はじめに
独ライプツィヒ大学がマイクロサイズマシンでの強化学習を可能にしました。
HOW TINY MACHINES BECOME CAPABLE OF LEARNING
https://www.uni-leipzig.de/en/newsdetail/artikel/wie-winzige-maschinen-lernfaehig-werden-2021-03-25/
〇論文
Reinforcement learning with artificial microswimmers
https://robotics.sciencemag.org/content/6/52/eabd9285
概要
人工マイクロスイマーとは、活性物質の複雑な振る舞いを再現することを目的とした人工の自走式微細粒子のことで、大きさは髪の直径の30分の1ほどです。表面の小さな金の粒子を加熱し、このエネルギーを運動に変換することによって、運動の方向を変えることができます。
人工マイクロスイマーは、多くの場合、微視的な生物の自走を模倣するように設計されていますが、環境に合わせた適切な行動はできていませんでした。対して、普通の生物はバクテリアから人間まで環境の情報を受けとり、処理、保持、思い出すことができます。
今回、独ライプツィヒ大学の研究チームが人工マイクロスイマーに機械学習アルゴリズムを使用して学習する特定の能力を与える方法を開発しました。

詳細
これまでの問題点
活性物質の複雑な振る舞いを再現できる人工マイクロスイマーは、多くの場合、微視的な生物の自走を模倣するように設計されています。ただし、生物と比較して、人工マイクロスイマーは、環境信号に適応したり、物理的な記憶を保持して最適化された緊急行動を生み出す能力が限られています。なお、巨視的な生体システムやロボットとは異なり、微視的な生物と人工マイクロスイマーはどちらもブラウン運動の影響を受け、その位置と推進方向がランダムになります。
研究手法
人口マイクロスイマーを外部から制御して、強化学習によって仮想環境内を移動する方法を学習します。自己熱泳動活性粒子のリアルタイム制御を使用して、これらの長さスケールでのブラウン運動の避けられない影響下での単純な標準ナビゲーション問題の解決することが目的です。
仮想報酬の助けを借りて、マイクロスイマーは、ブラウン運動によって繰り返し影響を受けながら、液体の中を通り抜けていきます。ノイズ下での学習に関しては、ノイズによって学習速度が低下しながらも、最適な動作が変更され、意思決定の強度も向上することがわかりました。
粒子を制御するフィードバックループの時間遅延の結果として、バクテリアの最適なランアンドタンブル時間を連想させる最適な速度がシステムに見出されます。これは、遅延応答を示すシステムの普遍的な特性であると推測されます。
金ナノ粒子で装飾されたマイクロスイマーについて
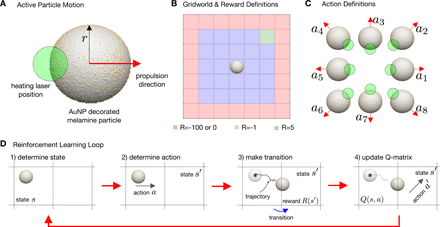
(A)自己熱泳動対称マイクロスイマーのスケッチ。使用した粒子の平均半径はr =1.09μmで、表面の30%が直径約10nmの金ナノ粒子で覆われていました。加熱レーザーがコロイドを非対称に(中心から距離dで)照らし、スイマーは明確に定義された熱泳動速度vを取得します。
(B)グリッドワールドには25の内部状態(青)があり、右上隅に1つのゴールがあります(緑)。ノイズの影響を調べるために、24個の境界状態(赤)のセットが定義されています。
(C)各状態で、レーザーの焦点を適切に配置することにより、粒子が指定された方向に沿って熱泳動的に推進される8つの可能なアクションを検討します。
(D)RLループは、アクティブな粒子の位置を測定し、状態を判断することから始まります。この状態の場合、特定のアクションはϵグリード手順で決定されます。その後、遷移が行われ、新しい状態が決定され、遷移に対する報酬が与えられます。この報酬に基づいて、Qマトリックスが更新され、手順はステップ1から始まり、エピソードがゴールに到達するか、グリッドワールドを出て境界状態になるまで終了します。
単一のマイクロスイマーによる学習
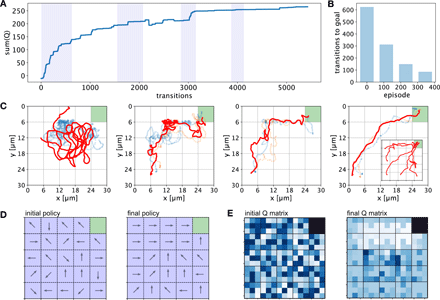
(A)グリッドワールド内の単一のマイクロスイマーの学習の進捗状況。
進行状況は、学習プロセスの各遷移におけるすべてのQ行列要素の合計によって定量化されます。 Q行列はランダムに初期化されました。影付きの領域は、学習プロセスの25のエピソードのセットを示し、開始点はランダムに選択されます。
(B)学習エピソードの数が増えるにつれて、左下隅から開始するときにターゲットに到達するために必要な平均ステップ数。
(C)学習プロセスのさまざまな段階での単一のマイクロスイマーの動作のさまざまな例。
最初の例は、グリッドワールドの任意の位置で学習プロセスの開始時に開始するスイマーに対応します。軌道は、多数のループによって特徴付けられます。学習エピソードの数が増えるにつれ、軌道は目標に向かって動き続けるようになります。これは、目標を達成するために取られる平均歩数の減少にも反映されています[(B)を参照]。右端のグラフの挿入図は、さまざまな開始位置からの軌跡を示しています。
(D)学習プロセスの収束状況。
(E)学習プロセスの最初と最後のQ行列の色表現。
各状態の小さな四角は、中央の四角を除いて、Q行列エントリによって与えられた対応するアクション(図1Cと同じ順序)の効用を表しています。暗い色はより小さな効用を示し、明るい色は対応するアクションのより良い効用を示します。
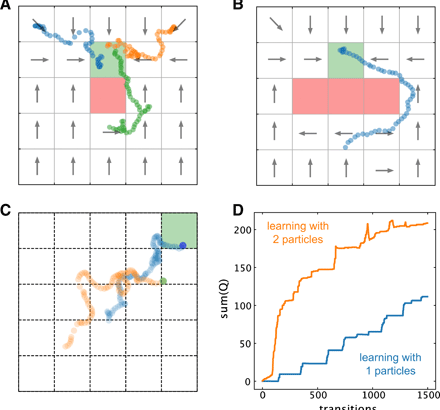
障害物と共有情報で学習した場合
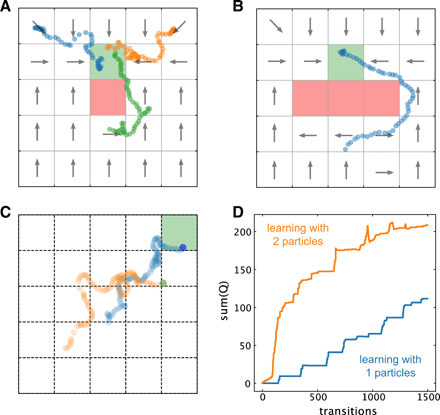
(A)グリッドワールドの中心にあるゴール状態(R = 5)の隣に仮想障害物(赤い四角、R = − 100)がある学習プロセスの軌道の例。
(B)大きな仮想障害物(赤い長方形、R = − 100)の背後で目標状態(R = 5)に到達することを学習したアクティブ粒子の軌道の例。
(C)学習プロセス中に情報を共有する2つの粒子の軌跡の例。
(D)情報を共有する2つの粒子と学習速度を比較する、各遷移でのすべてのQ行列要素の合計。
学習過程におけるブラウン運動の影響
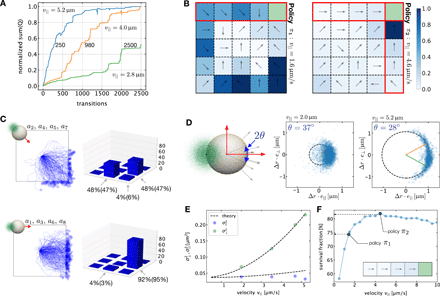
(A)学習プロセス中の遷移の総数の関数としてのQ行列要素の合計。 3つの異なるマイクロスイマー速度で学習するために、異なる曲線が得られました。
(B)高ノイズ(低速)(π1:v∥=1.6μms-1)および低ノイズ(高速)(π2:v∥=4.6μms-1)での学習プロセスから得られたポリシー。状態の色付けは、最良のアクションの値と他のすべてのアクションの平均との対比に対応します(式2)。
(C)ベルマンの式で使用される遷移確率。
(D)方向の不確実性の起源。
(E)意図した運動方向に平行および垂直な(D)の点群の分散。
まとめ
これらのマイクロスイマーのように人工知能とアクティブシステムをリンクすることは、未知の環境に適応しながら自律的にタスクを実行できる新しい知的な顕微鏡材料の開発に向けた最初の一歩になります。
同時に、人工マイクロスイマーと機械学習法の組み合わせが生物系における集団行動の出現への新しい洞察を提供することが期待されています。この方法が完全に開発され、生物学的システムを含む他の材料システムに適用されると、スマートドラッグや顕微鏡ロボット群の開発に使用できるようになると考えられています。