
はじめに
独フライブルク大学らの研究チームが、表形式データに対しても単純なニューラルネットワークモデル(MLP)が正則化次第で、決定木などの機械学習モデルよりも性能が良くなることを発表しました。これまで勾配ブースティング決定木などの機械学習モデルのほうが優勢だった表形式データに対してもニューラルネットワークが今後利用されていくことが想定されます。
Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data
https://arxiv.org/pdf/2106.11189.pdf
概要
これまで表形式データに対しては決定木系の機械学習(ML)のほうがディープラーニング(DL)よりも性能が良いとされてきました。表形式データに対して最適化されたDLも発表されましたが、はっきりとMLよりも良いといえない状況にありました。
今回のフライブルク大学の論文は正則化を適切に行うことで、単純なMLP(Multi-Layer Perceptron)でも最も精度のよいとされるMLモデル(XGBoost)よりもよい精度をだすことができることを示しました。
今後、表形式データに対してもDLの利用が普及すると考えられます。
論文のポイント
・DLで画像データなどのローデータ(raw data)に対して基本的に利用されている正則化技術は表形式データに対しても有効である。
・「正則化カクテル」と名付けられた正則化技術とハイパーパラメータの最適サブセットの提案。
・シンプルなMLPでもGBDT(特にXGBoostなどのトップモデルに対しても)よりもよい精度が出せる。
詳細
研究背景
勾配ブースティング決定木(Gradient-Boosted Decision Trees:GBDT)などがこれまでは表形式データに対しては性能が最もよいとされてきました。また、DLは画像や音声などMLモデルが苦手とするローデータを得意としていたため、ローデータに対する研究が進められ、表形式データに対しての研究はこれまであまり進められてきませんでした。
それでも近年、表形式に特化したDLがGBDTを上回ったとされた研究論文もいくつか出されましたが、それに対する反証論文もでており、DLの優位性がはっきりと示されたとはいえない状況にありました。(実際今回研究チームが確認した所、ハイパーパラメータをきちんと調整した場合、GBDTのほうがよいことも確認されました。)
今回研究チームは表形式データに対して特化させたDLモデルを作成しなくても、正則化をきちんと行えばMLモデルよりも性能が良くなることを示しました。(※論文中には明示されていませんが、おそらくDLモデルがタスクに対して表現力不足であるというよりも学習しやすい表形式データに過剰適合することが問題ではないか、という発想であると考えられます。)
正則化 Regularization
研究チームはDLモデルでローデータに対して一般的に行われているデータ拡張、残差ブロック、ドロップアウトなどの正則化手法がそのまま表形式データに対しても利用できることを指摘しています。
ポイントは、「数十種類以上存在する正則化手法の中から、特定のデータセットで最大の汎化性能を発揮する正則化剤のサブセットを発見すること」にあるとしています。このことを論文では、「正則化カクテル Regularization Cocktails」と表現しています。
正則化技術とその固有のハイパーパラメータの最適なサブセットの選択を、13種類の最新の正則化技術とその補助的なハイパーパラメータのプールの中から、各データセットに対して探索します。最適な組み合わせを発見することで、各タスクに対してMLPでも十分な性能がだせるだけでなく、XGBoostなどの既存トップモデルよりもよい精度をだすことに成功しました。
DLで利用されている主な正則化技術
荷重減衰(Weight decay):パラメータのノルムを小さくすることに焦点をあてた手法。L1やL2、またエラスティックネットを利用したものが知られている。Adamなどの実装でもみられる。
データ拡張(Data Augmentation):Cut-Outは入力空間の分布に対して不変性を維持した予測が保証されている。Mix-Upも同様の効果がある。
アンサンブル学習(Model Averageing):バリアンスを減らすと考えられる。ドロップアウトなどが知られている。
構造的正則化(Structural and Linearization):構造的な正則化技術を指す。ResNetのスキップコネクションなどが該当。
暗黙の正則化(Implicit):直接的に正則化することを目指した技術ではないものの、結果として正則化の効果が確認されているもの。バッチノーマライゼーションなど。
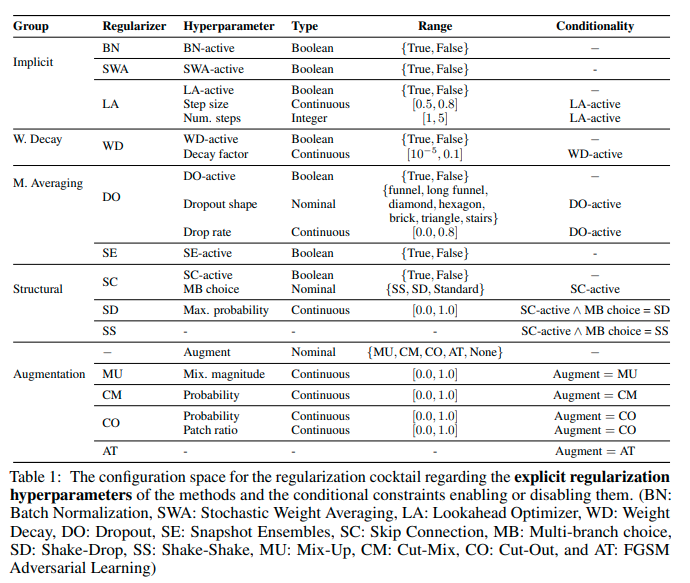
正則化カクテル
最適な正則化手法の組み合わせをみつけることが重要になります。
まず、正則化項を組み合わせた目的関数を定めます。この目的関数が最小になるようなものが正しく正則化が行えたモデルになります。
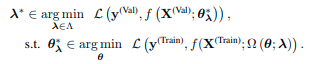
Ω=正則化項、λ=正則化項のハイパーパラメータ
この基本的な目的関数を最小化するような正則化技術の組み合わせを考えることになります。そのため、ここではK個の正則化技術を組み合わせたものが想定されます。
K個の正則化技術の組み合わせ
![]()
このK個の正則化技術の中から最適なものを探すために、以下の式を最小化することを目的に探索を行います。
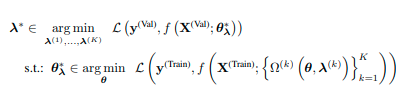
実際にこの組み合わせのなかで最適なものを探索するために、論文ではベイズ最適化を利用しています。(the multifidelity Bayesian optimization method ( BOHB: Bayesian Optimization and Hyperband )の利用)
このベイズ最適化をもとに最適な正則化手法をみつけることでDLモデルが既存のMLモデルよりもよい性能をだすことができました。
実験
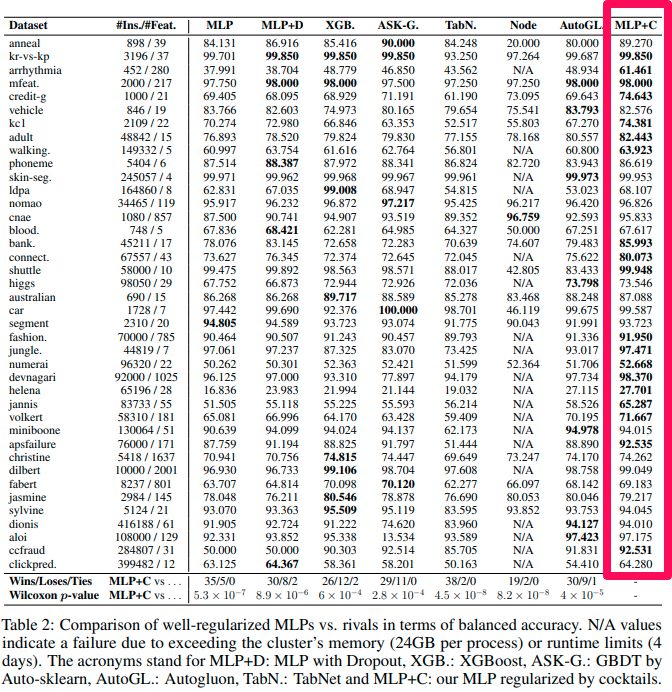
Kaggleなどの有力なコンペティションサイトでも利用されている以下のデータセットに対して、DLモデルと既存の最高精度モデル(多くはXGBoost)を比較しました。(データポイント:452〜416188、特徴量:4〜2001)
結果は以下のとおりです。ほとんどのタスクで単純なMLPや改良したDLモデルが最もよい性能を出しています。このことから、表形式データに対してDLモデルが必要なことはモデルの改良というよりも正則化であることが明らかになりました。
制限
正則化を行うことで単純なMLPでも表形式データに対して十分に性能をだすことができることがわかりました。しかし、一方で論文では以下の点に問題点があることも表明しています。
・計算コストがどうしてもかかってしまう。(最適な正則化手法の組み合わせを探索するために、時間がかかってしまっています。)
・分類問題しか解いてないので、回帰問題でも同様の結果が得られるかはわからない。
・バランスがよいデータセットでしか検証していない。(データセット内のクラスの割合が均等であること)
・データが極端に少ない場合についての検証が足りていない。(最小のデータセットでも500弱存在している)
まとめ
今回は、正則化をうまく利用することでDLモデルでも表形式データに対してもよい性能をだせることを明らかにした論文をご紹介しました。探索のための計算コストがネックにはなりますが、今後DLモデルも利用モデルの候補にはいれるべきであると考えられます。よりよいハイパーパラメータの探索手法が望まれます。