本論文は、Yuexin Maらによる視覚中心のBird eye viewに関する初めてのサーベイ論文である「 Vision-centric BEV (Bird eye view) perception 」 に関してまとめています。CV(Computer Vision)中心のBEVの最新の関連手法を提示しています。
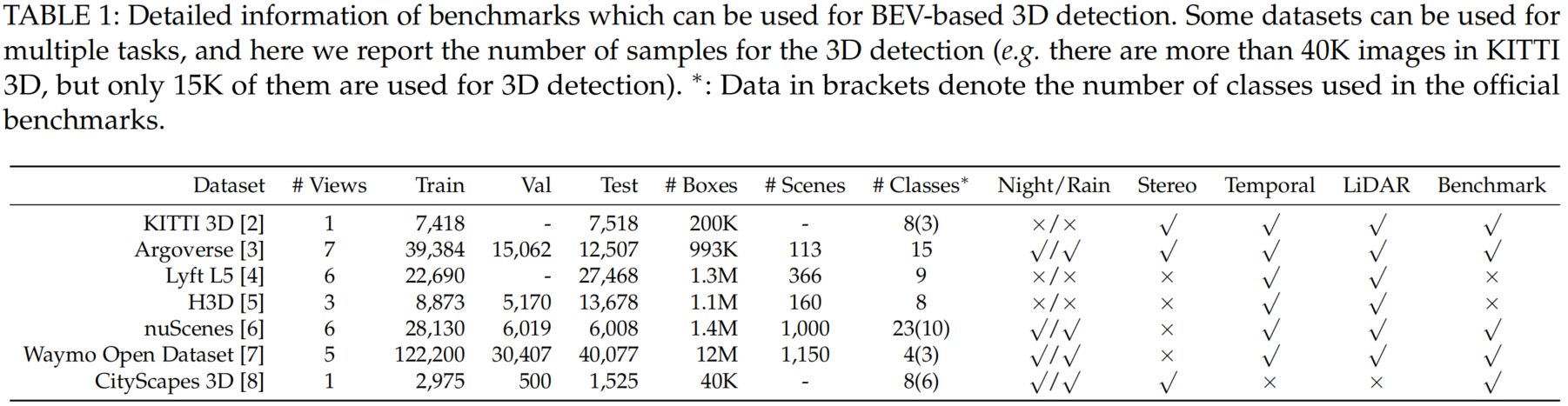
詳細はこちらのスライドを参考下さい。
基本情報
参照URL:https://arxiv.org/abs/2208.02797
イントロダクション
BEV(Bird eye view)により、動的な物体や静的な街並みなど、周囲の情景を正確かつ包括的に把握することができます。BEVは、自律走行車が安全かつ効果的な運転判断を行うために必要不可欠とされています。
近年、BEV(Bird eye view)で行われる3次元知覚が注目されているのには、主に2つの理由があります。
- 1. BEVによる世界の表現、特に交通シナリオは、豊富な意味情報、正確な位置特定、絶対的なスケールを含んでおり、行動予測、運動計画など、多くの下流実世界アプリケーションで直接展開することができる。
- 2. BEVは異なる視点、モダリティ、時系列、エージェントからの情報を融合させる物理的に解釈可能な方法を提供する。
このため、BEVの活用への期待が高まっています。
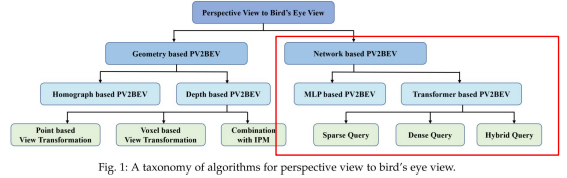
BEVは、ジオメトリベースとネットワークベースの2つに大別されます。
ジオメトリベース
カメラの物理的な原理をフルに活用し、解釈可能な方法でビューを変換する方法です。ホモグラフィ変換などを含みます。
ネットワークベース
MLPやTransfomerのネットワークで推定します。TransformerではBEVクエリを直接構築し、cross attentionメカニズムによってフロントビュー画像上で対応する特徴を検索することによりトップダウン型を採用しています。また、異なる下流タスクに対応するため、疎、密、またはハイブリッドなクエリが提案されています。
本論文の貢献
本論文の貢献は、以下になります。
- 1.本論文は透視図と鳥瞰図間のビュー変換を解決するための最近の進歩をレビューする最初のサーベイ論文であること。
- 2.視覚中心のBEVの最新の関連手法を提示し、コアアイデアと下流の視覚タスクを基に明確に分類していること。また、これらの手法の性能と限界に関する詳細な分析・比較を行っていること。
- 3.マルチタスク学習、BEVとの融合、経験的学習など、BEV知覚手法の拡張を提案し、関連手法の実装と開発を促進していること。
背景
Vision-centric BEV perceptionのタスク定義
Vision-centric BEV perception とは、入力画像列 I ∈ R^N×V×H×W×3が与えられたとき、アルゴリズムがこれらのPV(透視図,Perspective View)入力をBEVに変換する必要があるという考え方です。アルゴリズムは、これらのPV入力をBEV特徴量に変換し、BEVにおける物体の3次元バウンディングボックスや周辺環境の意味マップを検出するような知覚タスクを行う必要があります。ここで、N、V、H、Wはフレーム数とビュー数、入力画像の高さと幅を示しています。
LiDARベースのアプローチと比較して、視覚中心の方法は、画像から豊かな意味を情報を得ることができますが、正確な深度測定が不足しています。この問題に対処するための対処するための統一的な表現を得るために、最近の研究では通常、PVをBEV特徴に変換ビュー変換を採用しています。
3D物体検出
3次元物体検出は、3DVisionのコアタスクの1つです。このタスクは、「画像ベース」、「LiDARベース」、「マルチモダリティベース」に分けることができます。
画像ベース
複数の画像から物体のカテゴリと3次元バウンディングボックスを予測する必要があります。以前の手法は、一般的に透視ビューの特徴から直接予測を行うため、簡単な処理ではありますが、実際には多視点カメラのための複雑な後処理が必要です。また、複数のビューや時間的に連続したフレームからのステレオキューを活用することも困難であることから、この分野が注目され、効率と性能の両面で大きな進歩を遂げています。
LiDARベース
この手法は、3D Visionにおいて大きな成功を収めています。LiDAR が提供する周囲の 3D 環境の正確な測定により、画像ベースの手法よりもはるかに優れた性能を示し、よく研究されてきた経験があります。例えば、ポイントベースの手法とボクセルベースの手法に分類され、ボクセルベースの手法は、実際にはBEV知覚 としてさらに単純化することができます。
マルチモダリティ3D検出
RGB画像は、物体の色や形、質感などの豊富な情報を含んでいますが、正確な深度情報を提供することはできないため、LiDARで補完することができます。また、レーダーは粗い定位信号しか得られませんが、LiDARは物体の動きを感知することができます。これらのセンサーをいかに効果的に活用するかは、3DVisionの長年の課題です。
BEVのセグメンテーション
マップセグメンテーション
BEVに基づくマップセグメンテーションには、MLPに基づく手法とTransformerに基づく手法という二つの研究ラインが存在します。前者では、PONが単眼画像を入力としてマップを推定します。後者のTransformerベースのアプローチでは、Image2Map が画像からのマップ生成をシーケンス-シーケンス変換問題として定式化し、Transformerベースのネットワークを利用してエンドツーエンドでマップ生成を実行します。GitNet は2段階のフレームワークを設計しており、まず透視図においてセグメンテーションを行い、次にTransformerを用いてBEV特徴を処理します。
レーンセグメンテーション
BEVによる地図生成に加え、遠近効果を緩和するために、BEVの車線を検出する様々な手法が提案されています。
3DLaneNet
CNNを活用し、車線の3次元位置をエンドツーエンドで予測する先駆的な手法です。GEN-LaneNetは、まず画像を仮想トップビューに投影し、次に車線位置を回帰する2段階のフレームワークを設計し、凹凸路での車線検出を大幅に向上させることができます。
Persformer
Transformerのようなアーキテクチャを利用し、フロントビューの特徴からより良いBEVの特徴を生成し、2Dと3Dの車線を同時に予測することができます。
Dataset
KITTI、nuScenes、Waymo Open Dataset (WOD) は、BEVベースの3D知覚に最も影響力のある3つのベンチマークです。nuScenesデータセットは、360度の水平FOVをカバーする6台の較正済みカメラによる、Vision centric perceptionのための最も頻繁に使用されるデータセットです。3つのデータセット以外にも、Argoverse、H3D、Lyft L5などのベンチマークもBEVベース知覚に利用することが可能です。
Common Evaluation Metrices
BEV検出のための評価基準を以下にまとめています。(以下3つは、物体検出タスクと同様。)
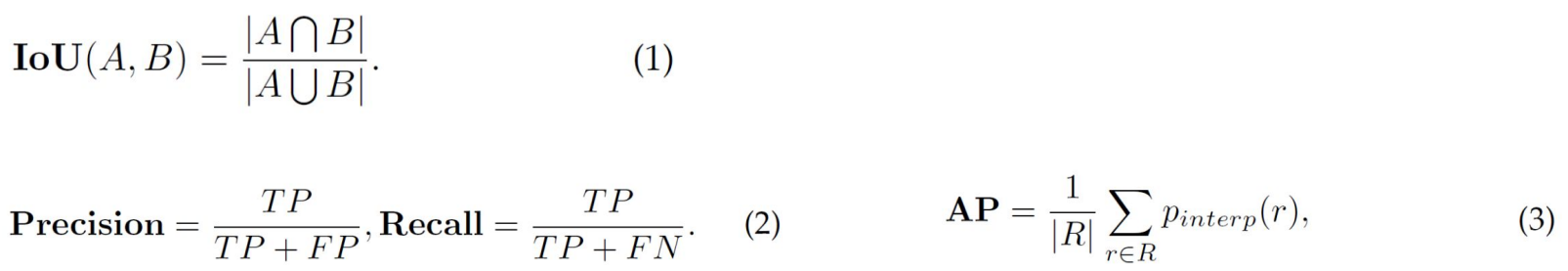
データセット固有の指標
KITTI 3Dの指標

Waymo Open Dataset の指標

nuScenes の指標
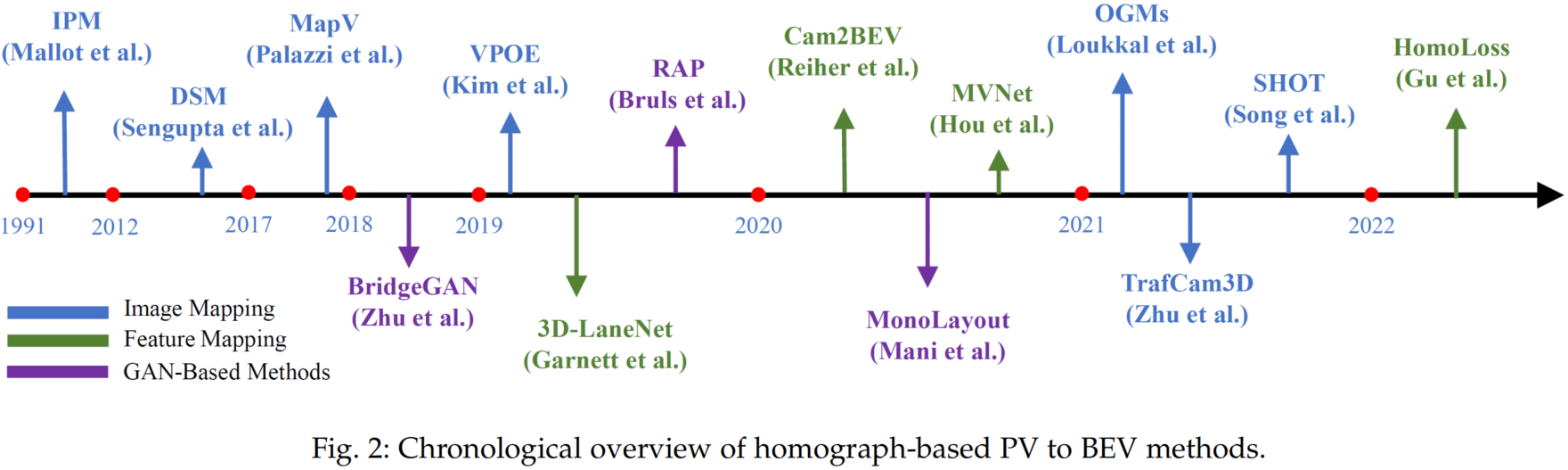
ジオメトリベースPV2BEV
PVからBEVへの変換の従来からの解決策は、幾何学的投影関係を利用することです。この種の手法をジオメトリベースのアプローチと呼んでいます。これまでの研究は、2つのビューの間のギャップをどのように埋めるかによって、ホモグラフベースの方法と深度ベースの手法の2つのグループに分けられます。
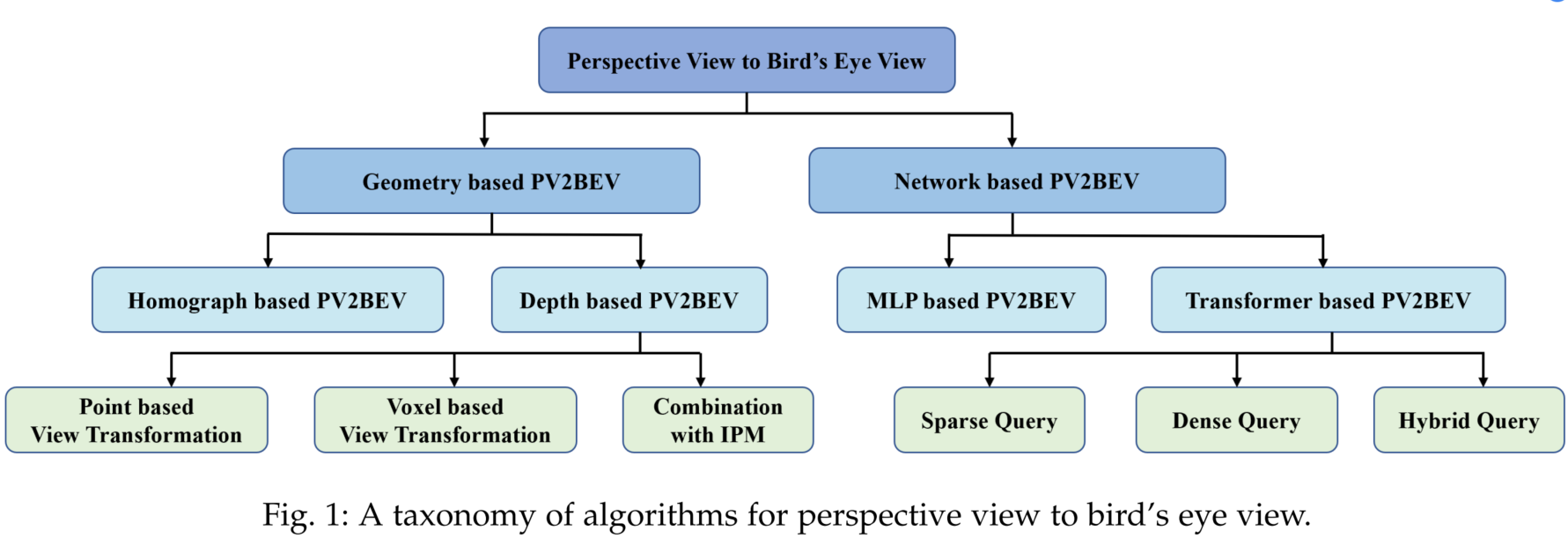
ホモグラフベースBEV 概要
ホモグラフを用いた手法は、透視図と鳥瞰図との間の平坦な地面の物理的なマッピングに依存しており、解釈性が良いとされています。またIPMは、画像投影や特徴量投影の役割を担っており、マッピングは、行列の乗算によって計算されます。PVからBEVへの実変換は非論理的であるため、IPMは問題の一部しか解けないため、PVの全特徴量マップに対する効果的なBEVマッピングはまだ未解決な状態です。
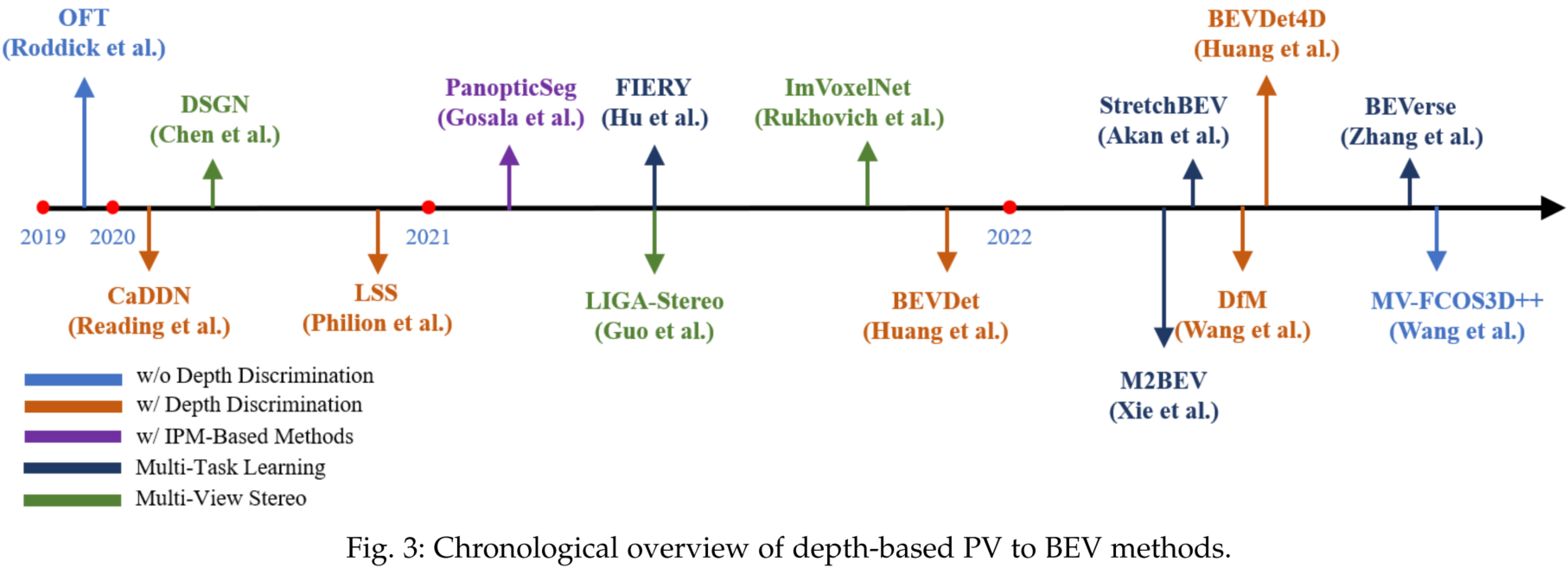
IPMに基づく手法は、すべての点が地上にあることを前提に構築されています。これを避けるためには、2次元の画素や特徴を3次元空間に持ち上げる深度が必要です。このような観点から、PV-BEV変換のための重要な手法として、深度ベースの手法があります。
深度ベースPV2BEV
深度ベースのPV2BEV手法は、3D表現に基づいて構築されます。これらは、ポイントベース手法とボクセルベース手法、IPMベース手法との組み合わせの3つのタイプに分けることができます。
ポイントベースのビュー変換
深度推定を直接利用して、ピクセルを点群に変換し、連続した3次元空間に散布する方式です。この方法は、単眼での深度推定とLiDARによる3D検出を統合します。
Pseudo-LiDARは、まず深度マップを疑似LiDARポイントに変換し、それを最先端のLiDARベースの3D検出器に送り込みます。Pseudo-LiDAR++ は、ステレオ深度推定ネットワークと損失関数で深度精度を向上させます。AM3Dは、擬似点群を補完的なRGB特徴で装飾することを提案しています。
PatchNetは、深度マップと3次元座標の差異を分析し、3次元座標を入力データの追加チャネルとして統合することで、同様の結果を得ることを提案しています。
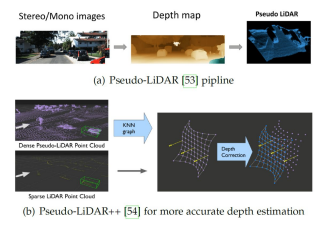
問題点
このパイプラインは通常、2ステージ間の勾配切断のため、学習時や展開時に複雑になることがあります。そのため、E2E Pseudo-LiDAR は、全体をエンドツーエンドで学習できるように、Change-of-Representation (CoR) モジュールを提案しています。しかし、特に大規模な屋外シーンでは、これらの側面においてボクセルベースの方法よりも本質的に劣ることが示されています。
ボクセルベースのビュー変換
ボクセルは3次元空間を離散化し、特徴変換のための規則的な構造を構築することで、3次元シーン理解のためのより効率的な表現を提示します。具体的には、この方式では、一般に、深度ガイダンスを用いて直接対応する3D位置に2D特徴を散布します。
初期の手法は、OFT のように、分布が一様であり、光線に沿ったすべての特徴が同じであると仮定しています。等間隔に配置された 3D 格子上に定義された 3D ボクセル特徴マップを構築し、対応する画像特徴マップを投影した領域上の特徴を蓄積してボクセルを埋めます。
次に、ボクセルの特徴を縦軸に沿って合計することで正投影特徴マップを求め、次に深層畳み込みニューラルネットワークが3次元物体検出のためのBEV特徴を抽出します。
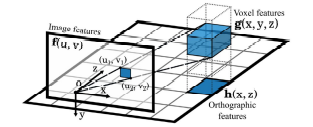
画像特徴マップを 3D 空間へマッピングする仕組み
ボクセルが画像空間内でどのような映るかがわかったところで、画像空間における特徴マップを 3D 空間にマッピングします。中心座標が (x, y, z) のボクセルの特徴マップ g(x, y, z) は、上記で求めたバウンディングボックスに含まれる範囲の特徴マップに対して Average pooling(平均プーリング)をかけることで求めることができます。
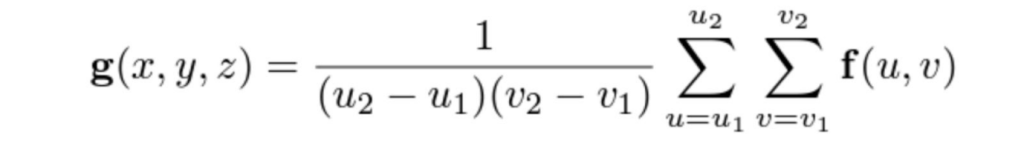
特徴マップのテンソルを繰り返し足し合わせる処理は、計算量増大の原因になってしまいます。そこで、提案手法では Integral images(積分画像)による高速化を図っています。ピクセル (u, v) の Integral map を F(u, v) は、再帰関数の利用により下式のように表すことができます。
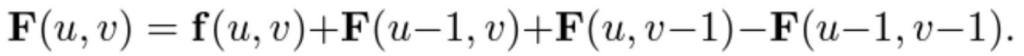
積分特徴マップ F が与えられると、バウンディングボックス座標 (u1,v1) と (u2,v2) で定義される領域に対応する出力特徴 g(x,y,z) は、次式で与えられます。
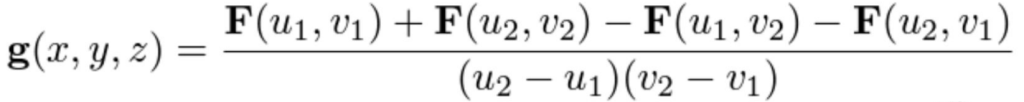
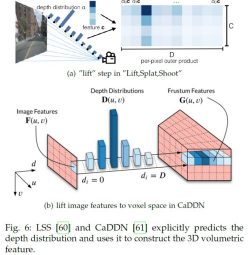
深度監視
予測された深度分布を用いて2次元特徴を持ち上げる(3次元にする)場合、深度分布の精度が重要です。CaDDN は、LiDARの投影点から得られる疎な深度マップを補間し、それを利用して深度分布の予測を監視します。この手法では、この深度監視と、分布予測を促す損失関数が重要であることが示されています。
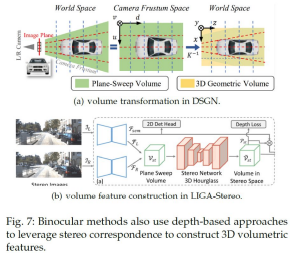
両眼型3D検出の手法であるDSGNやLIGA-Stereoも同様の深度監視に依存しており、スパースなLiDAR深度マップがより有効です。深度ラベルを使用しない他の作品は、疎なインスタンス注釈からそのような3Dローカライゼーションまたは深度情報を学習することしかできず、ネットワーク学習にとってより困難になります。
IPMベース手法との組み合わせ
IPMに基づく手法は、平坦な地面のシナリオでうまく機能し、学習するパラメータがごくわずかでも効率的に実行されます。明示的な深度予測と監視に依存しない方法は、垂直方向に沿った特徴集約に適しています。PanopticSeg は、両方の利点を利用し、パノプティックセグメンテーションのための高密度変換モジュールを提案しました。このモジュールは、IPMに続いてエラー修正を用いた平面変換器により平面BEV特徴を生成し、体積格子を用いて中間3D空間をモデル化し、これをフラット化して垂直BEV特徴を生成します。
ステレオマッチングのためのマルチビュー統合
単眼での深度推定に加え、ステレオマッチングにより、カメラのみでの知覚においてより正確な深度情報を予測することができます。その中でも、両眼設定は最も一般的でよく研究されているものであり、適切な多視点設定を確立するために、大きな重複領域と小さな水平オフセットのみを特徴としています。
これに対し、2眼の場合の深度推定には、より重要なメリットがあります。DSGN や LIGA-Stereo などの最近の両眼法では,ステレオマッチングと深度推定に平面スイープ表現を用いることが一般的です。そして、平面スイープ特徴量からボクセルと BEV 特徴をサンプリングし、その上で 3 次元検出を行います。また、ImVoxelNetのようなマルチビュー設定をターゲットとする他の方法は、隣接する領域間で重複領域も大きくなる室内シーンにおいて、このようなボクセルベースの定式化の有効性を示しています。そして、連続するフレームについても、時間的に隣接する2枚の画像も条件を満たすことができます。
ジオメトリベースPV2BEV / まとめ
深度ベースのビュー変換手法は、通常、明示的な3D表現、量子化されたボクセル、または連続した3D空間に散在する点群に基づいて構築されます。ポイントベース方式は、深度予測を擬似LiDAR表現に変換し、カスタムネットワークを用いて3D検出を行います。ボクセルベースの手法は、一様な深度ベクトルまたは明示的に予測された深度分布を使用して、2D特徴を3Dボクセル空間に持ち上げ、そこでBEVベースの知覚を実行します。
しかし、一般化できるエンドツーエンドの学習が困難なため、モデルの複雑さと性能の低さに悩まされています。 最近の手法では、計算の効率性と柔軟性から、ボクセルベースの手法が注目されています。このボクセルベースの手法は、カメラのみを用いた手法において、様々なタスクで広く採用されています。 深度監視は、正確な深度分布が透視図の特徴を鳥瞰図に変換するときに不可欠な手がかりを提供することができるので、このような深度ベースの手法にとって重要です。 また、DfM、BEVDet4D、MVFCOS3D++で分析したように、時間モデリングにおける手法の潜在的利点を探ることは有望な方向性となっています。
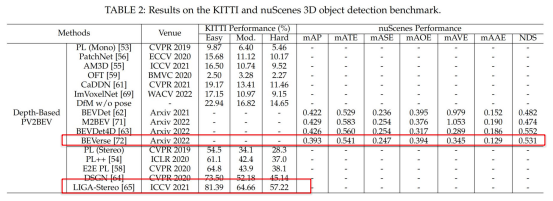
深度ベース手法の比較
ネットワークベースのPV2BEV
MLPベースとTransformerベースに分かれます。また、Transformerベースは、スパースクエリとデンスクエリ、ハイブリッドクエリに分かれます。スパースとデンスの違いは、各クエリに3次元空間またはBEV空間における空間位置があらかじめ割り当てられているかの違いとなっています。
MLPベースPV2BEV
MLPに基づく手法は、透視図から鳥瞰図への変換をモデル化するための一般的なマッピング関数としてMLPを利用します。MLP は理論的には普遍的な近似関数であるが、深度情報の欠如やオクルージョンなどのために、ビュー変換を推論することはまだ困難です。さらに、マルチビュー画像は通常、個別に変換され、レイトフュージョン方式で融合されるため、MLPベースの手法では活用することができません。
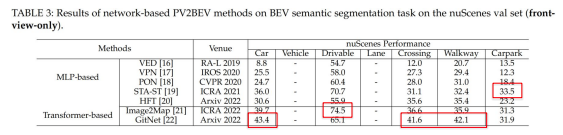
ネットワークベースのPV-to-BEV手法のセマンティックセグメンテーション精度
TransformerベースPV2BEV
Transformerを用いたBEVのMLPベースとTransformerベースのテンソルマッピングには、3つの大きな違いがあります。
- 1.重み付け行列は推論中に固定されるため、MLPで学習したマッピングはデータに依存しません。対照的に、Transformerにおけるcross attentionは、重み付け行列が入力データに依存するデータ依存性を持ちます。このデータ依存性により、Transformerはより表現力が豊かになる。一方で学習は困難になります。
- 2.cross attentionは順列不変です。すなわち、Transformer は入力の順序を区別するために位置エンコーディングを必要とするが、MLPは順列に敏感になります。
- 3.MLPベースの手法で行われるように、ビュー変換を前方から処理するのではなく、Transformerベースの手法は、クエリを構築し、Attentionメカニズムを通して対応する画像特徴を検索することにより、トップダウン型を採用しています。
スパースクエリベースの手法
クエリ埋め込みにより、画像特徴の密な変換を明示的に行うことなく、ネットワークが直接スパースな知覚結果を生成することが可能になっています。この設計は、3次元物体検出のような物体中心の知覚タスクで可能ですが、セグメンテーションのような密な知覚タスクに拡張することは容易ではありません。
STSU
単一の画像からBEV空間におけるローカル道路網を表す有向グラフを抽出するために、スパースクエリベースのフレームワークに従います。この方法は、センターラインとダイナミックオブジェクトの2組のスパースクエリを用いることで、3Dオブジェクトも共同で検出することができ、オブジェクトとセンターラインの間の依存関係がネットワークによって利用されることが可能です。
TopologyPL
最小サイクルを保存することにより道路網のトポロジーを考慮し、STSUを改良したものです。
DETR3D
DETR3D はSTSUと同様のパラダイムを提案しますが、マルチカメラ入力の3D検出に焦点を当て、cross attentionを形状に基づく特徴サンプリング処理に置き換えます。まず、学習可能なスパースクエリから3D参照点を予測し、次にキャリブレーション行列を使用して参照点を画像平面に投影し、最後にエンドツーエンド3Dバウンディングボックス予測のために対応するマルチビューマルチスケール画像特徴をサンプリングします。
PETR
DETR3Dの複雑な特徴サンプリング手順を軽減するために、PETR はカメラパラメータから得られる3D位置埋め込みを2Dマルチビュー特徴にエンコードし、スパースクエリが直接素のcross attentionにおける位置認識画像特徴と対話できるようにして、よりシンプルなフレームワークを実現しています。
PETRv2
3次元位置埋め込みを時間領域へ拡張することにより、時間情報を利用するものです。DETR3Dにおける不十分な特徴集約に対処し、重複領域における知覚結果を改善するために、Graph-DETR3D は、グラフ構造学習により各オブジェクトクエリーに対して様々な画像情報を集約することでオブジェクト表現を強化します。同様に、ORA3D もDETR3Dのオーバーラップ領域における性能の向上に焦点を合わせています。これは、ステレオ視差監視と敵対的学習により、オーバーラップ領域の表現学習を正則化するものです。
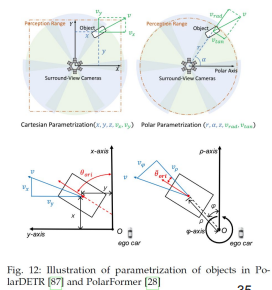
PolarDETR
3D検出のための極座標化を提案し、バウンディングボックスのパラメータ化、ネットワーク予測、損失計算をすべて極座標系で再定式化することで、誘導バイアスとしてサラウンドビューカメラのビュー対称性を利用して最適化と性能アップを図ります。また、DETR3Dにおける文脈情報の不足の問題を緩和するために、投影された参照点の特徴以外の文脈の特徴を利用します。
SRCN3D
別の2D検出フレームワークであるSparseRCNNに基づいて、疎な提案ベースのマルチカメラ3D検出方法を設計し、各提案は、学習可能な3D境界ボックスとインスタンス特性をエンコードする学習可能な特徴ベクトルを含んでいます。Cross attentionに基づく特徴量相互作用を置き換えるために、提案ボックスから抽出されたRoI特徴量で提案特徴量を更新するスパース特徴量サンプリングモジュールと動的インスタンス相互作用ヘッドが提案されます。
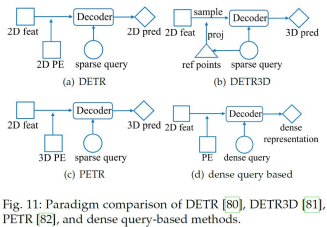
DETR、DETR3D、PETR、Dense query base 手法のパラダイム比較。
DETR
Transformerを用いた2Dの物体検出を行います。当サイトで詳細を紹介していますので参考ください。
Transformer を物体検出に採用!話題のDETRを詳細解説!
https://deepsquare.jp/2020/07/detr/
DETR3D
学習可能なスパースクエリから3D参照点を予測し、次にキャリブレーション行列を使用して参照点を画像平面に投影し、最後にエンドツーエンド3Dバウンディングボックス予測のために対応するマルチビューマルチスケール画像特徴をサンプリングします。
PETR
DETR3Dの複雑な特徴サンプリング手順を軽減するために、PETR はカメラパラメータから得られる3D位置埋め込みを2Dマルチビュー特徴にエンコードし、スパースクエリが直接素のcross attentionにおける位置認識画像特徴と対話できるようにして、よりシンプルなフレームワークを実現しています。
デンスクエリベースの手法
デンスクエリベースの手法では、各クエリは3次元空間またはBEV空間における空間位置があらかじめ割り当てられています。クエリの数はラスタライズ空間の空間解像度によって決定され、通常、スパースクエリベースの手法におけるクエリの数よりも大きくなります。密なBEV表現は、3D検出、セグメンテーション、および動き予測などの複数の下流タスクのための密なクエリと画像特徴との間の相互作用を通じて実現することができます。
Tesla
まず、位置エンコーディングとコンテキストサマリを用いて、BEV空間における密なBEVクエリを生成します。次に、クエリとマルチビュー画像特徴との間のcross attention により、ビュー変換を実施する。BEVクエリと画像特徴間の素のcross attentionは、カメラパラメータを考慮することなく実行されます。
CVT
cross attentionの幾何学的推論を容易にするために、画像特徴にカメラの固有および外部キャリブレーションから得られる位置埋め込みを装備し、cross attention モジュールを提案します。各変換デコーダ層におけるAttentionの演算は、膨大なクエリとキーエレメント数で大きなメモリ複雑性を必要とするため、通常、メモリ消費を抑えるために画像解像度やBEV解像度が制限され、これによっては、多くの場合、モデルのスケーラビリティを阻害する可能性があります。
高密度なクエリベースの手法の問題点を解決するために、多くの取り組みがなされています。
例)Deformable attention は、deformable convolution の疎な空間サンプリングとAttentionの関係モデリング能力を組み合わせ、疎な位置にのみ注意を向けることにより、Attentionのメモリ消費を著しく減少させることができます。
BEVFormer
BEV平面上に位置する密なクエリとマルチビュー画像特徴との間の相互作用のために、変形可能なAttentionを採用します。さらに、履歴BEVクエリのセットを設計し、クエリと履歴クエリ間の変形可能なAttentionを通じて、時間的な手がかりを利用することができます。
Ego3RT
高密度なクエリを偏光BEVグリッド上に配置し、クエリとマルチビュー画像特徴を相互作用させるために変形可能なAttentionに依存しています。偏光BEV特徴はグリッドサンプリングにより直交特徴に変換され、下流タスクに利用されます。
BEVSegFormer
クエリの特徴から直接参照点を予測するのではなく、カメラパラメータとクエリの事前定義された3次元位置を利用して、変形可能なAttentionで特徴サンプリングのための2次元参照点を計算しています。
PersFormer
画像上の参照点を計算するためにIPMに依存します。このような設計により、ネットワークはガイダンスのための幾何学的事前分布を持つ画像上の適切な領域をより良く特定することができるが、これはキャリブレーション行列に対してより敏感である危険性があります。
カメラキャリブレーションが固定されている場合、BEVクエリからピクセル位置への固定マッピングとなる。この演算子は、固定サンプリングオフセットと類似性に基づくAttentionの重みを持つ変形可能なattentionと見なすことができる。そして、BEVから2次元へのルックアップテーブルによるインデックス付け手法を提案し、高速な推論を行う。
CoBEVT
変形可能なAttentionを採用する代わりに、fused axial attention(FAX)と呼ばれる新しいAttentionの変形を提案し、計算量を減らし、高レベルの文脈情報と領域特徴の両方を取得できます。具体的には、まず特徴マップを3次元の非重複ウィンドウに分割し、各ローカルウィンドウ内のAttentionによるローカルAttentionと、異なるウィンドウ間のAttentionによるGlobal Attentionを行います。メモリ消費量を削減する有力な方法として、3次元幾何学的な制約を用いたCross Attentionに基づくインタラクションの簡略化があります。
Image2Map
まず単眼画像における垂直走査線と、カメラ中心から始まるBEV平面上の光線との間に1-1の関係を仮定することにより、単眼BEVセグメンテーションのためのフレームワークを提案します。そして、ビューの変換は、1次元の配列間変換問題の集合として定式化され、画像中の垂直走査線を1本ずつ変換エンコーダに渡してメモリ表現を作成し、BEV極線に復号化します。
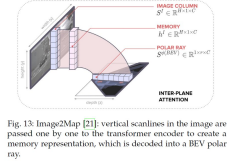
Polarの距離次元における制約のないオブジェクトのスケール変動を扱うために、マルチスケールPolar表現学習を提案しています。PolarDETRと同様に、バウンディングボックス予測は、極座標系で行われます。
LaRa
まずマルチビュー画像特徴を潜在空間にエンコードし、次にcross attenitonモジュールで潜在表現を照会してBEV特徴を得ることで、計算領域を制御しています。コンパクトな潜在空間は、入力サイズや出力解像度から切り離されているため、精密な制御が可能です。
さらに、視覚的特徴を補強し、特徴と潜在ベクトル間のcross attentionを誘導するために、校正行列から導かれる光線ベースの位置埋め込みが提案されています。
ハイブリッドクエリベースの手法
スパースクエリに基づく手法は、オブジェクト中心のタスクには適しています、明示的な密なBEV表現を導出できないため、BEVセグメンテーションのような密な知覚タスクには適しません。そこで、PETRv2ではハイブリッドクエリを設計し、スパースオブジェクトクエリに加えて、デンスセグメンテーションクエリを提案している。各セグメンテーションクエリは特定のパッチ(16×16)のセグメンテーションを担当します。
スパースクエリ vs デンスクエリ
スパースクエリに基づく手法は、物体検出タスクにおいて有望な結果を得るが、その3次元表現はエゴ座標フレームに対する幾何学的構造を持たないため、地図分割のような密な予測タスクを行うことは困難です。これに対し、空間分布を明示したデンスクエリは、BEV空間に対して密で統一的な表現を提供し、異なる知覚ヘッドを容易に採用できる可能性があります。しかし、多数のBEVクエリの下では膨大な計算コストがかかるため、高解像度の特徴マップを実現するためには、Attentionメカニズムをより効率的にすることが必要です。
効率的なTransformerアーキテクチャは、過去数年の間に集中的に関心を集めてきました。しかし、これらの研究は、キーとクエリが同じ要素集合から得られるSelf Attentionに焦点を当てており、2つの集合から得られるcross attentionにおける有効性は、まだ十分に検討されていません。
幾何学的な手がかり
概念的には、TransformerベースのPV-to-BEV手法は、Attentionメカニズムのみに依存してビュー変換を行うことができ、必ずしも幾何学的処理は必要ではありません。しかし、順列不変の性質により、Transformerは画像領域とBEVピクセル間の空間的関係を認識しないため、ネットワークの収束が遅く、データ量が多くありません。現在では、3次元幾何学的な制約を利用して、高速な収束やデータ効率を実現しようとする手法が増加しています。
キャリブレーションマトリックス
クエリの3次元座標が与えられた場合、カメラキャリブレーション行列はBEV空間から画像平面へのマッピングを定義し、視覚特徴とクエリを相互作用させるための良い手掛かりとなります。キャリブレーション行列は、transformerに基づくPV-to-BEV法のほとんどで様々な方法で活用されています。カメラ投影行列に依存して、特徴サンプリングのための2次元参照点を計算し、ネットワークが画像上の適切な領域に注意を向けます。
キャリブレーション行列を利用ますもう一つの方法は、カメラジオメトリに基づいて各画像垂直走査線をBEVに予め割り当て、global cross attentionを列方向Attentionに簡略化することです。この方法もまた、計算を大幅に節約することができます。
深度情報
TransformerベースのPV-to-BEV手法は、ビュー変換のために必ずしもピクセル単位の深度を必要としないませんが、深度情報はTransformerのジオメトリ的推論にとって依然として重要です。nuScenesオブジェクト検出ベンチマークにおいて、ほとんどのTransformerベースの手法は深度事前学習の恩恵を受け、クエリと画像特徴間の関連付けを確立するために有用な深度を考慮した2D特徴を提供します。深度予測は、投影されたLiDARポイントまたはオブジェクト単位の深度ラベルから、正解の深度を得ることができる Vision centric3D検出を支援するために、共同で最適化することができます。
MonoDTR と MonoDETR は、深度を考慮した特徴を生成し、Transformerの位置エンコーディングのためにピクセルごとの深度を予測する別のモジュールを設計しています。MonoDTRは、アンカーベースの検出ヘッドのためにコンテキスト特徴と深度特徴を統合するためにTransformerを使用し、MonoDETRは、オブジェクトクエリを深度特徴と相互作用させます。そして、深度 Cross Attention を備えたTransformerデコーダを提案することによって、2D画像から直接3D予測をデコードするために深度を考慮したようにTransformerを修正します。
ネットワークベースのPV2BEV / まとめ
Transformerに基づく視点投影は、ますます人気が高まっています。畳み込みバックボーンを置き換える特徴抽出器や、アンカーベース、アンカーフリーヘッドを置き換える検出ヘッドとしての役割も果たすことが可能です。スパースクエリベースの手法は、BEV空間を明示的に表現できないため、密な知覚タスク(道路セグメンテーションなど)を考慮する場合には、通常、デンスクエリが採用されます。
深度ベースのビュー変換手法で観察されるように、時間情報もまた、Transformerベースの手法にとって重要です。時間的統合を用いた手法は一般的にmAPとmAVEにおいてシングルフレーム手法を大きく上回ります。各カメラの知覚範囲は鋭角軸を持つため、垂直軸に基づく直交座標を非直交軸に基づく極座標に置き換えることが提案されており、さらなる研究のための興味深い方向性となると考えられます。
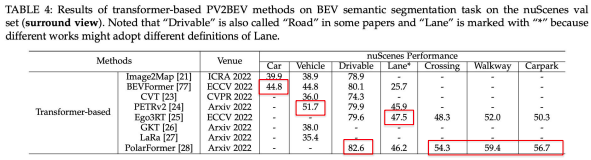
nuScenesのセグメンテーションタスクに対するTransformerベースのPV-to-BEV手法の結果
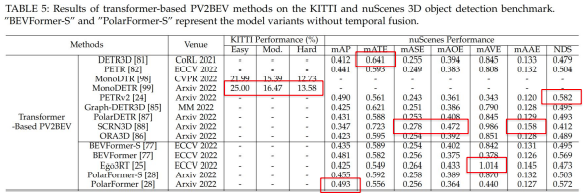
KITTI と nuScenes の3D物体検出のTranformerベースのPV-to-BEV手法の結果
拡張
BEV下でのマルチタスク学習
BEV 表現は、物体検出、地図分割、予測、運動計画など、多くの下流タスクに役立ちます。バックボーンネットワークを共有することで、計算コストを大幅に削減し、効率を向上させることができます。
FIERY
マルチカメラ映像からの時空間BEV表現を用いて、知覚と予測を一つのネットワークに統合するフレームワークを最初に提案しました。
BEVerse
将来の状態を生成するために、各タイムスタンプと残差の推定を行います。BEVerse は、メモリ消費を抑えるために、将来の状態を効率的に生成する反復フローを設計し、3D検出、Semantic Mapの再構成、および動き予測のタスクを共同で行っています。
BEVFormer
まず密なBEVクエリによりマルチビュー画像をBEV平面上に投影します。次にエンドツーエンドの3Dオブジェクト検出とマップセグメンテーションのために、共有BEV特徴マップ上で変形可能DETR とマスクデコーダ などの異なるタスク固有のヘッドを採用します。
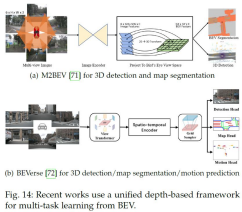
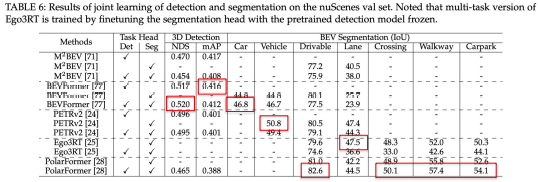
3Dオブジェクト検出とBEVセグメンテーションの共同学習は、通常、改善をもたらさないことが分かっています。異なる知覚タスク間の依存関係を調査し、共同改善を達成するためには、BEV表現は、マルチセンサー、マルチフレーム、マルチエージェントの融合に便利な方法を提供し、包括的な情報を活用することで、自動運転における知覚に大きく役立ちます。
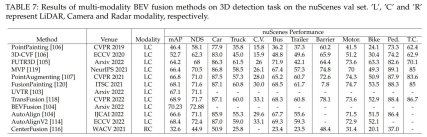
マルチモダリティ・フュージョン
カメラ、LiDAR、レーダーの3種類のセンサーメリットとデメリット

融合の対象
画像と点群の融合は、データレベルの融合と特徴レベルの融合 に分類することができます。データレベルの融合は、キャリブレーション行列を用いて、画素の特徴を点に結びつけます。特徴レベルの融合は、PVの画像特徴と3DやBEVの点群特徴を抽出し、2種類の高次元特徴を直接融合させます。
3つの融合方法
- 1.深度誘導に依存し、3次元空間での融合を操作します。
- 2.融合段階で画像の高密度な意味情報と空間形状情報を完全に保持し、推論を高速化するために効率的なBEVプーリング操作を提案します。
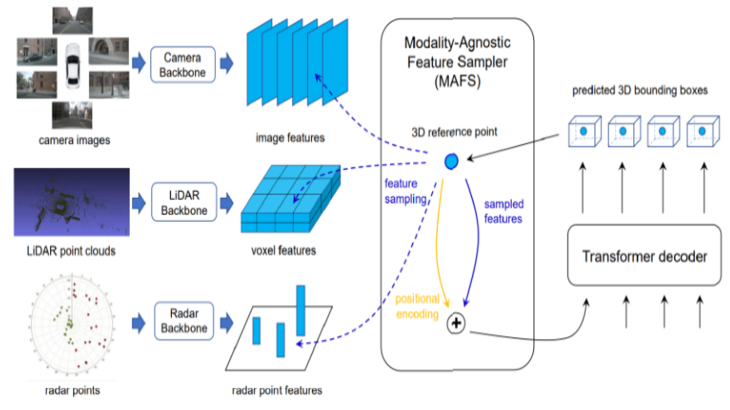
- 3.センサーフュージョンによる3D物体検出のために、クエリベースのモダリティに依存しない特徴サンプラーとTransformerデコーダを採用します。
UVTR
予測された深度スコアと幾何学的制約に従って、画像平面から特徴をサンプリングしてボクセル空間を構築します。AutoAlign は、明示的なカメラ投影なしに、ピクセルと3Dボクセル間の意味的整合性を適応的に整列し、自己教師付き学習によりクロスモーダル特徴相互作用を誘導します。これは、AutoAlignにおけるグローバルワイズアテンションとは異なるものです。
AutoAlignV2
クロスモーダル特徴の自動アライメントをガイドするために決定論的投影行列を使用し、モダリティ間のスパースサンプリングを実装しています。そして、各ボクセルについて、画像特徴と関連する点群特徴の関係を簡単に確立することができます。また、3次元空間での融合処理も行います。
Frustum PointNets / CenterFusion
検出された2Dオブジェクトの画像特徴を対応する3D位置に変換し、それぞれLiDAR検出とレーダー検出と融合するために、フラスタム投影を利用します。2番目のカテゴリの手法は、マルチモーダル入力から抽出されたBEV特徴量に対して融合処理を行うものです。
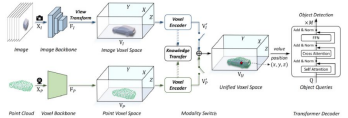
EV-Fusion
融合段階で画像の高密度な意味情報と空間形状情報を完全に保持し、推論を高速化するために効率的なBEVプーリング操作を提案しています。
RRF
投影とバイリニアサンプリングにより画像特徴の3次元ボリュームを定義し、ラスタライズされたRadar BEV画像を連結し、最終的にBEV融合特徴マップを得るために垂直次元を減少させます。
FISHINGNet
カメラ、LiDAR、Radarの特徴をそれぞれ単一の、共通の、トップダウンの意味的グリッド表現に変換し、これらの特徴を集約してBEVの意味的グリッド予測に利用する。第3のBEV融合手法は、3次元参照点をクエリーとして初期化し、利用可能なすべてのモダリティから特徴を抽出し、融合演算を行うことで3次元検出タスクをターゲットとするものです。
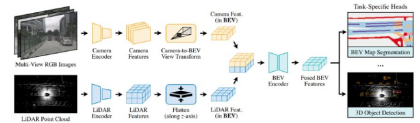
FUTR3D
センサーフュージョンによる3D物体検出のために、クエリベースのモダリティに依存しない特徴サンプルとTransformerデコーダを採用しています。
TransFusion
標準的な3Dと2Dのバックボーンを使用して、LiDAR BEV特徴マップと画像特徴マップを抽出し、クエリの初期化には前者(LiDAR BEV特徴マップ)に依存します。次に、垂直方向に沿って画像特徴を凝縮し、cross attentionを使ってBEV平面上に特徴を投影し、LiDAR BEV特徴と融合させます。
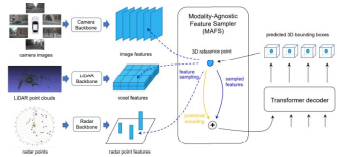
時間軸の融合
時間融合も以下の理由により、ロバストで信頼性の高いシステムにとって重要な要素です。
- 1.連続した観測データを蓄積することで、カメラの視野依存性に起因する自己閉塞や外部閉塞の影響を緩和し、閉塞の激しい物体を検出して信頼性の高い道路地図を生成するのに役立ちます。
- 2.時間的手がかりは、速度、加速度、ステアリングなどの物体の時間的属性を推定するために必要であり、カテゴリ分類や運動予測に有益です。
- 3.単一画像からの深度推定は当然ながら非定型で困難であるが、連続画像によって形成されるステレオ幾何学は、絶対深度推定に重要な指針となり、よく研究された理論的基礎を提供します。
連続した画像フレームに存在する時間情報の利点を考慮し、多くの研究 は、生の入力を連結し、画像から抽出した特徴を連結し、あるいはRNNやTransformerを用いて映像理解を行うが、3次元知覚に対してこれらのステップを取ることはほとんどありません。これは、自車両の移動に伴ってカメラの姿勢が変化するため、連続した透視図表現が厳密な物理的対応関係を持たないためです。このため、PVの時間的特徴を直接融合しても、3次元位置の正確な把握には限界があります。
BEV表現は単語座標への変換が容易で、連続したビジョンセントリックデータを物理的に融合するための橋渡し役として機能します。
BEVDet4D
まず、エゴモーションに基づいて、以前のフレームから現在の時間にBEV特徴マップをワープして、同じ座標系に特徴を置きます。次に、チャンネル次元に沿って整列した特徴マップを連結して検出ヘッドに供給します。しかし、移動する物体は、異なるタイムスタンプで異なるグリッド位置を持つことができるため、同じ物理的位置を持つ異なる時刻のBEV特徴は、同じ物体に属さないかもしれません。
BEVFormer
異なる時刻の同じオブジェクトの関連付けをより良く構築するために、現在のBEV特徴をクエリとして、以前のBEV特徴をキーと値として、self-attention層を介して特徴間の時間的なつながりをモデル化するものです。
PETRv2
BEV特徴マップをラッピングする代わりに、パースペクティブビューと3次元座標マップに対して直接ラッピング処理を行います。まず、前フレームの3次元座標をエゴモーションに基づいて現在時刻に変換し、前フレームの位置符号化を生成します。次に、2つのフレームの2D画像特徴と3D座標は、Transformerデコーダのために一緒に連結され、ここで、疎なオブジェクトクエリは、時間情報を得るために現在と以前の特徴の両方と相互作用することができます。
UniFormer
以前のフレームからのPV特徴を統一された仮想ビューに変換し、cross attentionを用いて過去と現在のすべての特徴を融合し統合するものです。
DfM
深度推定における時間的手がかりの重要性を理論的に分析し、より早い段階から時間的手がかりを利用することで、より良い深度推定によるPV2BEV変換の促進を選択します。単一の画像からの単眼的理解に頼るのではなく、時間的に隣接する画像からのステレオ幾何学的手がかりを統合します。また、ステレオ推定では対応できないケースに対応するため、単眼推定とステレオ推定のバランスを適応的にとる単眼補正手法を提案します。正確な深度推定に基づき、2次元画像の特徴を3次元空間に持ち上げ、そこに存在する3次元物体を検出します。
ステレオ推定では対応できない場合、単眼推定とステレオ推定を適応的にバランスさせる単眼補正を提案します。DfMは、正確な深度推定に基づき、2次元画像の特徴を3次元空間に持ち上げ、そこに存在する3次元物体を検出します。
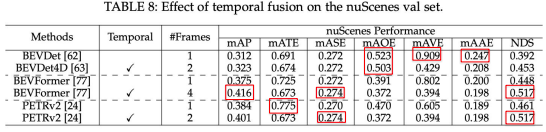
下表に示すように、空間のみの3次元空間から空間-時間4次元空間にモデルを持ち上げると、特に速度と姿勢の予測において、全体の検出性能が大幅に改善されます。しかし、ほとんどの時間モデルは、最大4つ前のフレームしか利用せず、長距離の履歴情報はほとんど無視されます。例えば、BEVFormerの性能はフレーム数が4より大きくなると横ばいになり始める。これは長距離の情報がうまく利用されていないことを意味しています。
マルチエージェントフュージョン
最近の文献では、シングルエージェントのシステムがほとんどであり、完全な交通シーンにおけるオクルージョンの処理と不鮮明な物体の検出が困難です。しかし、Vehicle-to-Vehicle (V2V)通信技術の発展により,近隣の自律走行車両間でセンサデータをブロードキャストし、同じシーンの複数の視点を提供することにより、この問題を克服することが可能になりました。
マルチエージェントデータからカメラ特徴を融合するために、まず、自身の姿勢と送信者の姿勢に基づいて他のエージェントからのBEV特徴を幾何学的に歪め、fused axial attention 機構を用いて、複数のエージェントから受け取ったBEV特徴の情報をTransformerにより融合させる方法が提案されています。しかし、マルチエージェントを含む利用可能な実世界データセットがないため、提案フレームワークはシミュレーションデータセット上でのみ検証されており、実世界での汎化能力はまだ不明であり、さらなる検討が必要です。
経験的ノウハウ
知覚からの解像度
透視図から鳥瞰図への視点変換を行うため、これら2つの視点に対する知覚範囲の設定は、性能と効率とのトレードオフとなります。近年、グラフィックスカードの計算能力の飛躍的な向上に伴い、透視図画像の解像度や鳥瞰図グリッドサイズは大幅に増加しています。透視画像解像度の増加は、性能を大幅に向上させることができるが、推論速度にも影響を与えます。これらの BEV ベースの手法は、νScene 上で LiDAR ベースの手法に迫る成果を上げているが、高入力解像度による計算負荷の高さは、導入時の深刻な問題であり、今後の検討課題です。
知覚範囲がLiDARベースの検出器における設定と常に一致しているため、BEV知覚解像度に対するグリッドサイズの影響を主に考察しています。しかし、これらの一般的な設定は、高速道路でのケースなど、いくつかの実用的なシナリオでは十分ではなく、これも将来の研究を必要とする潜在的な問題です。
ネットワークデザイン
検出性能のもう一つの重要な要因は、異なる特徴抽出バックボーンと検出ヘッドを使用することです。この種の方法は、通常、遠近法理解のための十分な意味的監督の欠如に悩まされています。そこで、ほとんどの手法では、3D検出 または深度推定のための単眼ベースの手法で事前に学習したPVバックボーンを使用しています。 検出ヘッドに関しては、Transformerベースの方法は通常、完全にエンドツーエンド設計を達成するために、DETR3D またはtransformable DETRヘッドを使用しています。
補助的なタスク
画像、動画、LiDAR点群など、学習時に利用可能な様々なデータモダリティがあるため、より良い表現学習のための補助タスクの設計も最近の研究のホットスポットになっています。深度推定、単眼2D・3D検出、2D車線検出 などの古典的な補助タスクに加え、ステレオから単眼学習、 LiDARからステレオ学習 など、クロスモダリティ設定から知識抽出するスキームもいくつか考案されています。しかし、この新しいトレンドはまだ小規模なデータセットでの実験に焦点を当てており、大量の学習データがこのような学習アプローチの利点を弱める可能性がある大規模なデータセットでの検証と開発をさらに進める必要があります。
トレーニング内容
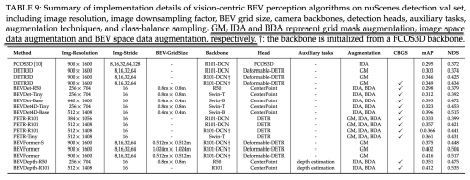
学習ベースの認識における共通の問題についてです。まず、これらの手法のほとんどはビュー変換と異なるモダリティを含むため、data augmentation はPV画像とBEVの両方に適用することができます。以下に示すように、最近の手法では、通常、3種類のdata augmentationを利用します(GM、IDA、BDA)。その中でも、BEVの増強は、このパラダイムにとって特に重要です。さらに、LiDARベースのアプローチと同様に、クラスが不均衡な問題について、いくつかの手法は、ロングテールのカテゴリのサンプル数を増やすためにCBGS を利用しています。
まとめ / 感想
PV2BEVの変換を解くための最近の研究を包括的にまとめたサーベイ論文ですが、体系的、全体像を掴む参考になりました。個別の手法の詳細については、ぞれぞれの論文を確認したいと思います。
参考文献
T. Roddick and R. Cipolla, “Predicting semantic map representations from images using pyramid occupancy networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 138–11 147.
A. Saha, O. Mendez, C. Russell, and R. Bowden, “Translating images into maps,” in 2022 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2022.
Y. Jiang, L. Zhang, Z. Miao, X. Zhu, J. Gao, W. Hu, and Y.-G. Jiang, “Polarformer: Multi-camera 3d object detection with polar transformer,” ArXiv, p. abs/2206.15398, 2022.
T. Roddick, A. Kendall, and R. Cipolla, “Orthographic feature transform for monocular 3d object detection,” arXiv preprint arXiv:1811.08188, 2018.
S. Chen, , X.Wang, T. Cheng, Q. Zhang, C. Huang, andW. Liu, “Polar parametrization for vision-based surround-view 3d detection,” arXiv:2206.10965, 2022.
Y. Li, Y. Chen, X. Qi, Z. Li, J. Sun, and J. Jia, “Unifying voxel-based representation with transformer for 3d object detection,” CoRR, 2022.
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” CoRR, 2022.