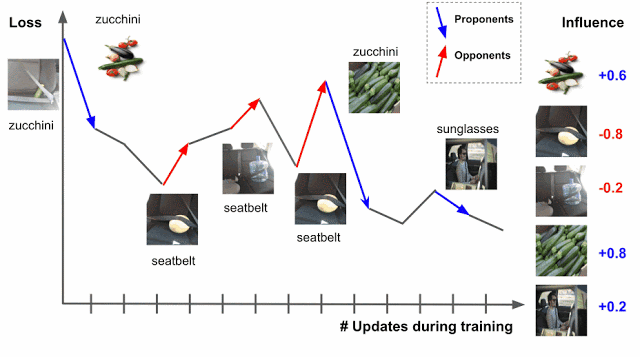
この手法の問題点は、学習アルゴリズムが一度に複数のトレーニング例にアクセスすることです。そのため、各トレーニング例の相対的な寄与を解きほぐす方法が必要です。これは、ポイントごとの損失勾配を適用することで実行できます。一緒に、これらの2つの戦略はTracInメソッドをキャプチャします。これは、テストとトレーニングの例の損失勾配の内積の単純な形式に還元でき、学習率で重み付けされ、チェックポイント全体で合計されます。
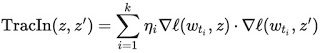
トレーニング例(z)とテスト例(z ‘)の損失勾配の内積は、さまざまなチェックポイントでの学習率(ηi)によって重み付けされ、合計されます。
あるいは、代わりに予測スコアへの影響を調べることもできます。これは、テスト例にラベルがない場合に役立ちます。この形式では、テスト例の損失勾配を予測勾配に置き換えるだけで済みます。
実験
影響の計算
いくつかのトレーニングデータと特定の分類のテスト例(カメレオンの画像)について損失勾配ベクトルを計算し、次に標準的なk-最近傍ライブラリを利用してトップの「proponents」と「opponents」を取得することで、TracInの有用性を確認します。
上位の「opponents」はカメレオンの溶け込む能力を示しています。比較のために、最後のレイヤーからの埋め込みを用いたk-最近傍を示します。「proponents」は似ているだけでなく、同じクラスに属している画像であり、「opponents」は似ているが異なるクラスに属している画像です。「proponents」と「opponents」が同じクラスに属しているかどうかについては、明示的な強制力がないことに注意してください。

上段:影響ベクトルの上位の「proponents」と「opponents」。
下の行:最後から2番目のレイヤーからの埋め込みベクトルの最も類似した例と異なる例。
クラスタリング
テスト例の損失をTracInによって与えられたトレーニング例の影響に単純化した内訳は、また任意の勾配降下法のニューラルモデルからの損失(または予測)が勾配の空間における類似度の和として表現できることを示唆しています。最近の研究では、この関数形がカーネルの形に似ていることが実証されており、ここで説明した勾配類似度がクラスタリングのような他の類似度タスクにも適用できることを示唆しています。
この場合、TracIn はクラスタリングアルゴリズムの中で類似度関数として利用することができます。類似度メトリックを距離メジャー(1 – 類似度)に変換できるようにバインドするために、勾配ベクトルを単位ノルムを持つように正規化します。以下では、より細かいクラスタを得るために、ズッキーニの画像にTracInクラスタリングを適用しています。

TracInの類似性を使用したズッキーニ画像内のより細かいクラスター。
各行は、クラスター内で同様の形のズッキーニを含むクラスターです。
(断面でスライスされたズッキーニ(上)、ズッキーニの山(中央)、ピザのズッキーニ(下))
影響力と外れ値
TracInを使用して、高い影響力を示す外れ値、つまり、トレーニングポイントそれ自体が予測に与える影響を特定することもできます。影響力が高い外れ値の学習データは、ラベルが誤っているか、データがまれである場合に発生します。どちらの場合も、モデルが例を一般化するのが困難です。以下は、自己影響力の高い例です。

間違ってラベル付けされたデータ

オシロスコープクラスのデータ:まれなデータ(左)とラベル内の通常データ(右)
まとめ
データセットが大きくなってくると、データセット内をすべて見ることが難しくなってきます。一方で、データセットはただ増やせばいいというわけではなく、特徴量をうまくとらえたデータセットであれば量がなくてもよいことが知られています。今回のTrackInなどを利用して、より質の高いデータセットを作ることが、性能の高いモデルを作る上では求められます。