はじめに
Google Brainが全結合層を基本としたニューラルネットワークがTransformerと同程度の精度を出すことができることを研究で明らかにしました。この結果、NLP(自然言語処理)だけではなく、最近ではCV(画像処理)の分野でもデファクトスタンダードになりつつあったTransformerをベースとしたモデル構成に再考が求められることになります。
なお、今回利用した図はすべて下記論文(「Pay Attention to MLPs」)から引用しております。
Facebookチームが開発した画像分類にTransformerを利用した効率モデルDeiTを紹介!
https://deepsquare.jp/2021/01/deit/
画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!
https://deepsquare.jp/2020/10/vision-transformer/
Transformer を物体検出に採用!話題のDETRを詳細解説!
https://deepsquare.jp/2020/07/detr/
自然言語処理の必須知識 Transformer を徹底解説!
https://deepsquare.jp/2020/07/transformer/
CV:画像処理 Computer Vision
NLP:自然言語処理 Nature Language Processing
MLP:多層パーセプトロン MultiLayer Perceptron(≒全結合型ニューラルネットワーク)
gMLP:ゲート付きMLP
aMLP:Attention機構付きgMLP
ViT:Vision Transformer
論文のポイント
・Google Brainから流行しているTransformer型アーキテクチャ(具体的にはAttention機構)が実際はどの程度不可欠なものかをMLP型アーキテクチャと比較して確認した研究論文。
・Attention機構はCV(画像処理)ではほぼ必要性がなく、NLP(自然言語処理)でも特定のタスク以外では必要性が低いことが確認された。
・NLPの特定の分野ではAttention機構の有効性が確認されており、gMLPとAttention機構を組み合わせたaMLPでBERTを超える精度を記録することが出来た。
・ただし、ゲート機構備えたMLP(gMLP)はTransformerと同様にスケーラビリティがあるため、精度上の問題はモデル容量を大きくすることで解決できると考えられる。
・Transformerの研究だけでなく、MLPの研究を推進することを提言している。
概要
研究のモチベーション
Transformerは革新的なモデルでNLPのデファクトスタンダートになりました。それだけではなく、現在ではViT(Vision Transformer)の発表などでCVでもデファクトスタンダートになりつつあります。
しかし実際にTransformer、特にAttention機構は本当に必要不可欠なものなのか、という疑問が実は存在します。Attention機構が実現しているもののなかで特に重要なコンセプトである①再帰型ではない(=並列処理できる)、②トークン間の空間情報を取得する、ということをほかのアーキテクチャでも表現可能であった場合、Attention機構を用いる必要性はどこまで存在するのか?というのが今回の研究のモチベーションとなります。
研究の方法
Attention機構を利用せずに上記の①と②を満たすMLP型のモデル(gMLP)を開発して、Transformer型のモデル(DeiTやBERTなど)と精度比較することでAttention機構がもたらす他の特徴の有用性を確認しました。
研究の結論
研究の結果、gMLPでも CVや一部のタスクを除くNLPでTransformer型のモデルと同程度の精度が出せることが確認できました。また、Transformer型モデルと同様にモデルの容量を大きくすると精度が向上するスケーラビリティが確認されました。このことからAttention機構はCVでは重要ではないと考えられます。NLPでは一部のタスクではAttention機構の有用性が確認されたもののありましたが、gMLPにAttentionを一部だけで利用したaMLPが最高精度を記録するなど、MLPの有用性が確認できるものとなりました。
総論として、TransformerのAttention機構に現在は注目が集まっていますが、MLPもTransformerと同程度の重要性や有効性があるため、今後同程度に研究していく必要があると提言しています。
PPT版はこちらをご参考下さい。
詳細
研究の背景・手法
Transformerはその有用性からNLPだけでなくCVでもベースモデルとしてデファクトスタンダードとなっています。そのため、NLPではLSTM-RNNや、CVではCNNがあまり利用されなくなり、新たな研究もTransformerをベースモデルとしたものが多くなっています。そうした状況にありながら、あまりにもTransformerが有効であったため、実際にTransformerにおけるAttention機構は本当に必要なのか、本当に不可欠の機構なのかという点はこれまで十分に検討されてきませんでした。またAttention機構が実現しているいくつかのコンセプトを実現できるような機構が開発できていなかったということもあります。今回、いくつかのコンセプトを表現できるgMLPの開発が成功したことで、Attention機構の有用性を確認することができるようになりました。
Transformerが実現している重要なコンセプトとして、①再帰型処理を用いないことでトークンを並列処理できる、②トークン間の空間情報を収集できる、というものがあります。しかし、このコンセプト自体は今回MLPにゲートを付与したgMLPのような形でも実装することができます。そのため、Attention機構をわざわざモデルに組み込む必要性があるとしたら、それ以外のAttention機構特有のメリットがタスクの精度を大きく左右している場合のみと言えます。
Attention機構特有のメリットとしては、入力データの表現に基づいた動的なパラメータの決定によってより有効なInductive biasを導入できるというものがあります。一方で、今回のgMLPのようなMLP系のメリットは静的なパラメータの決定により任意の関数を表現できるというものがあります。つまり、Attention機構が必要不可欠かどうかは、モデルにAttention機構によって獲得できるInductive biasを導入することがMLPなどがもつ強力な関数表現力よりもタスクを処理するうえで有効であるかどうか、とも言い換えることができます。
今回、Attention機構が可能にしているコンセプトを表現できるゲート付きMLP(gMLP)とTransformer型モデルの精度を比較し有用性を確認しました。
・入力データの表現に基づいた動的なパラメータの決定によってより有効なInductive biasを導入できる
※Inductive bias(帰納的バイアス、learning bias:学習バイアス)とは
モデルが遭遇していない特定の入力の出力を予測するために使用する一連の仮定のこと
MLP特有のメリット
・静的なパラメータの決定により任意の関数を表現できる
モデルについて
gMLP
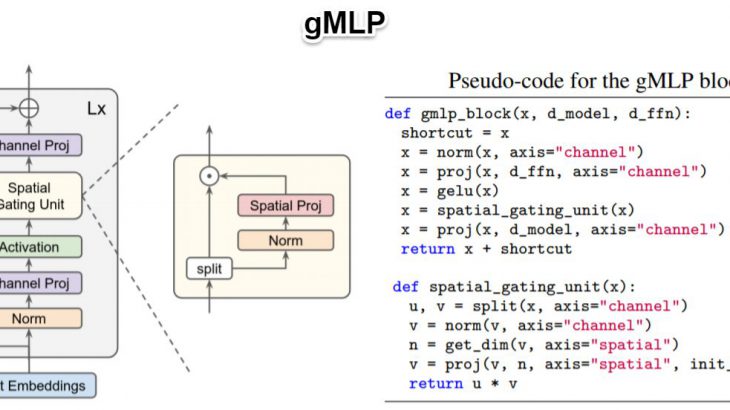
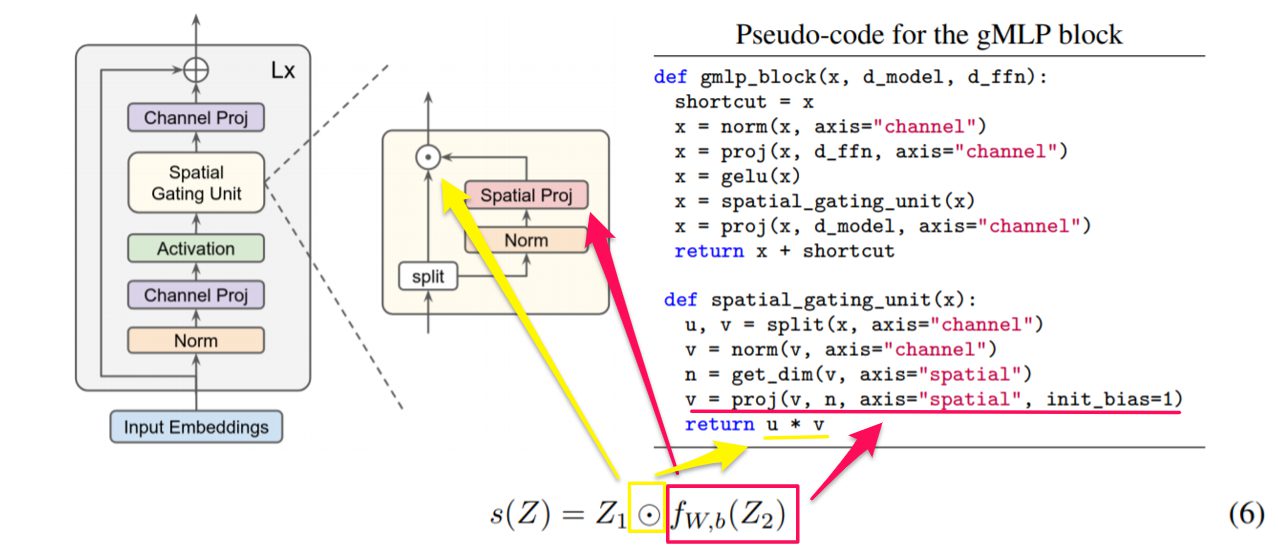
gMLPは、Attention機構が実現しているコンセプトのうち、特に②トークン間の空間情報を取得する、を獲得するために、様々な工夫が行われています。そのためにgMLP-blockを構築し、それを何層(論文ではL層分と表記される)か積み重ねることで適切な特徴量を獲得できるようにしています。特にこのgMLP-blockにおけるSpatial Gating Unit(SGU)がgMLPで最も工夫された点にあります。
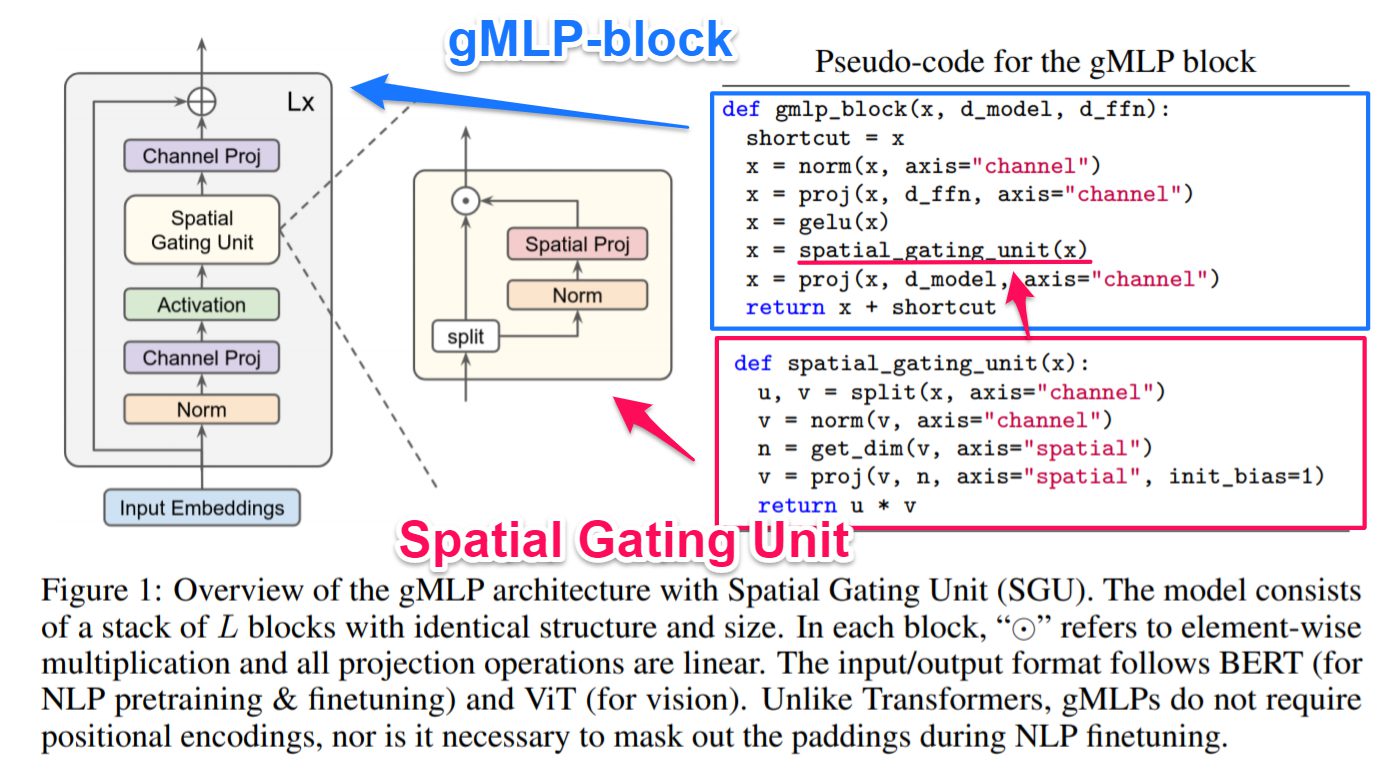
gMLP-block
gMLP-blockは以下のように、線形射影と活性化関数を組み合わせて出力した値(⑴)に対して、Spatial Gating Unit(SGU)(⑵)を用いることで、トークン間の空間情報を取得しています。その後、再び線形射影(⑶)を行うことで必要な特徴量を獲得しています。ポイントとして、Transformerのようにポジションエンベディング層を利用していません。Transformerではポジションエンベディング層を利用することで、画像や文章のトークンがそれらのどこからきたのかを把握していましたが、gMLPではSGUがそのような情報を取得してくれます。

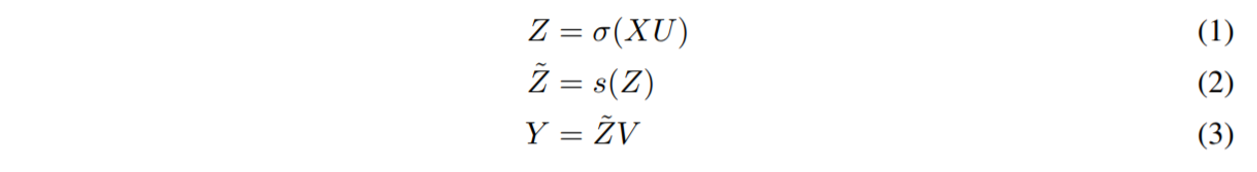
※この数式において、ショートカット、ノーマライゼーション、バイアス項は見やすさのために省略されています。
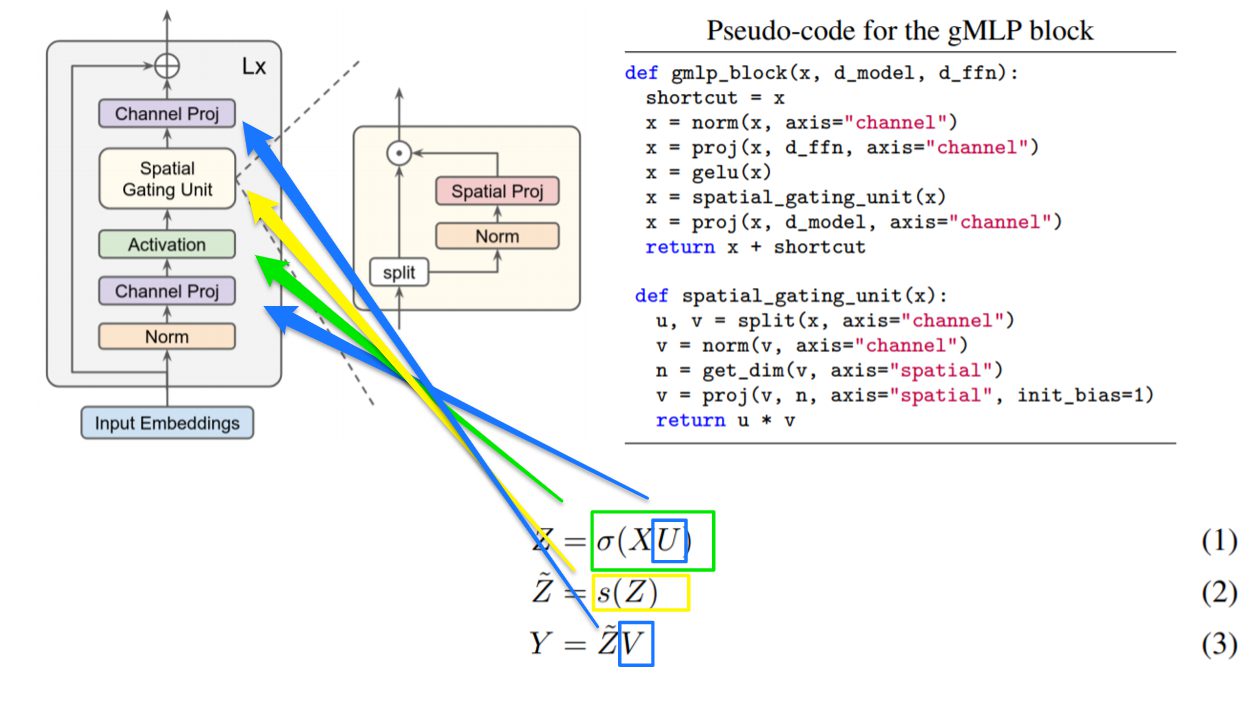
※このブロック構造はMobileNetv2の空間深さ方向畳み込みからアイディアを受けているそうです。
Spatial Gating Unit
トークン間の空間情報をどのようにとらえることができるか、というのがgMLPを構築する上での最大の問題点になりました。そのために開発されたのがSpatial Gating Unitです。

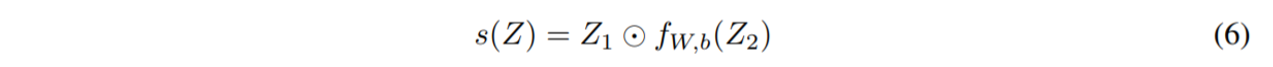
最終的なSGUは上記の式(⑹)になります。論文では、この(⑹)に至るまでの経緯を説明してくれています。
まず、最もシンプルな方法としてデータ長の行列を持つWを用いて線形射影をするという手法が考えられます。
![]()
これに加えて、もとの入力(Z)と空間的に転移された入力(fw,b(Z))同士の要素積を取ることで、より適切な空間情報を獲得しました。
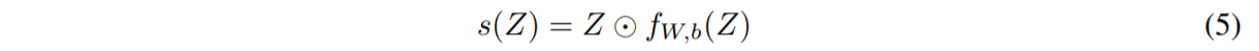
なお、このとき「学習初期のWはほとんど0で、バイアスは1であること」が重要であることが研究中にわかったとしています。これは学習の初期は線形射影がほぼ恒等写像のような状況になることを意味しています。この初期値にすることで、gMLP-blockが学習初期(各トークンが個別に処理されているとき)はTransformerのFFN(Feed-Forward Network)のように機能します。そして、徐々にトークン間の空間情報が差し込まれていくことになります。
この乗法ゲーティング(SGU)は、空間信号を使用して個々のトークン表現を「変調」するメカニズムと見なすことができるとしています。つまり、言い換えれば、Zの各要素の大きさは、ゲーティング関数に従って迅速に調整できるということです。
そして、この(5)にGLUsなどで使われている技法として入力値を分割して利用する手法を組み込んだのが、最終的に導入された(6)になります。なお、数式上には書かれていませんが、入力値をノーマライズすることでモデルが安定するため、行われています。
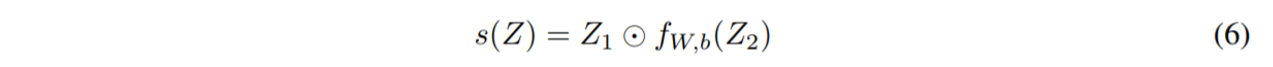
画像分類
ImageNetを利用した画像分類タスクの精度を、Vision Transformer(ViT)とDeiT(ViTの改良版)及び、CNNモデルと比較しました。 gMLPはDeiTなどと同様に強く過学習してしまう傾向が見られたため、DeiTと同様の手法を用いた正則化が行われていますが、基本的にそれ以外の精度を向上させるようなチューニングは避けています。
利用したgMLPの各モデル
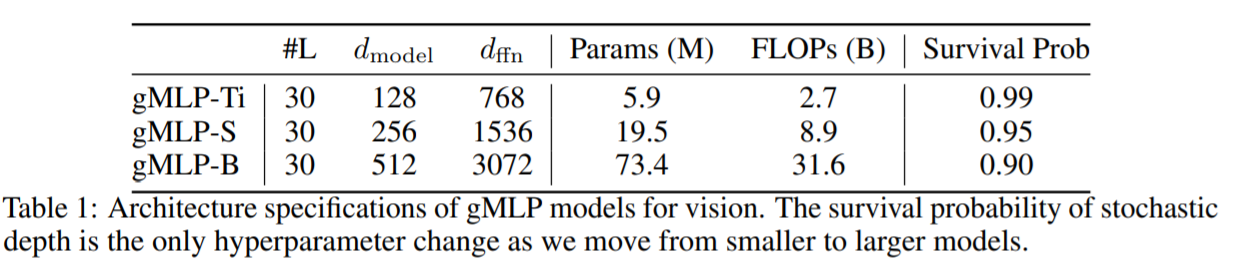
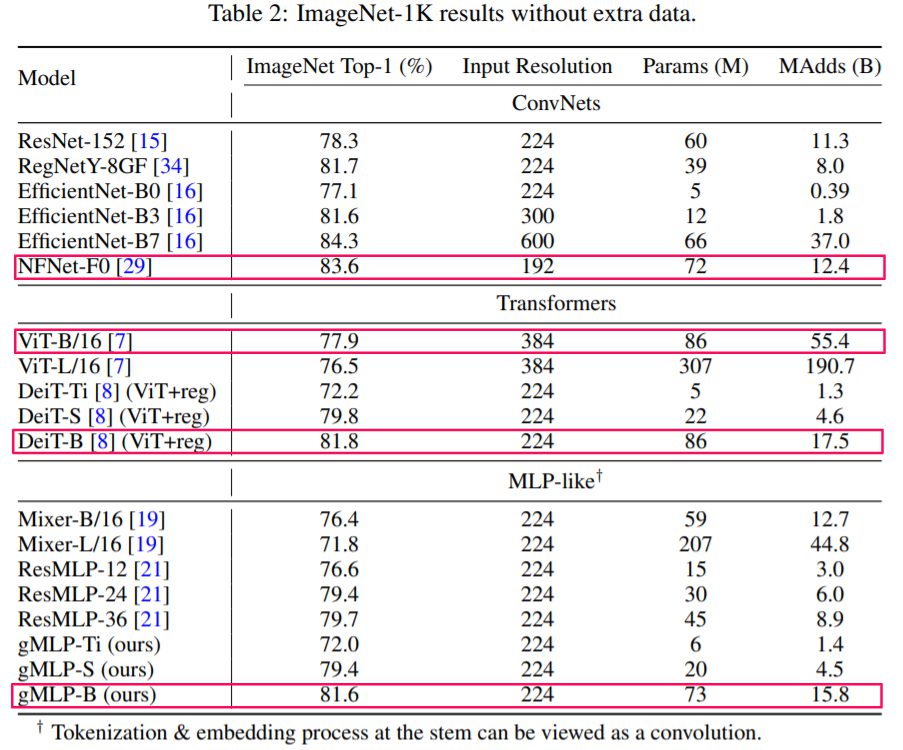
結果
DeiTとあまり変わらない結果が得られました。また、gMLPは直前に提出されたほかのMLP系の新モデルよりもよい精度が出せています。
このことから、gMLPはTransformer同様のデータ効率性があると考えることができます。
また、それ以上に既存のCNNモデルの方がよい精度を出しているということも注目に値します。
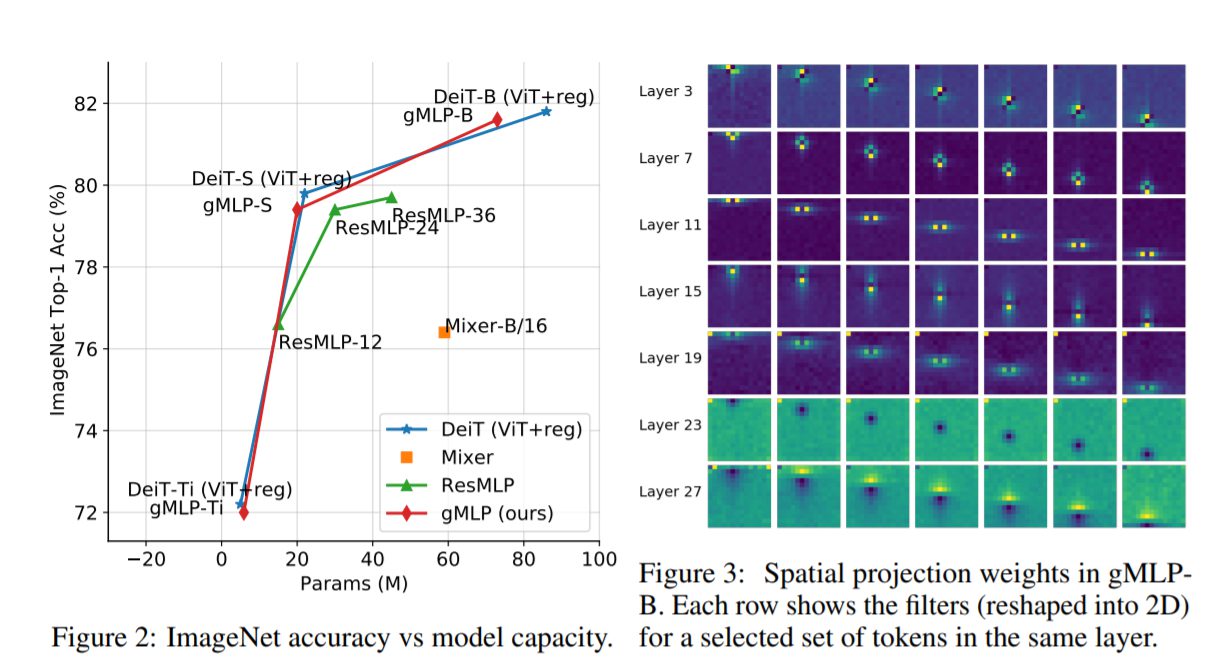
なお、下記の右図で示されているようにgMLPの空間射影行列を可視化したところ、CNNのような局所不変性と空間不変性が確認されました。つまり、各空間射影行列では、データ駆動型の不規則な(非正方形な)カーネルを用いて畳み込みを実行することを効果的に学習しているとも言えます。
自然言語処理
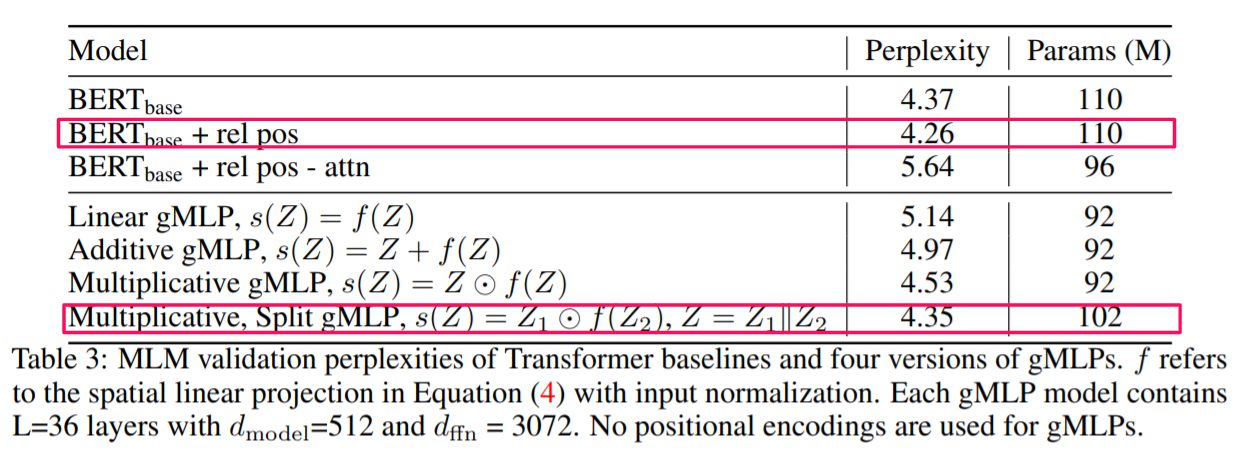
条件を変更したBERTとの比較が行われています。
Perplexity
まず、NLPの言語モデルの評価指標の一つであるPerplexity(単語の平均分岐数:低いほうが良い)で比較されています。両者の最高のモデル同士では性能にほぼ差がないことが明らかになりました。
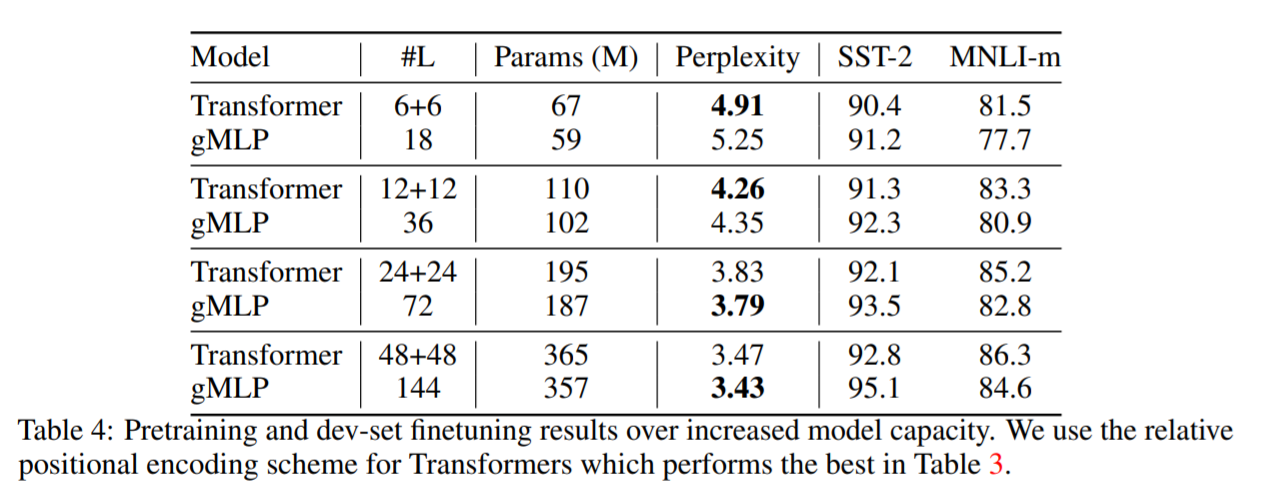
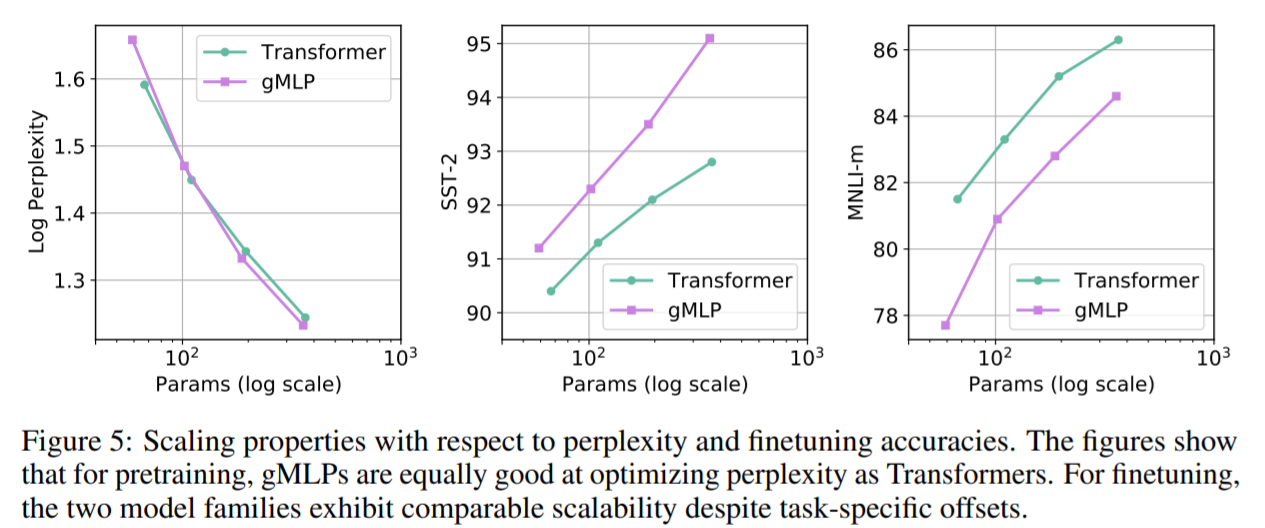
スケーラビリティ
TransfomerとgMLPのモデルサイズを大きくしたときの性能の変化を確認しています。
Perplexityに関しては両者はほぼ同じような精度を出していると言えます。それだけでなく、あるモデル容量からgMLPの方がよくなっているとも言えます。ただし、SST-2ではgMLPの方が精度が良いのにもかかわらず、MNLI-mではTransformerの方がよい結果を出しています。このことから、Attention機構を用いることでNLPの一部のタスクでは有効に働くことが考えられます。
SST(Stanford Sentiment Treebank):感情分析(Sentiment Analysis(SA))タスク
文章がどの感情を示しているものかを分類するタスク。SSTはRotten Tomatoes の映画レビューから構成した構文解析木のことで、 ツリーの各ノードに negative(1) 〜 positive(25) までの25段階評価が振ってある。なお、SST-2とはそれをNegatibeとPositiveの2段階に単純化したもの。
MNLI(Multi-Genre Natural Language Inference):自然言語理解 (General Language Understanding Evaluation(GLUE))タスク
前提文Tが仮説文Hを含意するか否かを判定するタスク。MNLIはテキスト含意情報で注釈が付けられた433kの文のペアを含むコーパスのことで、話し言葉や書き言葉など様々なジャンルをカバーすることでSNLIより一般化評価が可能になっている。(MNLI-m はMultiNLI Matched、 MNLI-mm はMultiNLI Mismatchedを意味している。)
また、TransformerもgMLPも精度の違いはありますが、モデル容量を大きくすることで精度が向上傾向にあることはわかります。これはTransformer系の強みともされていたスケーラビリティがgMLPにもある可能性があることを示しています。このことから、gMLPの精度の問題もTransformerと同様にモデル容量を大きくすることで解決することが可能であると考えられています。
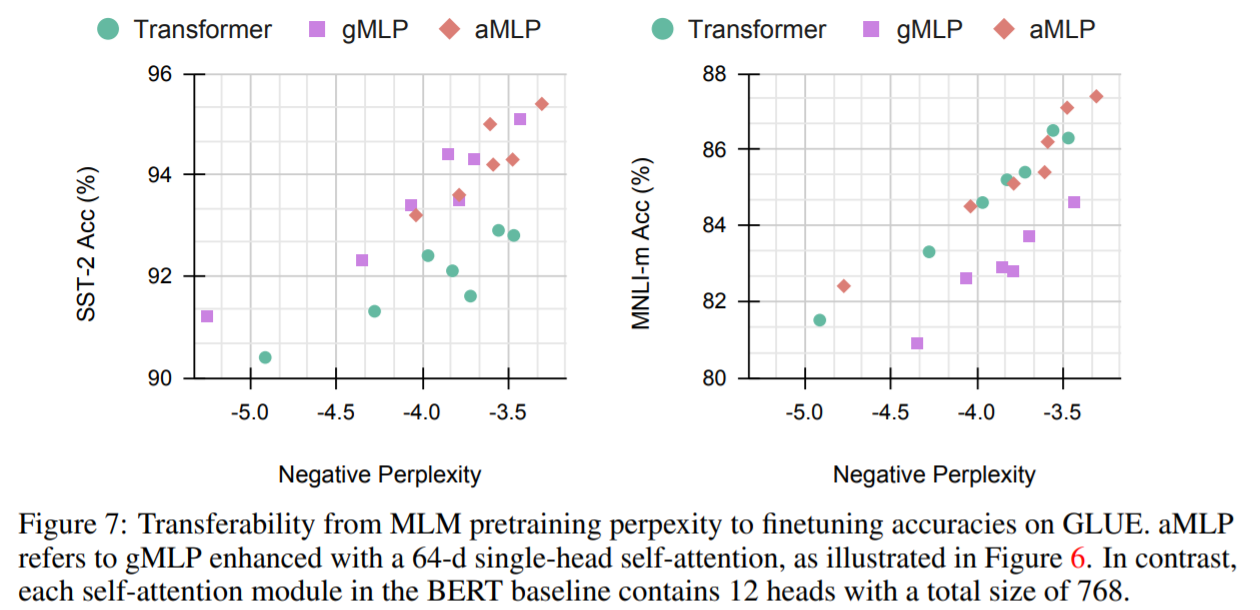
Attention機構の有用性
これまでの結果から、Attention機構は特定のタスク、今回であればMNLIなどには有効である可能性があり、それを確かめる必要性からgMLPにAttention機構を接続したモデルaMLPを用いて精度確認が行われました。
Self-Attention機構は、トークン間というよりも文レベル間の関係性を取るのに有用でないかと考えられます。gMLPでもトークン間の空間情報を取ってくることはできていたと考えられるため、追加するAttention機構は比較的小さい典型的なmulti-head attentionを接続しました。

aMLPは見事にgMLPの欠点部分を克服し、MNLIでもよい精度を出すことができています。
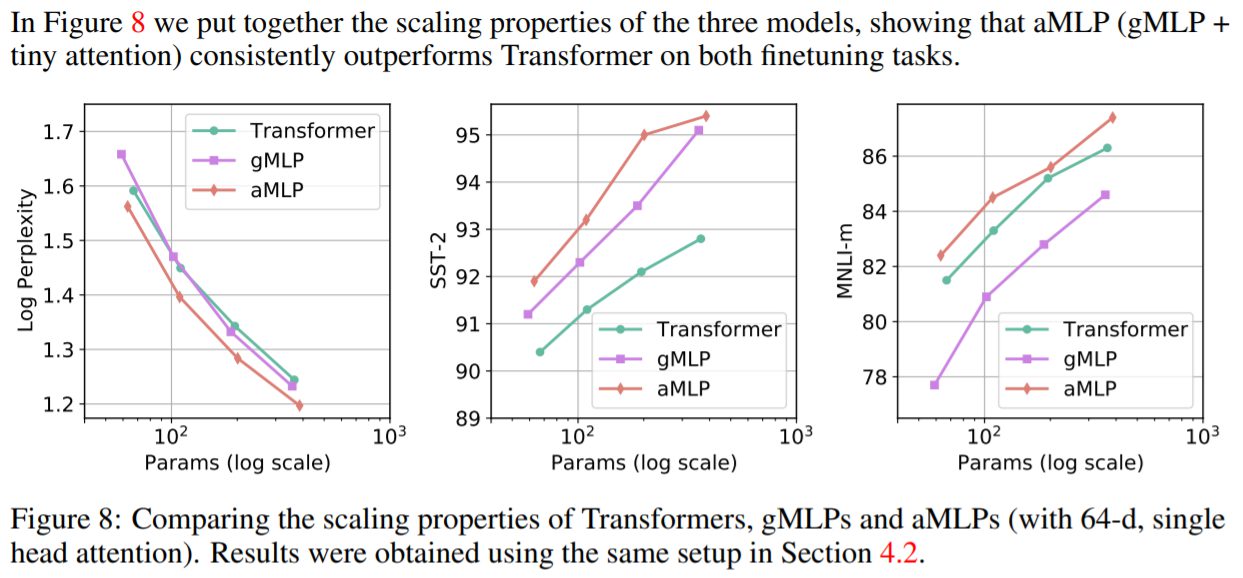
最終的な評価
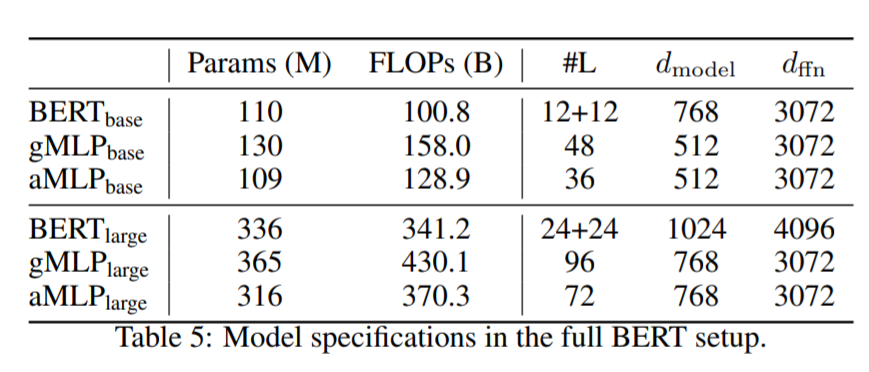
英語のC4データセットを使い、すべてバッチサイズ256、最大長512、100万回のトレーニングステップという条件で各モデルの精度を確認しました。また、より長い文章への対応力を測るために、 SQuAD(Stanford Question Answering Dataset)という質問回答タスクデータセットも新たに用いています。
評価に用いられたモデル
結果
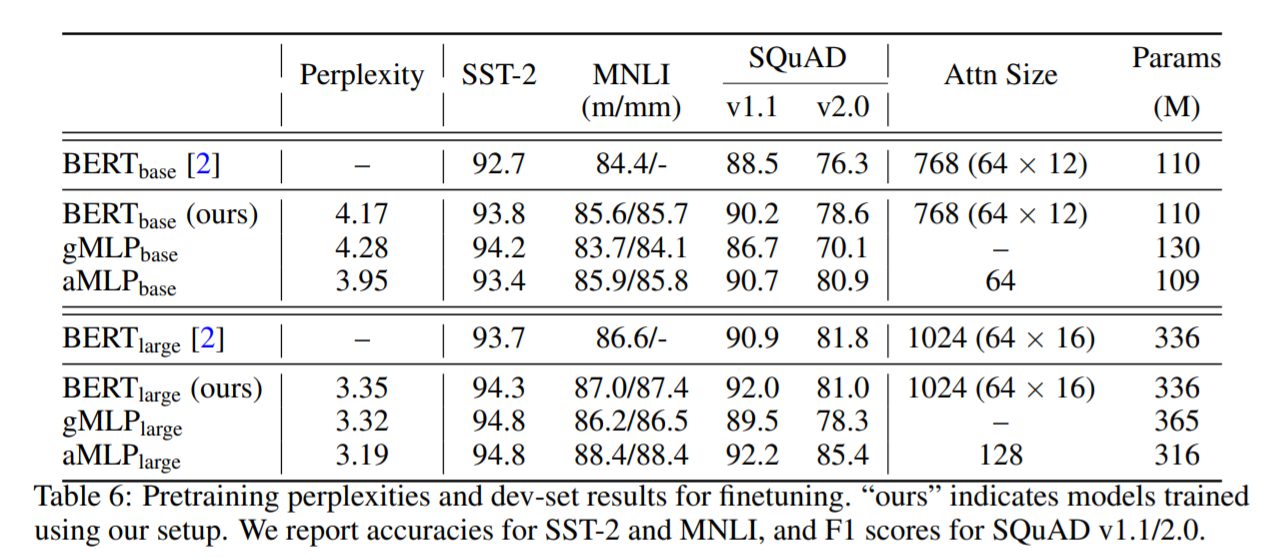
論文に掲載されたもともとのBERTbaseよりもgMLPlargeの方がよい精度を出すことがSQuADv1.1で出来ています。 これはスケールを大きくすれば、これはgMLPのようなAttention機構を持たないモデルでもNLPの様々なタスクでもTransformer系と互角に戦える可能性があることを示しています。
それだけでなく、Attention機構を加えたaMLPはすべての指標でTransformer系を超えています。精度上の問題は、gMLPのスケールを大きくすることで解決することができますが、実用上ではこの小さなAttention機構を加えるという作業は精度改善を行える手法ということが言えます。
まとめ
今回のGoogle Brainチームからの発表はMLPベースのモデルでもTransformerと同程度の精度を出すことができるというものであり、決してTransformerの方が悪いということではありません。少なくともすぐにTransformerからgMLPが主流となるとは言えません。また、gMLPの問題点等は今後明らかになっていくと思われます。
ただし今回の発表はTransformerは他のベースモデルを圧倒し、AIの主流となると考えられていただけに衝撃的なものといえるのではないでしょうか。今後Transformerだけでなく様々な可能性を検討した新しいモデルが登場することが考えられ、モデルの乱立も懸念されます。少なくともTransformer以外のモデルについても検討していくことが求められそうです。