はじめに
2021年5月に台湾の中央研究院らの研究チームが発表した、暗黙知を組み込むことでよりマルチタスクに向けたモデル『YOLOR』を解説します。
※記事中で利用している図は特に断りがない限り、論文から引用しています。
『You Only Learn One Representation: Unified Network for Multiple Tasks』
https://arxiv.org/pdf/2105.04206v1.pdf
概要
人間は五感と過去の経験を通して世界を理解します。意識的に獲得される知識「形式知」と無意識のうちに習得される知識「暗黙知」と呼ばれるものを組み合わせることで、新しいものやことに出会っても柔軟に対応することができます。
今回、研究チームは暗黙知と形式知の統合をはかるモデルの開発に取り組むことで、モデルを簡単に複数のタスクにも対応できるようにしました。
論文の主張するポイント
1.統合ネットワークの提案
さまざまなタスクを実行できる統合ネットワーク(=YOLOR)を提案しています。暗黙知と形式知を統合することで一般的な表現を学習し、この一般的な表現を通じてさまざまなタスクを完了することができるようにしました。 提案されたネットワークは、ごくわずかな追加コスト(パラメーターと計算の量の1万未満)でモデルのパフォーマンスを効果的に改善しています。
2.暗黙知学習プロセス
暗黙知学習プロセスに「カーネル空間アラインメント」、「予測改良」、「マルチタスク学習」を導入し、それらの有効性を検証しています。
3.暗黙知のモデル化
暗黙知をモデル化するためのツールとして、「ベクトル」、「ニューラルネットワーク」、「行列因数分解」を使用する方法についてそれぞれ説明し、同時にその有効性を検証しています。
4.暗黙知の効果
学習した暗黙知(一般表現)が特定の物理的特性に正確に対応できることを確認し、視覚的な方法でも提示しています。また、目的の物理的意味に一致する演算子を使用すれば、暗黙知と形式知を統合することができ、乗数効果があることも確認されました。
5.精度
最先端の方法と組み合わせることで、提案されたYOLORは、オブジェクト検出でScaled-YOLOv4-P7と同等の精度を達成し、推論速度を88%向上させました。
詳細
開発背景
人間は下記の図を見た時に様々な角度から物事を見ることができます。しかし、現在のモデルはタスクにあわせた判断しか出来ていません。一般的に、現在ニューラルネットワークモデルで抽出できる特徴は、通常、他タスクへの適応性が不十分です。この適応性が不十分である原因には、人間における「暗黙知」が利用されていないことが原因と考えられます。

暗黙知は無意識下で学習されていると考えられています。そのため、どの様に学習され、取得されるかは明確に定義づけられているとは言えません。一般的にニューラルネットワークでは浅い層で取得される特徴量は「形式知」と見立てられ、深い層で取得される特徴量は「暗黙知」とされています。本論文では、観察に直接対応する知識を「形式知」と呼び、観察とは直接関係のない知識については、「暗黙知」と呼ぶこととしています。
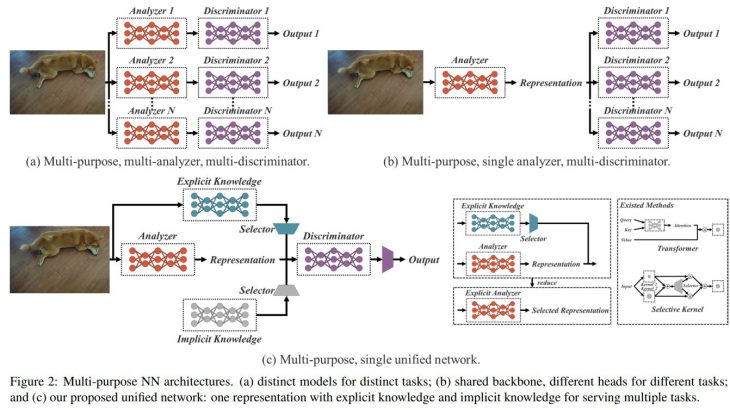
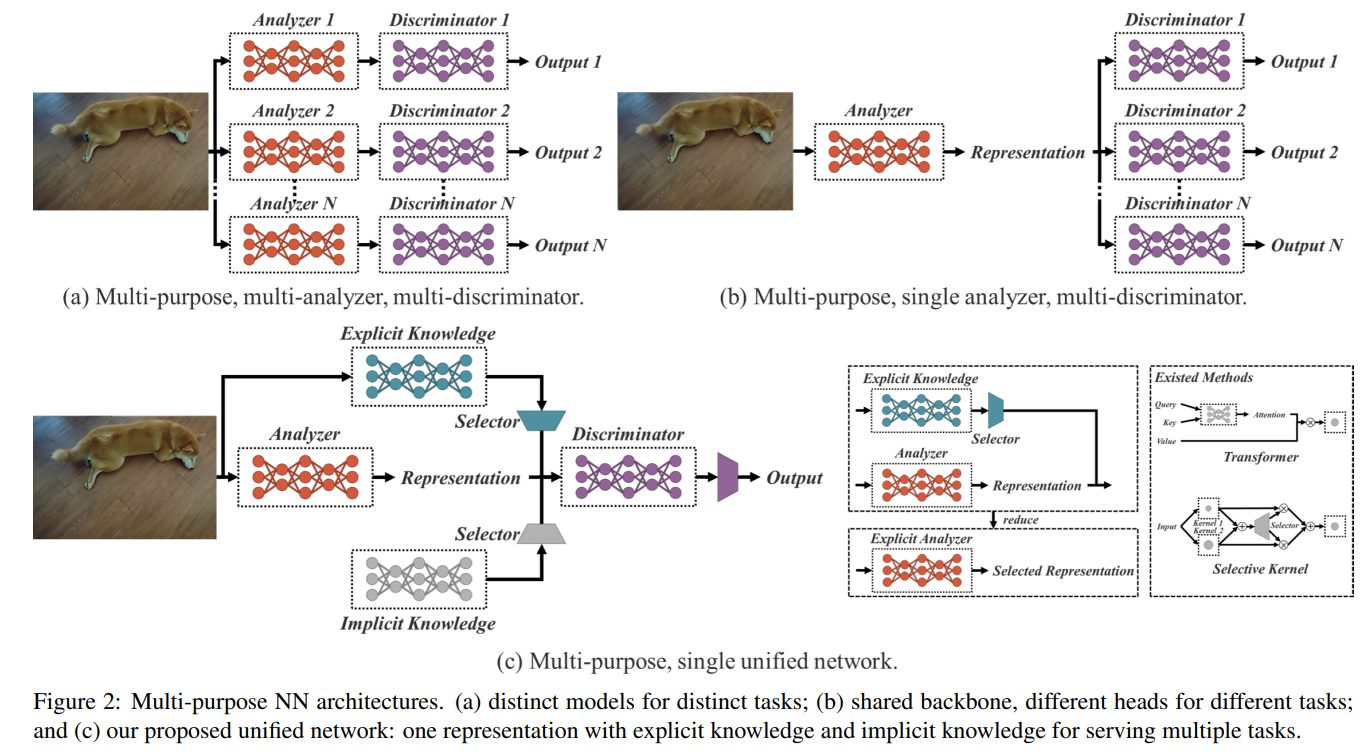
今回、研究チームは「暗黙知」と「形式知」を統合し、学習したモデルに「一般表現」を含めることができる統合ネットワークを提案しています。この「一般表現」により、さまざまなタスクに適した「サブ表現」が可能になります。
YOLORモデル図
先行研究
以下の三つの方向性について事前研究が行われています。
(1)明示的深層学習:
入力データに基づいて機能を自動的に調整または選択できる方法(Transformerなど)
(2)暗黙的深層学習:
暗黙的深層知識学習と暗黙的微分をカバーしている。(暗黙的深層表現と深い平衡モデル)
(3)知識モデリング:
暗黙知と明示的知識を統合するために使用できる方法。(知識モデリングや、スパース表現など))
暗黙知はどのように機能するのか
暗黙知の集合 Z = {z1, z2, …, zk} がどのように様々なタスクで有効利用するのか、を詳しく解説していきます。
多様体空間の削減
前提として、「優れた表現」は、それが属する多様な空間で適切な投影を見つけ、その後の客観的なタスクを成功させることができるはずと考えることができます。
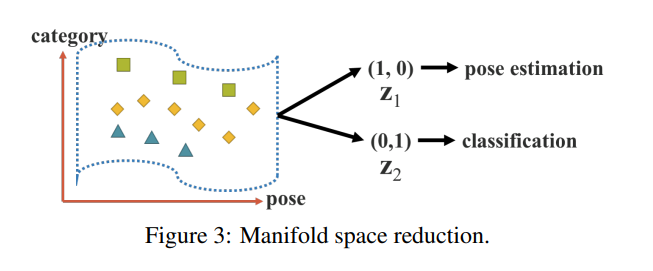
ターゲットカテゴリが投影空間の超平面によって正常に分類できる場合、最良の結果になります。 図3で示すように、「射影ベクトル」と「暗黙の表現」の内積を使用して、多様体空間の次元を減らすことで、さまざまなタスクを効果的に達成することができます。
カーネル空間のアラインメント
マルチタスク(およびマルチヘッド)ニューラルネットワークでは、「カーネル空間の不整合」が頻繁に発生します。図4.(a)は、カーネル空間の不整合の例を示しています。
この問題に対処するために、「出力特徴」と「暗黙的表現」の加算と乗算を実行して、図4.(b)に示すように、カーネル空間を変換、回転、およびスケーリングします。このことで、ニューラルネットワークの各出力カーネル空間をアラインメント(整列)させることができます。
上記の操作は、特徴ピラミッドネットワーク(FPN)での大きなオブジェクトと小さなオブジェクトの特徴の位置合わせ、大きなモデルと小さなモデルを統合するための「蒸留」の使用、ゼロショットドメイン転移学習の処理など、さまざまな分野で広く使用できます。

より多くの機能について
さまざまなタスクに適用できる機能に加えて、「暗黙知」をさらに多くの機能に拡張することも今回のモデルでは可能としています。
図5(a)に示すように、加算を導入することにより、中心座標のオフセットを予測するニューラルネットワークを作成できます。
また 図5(b)で示されるように、 乗算を導入して、アンカーのハイパーパラメータセットを自動的に検索することもできます。(アンカーベースのオブジェクト検出器ではアンカーのハイパーパラメータの設定がひとつの課題となっています。)
さらに 図5(c)で示すように、内積と連結をそれぞれ使用して、マルチタスクの特徴選択を実行し、後続の計算の前提条件を設定できます。

統合ネットワークにおける暗黙知
従来のネットワークと論文で提唱している「統合ネットワーク(=YOLOR)」の目的関数を比較します。そのことで、暗黙知の導入が多目的ネットワークのトレーニングに重要である理由を明らかにします。
暗黙知の公式
従来のネットワークの目的関数は、以下のようになります。

x:観測値
θ:ニューラルネットワークのパラメーターのセット
fθ:ニューラルネットワークの関数
ε:誤差項
y:特定のタスクのターゲット
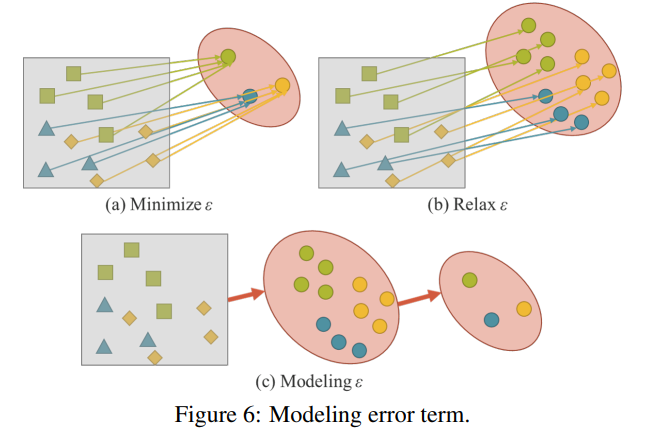
従来の学習では、通常、fθ(x)をターゲットにできるだけ近づけるために最小化されます。これは、図6.(a)に示すように、同じターゲットを目的とする異なる観測値が、fθによって取得されるサブ空間内の単一のポイントに収まると予想されていることを意味します。つまり、従来の学習で期待している解の空間は、現在のタスクtiに対してのみ識別可能であり、さまざまな潜在的なタスクT \ ti(T = {t1、t2、…、tn})に対してはほとんどの場合、うまく利用できません。
汎用ニューラルネットワークの場合、得られた表現がTに属するすべてのタスクに役立つことが期待されます。したがって、図6(b)に示すように、多様体空間で各タスクの解決策を同時に見つけることができるように「リラックス(Relax)」する必要があります。
ただし、各タスクもこなせるようなtiの解を得るために、ワンホットベクトルの最大値やユークリッド距離のしきい値などの簡単な数学的方法を使用することは不可能となります。この問題を解決するには、図6(c)に示すように、誤差項をモデル化してさまざまなタスクの解決策を見つける必要があります。
統合ネットワーク
「統合ネットワーク」を学習するために、「形式知」と「暗黙知」を一緒に使用して誤差項をモデル化しています。今回モデル化された学習の方程式は以下のとおりです。
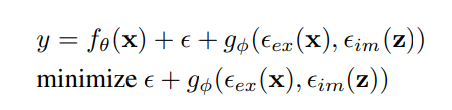
ここで、ΕexとΕimは、それぞれ、観測値xと潜在コードzからの明示的エラーと暗黙的エラーをモデル化する操作です。 ここでのgφは、形式知と暗黙知から情報を組み合わせたり選択したりするのに役立つタスク固有の操作です。
形式知をfθに統合するためのいくつかの既存の方法があります。
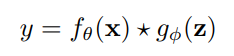
★ は fθ と gφ を組み合わせることができるいくつかの可能な演算子を表します。 今回は、加算、乗算、および連結の演算子を使用します。
エラー項の導出プロセスを複数のタスクの処理に拡張すると、次の式が得られます。
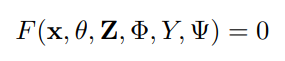
Z = {z1、z2、…、zT}:T個の異なるタスクの暗黙的な潜在コードのセット
Φ:Z から暗黙的な表現を生成するために使用できるパラメーター
Ψ:明示的な表現と暗黙的な表現のさまざまな組み合わせから最終的な出力パラメーターを計算するために使用される
さまざまなタスクについて、次の式を使用して、すべてのz∈Zの予測を取得できます。
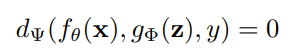
すべてのタスクについて、共通の統一表現fθ(x)から開始し、タスク固有の暗黙的な表現gΦ(z)を実行し、最後にタスク固有の識別子dΨを使用してさまざまなタスクを完了します。
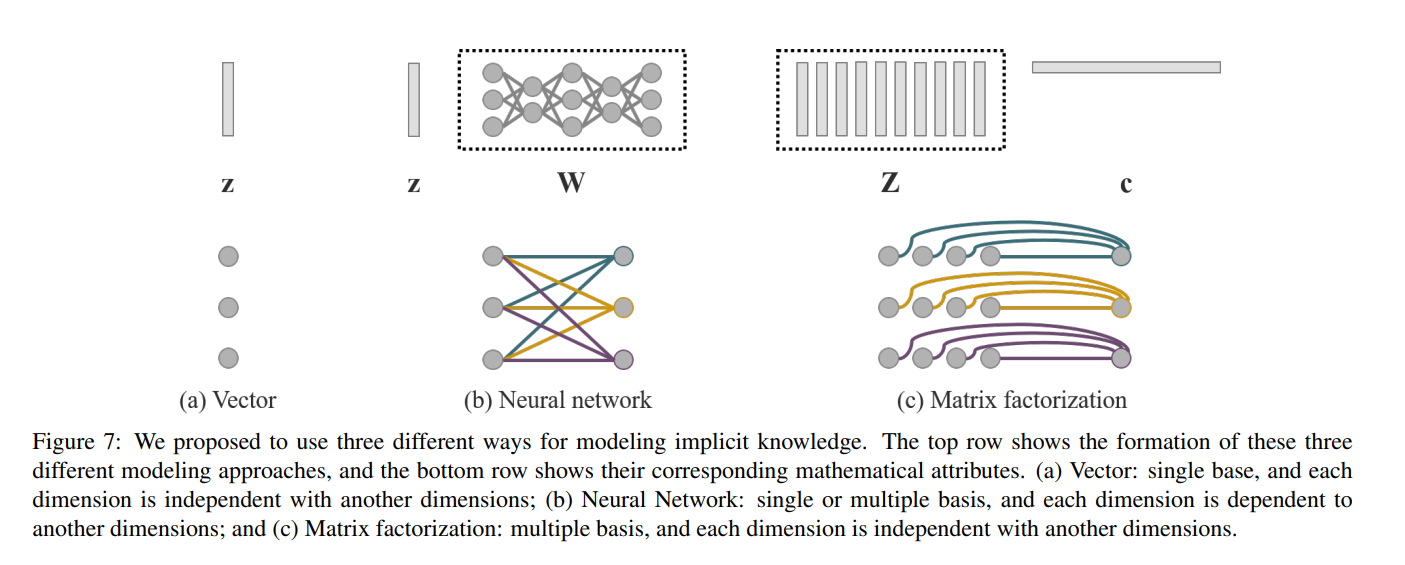
暗黙知のモデル化
Vector / Matrix / Tensor: Z
ベクトルzを暗黙知の事前知識として直接使用し、暗黙知として直接使用します。 このとき、各次元は互いに独立していると想定する必要があります。
Neural Network: Wz
暗黙知の事前知識としてベクトルzを使用し、次に重み行列Wを使用して線形結合または非線形化を実行することで、「暗黙知」となります。このとき、各次元は互いに依存していると想定する必要があります。
より複雑なニューラルネットワークを使用して、暗黙の表現を生成することもできます。または、マルコフ連鎖を使用して、異なるタスク間の暗黙的な表現の相関をシミュレートします。
Matrix Factorization: (Z**T)c
暗黙知の事前知識として複数のベクトルを使用すると、これらの暗黙の事前基底Zと係数cが暗黙の表現を形成します。
さらに、cに対してスパース制約を実行し、それをスパース表現形式に変換することもできます。さらに、Zとcに非負の制約を課して、それらを非負の行列因子分解(NMF)形式に変換することもできます。
学習
モデルが最初に暗黙知を持っていないと仮定すると、明示的な表現fθ(x)には何の影響もありません。
結合演算子★
★ ∈{加算、連結} ⇒ z〜N(0、σ)
★ ∈{乗算} ⇒ z〜N(1、σ)
※ σはゼロに近い非常に小さな値です。
※zとφについては、どちらも誤差逆伝播で学習されます。
推論
暗黙知は観測xとは無関係であるため、暗黙モデルgφがどれほど複雑であっても、推論フェーズが実行される前に、それを一定のテンソルのセットに減らすことができます。
言い換えれば、暗黙の情報の形成は、アルゴリズムの計算量にほとんど影響を与えません。また、上記の演算子が乗算の場合、後続の層が畳み込み層の場合は、以下の式を使用して積分します。
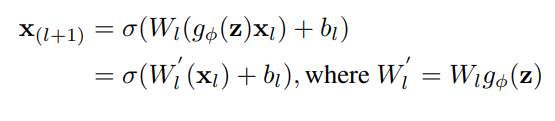
加算演算子に遭遇し、前の層が畳み込み層であり、活性化関数がない場合は、以下に示す式を使用して統合します。
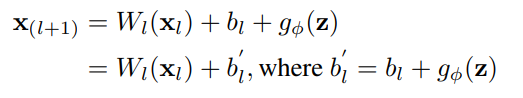
実験
実験では、MSCOCOデータセットを利用しています。MSCOCOでは、①「オブジェクト検出」、②「インスタンスセグメンテーション」、③「パノラマセグメンテーション」、④「キーポイント検出」、⑤「スタッフセグメンテーション」、⑥「画像キャプション」、⑦「マルチラベル画像分類」、⑧「 ロングテールオブジェクト認識」などのタスクへの対応が求められます。
実験のセットアップ
実験では、暗黙知を3つの側面(①FPNの機能の調整、②予測の改良、③1つのモデルでのマルチタスク学習)に適用しています。 マルチタスク学習の対象となるタスクには、「オブジェクトの検出」、「マルチラベル画像の分類」、および「機能の埋め込み」が含まれています。
実験のベースラインモデルとしてYOLOv4-CSPを選択し、図8の矢印が示す位置でモデルに暗黙知を導入します。すべてのトレーニングハイパーパラメーターは、ScaledYOLOv4のデフォルト設定と合わせています。
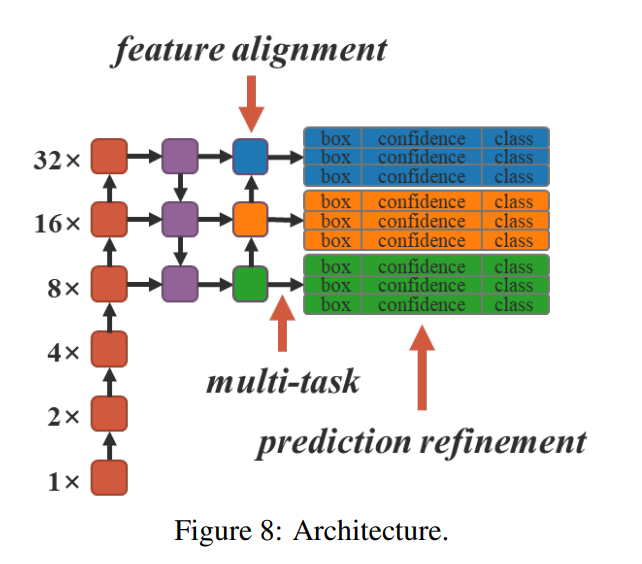
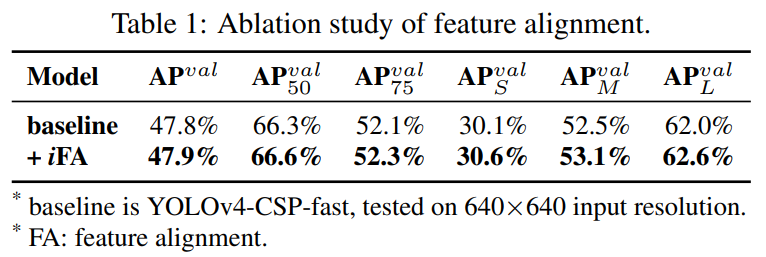
FPNに対する特徴アラインメント
特徴の位置合わせのために各FPNの特徴マップに暗黙の表現を追加します。
対応する実験結果が表1となります。フィーチャスペースの配置に暗黙的な表現を使用した後、APS、APM、およびAPLを含むすべてのパフォーマンスが約0.5%向上したことが確認されました。
物体検出に対する予測強化
予測の改良のために、暗黙の表現が出力レイヤーに追加されました。表2に示すように、ほぼすべての指標スコアが改善されています。
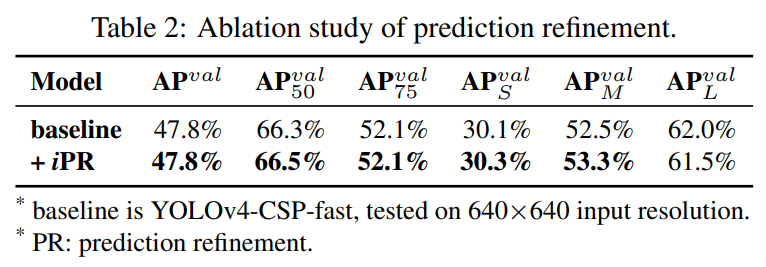
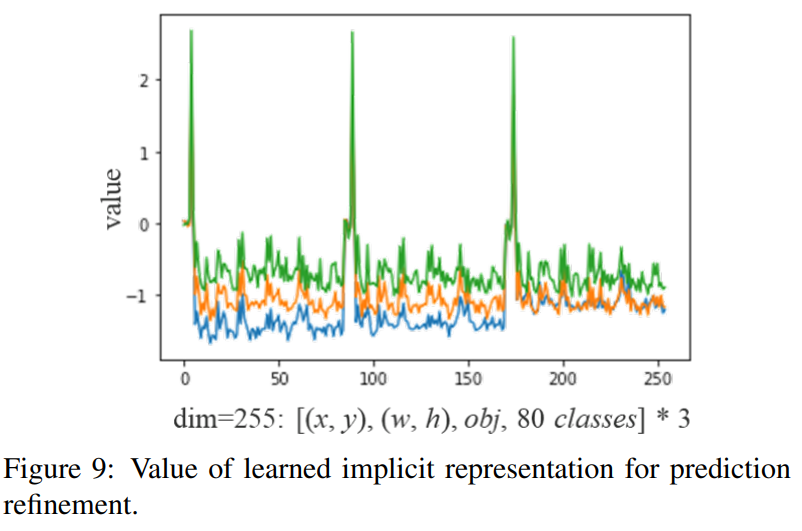
図9は、暗黙的な表現の導入が検出結果にどのように影響するかを示しています。 オブジェクト検出の場合、暗黙の表現に関する事前知識を提供しなくても、提案された学習メカニズムは、各アンカーの(x、y)、(w、h)、(obj)、および(クラス)パターンを自動的に学習できます。
マルチタスクに対する標準表現
同時に多くのタスクで共有できるモデルを学習させる場合、損失関数の共同最適化プロセスを実行する必要があるため、実行プロセス中に複数方向に損失関数が導かれようとしてうまくいかないという状況が発生することが多々小支持ます。
上記の状況では、複数のモデルを個別にトレーニングしてからそれらを統合するよりも、最終的な全体的なパフォーマンスが低下します。この問題を解決するために、マルチタスクの標準表現をトレーニングすることを提案しています。各タスクブランチに「暗黙の表現」を導入することによって表現力を強化することを目指します。
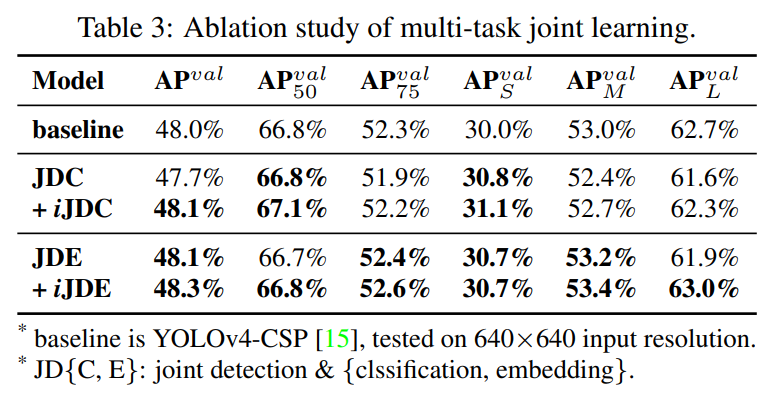
表3に示されているデータのように、暗黙的な表現を導入しないと、マルチタスクトレーニング後に一部のインデックススコアが向上し、一部は低下しました。
ジョイント検出及び分類タスク(JDC)に暗黙の表現を導入した後、+ iJDCに対応するモデルカテゴリでは、全体的なインデックススコアが大幅に増加し、シングルタスク学習モデルのパフォーマンスを上回っています。暗黙の表現があったときと比較して導入されていない場合、中型物体と大型物体でのモデルのパフォーマンスも、それぞれ0.3%と0.7%向上しています。
ジョイント検出及び埋め込みタスク(JDE)の実験では、特徴の位置合わせによって暗示される暗黙の表現の特性のため、インデックススコアを改善する効果がより重要になります。
JDEおよび+iJDEに対応するインデックススコアのうち、+ iJDEのすべてのインデックススコアは、暗黙的な表現を導入しないインデックスを上回っています。その中で、大型物体のAPは1.1%も増加しています。
異なる演算子を利用した暗黙知モデリング
図10に示すように様々な演算子を使用して、明示的表現と暗黙的表現を組み合わせた実験を行いました。

表4は、結果を示しています。
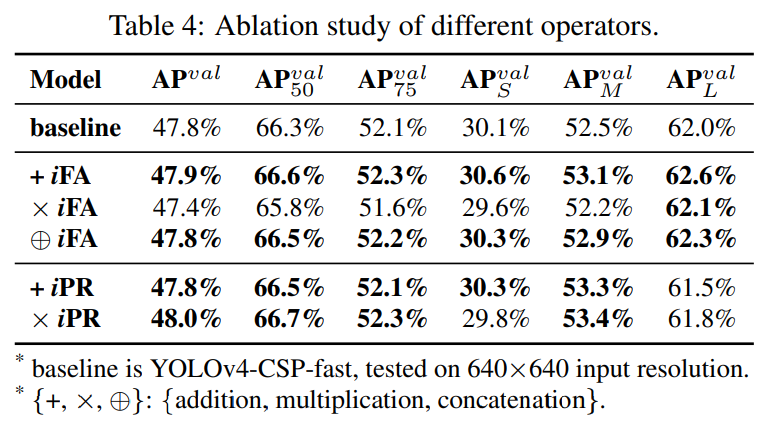
特徴アラインメント実験の暗黙知では、加算と連結の両方でパフォーマンスが向上するのに対し、乗算ではパフォーマンスが低下することがわかります。これは、グローバルシフトとすべての個々のクラスターのスケーリングを処理する必要があるため、その物理的特性に完全に準拠しています。
予測改良実験の暗黙知では、連結の演算子が出力の次元を変更するため、実験で加算演算子と乗算演算子を使用した場合の効果のみを比較しています。この一連の実験では、乗算を適用した場合のパフォーマンスは、加算を適用した場合よりも優れていることがわかりました。原因は、センターシフトは予測を実行するときに加算デコードを使用し、アンカースケールは乗算デコードを使用するためです。中心座標はグリッドで囲まれているため、影響は小さく、人工的に設定されたアンカーはより大きな最適化スペースを所有しているため、改善がより重要になります。
上記の分析に基づいて、他の2つの実験セットを設計しています。最初の実験セットでは、特徴空間をアンカークラスターレベルに分割して乗算と組み合わせます。2番目の実験セットでは、予測の幅と高さに対してのみ乗算の改良を行いました。

表5に示した図から、対応する修正を行った後、さまざまな指標のスコアが包括的に改善されていることがわかります。実験は、明示知と暗黙知を組み合わせる方法を設計するとき、乗数効果を達成するために、最初に結合された層の物理的意味を考慮しなければならないことを示しています。
異なる方法での暗黙知モデリング
ベクトル、ニューラルネットワーク、行列因数分解など、さまざまな方法で暗黙知のモデル化を試みました。
ニューラルネットワークと行列因数分解を使用してモデリングする場合、暗黙的な事前次元のデフォルト値は、明示的な表現次元の2倍となります。
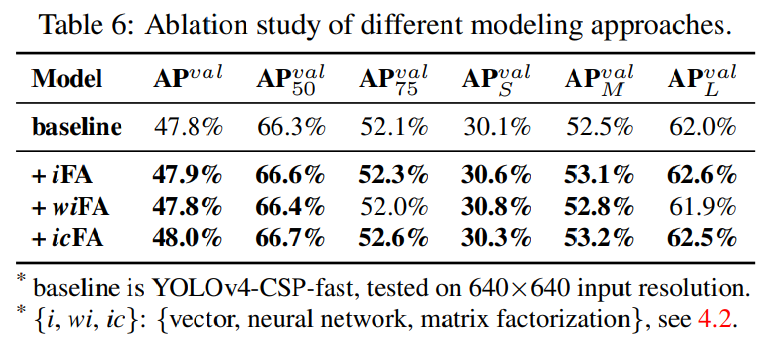
暗黙知をモデル化するためにニューラルネットワークまたは行列因数分解を使用するかどうかにかかわらず、全体的に性能が向上することがわかります。その中で、行列分解モデルを使用することで最良の結果が得られ、AP、AP50、およびAP75のパフォーマンスがそれぞれ0.2%、0.4%、および0.5%向上します。
暗黙知の分析
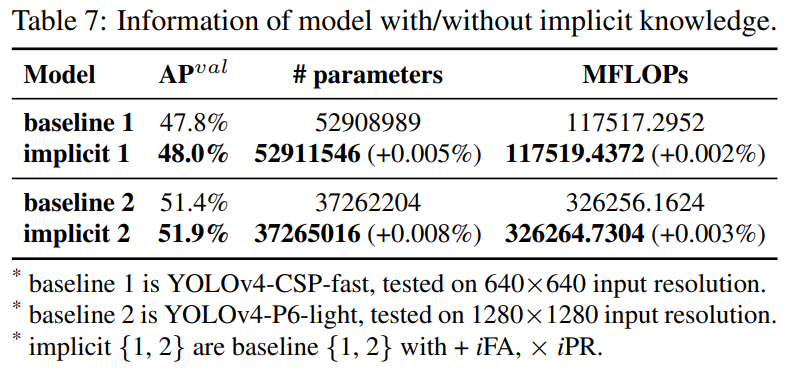
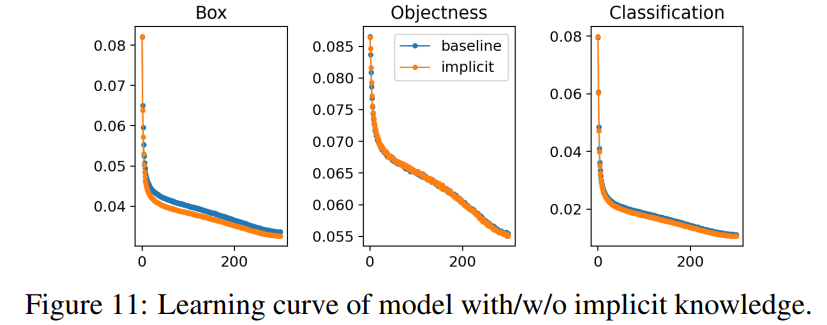
暗黙知の有無にかかわらず、パラメーターの数、FLOP、モデルの学習プロセスを分析し、その結果をそれぞれ表7と図11に示します。
暗黙知の実験セットを使用したモデルでは、パラメーターと計算の量を1万分の1未満しか増加させなかったことがわかりました。そのため、モデルの推論、および学習プロセスも迅速かつ正確に収束できます。

物体検出に対する暗黙知
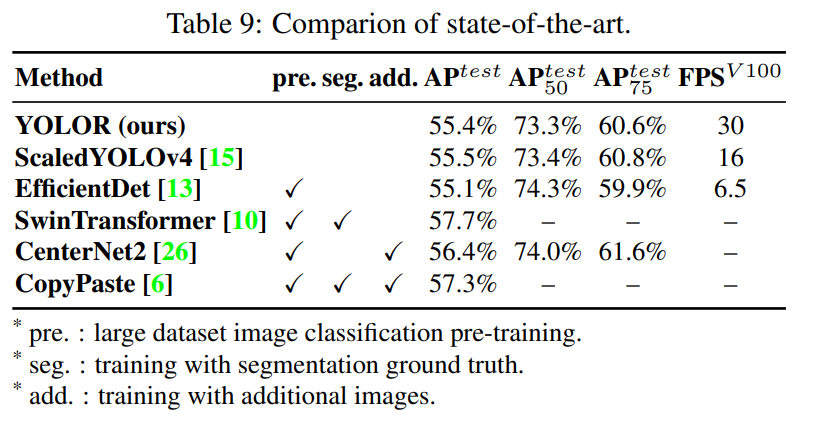
提案された方法の有効性を、オブジェクト検出の最先端の方法と比較することで確認します。 暗黙知を導入する利点を表8に示します。

学習プロセス全体で、スケーリングされたYOLOv4 の学習プロセス(最初に300エポックを学習させ、150エポック分に対して微調整する)に従います。
表9に、最新の方法との比較を示します。 注目に値することの1つは、提案された方法には追加のトレーニングデータと注釈がないことです。暗黙知の統一されたネットワークを導入することで、最先端の手法に匹敵する十分な結果を得ることができます。