はじめに
ICLR2022に向けて、ViT や MLP-Mixer などよりもシンプルな作りにもかかわらず、より高性能な新モデル ConvMixer が発表されました。
ViT をはじめとして強力な Transformer 型の画像処理モデルが次々に発表されていますが、今回紹介する論文は Transformer 型モデルが強力な理由として Attention 機構だけでなく入力画像をパッチ単位(事前に定めた大きさごとに画像を分割したもの)にする点にあるとしています。
●Vision Transformer
画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!
●Transformer
自然言語処理の必須知識 Transformer を徹底解説!
●MobileNet
・軽量モデルに新風を巻き起こした代表格!MobileNetV1 を詳細解説!
・モバイル向けの代表モデルMobileNetV2を詳細解説!
概要
画像処理の世界はながらくCNNベースのモデルが主流でした。よく知られているResNet やVGG などは、現在でも多くのモデルで利用されています。
対して、自然言語処理の世界では、Attention機構を利用したTransformerベースのモデルが目覚ましい性能を発揮し、現在ではTransformerをベースに設計することがデファクトスタンダードであると言えます。
そうした状況を受け、近年 Vision Transformer(通称 ViT) をはじめとしてTransformer を利用したモデルが画像処理の世界でも作られるようになりました。それらはとくに巨大なデータセットで優れた性能を発揮したことで大きな注目を集めています。
今回の論文は、そうした潮流が前提としている Transformer の骨格である Attention 機構が重要であるという論に対して疑問を投げかけたことで新たな可能性を提示しています。
研究者チームは、Attention 機構ではなく、Transformer を画像に対して利用するために必要な「画像をパッチ単位に分割すること」が重要であると仮定し、それらを実証するために、入力画像をパッチ単位に分割すること以外は普通のCNNモデルとほとんどかわらない ConvMixer を開発しました。
ConvMixer はベンチマークなどに対して最適化処理をしていないにもかかわらず、ViTやMLP-Mixer よりもよい性能を記録し、DeiTなどのSoTAモデルにも匹敵する性能を出しました。研究チームは、計算資源の問題から試せていないが、より最適な設定にすることで強力なベースモデルになるのではないかと想定しています。
- ・入力画像に対して、パッチサイズに分割しエンベディングする処理することは、Attention 機構と同じくらい重要なであると提唱。
- ・入力画像をパッチ単位に分割するだけのCNNをベースとしたシンプルなモデル ConvMixer を開発。
- ・今後ベースモデルとされ、改良系が開発されることを想定。
PPT版はこちらをご参考下さい。
詳細解説
背景
ここ数年のAIモデルの潮流として、画像処理は CNN ベース、自然言語処理は Transformer ベースという流れがありました。
Transformer が自然言語処理の世界で革新的な性能を発揮したため、画像処理にも Transformer を取り入れたいというモチベーションはあったのですが、大きな問題として、画像が Transformer が受け入れるシーケンスデータではないというものがありました。(※シーケンスデータとは、前後のデータ間に影響関係があるようなデータのこと。一般的に文章や気温データなどが知られている。)画像をピクセル単位で扱うことで、シーケンスデータのように扱うこともできますが、計算能力が向上している現在でも計算コストや計算資源のことを考えると現実的ではありません。
そうした状況を変えたのが、Vision Transformer(通称 ViT )です。ViT は画像をパッチ単位(事前に設定した一定の大きさ)で分割しエンベディングすることで、シーケンスデータのように利用することで可能にしました。シンプルですが、このことで ViT はTransformer を画像処理の世界に持ち込むことに成功しました。
特により巨大なデータセットで ViT が効果を発揮することを明らかにしました。このことから、自然言語処理の世界でデファクトスタンダードになったように、画像処理の世界でも Transformer がデファクトスタンダードになるのかもしれないと考えられるようになっています。
こうした性能の向上は、通常 Transformer の核である Attention 機構が大きな寄与をしているように考えられています。そのため、画像をパッチ単位に分けエンベディングする処理が Attention 機構に悪影響を与えていると考えられ、できるだけこの部分を省こうとする研究も多くなされました。
今回研究チームが提唱している仮説はそうした考えに疑問を呈し、Transformerに入れる前の前処理で画像をパッチ単位にわけエンベディングすることが重要な要因なのではないか、という発想からきているものです。
そのことを明らかにするために、よりシンプルなCNNベースのConvMixerを開発しました。シンプルながら、ResNet などの従来のものや、VitやMLP-Mixerなどと比べても性能がいいことを示し、パッチ表現それ自体がより重要であることを証明できるようになっているとしています。
ConvMixer
ConvMixer は以下の点で基本的に ViT などと同じようになっています。
1.パッチ単位で処理すること
2.解像度とサイズの表現を各層を通して維持すること
3.連続する層で表現をダウンサンプリングしないこと
4.情報の空間的融合からチャンネル単位の融合を切り離すこと
決定的に異なるのは、「一般的な畳み込みしか利用しないこと」です。(=複雑なアーキテクチャ構造は利用していません。)
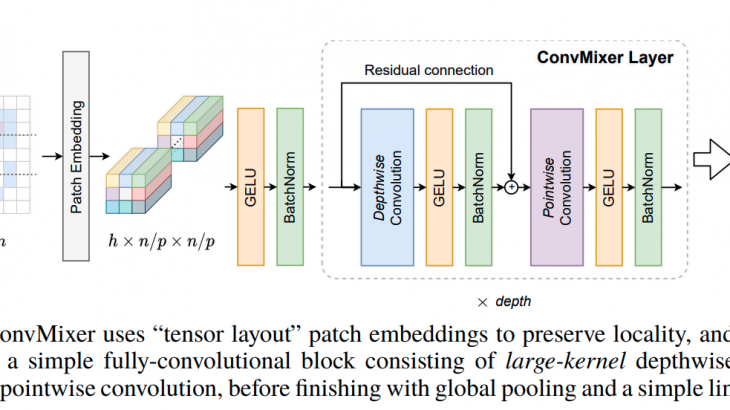
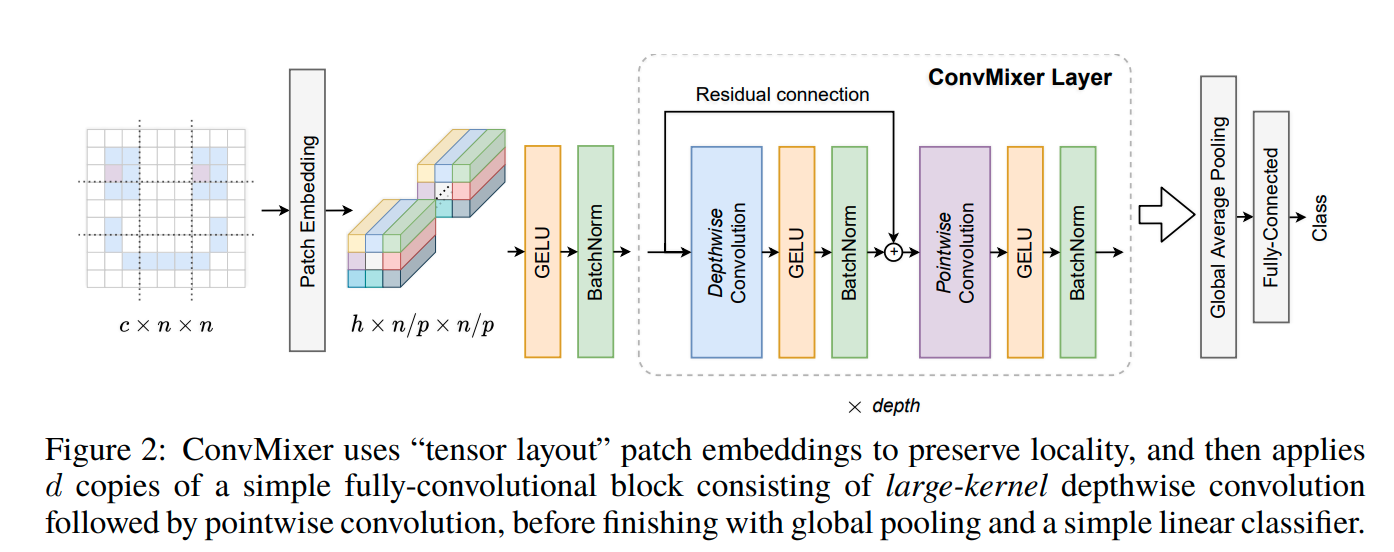
ConvMixer のモデル図
ConvMixer のコード図

基本的にシンプルな畳み込みブロックで構成されています。
パッチエンベディング Patch embedding

パッチサイズがp、エンベディング次元がhなら、ストライドp、カーネルサイズp、アウトプット次元がhのような畳み込みと同じであるといえます。
ConvMixer

ConvMixer は基本的に Depthwise Convolution と Pointwise Convolution を利用したものになります。加えて、ResNet などでつかわれる残差接続と、バッチノーマライゼーションが適用されています。なお、通常よりも大きなカーネルサイズが Depthwise Convolution では有効であることが確認されています。
最終的に、ソフトマックス分類機にわたすサイズhの特徴量ベクトルを取得するためにグローバルアベレージプーリングを行っています。
ConvMixerのパラメータ
ConvMixer で重要となるパラメータは以下の4つになります。(これらは実験で適切な値が模索されています。)
①パッチエンベディングの次元 h (隠れ次元)
②深さd(もしくはConvMixer層を繰り返す数)
③パッチサイズ p(モデル内部の解像度をコントロールする)
④Depthwise Convolutionのカーネルサイズ k
なお、h/d でモデルのヴァリエーションを表記しています。
ConvMixer のポイント
MLPs と Self-Attention は距離のある空間的位置を効果的に調整する=任意の大きさの受容野になるということが有用であるとされていますが、ConvMixer も同じように、大きなカーネルサイズの畳み込みを利用することで、距離のある空間的位相を効果的に調整することが可能となっています。
また、Transformer系は理論的により柔軟で、より大きな受容野でコンテンツを意識した挙動が可能であることがメリットですが、CNNベースのモデルには、畳み込みがもたらす帰納的バイアスが画像タスクと高いデータ効率性に有効に働くという点で大きなメリットがあります。ConvMixer は畳み込みの基本的な処理をしているだけであり、このことは畳み込みネットワークの従来のピラミッド型のプログレッシブダウンサンプリング設計とは対照的に、パッチ表現自体の効果も垣間見ることができることを指摘しています。
実験
初期実験
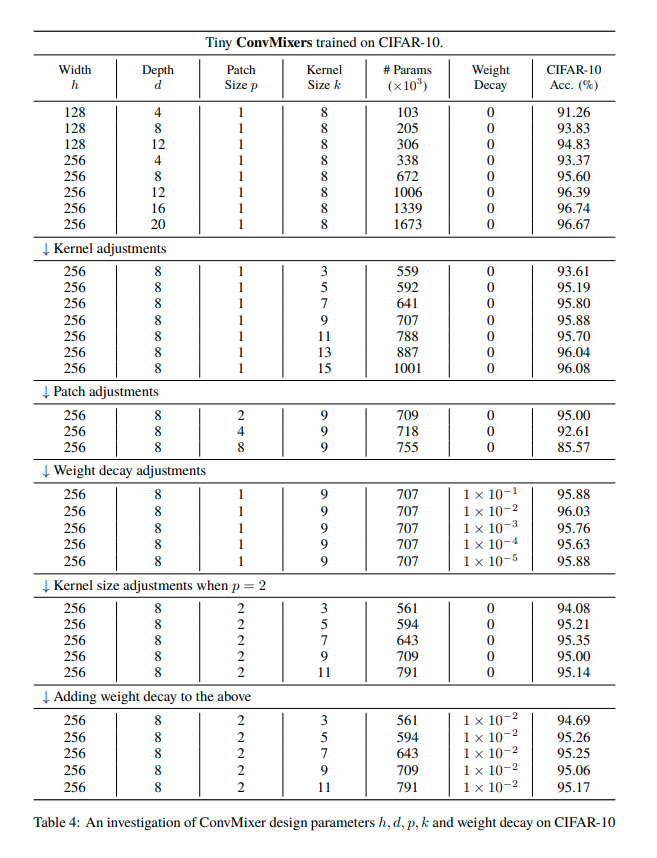
CIFAR-10 を用いて行われ、0.7 M パラメータで約96%の精度を達成しました。
なお、その際にアブレーション実験が行われ、最適な設定が確認されています。
結果の概要

詳細な結果
ImageNet-1Kを用いた実験
●実験のセットアップ
データセット:ImageNet-1K
データ拡張:RandAugment、mixup、CutMix、random erasing、勾配ノルムクリッピング
最適化関数:AdamW(学習率スケジュールラーも利用)
●結果
ConvMixer-1536/20 with 52M parameters ⇨ 81.4%
(なお、k=9→k=3にすると、1%精度が下がる)
ConvMixer-768/32 with 21M parameters ⇨ 80.2%

まとめ
ConvMixerは最初に「パッチ単位のエンベディング」をすることにより、通常のCNNで段階的に行われるダウンサンプリングを一度に実行できるため、内部解像度がすぐに低下し、有効な受容野サイズが増加して、離れた空間情報を簡単に混合(=Mixer)できるようになります。そのため、パッチエンベディングの使用も、強力で重要なポイントであるといえます
ConvMixer はネットワークを通じて、同じサイズ、シェイプを維持する等方的アーキテクチャです。(等方的とは、ある対象の性質や分布が方向に依存しないこと。)系統的には、MobileNetに近いもので、ConvMixerのほうがよりシンプルになっているといえます。シンプルなパッチエンベディングを備える「等方性」アーキテクチャ自体が、ディープラーニングの強力なベースであることを論文は示唆しています。