はじめに
米コロンビア大学の研究チームが、AI に対して、数値データでラベル付けされデータを教師データとして与えるよりも、自然言語音声でラベル付けしたデータの方がロバスト性が高いことを明らかにしました。
Deep Learning Networks Prefer the Human Voice—Just Like Us
https://www.engineering.columbia.edu/press-releases/hod-lipson-deep-learning-networks-prefer-human-voice
〇公式論文
BEYOND CATEGORICAL LABEL REPRESENTATIONS FOR IMAGE CLASSIFICATION
https://openreview.net/pdf?id=MyHwDabUHZm
〇公式解説動画
概要
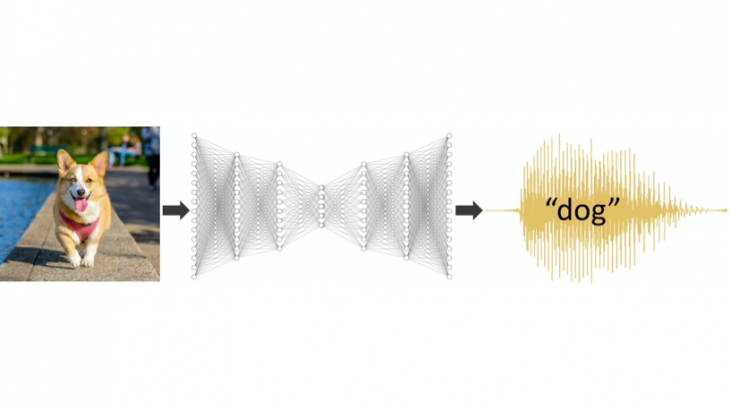
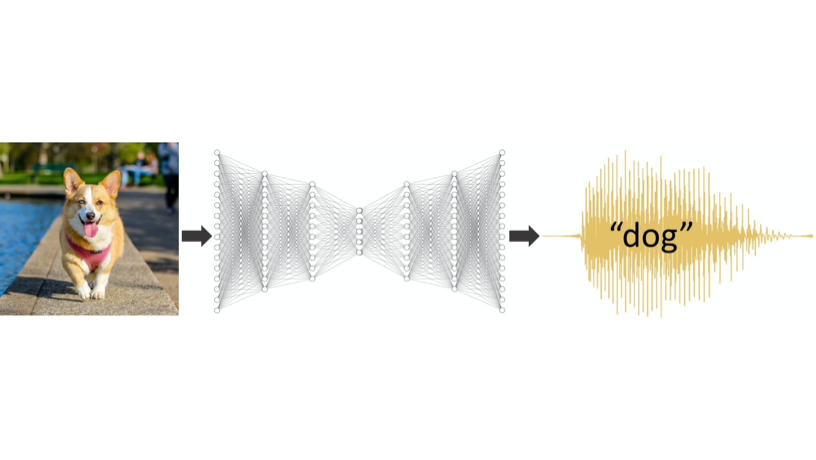
米コロンビア大学の研究チームが、教師データのラベルに数値データを与えるよりも、人間の音声データを与えた方が精度の向上につながることを発表しました。(例えば、犬と猫の写真を分類する際、教師データに0=犬、1=猫、と与えるのではなく、音声で「犬」、「猫」と与えます。)現在はどのようなデータを与えるかが重視されていますが、ラベルデータの表現についても研究を進めるべきではないかと提起しています。
詳細
研究チームは、たとえば、世界で最も高度に進化した音の1つである特定の単語を発する人間の声の力を使用して、システムが動物を認識するように「トレーニング」されている場合、ニューラルネットワークはより速くよりよく学習する可能性があると仮定し、その効果を実験で確認しました。
実験①
10種類のオブジェクトを分類するときに、従来の数値データを与えたものと、音声データを与えたものを比較することで、実験しました。
従来のモデルは、正解ラベルとして10個の数値が与えられ、任意の列の「1」は正解を示し、9つの0は不正解を示します。それに対して、今回の実験モデルには、正解ラベルとして実際に声に出して録音した人間の声の音声ファイルが与えられます。 (1と0はありません。)
結果①
両方のAIシステムを合計15時間トレーニングし、それぞれの分類パフォーマンスを比較しました。画像が表示されると、元のネットワークは、トレーニングされたとおりに、一連の10個の1と0として答えを吐き出します。対して、実験的なニューラルネットワークは、画像内のオブジェクトが何であるかを「伝えよう」とする明確に識別可能な音声を生成しました。音調として人間らしさはないものの、音として何を指しているかがわからないものではありません。
両方のモデルが同等に機能し、写真に描かれている動物または物体を正しく識別しました。これは数字を予測するよりも、音声を生成する方が難しいと考えられていることを踏まえると、驚くべき結果ともいえます。
実験②
トレーニングツールとしてサウンドを使用することの限界をさらに探求するために、研究者は別の実験を設定しました。トレーニングプロセス中に使用する写真の数をはるかに少なくしました。トレーニングの最初のラウンドでは、50,000枚のトレーニング画像を両方のニューラルネットワークに与えましたが、2番目の実験の両方のシステムには、はるかに少ないトレーニング画像として2,500枚を与えました。
結果②
AIの研究では、トレーニングデータがまばらな場合、ほとんどのニューラルネットワークのパフォーマンスが低下することがよく知られています。この実験では、従来の数値トレーニングされたネットワークも例外ではありませんでした。画像に写っている個々の動物を識別する能力は、約35%の精度まで急落しました。対照的に、実験用ニューラルネットワークも同じ数の写真でトレーニングされましたが、精度は70%程度までしか低下しませんでした。
実験③
更に、画像のあいまいさについても、音声駆動のトレーニング方法をテストしています。AIが「理解」するのが難しいとされる画像を用いて実験を行いました。(たとえば、あるトレーニング画像には、犬や奇妙な色の猫のわずかに破損した画像が描かれていました。)
結果③
音声訓練されたニューラルネットワークは依然として約50%程度の精度を保ちましたが、数値訓練されたネットワークはわずか20%の精度しかでませんでした。
研究チームの考察
今回の調査結果は、従来の「バイナリ入力は、情報をマシンに伝達するためのより効率的な方法である」という一般的な仮定に反しており、反発も招いたとしています。(国際的なAI会議に提出した際には、ある匿名のレビューアから、結果が「あまりにも驚くべき、直感的ではない」と感じたという理由だけで論文が拒否されたことを報告しています。)
しかし、情報理論のより広い文脈で検討すると、今回の仮説は、実際には、情報理論の父である伝説のクロードシャノンによって最初に提案されたはるかに古い画期的な仮説を支持しています。シャノンの理論によれば、最も効果的な通信「信号」は、最適なビット数と最適な量の有用な情報によって特徴付けられます。
これは、人間の言語が何万年もの間最適化プロセスを経てきたという事実を踏まえると、話し言葉がノイズと信号のバランスが取れているとしても、不思議ではないことを意味していると指摘しています。シャノンエントロピーから考えた場合、人間の言語でトレーニングされたニューラルネットワークが単純な1と0でトレーニングされたニューラルネットワークよりも優れていることは理にかなっているとしています。
まとめ
今回の研究結果は一般にAIを利用する場合でも大きく影響を与える可能性があるため、重要なテーマとなります。今後、ラベルデータをどのように与えるかで性能が変化することが明らかになった場合、従来のトレーニングデータの作り方が大幅に変わる可能性があります。今後、同様の研究が進むことで、最適なラベルデータの在り方が明らかになることが期待されます。